인공지능을 공부하게 되면 Tensor라는 이름을 많이 보게 됩니다.
Tensor는 무엇이고 어디에 쓰이는 건지 알아보도록 하겠습니다.
1. 벡터, 행렬, 텐서
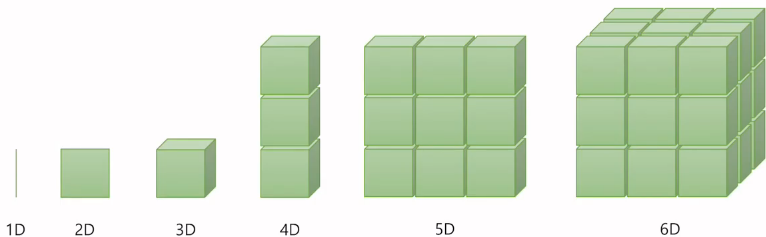
인공지능에서 다뤄지는 가장 기본적인 데이터 단위는 벡터, 행렬, 텐서입니다.
위 그림에는 나와있지 않지만 차원이 없는 값을 스칼라라고 부릅니다.
0 차원 텐서 -> 스칼라
1 차원 텐서 -> 벡터
2 차원 텐서 -> 행렬
3 차원 텐서 -> 텐서
굳이 구분을 한다면 위와 같은 방식으로 나열이 되지만 사실 나눠서 부르지 않고 합쳐서 텐서라고 부릅니다.
그렇다면 이 텐서를 어떻게 구현하는 방법에 대해서 알아보겠습니다.
파이토치, Numpy를 사용해서 텐서를 정의해보겠습니다.
2. 텐서 정의
numpy_t1 = np.array([0,1,2,3])
pytorch_t1 = torch.tensor([0,1,2,3])
pytorch_t1 = torch.from_numpy(numpy_t1)
이 말고도 torch.ones_like, torch.rand, torch.ones, torch.zeros 등 텐서를 정의하는 방법은 매우 다양합니다. 대표적으로 torch.zeros는 입력한 차원 수만큼 0인 텐서를 생성합니다.
3. 텐서 연산
텐서를 만든 후 이 텐서들은 필요에 따라 연산이 가능합니다. 어떤 연산이 가능한지 알아보기 전에 브로드캐스팅이라는 개념을 알고 가겠습니다.
브로드캐스팅(Broadcasting)
두 행렬 A,B가 있다고 가정했을 시에 A와 B를 덧셈과 뺄셈을 할 때 두 행렬 A,B의 크기가 같아야 합니다. 곱셈을 할 때는 A의 마지막 차원과 B의 첫번째 차원이 일치해야합니다.
이런 규칙들이 있으나 딥러닝을 하게 될 시에 불가피하게 크기가 다른 텐서에 대해서 연산을 수행할 때가 생기게 됩니다. 이런 경우를 위해서 파이토치에서는 자동으로 크기를 맞춰 연산을 수행시키게 하는 브로드캐스팅이라는 기능을 제공합니다.
(1X2) + (2X1) 경우
m1 = torch.FloatTensor([[1,2]])
m2 = torch.FloatTensor([[3],[4]])
tensor([[4., 5.],[5., 6.]])
위 두 벡터는 원래 수학적으로 덧셈을 수행할 수 없으나 파이토치는 브로드캐스팅 기능을 이용하여 두 벡터의 크기를 (2X2)로 변경하여 덧셈을 수행합니다.
이러한 브로드캐스팅 기능은 편리하다고 할 수 있으나 자동으로 실행되는 기능이므로 사용자 입장에서는 주의해야합니다.
4. 자주 사용되는 기능
1. 행렬 곱셈(Matrix Multiplication), 곱셈(Multiplication)
행렬로 곱셈을 하는 방법은 크게 2가지가 있습니다. 바로 행렬 곱셈과 원소 별 곱셈입니다.
행렬 곱셈은 matmul(), 원소 별 곱셈은 mul()을 사용합니다.
2. 평균(Mean)
Numpy에서의 사용법과 매우 유사합니다. mean()을 사용하여 원소의 평균을 구하면 됩니다.
mean의 인자에 dim(차원)을 주게 되는 경우를 보겠습니다.
t = torch.FloatTensor([[1,2], [3,4]])
t.mean(dim=0)
result = tensor([2., 3.])
dim=0 라는 것은 첫번째 차원을 의미합니다. 행렬에서 첫번째 차원은 행을 의미합니다.
그리고 인자로 dim을 준다면 해당 차원을 제거한다는 의미가 됩니다. 다시 말해 행렬에서 열만 남기겠다는 말이 됩니다.
3. 덧셈
덧셈은 sum()을 이용해 수행하면 됩니다. 평균을 구하는 방법과 같이 dim을 인자로 줄 수 있습니다. 만약 dim=1 이라면 열을 제거한다는 뜻으로 행만 남기겠다는 뜻입니다. dim=-1도 같은 말입니다.
4. Max와 ArgMax
Max는 원소의 최대값을 반환하지만 ArgMax는 최대값을 가진 인덱스를 반환합니다.
5. View
View는 Numpy에서의 Reshape와 같은 역할을 합니다. 텐서의 크기를 변경해주는 역할을 수행합니다.
만약 3차원 텐서를 2차원 텐서로 변경시키고 싶은 경우를 보겠습니다.
t = np.array([[[0, 1, 2], [3, 4, 5],[[6, 7, 8], [9, 10, 11]]])
ft = torch.FloatTensor(t)
ft라는 이름의 3차원 텐서를 정의하고 크기를 확인하면 torch.Size([2,2,3]) 입니다.
이 ft텐서를 view를 사용해 2차원 텐서로 변경해보겠습니다.
ft.view([-1,3])
ft.view([-1, 3]).shape
tensor([[ 0., 1., 2.], [ 3., 4., 5.], [ 6., 7., 8.], [ 9., 10., 11.]])
torch.Size([4, 3])
view([-1,3])이 가지는 의미는 다음과 같습니다.
-1은 자동으로 파이토치에게 맡기겠다는 의미이며 3은 두번째 차원의 길이가 3이 되도록 하라는 의미입니다.
즉, 3차원 텐서를 2차원 텐서로 변경하되 (?,3)의 크기로 변경하라는 의미입니다.
6. Squeeze, Unsqueeze
스퀴즈는 차원이 1인 차원을 제거하는 기능이고 언스퀴즈는 차원이 1인 차원을 생성하는 기능입니다.
ft = torch.FloatTensor([[0],[1],[2]])
ft.squeez()
tensor([0., 1., 2.])
(3X1)크기를 가진 2차원 텐서 ft에 squeeze 연산을 수행하게 되면 1인 두번째 차원 즉, 열이 제거 되면서 (3,)의 크기를 가진 텐서로 변경됩니다.
다음은 언스퀴즈의 경우입니다.
ft = torch.Tensor([0,1,2])
ft.unsqeeze(0)
tensor([[0., 1., 2.]])
인자로 특정위치를 넣어주면 특정 위치에 1인 차원을 생성합니다. 결과는 (3,) 크기에서 (1X3)의 크기로 변경된 것을 보여줍니다.
7. 타입 캐스팅(Type Casting)
텐서에도 자료형이 있습니다. 각 데이터형별로 정의되어져 있습니다.
이런 자료형을 변환하는 것을 타입 캐스팅이라고 합니다.
lt = torch.LongTensor([1,2,3,4])
lt.float()
이런 식으로 변환하고자 하는 텐서에 .자료형() 을 붙이면 타입 캐스팅이 됩니다.
8. 연결(Concatenate)
두 텐서를 연결하는 방법에 대해 알아보겠습니다.
x= torch.FloatTensor([[1,2], [3,4]])
y= torch.FloatTensor([[5,6], [7,8]])
torch.cat([]) 을 사용해 연결할 수 있습니다. dim을 인자로 주어 어느 차원을 늘릴 것인지를 설정할 수 있습니다.
torch.cat([x,y], dim=0)
tensor([[1., 2.], [3., 4.], [5., 6.], [7., 8.]])
dim=0을 인자로 넣어주었기 때문에 첫번째 차원을 늘리라는 의미를 가지고 있습니다.
torch.cat([x,y], dim=1)
tensor([[1., 2., 5., 6.], [3., 4., 7., 8.]])
dim=1을 인자로 넣어준 경우에는 위와 같은 결과를 얻을 수 있습니다.
9. 스택킹(Stacking)
연결을 하는 또 다른 방법으로 스택킹이 있습니다. 옆으로 연결한다기 보단 쌓는다는 의미입니다.
x = torch.FloatTensor([1, 4])
y = torch.FloatTensor([2, 5])
z = torch.FloatTensor([3, 6])
torch.stack([x, y, z])
tensor([[1., 4.], [2., 5.], [3., 6.]])
순차적으로 쌓여 (3X2) 텐서가 됩니다.
10. ones_like, zeros_like
ones_like는 1로 채워진 텐서를 만드는 것이고 zeros_like는 0으로 채워진 텐서를 만듭니다.
11. 인플레이스(In-Place) 연산
인플레이스 연산은 _을 뒤에 붙여주면 됩니다. 인플레이스 연산을 하는 이유는 메모리를 절약하기 위해서입니다.
인플레이스 연산은 새로운 값을 다른 곳에 저장하여 만드는 것이 아닌 기존 값에 새로운 값을 덮어쓰는 의미라 메모리 절약이 됩니다.
하지만 인플레이스 연산도 브로드캐스팅 기능처럼 사용자가 잘 생각하고 써야합니다.
