학습 데이터에 모델이 과하게 학습하는 현상을 과적합(Overfitting) 이라고 합니다. 과적합 현상은 모델의 성능을 떨어트리는 주요 문제입니다. 모델이 과적합되면 훈련 데이터에 대한 정확도는 높을지라도 새로운 데이터인 검증 데이터나 테스트 데이터에 대해서는 제대로 동작하지 않습니다.
이는 모델이 학습 데이터를 불필요할정도로 과하게 학습하여 훈련 데이터에 포함된 노이즈까지 학습한 상태라고 해석할 수 있습니다. 그렇다면 이 과적합을 막을 수 있는 방법은 무엇이 있을까요?
1. 데이터의 양을 늘리기
모델은 데이터의 양이 적을 경우에 해당 데이터의 특정 패턴이나 노이즈까지 쉽게 암기하므로 과적합 현상이 발생할 확률이 늘어납니다. 그렇기 때문에 데이터의 양을 늘릴 수록 모델은 데이터의 일반적인 패턴을 학습하여 과적합을 방지할 수 있습니다. 만약 데이터의 양이 적을 경우에는 의도적으로 기존의 데이터를 조금씩 변형하고 추가하여 데이터의 양을 늘리기도 하는데 이를 데이터 증식 또는 증강(Data Augmentation) 이라고 합니다. 이미지 데이터의 경우에는 데이터 증식이 많이 사용되는데 이미지를 돌리거나 노이즈를 추가하고, 일부분을 자르는 등으로 데이터를 증식시킵니다.
2. 모델의 복잡도 줄이기
인공 신경망의 복잡도는 은닉층(Hidden Layer)의 수나 매개변수의 수 등으로 결정됩니다. 과적합이 되었을 때 인공 신경망 모델에 대해서 할 수 있는 조치는 인공 신경망의 복잡도를 줄이는 것입니다.
class Architecture1(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(Architecture1, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.relu = nnReLU()
self.fc3 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
out = self.relu(out)
out = self.fc3(out)
return out위 인공 신경망은 3개의 선형(Linear) 레이어를 가지고 있습니다. 이 신경망이 입력 데이터에 과적합 현상을 보인다면 다음과 같이 레이어를 줄여서 복잡도를 줄일 수 있습니다.
class Architecture1(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(Architecture1, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out3. 가중치 규제(Regularization) 적용
복잡한 모델이 간단한 모델보다 과적합이 될 가능성이 높습니다. 복잡한 모델을 간단하게 하는 방법으로는 레이어나 매개변수 등을 줄이는 것도 있지만 가중치 규제 방법(Regularization)이 있습니다.
- L1 규제 : 모든 가중치 w의 절대값 합계를 손실 함수에 추가합니다. L1 노름 이라고도 합니다.
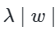
- L2 규제 : 모든 가중치 w의 제곱합을 손실 함수에 추가합니다. L2 노름 이라고도 합니다.
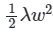
이 두 식 모두 손실 함수를 최소화하기 위해서 가중치 w의 값이 작아져야 한다는 특징이 있습니다. L1 규제로 예를 들어보면 L1 규제를 사용하면 손실 함수가 최소가 되게 하는 가중치와 편향을 찾는 동시에 가중치들의 절대값의 합도 최소가 되어야 합니다. 이렇게 되면 가중치 w의 값들은 0 또는 0에 가깝게 작아져야 하므로 어떤 특성들은 모델을 만들 때 거의 사용되지 않게 됩니다.
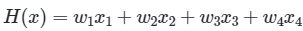
위와 같은 식이 있다고 가정하겠습니다. 여기에 L1 규제를 사용하였더니 w3의 값이 0이 되었다고 해보겠습니다. 이는 x3 특성은 사실 모델의 결과에 별 영향을 주지 못하는 특성이 됩니다.
L2 규제는 L1 규제와는 달리 가중치들의 제곱을 최소화하므로 w의 값이 완전히 0이 되기보다는 0에 가까워지는 경향을 뜁니다. L1 규제는 어떤 특성들이 모델에 영향을 주고 있는지를 정확히 판단하고자 할 때 유용합니다. 만약, 이런 판단이 필요가 없다면 L2 규제가 대체적으로 더 잘 동작하는 경우가 많습니다. 인공 신경망에서 L2 규제를 가중치 감쇠(weight decay)라고도 부릅니다.
파이토치에서는 옵티마이저의 weight_decay 매개변수를 설정하여 L2 규제를 적용합니다. weight_decay 배개변수의 기본값은 0입니다.
4. 드랍아웃(Dropout)
드랍아웃은 학습 과정에서 신경망의 일부를 사용하지 않는 방법입니다. 예를 들어서 드랍아웃의 비율을 0.5로 한다면 학습 과정마다 랜덤으로 절반의 뉴런을 사용하지 않고 나머지 절반 뉴런만을 사용합니다.
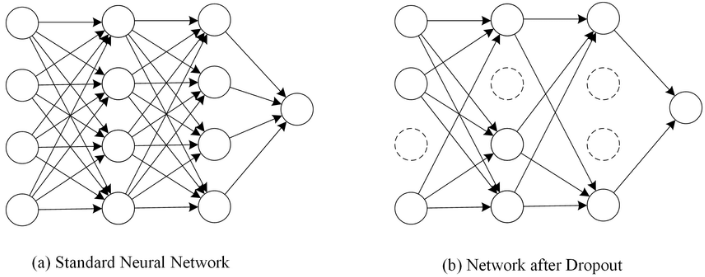
드랍아웃은 신경망 학습 시에만 사용하고 예측 시에는 사용하지 않는 것이 일반적입니다. 학습 시에 인공 신경망이 특정 뉴런 또는 특정 조합에 너무 의존적이게 되는 것을 방지해주고 매번 랜덤 선택으로 뉴런들을 사용하지 않으므로 서로 다른 신경망들을 앙상블하여 사용하는 것 같은 효과를 내어 과적합을 방지합니다.
