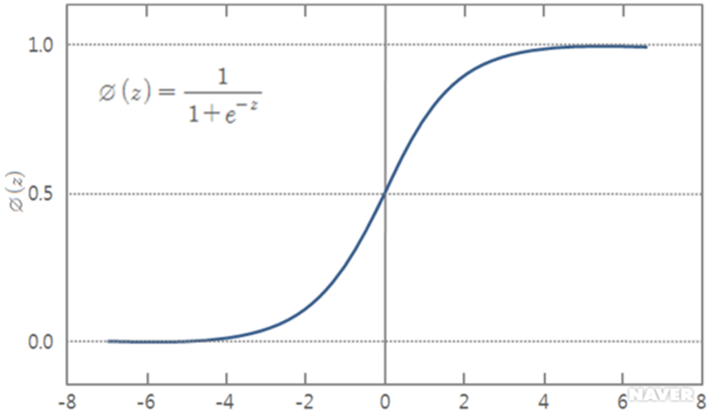
📌 로지스틱 회귀분석(Logistic Regression)
로지스틱 회귀분석(Logistic Regression)은 종속 변수가 범주형 데이터일 때 적용할 수 있는 회귀 분석 기법 중 하나로, 데이터가 특정 범주(예: 성공/실패, 스팸/정상 등)에 속할 확률을 예측하는 데 사용됩니다.
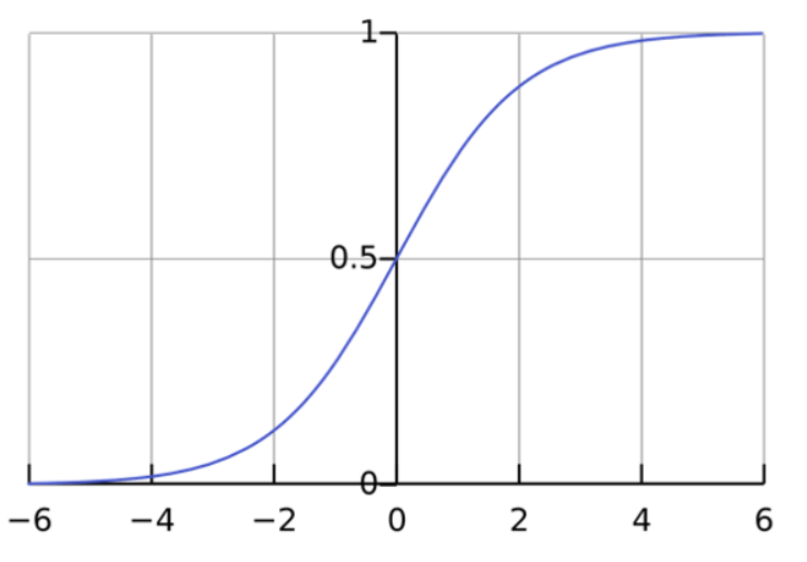
✅ 로지스틱 회귀분석의 기본 개념
로지스틱 회귀분석은 시그모이드 함수를 활용하여 독립 변수와 종속 변수 사이의 관계를 모델링합니다. 이 과정에서 종속 변수는 이진 분류 또는 다중 분류 문제로 확장될 수 있습니다.
- 이진 분류: 제품이 불량인지 여부, 고객 이탈 여부, 이메일 스팸 여부
- 다중 분류: 특정 질병의 유형 분류, 이미지에서 객체 감지
범주형 반응변수
📍 이진변수 (반응변수값이 0 혹은 1에 포함)
로지스틱 회귀분석은 특히. 이진 분류 문제 해결에 효과적이다. 독립변수와 종속변수 간의 로지스틱 함수를 사용하여 데이터를 모델링하고, 각 독립변수의 가중치를 조정하여 예측 확률을 계산합니다. 이를 통해 각 개별 관측치의 이진 분류 결과를 예측할 수 있습니다.
📍 멀티클래스 변수 (반응변수 값이 1 혹은 2 혹은 3 이상인 경우)
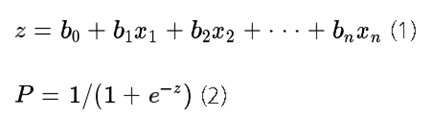
✅ 로지스틱 회귀와 선형 회귀의 차이점
선형 회귀는 연속형 데이터를 예측하는 데 적합하지만, 범주형 데이터를 처리하기에는 한계가 있습니다. 아래는 예시를 통해 이해해봅시다.
▶ Case 1: 연속형 데이터를 다룰 때 (선형 회귀)
선형 회귀는 연속형 종속 변수를 예측하는 데 효과적입니다. 예측 값은 독립 변수의 가중치 합에 따라 직선(linear line) 형태로 표현되며, 데이터의 패턴을 잘 반영할 수 있습니다.
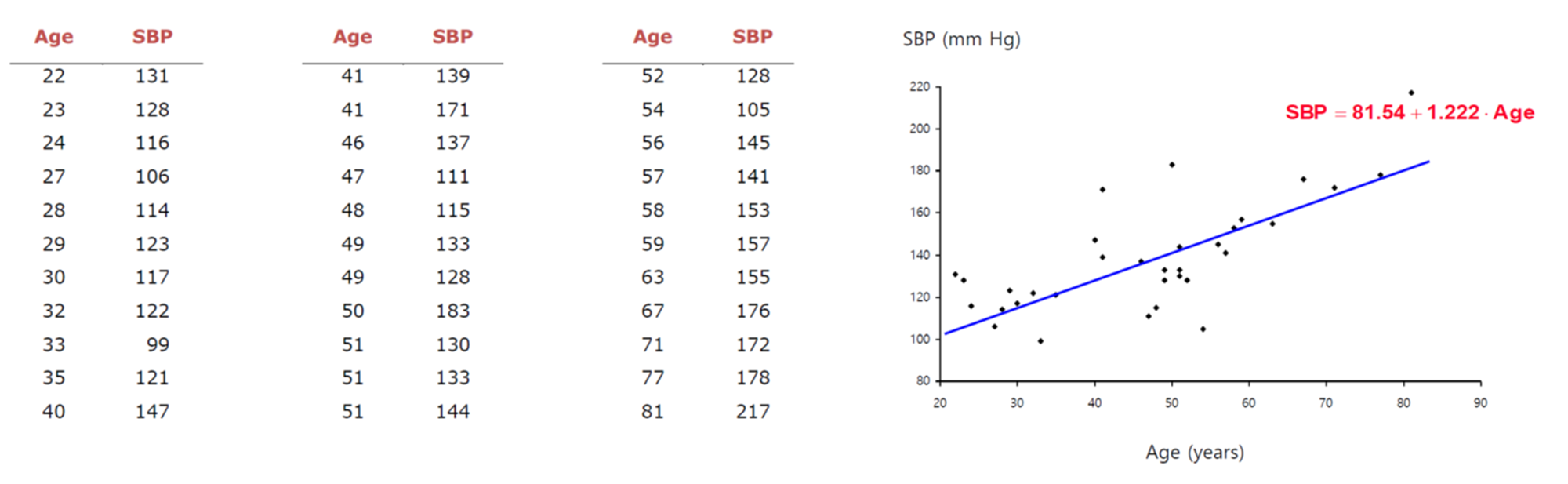
아래 그림에서는 데이터가 연속형 종속 변수일 때, 선형 회귀 모델이 데이터의 패턴을 잘 적합시키는 모습을 보여줍니다.
특징:
- 입력 변수에 따른 출력 값(종속 변수)을 연속적으로 예측
- 회귀선은 데이터 패턴을 최대한 따라가는 직선으로 적합됨
- 잔차(실제 값과 예측 값의 차이)를 최소화하는 것이 목표
예시:
- 주택의 면적을 기준으로 주택 가격을 예측
- 학생의 공부 시간에 따른 시험 점수 예측
타켓변수가 연속형 일때, 일반적인 선형 회귀로 회귀선을 적합하게 그리고 패턴을 파악하고 예측할 수 있다.
▶ Case 2: 범주형 데이터를 다룰 때 (로지스틱 회귀)
선형 회귀는 연속형 데이터에 적합하지만, 종속 변수가 범주형 데이터인 경우에는 한계를 드러냅니다.
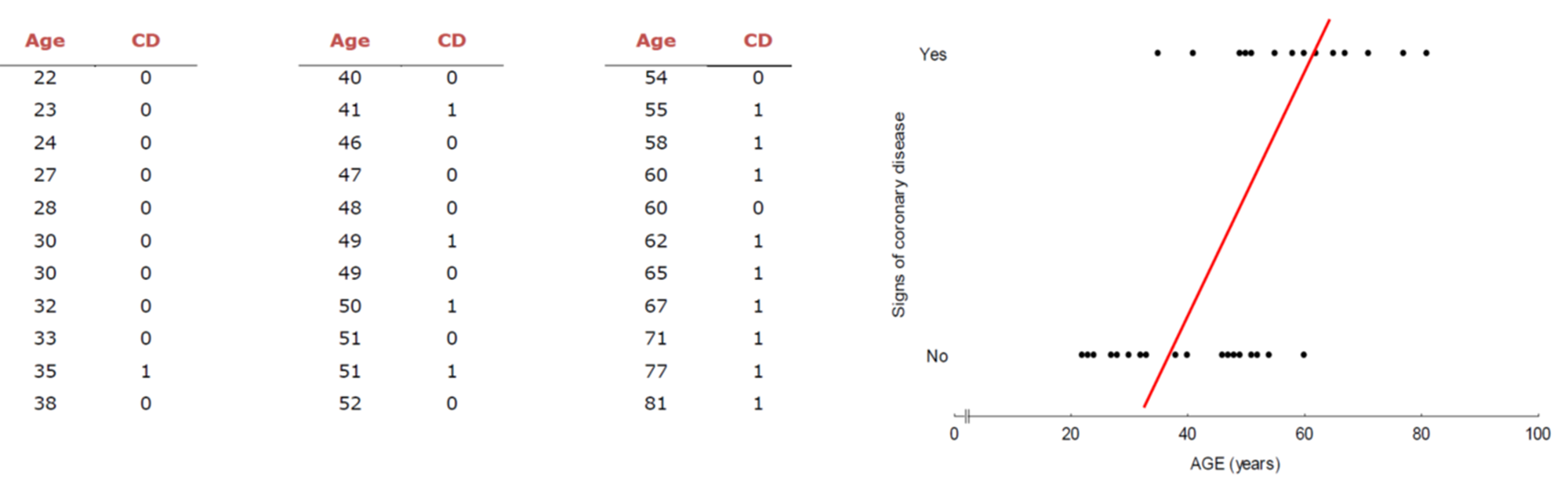 다음 그림은 종속 변수가 범주형 데이터일 때, 선형 회귀선을 적용한 경우를 보여줍니다. 단순 선형 회귀선으로는 데이터의 패턴을 잘 나타냈다고 이야기할 수 없겠죠?
다음 그림은 종속 변수가 범주형 데이터일 때, 선형 회귀선을 적용한 경우를 보여줍니다. 단순 선형 회귀선으로는 데이터의 패턴을 잘 나타냈다고 이야기할 수 없겠죠?
🔎 WHY?
1. 선형 회귀의 예측 값이 0에서 1 사이로 제한되지 않는다
범주형 데이터를 확률로 표현해야 하는 상황에서 적절하지 않습니다. 예를 들어, 어떤 데이터가 특정 범주에 속할 확률이 음수이거나 1을 초과하는 값으로 예측된다면, 이는 해석이 불가능하거나 잘못된 결과로 이어질 수 있습니다.
2. 선형 회귀가 데이터의 이진 분류 특성을 제대로 반영하지 못한다
이로 인해 분류 문제에서 패턴을 적합하게 모델링하지 못하고 예측 성능이 크게 떨어질 수 있습니다.
=> 이러한 문제의 해결책으로 등장한 것이 바로 로지스틱 회귀 개념입니다.
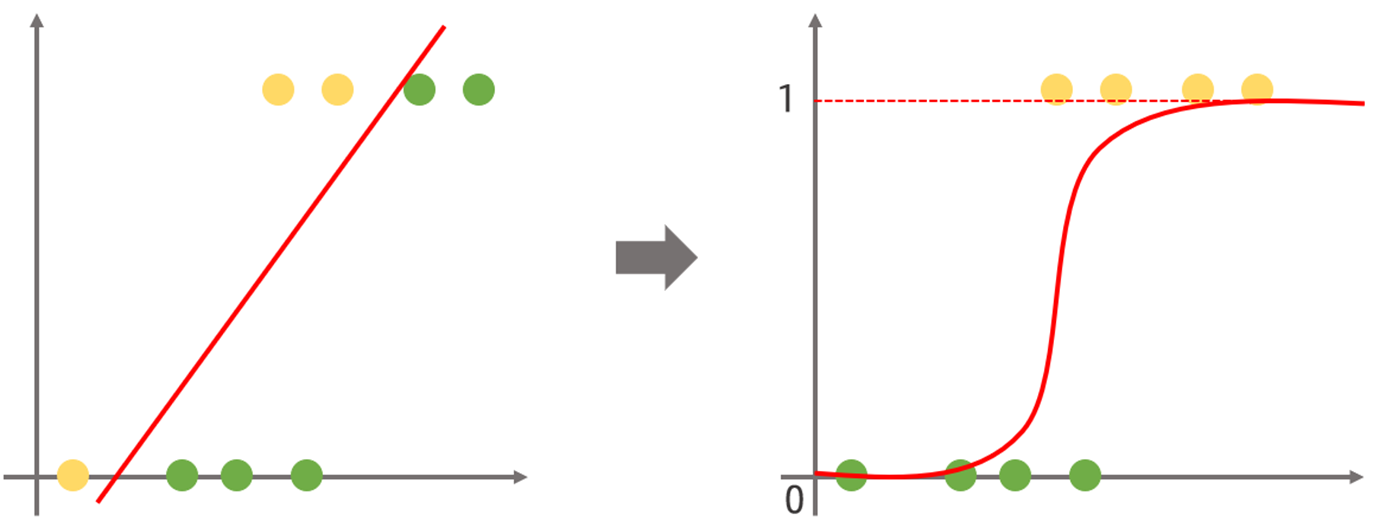
로지스틱 회귀는 선형 회귀의 한계를 극복하기 위해 비선형적인 접근 방식을 채택합니다. 이진 분류 문제에서 데이터를 효과적으로 모델링하기 위해 시그모이드 함수를 사용하여 그래프를 비선형으로 표현합니다. 시그모이드 함수는 입력 값을 기반으로 출력 값을 0에서 1 사이의 확률 값으로 변환하며, 이로 인해 이진 분류의 특성을 잘 반영할 수 있습니다.
✅ 로지스틱 회귀모델의 주요 개념
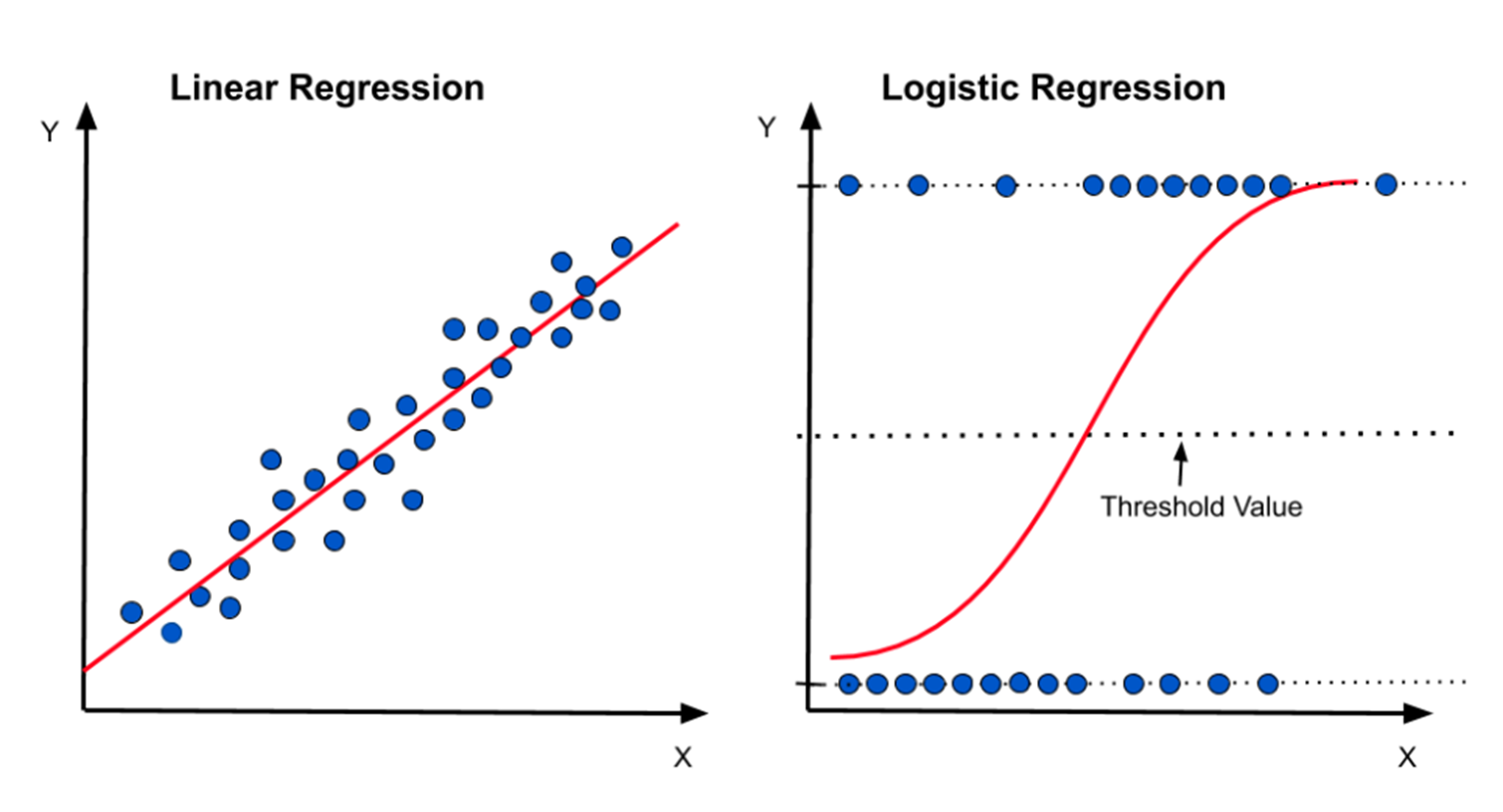
🔎 시그모이드 함수
로지스틱 회귀분석의 핵심은 시그모이드 함수입니다.
로지스틱 회귀 모델은 시그모이드 함수를 활용해 회귀선을 적합시킵니다. 이러한 접근은 범주형 데이터의 패턴을 보다 정확하게 표현하고, 각 데이터 포인트가 특정 클래스에 속할 확률을 효과적으로 계산할 수 있습니다.
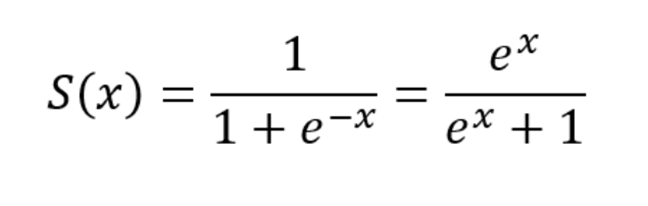 (이때, x는 독립 변수의 가중치 합(선형 모델)입니다.)
(이때, x는 독립 변수의 가중치 합(선형 모델)입니다.)
▶ 시그모이드 함수의 특징
◼ 출력 값의 범위:
입력 값 x가 어떤 값이든 출력 값은 항상 0과 1 사이입니다. 이에 따라 예측 값을 확률로 해석할 수 있습니다.
◼ 단조 증가 함수:
x 값이 증가할수록 출력 값도 증가하며, x 가 감소하면 출력 값은 감소합니다. 따라서 입력 값이 클수록 특정 범주에 속할 확률이 높음을 의미합니다.
◼ S자 곡선:
함수의 형태가 S자(S-shape)로 나타나며, z=0을 기준으로 대칭적입니다. z=0일 때 함수 값은 정확히 0.5입니다
◼ 그 외 특징
- 하나의 종속 변수와 여러 독립 변수 간의 다변수 회귀 관계 조사 가능
- 미분결과를 아웃풋의 함수로 표현 가능
✅ 로지스틱 회귀의 응용 사례
-
불량품 예측: 공장에서 생산된 제품의 품질 분류
-
이탈 고객 분석: 고객이 이탈할 가능성을 예측하여 마케팅 전략 수립
-
사기 거래 탐지: 금융 거래 데이터를 분석하여 사기 행위 탐지
-
질병 진단: 유전자 정보를 기반으로 특정 질병 예측
-
스팸 이메일 분류: 이메일의 텍스트 데이터를 분석하여 스팸 여부 분류
✅ 로지스틱의 장점
(1) 종속 변수와 독립 변수 사이의 관계가 비선형 관계로 식별되기 때문에 정규 분포의 가정이 독립 변수에 적용되지 않습니다.
(2) 명목형, 연속형, 순서형을 비롯한 다양한 독립 변수에 다양한 자료 유형을 사용할 수 있기 때문에 복잡한 현상을 설명할 수 있습니다.
(3) 로지스틱 회귀분석의 결과에는 각 요인에 대한 여러 분석값이 포함됩니다.
📌 Odd
📍 Odd : 성공 확률을 p로 정의할 때, 실패 대비 성공 확률 비율
📍 Odds ratio (오즈비, 교차비, 승산비, OR) : 두 오즈(Odds)의 비율
Odds(오즈)는 특정 사건이 발생할 확률과 발생하지 않을 확률 간의 비율을 나타내는 값입니다. 이는 성공 확률과 실패 확률을 비교하는 방법으로, 로지스틱 회귀에서 중요한 개념 중 하나입니다.
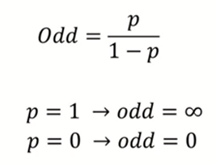
- p: 특정 사건이 발생할 확률 (예: 축구 경기에서 특정 팀이 승리할 확률)
- 1−p: 특정 사건이 발생하지 않을 확률 (예: 해당 팀이 패배할 확률)
✅ Odds의 실제 사례: 피파 월드컵 승리 예측
피파 월드컵에서 특정 팀의 승리 가능성을 예측할 때 Odds 개념을 사용할 수 있습니다.
예를 들어, 특정 팀의 승리 확률이 p=0.8 (80%)라고 가정한다면
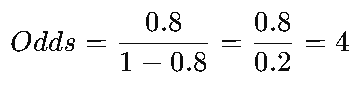
이는 이 팀이 패배할 확률보다 승리할 확률이 4배 높다는 것을 의미합니다.
반대로, 승리 확률이 p=0.4 (40%)라면
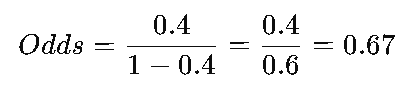
이는 이 팀이 패배할 확률이 승리할 확률보다 약 1.5배 높다는 것을 나타냅니다.
✅ Odds ratio에 따른 결과 해석
1. Odds ratio = 1
: 두 범주 간의 확률이 동일함(각 행별로 Odds가 동일함). 두 범주형 변수(질병, 위험인자)간에 연관성이 없음을 의미합니다.
2. Odds ratio > 1
: 독립 변수의 값이 증가할수록 첫번째 범주에 속할 확률이 더 높아집니다.
Ex. 위험인자에 노출되었을 때, 질병에 걸릴 확률이 더 높습니다.
3. Odds ratio <1
: 독립 변수의 값이 증가할수록 두번째 범주에 속할 확률이 더 높아집니다.
Ex. 위험인자에 노출되지 않았을 때, 질병에 걸릴 확률이 더 높습니다.
✔ 주의사항: 다중공선성
독립 변수들 간에 높은 상관 관계가 있는 경우, 로지스틱 회귀와 오즈비의 추정이 모두 불안정해질 수 있으므로 다중공선성을 고려해야 합니다.
해결 방안 :
◼ 변수 선택: 독립 변수를 줄여 다중공선성을 완화
◼ 정규화 회귀: Ridge 또는 Lasso 회귀 기법 활용
☺ 사진 및 자료 참고 ☺
https://aws.amazon.com/ko/what-is/logistic-regression/
https://syj9700.tistory.com/54
https://velog.io/@js03210/%EA%B8%B0%EA%B3%84%ED%95%99%EC%8A%B5%EA%B3%BC-MLE-%EA%B4%80%EA%B3%84
https://aws.amazon.com/ko/what-is/logistic-regression/
https://leehah0908.tistory.com/8
https://www.youtube.com/watch?v=l_8XEj2_9rk
