✨ Hash Table이란?
효율적인 탐색을 위한 자료구조로써 key-value쌍의 데이터를 입력받음, 해시값 h(k)를 위치로 지정하여 key-value 데이터 쌍을 저장
- 좋은 Hash Function : 해시값이 고르게 분포되게 하는 것
✅ Direct-address Table
Key값으로 k를 갖는 원소는 index k에 저장하는 방식
[ { 1 : a}, { 2 : b}, { 3 : c} ]
-
불필요한 공간 낭비
-
key가 다양한 자료형을 담을 수 없게 됨
✅ Hash Table
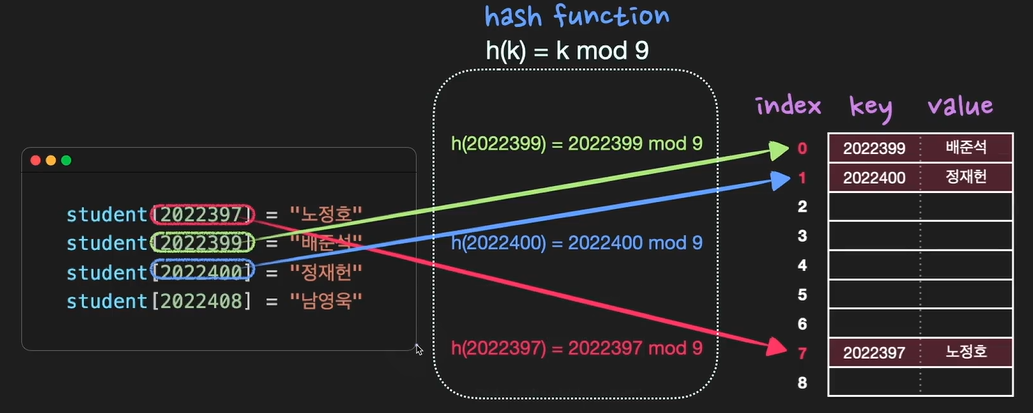
hash function h를 이용해서 key-value를 index : h(k)에 저장
키 k값을 갖는 원소가 위치 h(k)에 hash된다 (h(k)는 키 k의 해시값이다)
-
key는 무조건 존재해야 함
-
중복되는 key가 있어서는 안됨
-
hash table을 구성하고 있는 데이터의 공간을 slot 또는 bucket이라고 함
✅ 시간복잡도와 공간효율
-
저장, 검색, 삭제 : O(1)
(collision으로 인하여 최악의 경우 O(n) -
공간 효율성은 떨어짐
데이터가 저장되기 전에 미리 저장공간(slot, bucket)을 확보해야 하기 때문
따라서 저장공간이 부족하거나 채워지지 않은 부분이 많은 경우 생길 수 있음
✅ Collision
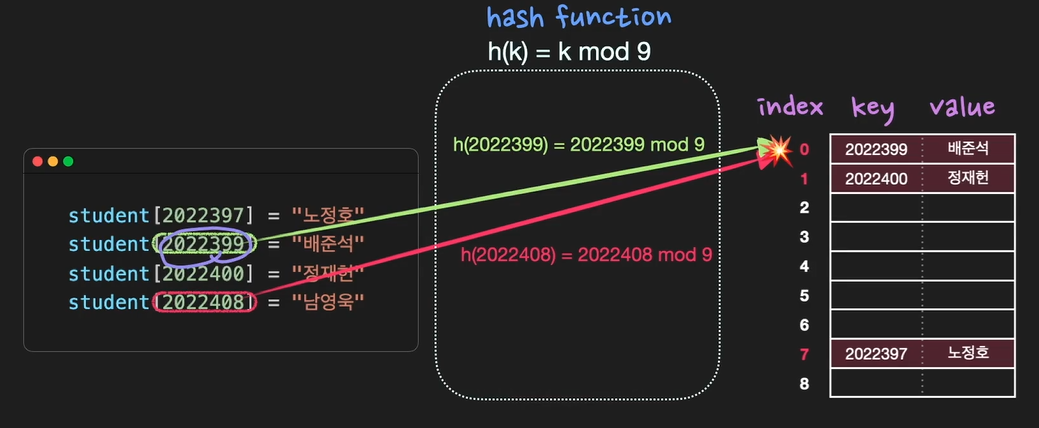
collison이란 서로다른 key의 해시값이 똑같을 때를 말함, 중복되는 key는 없지만 해시값은 중복될 수 있는데 이 때 collision이 발생, 따라서 collision이 최대한 적게 나도록 hash function을 잘 설계해야 함
❓ seperate chaining
linked List를 이용, linked list에 노드(slot)을 추가하여 데이터를 저장
-
삽입 : 서로 다른 두 key가 같은 해시값을 갖게되면 linked list에 node를 추가하여 (key, value) 데이터 쌍을 저장, 삽입의 복잡도는 O(1)
-
검색 : 기본적으로 O(1)의 시간복잡도 이지만 최악의 경우 O(n)의 시간복잡도를 갖음
-
삭제 : 검색의 시간복잡도와 동일, 최악의 경우 O(n)의 시간복잡도를 갖음
❓ open addressing
미리 정해진 규칙에 따라 hash table의 비어있는 slot을 찾음
빈 slot을 찾는 방법에 따라 크게 Linear Probing, Quadratic Probing, Double Hashing으로 나눔
-
Linear Probing : 충돌이 발생한 해시값으로 부터 일정한 값을 건너뛰어 (+1, +2, +3 ...), 비어있는 slot에 데이터를 저장
(특정 영역에 데이터가 집중적으로 몰리는 클러스터링(Clustering) 현상이 발생하는 단점이 있음, 평균 탐색 시간이 증가) -
Quadratic Probing : 일정한 값 ( +1^2, +2^2, +3^2 ..)로 건너뛰어, 비어있는 slot에 데이터를 저장
(특정 영역에 데이터가 집중적으로 몰리는 클러스터링(Clustering) 현상이 발생하는 단점이 있음, 평균 탐색 시간이 증가) -
Double Hashing : 클러스터링 문제가 발생하지 않도록 2개의 해시함수를 사용하는 방식, 최초의 해시값을 얻을 때 사용하고 또다른 해시 충돌이 발생할 때 탐사 이동폭을 얻기 위해 사용
