오늘 할 것
- Huggingface에 존재하는 여러 Pretrained Parameter 활용해보기
오늘 한 것
klue/roberta-large
실험 이유
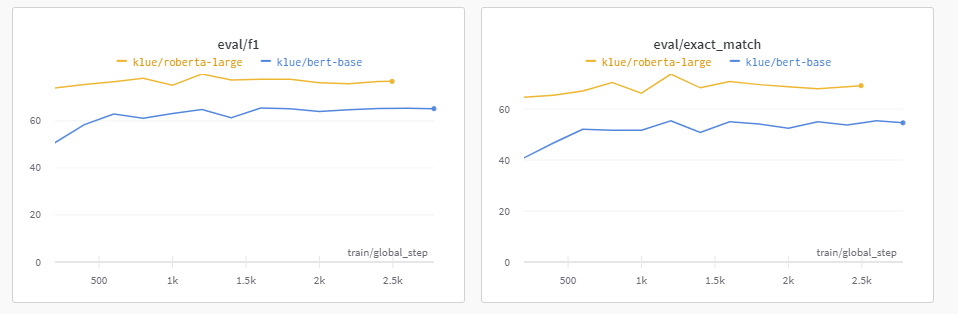
저번 대회에서도 klue/roberta-large를 활용한 것이 가장 점수가 높았고, 이번 Data도 한글 데이터이기 때문에 한글 Data에 적합한 Pretrained Model인 klue/roberta-large Parameter를 활용하였다.
결과
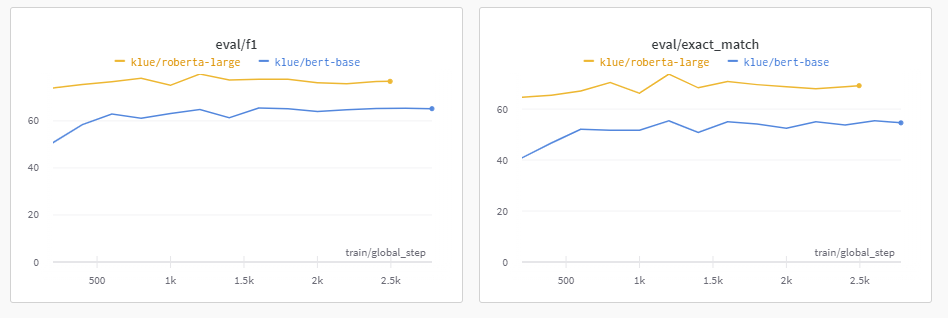
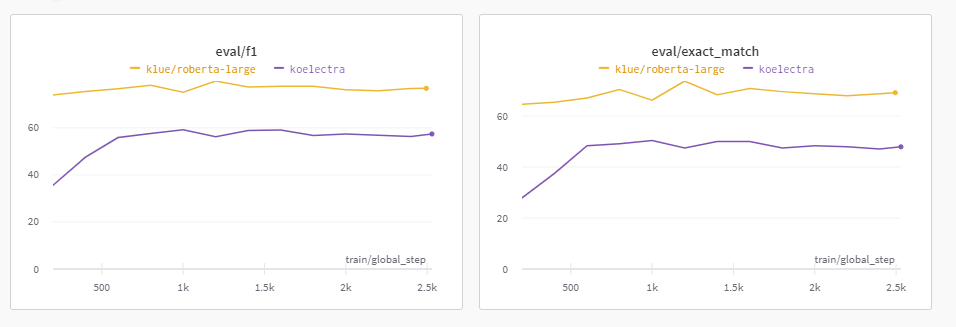
아래에서도 비교하겠지만, 모든 Model 중에서 가장 점수가 높았다. 앞으로는 klue/roberta-large 활용하는 것을 Base로 두어야겠다
klue/bert-base
실험 이유
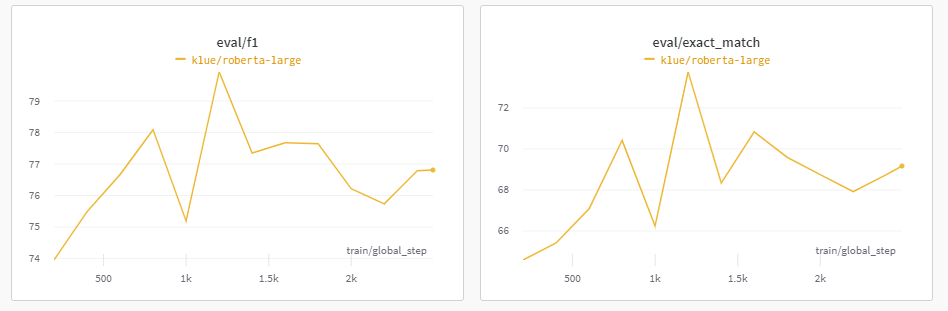
사실 처음부터 성능이 안 나올 것이라고 예측했다.
결국에는 Competition인 상황에서는 모델이 큰 것이 이득일 것인데, klue/bert-base는 오히려 roberta-large보다 작은 Model이기 때문이다.
이를 인지하고, 얼마나 떨어지는지에 대해 알아보기 위하여 실험을 진행하였다.
실험 결과
생각보다 많이 떨어졌음을 알 수 있었다. EM으로 채점을 하는데, EM이 최대 60을 넘기지 않는 것을 보며 활용하지 않는 것이 정답이였다는 확신을 하였다.
XLM-multilingual
실험 이유
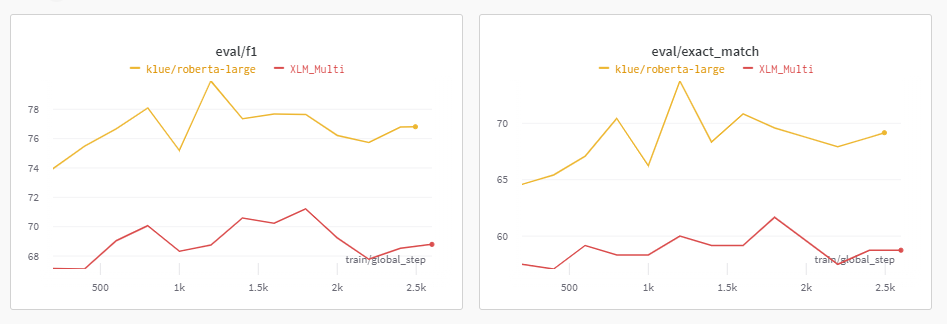
저번 대회 Feedback에서 XLM-multilingual의 성능이 더 좋았을 것 같다는 말씀이 있었다.
따라서, 이를 기반으로 XLM이 더 좋지 않을까 하는 생각에 실험을 진행하였다.
실험 결과
klue/bert-base보다는 점수가 좋아졌으나, klue/roberta-large보다는 낮았다.
이번 Task는 저번 Task보다 Context에 한국어가 더 많이 포함되어 있기 때문에 제대로 Tokenizing시키지 못하여 이런 결과가 발생하였다고 유추하였다.
즉, 다음부터 활용할 모델들은 "한국어"를 전문으로 하는 Model과 Tokenizer를 활용하는 것이 Multilingual보다는 좋을 것이라고 판단하였다.
Koelectra
실험 이유
한국어를 기반으로 처음부터 학습시킨 모델은 대표적으로 Kobert, Koelectra가 존재한다.
하지만, 아래에서 설명할 것이지만 이번 Task는 Tokenizer가 use_fast = True라는 Parameter를 활용할 수 있는 Tokenizer만 활용 가능하다.
(다른 것을 활용하고 싶을 경우 Source Code를 갈아 엎어야 한다)
하지만 Kobert의 Tokenizer는 use_fast = True를 지원하지 않기 때문에, 이를 지원하는 Koelectra로 실험해보기로 하였다.
그리고, Koelectra든 Kobert든 모델의 Size가 어차피 Base 수준이라 성능이 그렇게 나오지 않을 것 같다는 예측을 하였다.
실험 결과
실제로 klue/bert-base만큼의 점수가 나왔다.
모델의 Size가 bert-base라면 한국어만 학습을 시켰든 아니든간에 무조건 큰 모델보다 Accuracy가 작아짐을 알 수 있었다.
즉, 이후 실험에서 만약 Pretrained Model을 가져와 성능을 키우고 싶다면, "한국어"를 전문으로 학습한 "큰 모델"을 가져와야 함을 알 수 있었다.
에러 처리
FastTokenizer
에러 내용
NotImplementedError: return_offset_mapping is not available when using Python tokenizers.To use this feature, change your tokenizer to one deriving from transformers.PreTrainedTokenizerFast.
- 즉, 코드 중
train_data.map()메서드가 존재하는데, 이 메서드를 활용하기 위해서는PreTrainedTokenizerFast버전이 존재해야 한다는 것이다.
자세한 내용
Huggingface에는 PreTrainedTokenizerFast라는 Tokenizer 형식이 존재하는데, "Fast Tokenizer"라고도 한다.
Fast Tokenizer는 Rust로 구축된 Tokenizer를 의미하는데, 이는 Batched Tokenization에서 속도를 더욱 빠르게 해주며 입력으로 주어진 문장과 Token 사이를 Mapping해주는 추가적인 함수를 지원한다.
여기서 에러가 생기는 이유는 아래 문장이다. "추가적인 함수를 지원한다"
이 Task 특성 상 Encoding시키고 다시 Decoding할 때 해당 단어의 위치가 매우 중요해진다.
.map()에 들어간 Function을 잘 살펴보면 Decoding 시 원래 Position을 찾는 코드가 들어가 있으며, 이 부분이 (이 Task에서는) 필수적이므로 꼭 활용해야하는 코드이다.
그런데, 문장과 Token 사이를 Mapping해주는 함수는 일반 PreTrainedTokenizer에는 존재하지 않는 함수이다. 꼭 "Fast Tokenizer"이여야만 활용할 수 있는 함수이다.
Fast Tokenizer는 SentencePiece Tokenizer(T5, Albert, XLNet 등)을 지원하지 않고 있으며, Kobert도 Fast Tokenizer는 지원하지 않고 있다.
따라서, use_fast = True Parameter를 Kobert에 활용해도 에러가 뜨는 것이다
느낀점
확실히 어제까지 Source Code를 확실히 파악해 놓으니 코드 짜기가 한결 쉬워지고, 에러 처리하기도 쉬워진 것 같다
(위 에러를 처리하는데 1시간도 채 걸리지 않았다)
내가 잘하고 있다는 반증인가 싶어서 조금 기쁘기도 했고, 내가 예상한대로 Wandb 결과 그래프가 나온다는 것도 많이 기뻤던 대회였던 것 같다
