Machine Learning
1.[머신러닝] 데이터마이닝
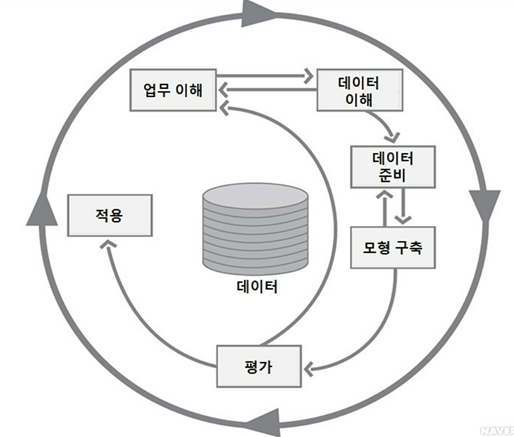
데이터마이닝은 방대한 양의 데이터로부터 유용한 정보를 추출하는 프로세스를 뜻한다. 기업은 경영 활동에 필요한 다양한 의사결정을 진행할 때, 데이터마이닝 과정을 사용한다.데이터 마이닝 표준 처리 과정(CRISP-DM, Cross Industry Standard Proce
2.[머신러닝] K-means
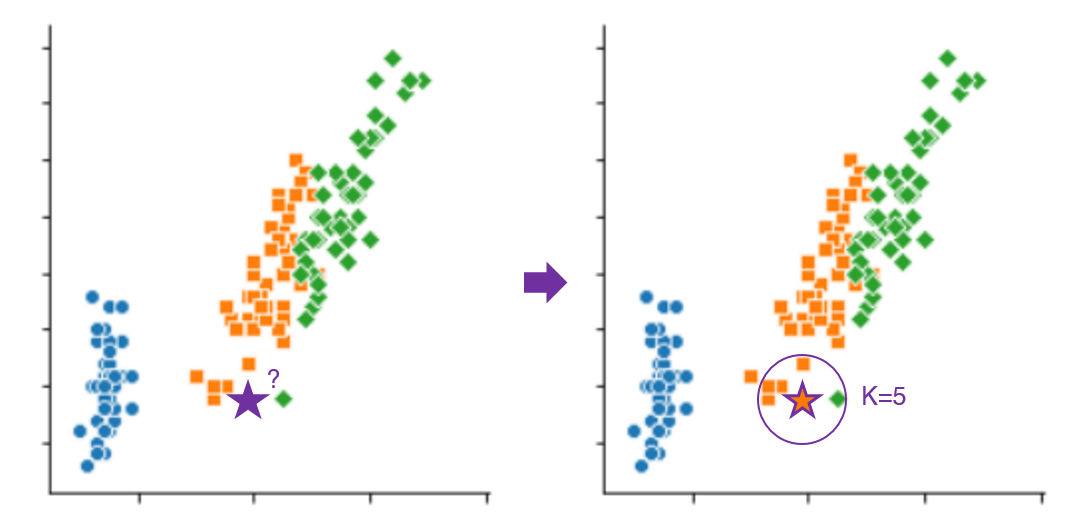
K-means 알고리즘군집의 개수(K) 설정하기초기 중심점 설정하기데이터를 군집에 할당(배정)하기중심점 재설정(갱신)하기데이터를 군집에 재할당(배정)하기K-means 예제코드유클리드 거리(Eucledian distance) (or L2 Distance)피타고라스 정리를
3.[머신러닝] 차원축소
차원의 저주 (Curse of Dimensionality)차원의 저주(Curse of Dimensionality)란, 간단히 말해, 데이터의 특징(feature)이 너무나도 많아서 알고리즘 성능 저하가 나타나는 현상을 일컫는다. 데이터를 학습시키는 근본적인 이유는 데이
4.[머신러닝] TRAIN, VALIDATION, TEST SET
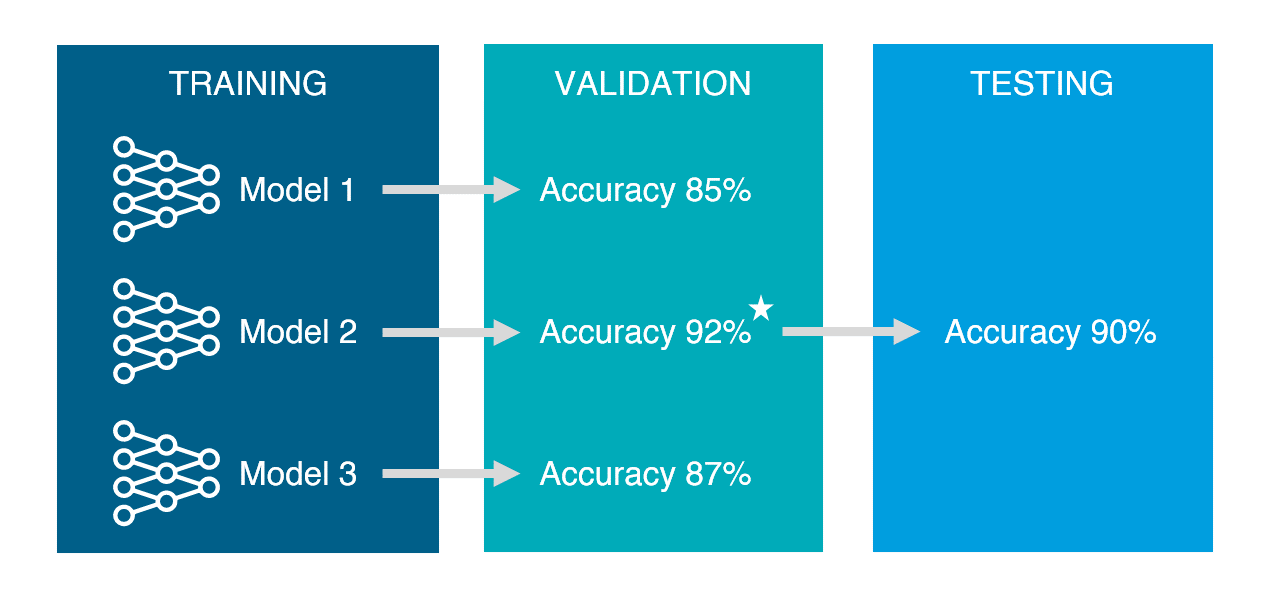
데이터마이닝에서는 모델의 성능을 정확하게 평가하고, 개선하기 위해서 데이터를 분할해 사용한다.학습용 데이터 (training data) : 모델을 학습하는데 사용된다. Training data으로 모델을 만든 뒤 동일한 데이터로 성능을 평가해보기도 하지만, 이는 ch
5.[머신러닝] 로지스틱 회귀분석, 오즈, 오즈비(Odds ratio)
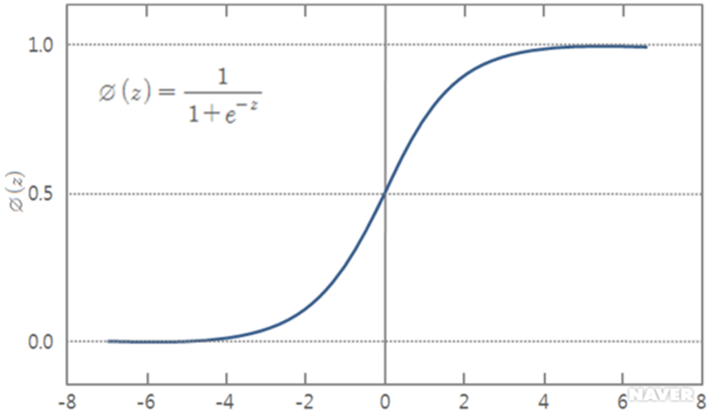
로지스틱 회귀분석(Logistic Regression) 은 종속 변수가 범주형 데이터일 때 적용할 수 있는 회귀 분석 기법 중 하나로, 데이터가 특정 범주(예: 성공/실패, 스팸/정상 등)에 속할 확률을 예측하는 데 사용됩니다. 로지스틱 회귀분석은 시그모이드 함수를 활
6.[머신러닝] Support vector machine(SVM) 최대 마진 분류와 커널 트릭의 이해
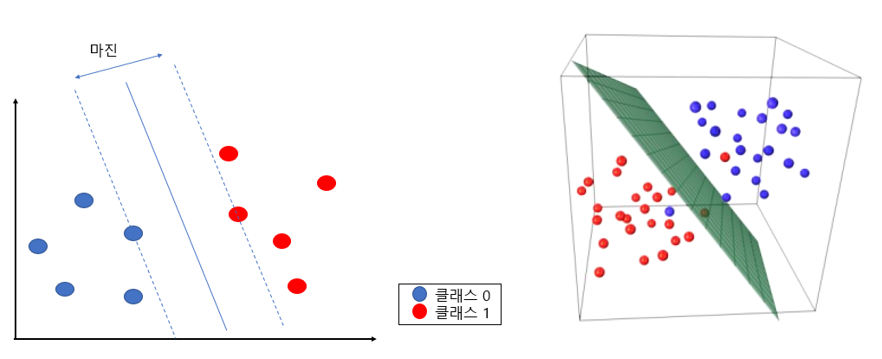
최대 마진(Maximum Margin)을 가지는 결정 경계를 이용하는 분류, 회귀 기법. 이진 분류 모델에서는 class0과 1을 구분하기 위한 최적의 경계를 탐색 SVM는 데이터를 분류할 때, 마진(magin)을 최대화하는 방식으로 경계를 추론함 이때, sup
7.[머신러닝] 앙상블 기법 ( 배깅, 부스팅, 보팅, 스태킹 )
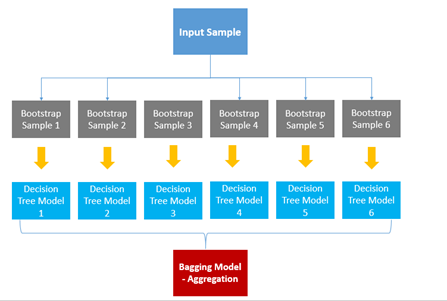
앙상블 (Ensemble) : 다양한 학습 알고리즘을 결합하여 학습 시키는 것, 예측 성능을 높이고 각각의 알고리즘을 단일로 사용할 시 발생할 수 있는 단점 보완 가능.먼저, 부트스트랩(bootstrap)이란? 통계학 용어 중 하나로, random sampling 적용
8.[머신러닝] 하이퍼 파라미터 개념 (파라미터, 하이퍼 파라미터, 하이퍼파라미터의 튜닝 기법)
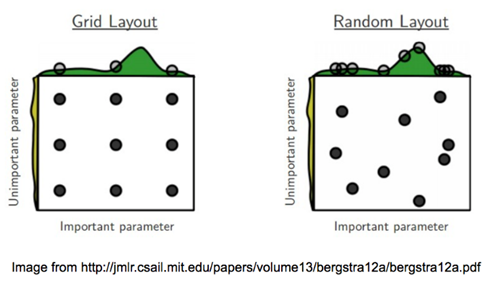
: 머신러닝 훈련 모델에 의해 요구되는 변수• 예측 모델은 새로운 샘플을 주어지면 무엇을 예측할지 결정할 수 있도록 파라미터를 필요로 한다.• 머신러닝 훈련 모델의 성능은 파라미터에 의해 결정된다.• 파라미터는 데이터로부터 추정 또는 학습된다.• 파라미터는 개발자에 의