인공지능 공부
1.TENSOR(텐서)
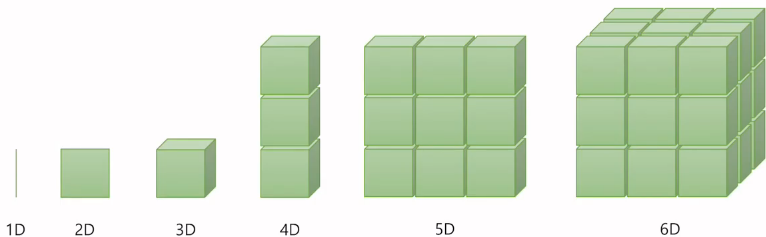
인공지능을 공부하게 되면 Tensor라는 이름을 많이 보게 됩니다.Tensor는 무엇이고 어디에 쓰이는 건지 알아보도록 하겠습니다.인공지능에서 다뤄지는 가장 기본적인 데이터 단위는 벡터, 행렬, 텐서입니다.위 그림에는 나와있지 않지만 차원이 없는 값을 스칼라라고 부릅니
2.ML의 기본적인 개념

머신 러닝에서 식을 세울 때 이 식을 가설이라고 합니다. 가설은 임의로 추측해서 세워보는 식일 수도 있고, 경험적으로 알고 있는 식일 수도 있습니다. 그래서 맞는 가설이 아니라고 판단되면 계속 수정해나가는 식이 되기도 합니다.선형 회귀의 가설은 y = Wx + b 입니
3.배치와 커스텀 데이터
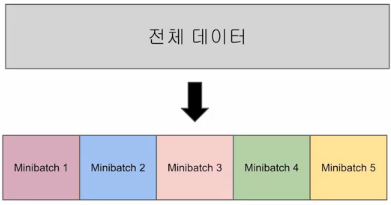
위 데이터의 개수는 5개입니다.그러나 현업에서 다루게 되는 많은 양의 데이터에 비하면 굉장히 적은 양입니다.예를 들어, 수 십만개 이상의 전체 데이터에 대해 계산을 하게 된다면 매우 많은 시간과 메모리가 필요합니다. 그래서 전체 데이터를 작은 단위로 나누어 그 단위로
4.선형 회귀(Linear Regression)
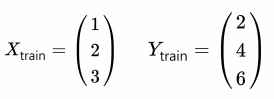
단순 선형 회귀의 데이터 구조는 다음과 같습니다.선형 회귀의 가설은 y = Wx + b 직선의 방정식과 같습니다.위 그림은 임의로 그려진 주황색 선에 대해 각 실제값과 직선의 예측값에 대한 값의 차이를 화살표로 표현된 것입니다. 빨간색 화살표는 곧 실제값과 예측값 사이
5.머신러닝/딥러닝 용어 이해
머신 러닝 모델의 평가 실제 모델을 평가하기 위해서는 데이터를 훈련용, 검증용, 테스트용으로 분리하는 것이 일반적입니다. 훈련용과 테스트용이 쓰이는 이유는 알겠으나 검증용은 왜 쓰일까요? 검증용 데이터는 모델의 성능을 평가하기 위한 용도가 아니라 모델의 성능을 조정하
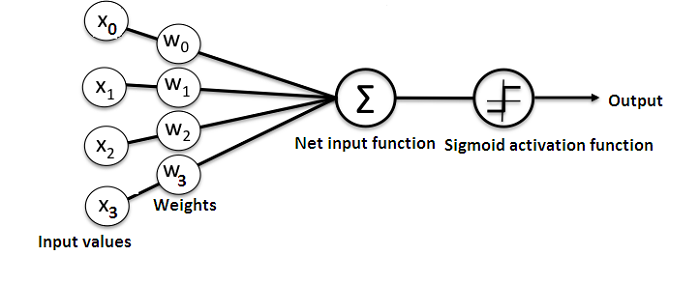
6.퍼셉트론(Perceptron)
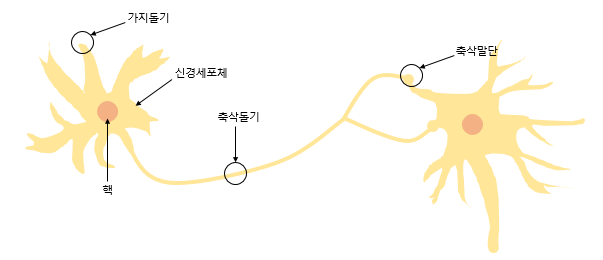
인공 신경망은 머신 러닝의 방법 중 하나입니다. 최근 인공 신경망을 복잡하게 쌓아 올린 딥 러닝이 다른 머신 러닝 방법들을 뛰어넘는 성능을 보여주는 사례가 늘면서, 머신 러닝과 딥 러닝을 구분하기 시작했습니다.퍼셉트론은 프랑크 로젠블라트가 1957년에 제안한 초기 형태
7.로지스틱 회귀(Logistic Regression)
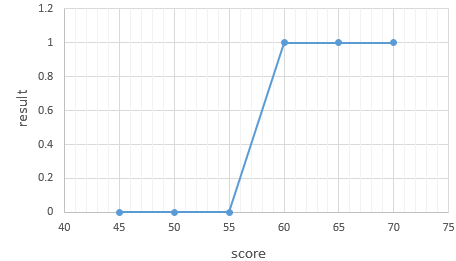
로지스틱 회귀(Logistic Regression)은 이름은 회귀이지만 사실 분류 문제에 쓰이는 알고리즘입니다. 그 중에서도 이진 분류(Binary Classification)에 사용됩니다.이진 분류는 2개의 선택지 중에서 하나를 고르는 것입니다. 예를 들면 메일이 스
8.원-핫 인코딩
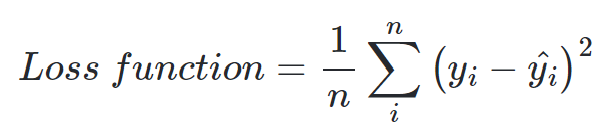
원-핫 인코딩(One-hot encoding)은 범주형 데이터를 처리할 때 label을 표현하는 방법입니다.선택해야 하는 선택지의 개수만큼 차원을 가지면서 각 선택지의 인덱스에 해당하는 원소에는 1, 나머지 원소는 0의 값을 가지도록 하는 표현 방법입니다.예를 들어서
9.소프트맥스 회귀(Softmax Regression)

이전에 로지스틱 회귀를 통해서 2개의 선택지 중 1개를 고르는 이진 분류를 구현해봤습니다. 이번엔 소프트맥스 회귀를 통해 3개 이상의 선택지 중에서 1개를 고르는 다중 클래스 분류에 대해 알아보겠습니다.다중 클래스 분류는 3개 이상의 선택지 중에서 1개를 고르는 문제입
10.역전파(BackPropgation)
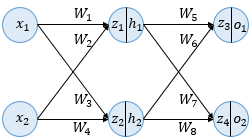
인공 신경망이 순전파 과정을 진행하여 예측값과 실제값의 오차를 계산하였을 떄 어떻게 역전파 과정에서 가중치를 업데이트하는지 보겠습니다.역전파의 이해를 위해서 사용할 인공 신경망은 입력층, 은닉층, 출력층 이렇게 3개의 층을 가집니다. 또한 2개의 입력과, 2개의 은닉층
11.비선형 활성화 함수
비선형 활성화 함수(non-linear Activation function)는 입력을 받아서 수학적 변환을 수행하고 출력을 생성하는 비선형 함수입니다. 전형적인 활성화 함수 중에서 시그모이드 함수와 소프트맥스 함수가 있습니다.이번엔 인공 신경망의 은닉층에서 왜 활성화
12.다층 퍼셉트론으로 MNIST 분류
13.과적합
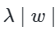
학습 데이터에 모델이 과하게 학습하는 현상을 과적합(Overfitting) 이라고 합니다. 과적합 현상은 모델의 성능을 떨어트리는 주요 문제입니다. 모델이 과적합되면 훈련 데이터에 대한 정확도는 높을지라도 새로운 데이터인 검증 데이터나 테스트 데이터에 대해서는 제대로
14.기울기 소실과 기울기 폭주
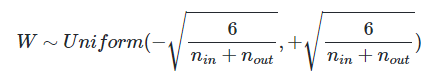
깊은 인공 신경망을 학습하다보면 역전파 과정에서 입력층으로 갈 수록 기울기가 점차적으로 작아지는 현상이 발생할 수 있습니다. 입력층에 가까운 레이어에서 가중치들이 업데이트가 제대로 되지 않으면 결국 최적의 성능을 가진 모델을 만들 수 없게 됩니다. 이런 현상을 기울기
15.순환 신경망(Recurrent Neural Network, RNN)

순환 신경망(RNN)은 시퀀스(Sequence)모델입니다. 입력과 출력을 시퀀스 단위로 처리하는 모델입니다. 번역기를 생각해보면 입력은 번역하고자 하는 문장 즉, 단어 시퀀스입니다. 출력에 해당되는 번역된 문장 또한 단어 시퀀스입니다. 이러한 시퀀스들을 처리하기 위해
16.CNN(Convolutional Neural Network)

합성곱 신경망(Convolutional Neural Network)은 이미지 처리에 탁월한 성능을 보이는 신경망입니다. 이번 챕터에서는 합성곱 신경망에 대해서 알아보겠습니다.합성곱 신경망은 크게 합성곱층(Convolution Layer)와 풀링층(Pooling Laye
17.CNN으로 MNIST 분류
합성곱 신경망은 합성곱 층을 부르는 단위가 통합이 되어있지는 않습니다.합성곱(nn.Conv2d) + 활성화 함수(nn.ReLU)를 하나의 합성곱 층으로 보고 최대 풀링(nn.MaxPool2d)은 풀링 층으로 별도로 명명합니다.합성곱(nn.Conv2d) + 활성화 함수(
18.MultiModal Model
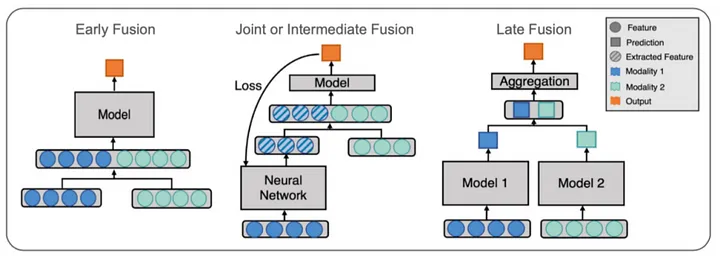
멀티모달 모델(MultiModal Model)은 텍슽, 이미지, 오디오, 비디오 등 다양한 유형의 데이터(모달리티)를 함께 고려하여 서로의 관계성을 학습하고 처리하는 인공지능입니다. 이 중에서 상대적으로 크기가 큰 모델은 대형 멀티모달 모델 즉, LMM(Large Mu
19.YOLOv1 PYTORCH 구현
YOLOv1 논문을 바탕으로 Pytorch를 이용하여 구현했습니다. 아직 서툰부분이 많아 미흡하지만 보람찬 구현이었습니다.구현 환경은 Colab을 사용하였습니다.모델을 정의하는 부분은 따로 architecture config를 만들어 반복된 작업을 줄였으면 좋았겠지만