오늘 할 것
- Classifier로 LSTM 활용해보기
- Bidirectional LSTM과 일반 LSTM 모두 Classifier로 활용해보기
- BiLSTM Output 전체를 활용할 것인지, 아닌지에 대해 확인해보기
- 2-Layer로 Classifier 변경해보기
- CNN Layer 활용해보기
오늘 한 것
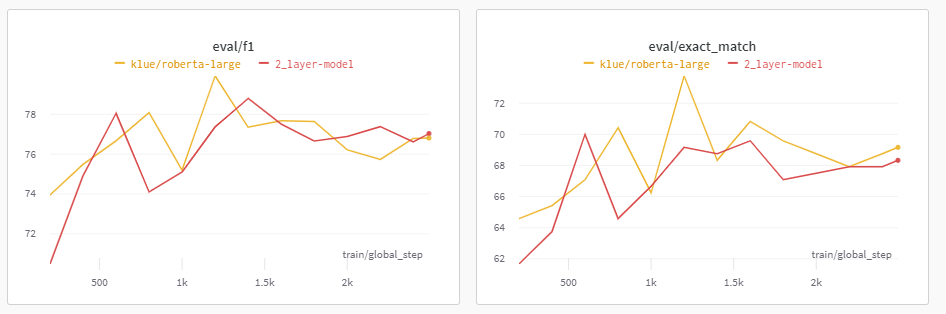
2-Layer로 Classifier 변경시키기
수행 이유
Model이 커지면 커질수록 Accuracy가 높아지는 것으로 알고 있었다.
Huggingface에서 활용하는 AutoModelForQuestionAnswering에서 Classifier는 오직 1개의 Layer로만 구성되어 있고, nn.Linear을 활용하는 것을 알 수 있었다.
그렇다면, nn.Linear를 2개를 활용하여 모델을 조금 더 크게 하면 좋은 결과가 나오지 않을까 생각했다.
수행 과정
nn.Linear(1024, 512), nn.Linera(512,2)를 Sequential하게 활용하여 2단계를 거쳐 특징을 추출하도록 하였다.
수행 결과
생각보다 큰 차이는 없었던 것 같다.
이번 대회의 Evaluation Metric이 EM이라는 것을 간주해봤을 떄, EM적으로는 오히려 낮게 나오는 2 Layer-model을 활용할 이유가 없어 보여 활용하지 않기로 하였다.
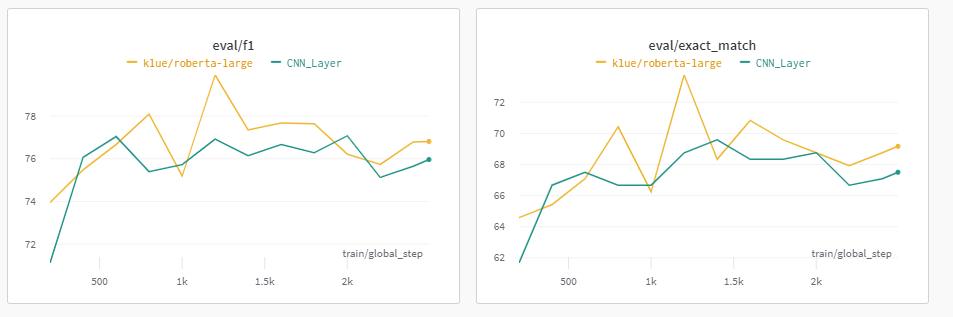
CNN Layer로 Classifier 변경시키기
수행 이유
이전에 들었던 강의 중 RNN과 CNN을 결합시킨 모델이 있었던 것으로 기억하고 있어, 이번 Task에도 이를 활용하면 좋은 결과를 낼 수도 있지 않을까 싶어 실험해보았다.
수행 결과
그렇게 좋은 성능 향상은 없었다. 사실 CNN은 V100이 놀고 있는 것을 보기 싫었던 내가 대충 생각해내서 수행시킨, 근거 없는 모델이였는데 이때문인지 점수 변경에 큰 영향을 미치진 않았다.
하지만, RNN과 CNN을 동시에 활용하는 RCNN, CRNN 모델이 실제로 존재하는 것은 대회 끝나고 찾아봤기 때문에, 이 방법도 제대로 조사하여 수행시킨다면 좋은 결과를 낼 수도 있다는 점을 생각하여 나중에 이 방법들도 제대로 수행시켜 보자.
BiLSTM 활용
수행 이유
사실 내가 가장 큰 신경을 쓴 부분이다.
BiLSTM을 Classifier로 활용하면 무조건 좋은 성능을 보일 것이라고 생각했다.
이유는 크게 2가지이다.
- 실제로 QA 문제를 해결할 떄 BiLSTM을 Classifier로 활용하는 경우가 있다.
- BiLSTM은 어느정도 문맥의 흐름을 포함하는 형태로 Output을 내기 때문에, 질문과 Context의 흐름이 중요한 이번 QA Model에서는 꽤나 좋은 성능을 내주지 않을까라는 기대가 있었다.
BiLSTM 같은 경우 많은 방식으로 실험을 해봤기 때문에 모든 경우의 수를 따로 정리했다.
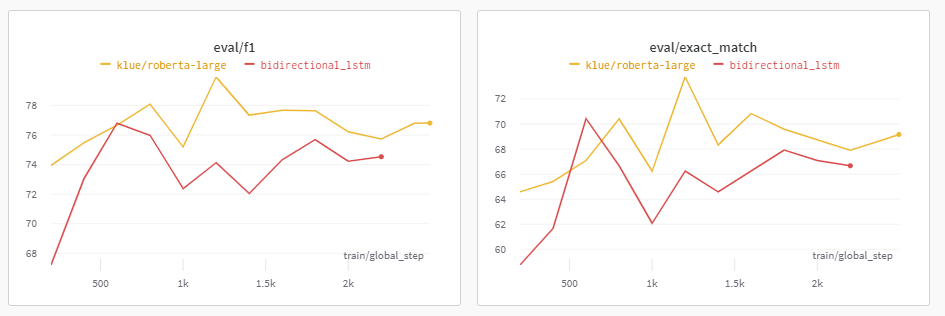
1. 기본적인 BiLSTM
수행 과정
BiLSTM에서 나온 Output을 nn.Linear함수에 담아 최종 Output을 도출해냈다.
수행 결과
그렇게 좋은 성능 향상은 보이지 않았다.
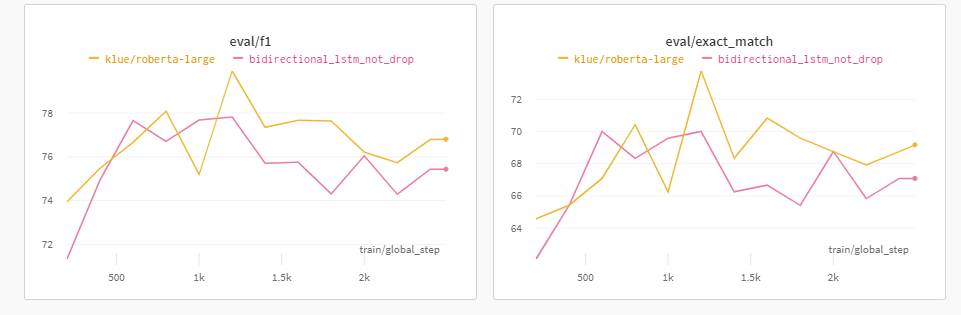
2. Dropout 활용하지 않음
수행 과정
위 첫번째 기본적인 BiLSTM에서는 BiLSTM의 Output을 nn.Linear함수에 넣기 이전에 Dropout을 활용했다.
하지만, 이번에는 Dropout을 활용하지 않고 바로 최종 Output을 도출할 함수의 Input으로 넣었다.
수행 결과
f1적으로는 BiLSTM에 Dropout을 적용한 것보다 좋은 Model임이 밝혀졌으나, 우리가 활용하는 EM적으로는 더욱 낮은 점수를 도출함을 알 수 있었다.
따라서, 앞으로의 실험에서는 무조건 Dropout(p=0.7)를 활용하기로 하였다.
3. BiLSTM의 Output을 반으로 나눠 반만 활용
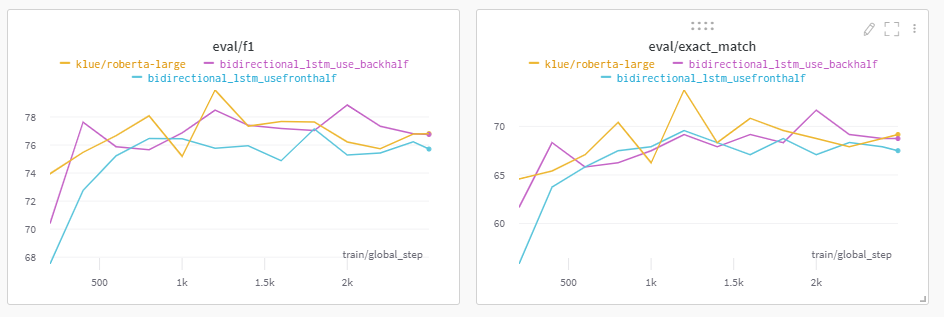
수행 이유
BiLSTM을 활용하면, Hidden Layer가 1024일 때 총 Output의 Size는 2048이 됨을 알 수 있었다.
이는, BiLSTM이 순방향으로 진행될 때 나온 Output과 역방향으로 진행하여 도출한 Output을 Concat시켜 결과값으로 반환하기 때문이다.
따라서, 순방향에서 나오는 Output, 혹은 역방향에서 나오는 Output 1개만 활용하여 결과값을 도출하면 좋은 결과가 있지 않을까 싶어 시도해보았다.
수행 결과
front를 활용하는 것보다는 Backhalf, 즉 2048 Size의 Output 중 뒤 1024 Data만 활용하는 것이 더 좋은 결과를 도출하였다
하지만, klue/roberta-large만 활용한 Model보다는 (EM을 기준으로 했을 때) 좋아지지 않았으므로 일단 다른 방법도 시도해보기로 하였다.
4. BiLSTM에 나온 Output을 ReLU 활성화 함수를 적용시킨 이후 Linear에 적용
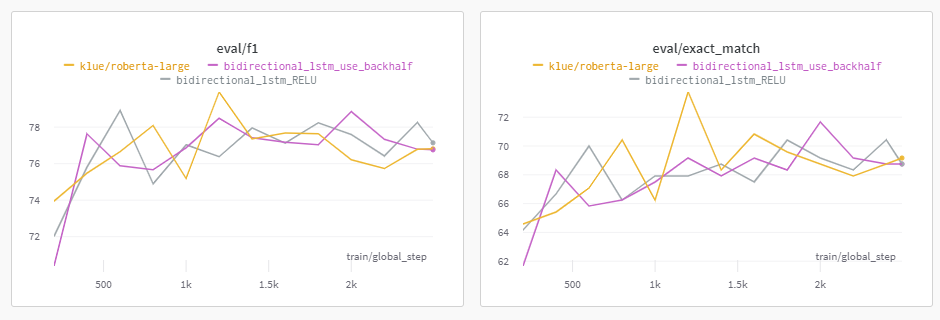
수행 이유
활성화 함수를 활용하여 BiLSTM에 나온 결과값을 비선형적으로 만들고 nn.Linear를 적용한다면 더욱 좋은 결과가 있지 않을까 생각했다
(Layer가 깊어진 것을 더 잘 활용할 수 있을 것이라 예상했다)
수행 결과
BiLSTM Classifier를 적용시킨 함수들 중 2번째로 좋은 점수를 냈다
(첫번째는 보라색 그래프인 BiLSTM의 뒷부분만 활용한 실험)
이 방법으로 inference.py를 수행시켜 Prediction 파일을 제출해보았으나 점수가 떨어져 BiLSTM이 그렇게 좋은 방법은 아니라고 깨달았다.
기타
LSTM을 겹쳐서도 수행해보고(num_layers 값을 1이 아닌 3으로 설정하였음) BiLSTM이 아닌 일반 LSTM도 활용해보는 등 많은 경우를 실험해보았지만, 모두 결과가 좋지는 않았다.
LSTM보다는 BiLSTM이 더 좋을 것 같다는 내 생각은 틀리지 않았으나, BiLSTM이 일반 Classifier보다 더 좋을 것 같다는 생각은 틀렸던, 반은 성공하고 반은 실패했던 하루였다.
에러 내용
Input Size가 설정한 것과 다름
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling cublasCreate(h and ≤)
발생 이유
BiLSTM의 Output을 nn.Linear(1024, 2)에 태울 때 발생한 Error이다.
위에 설명했듯, BiLSTM으로 설정했다면 Output은 순방향의 Output과 역방향의 Output을 Concat시켜 최종 결과를 도출한다.
즉, nn.Linear(2048,2)로 설정했어야 제대로 함수가 돌아가는 것이다.
BiLSTM을 제대로 이해하지 않고 코드 수행만 시키려다가 발생한, 매우 초보적인 실수였다.
GPU Data와 CPU Data의 혼용
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling cublasCreate(handle)
발생 이유
BiLSTM을 활용할 때, h0와 c0라는 Input 값이 따로 필요한데(초기 Cell State, Hidden State), 이 값들은 현재 CPU에 존재하고 있었다.(따로 처리를 해주지 않았음)
그런데 Model과 Model의 Output들은 모두 GPU(cuda:0)에 존재하고 있기 때문에, 이 두 값의 계산이 수행 불가하게 되는 것이다.
따라서, h0와 c0를 .to(device)를 통해 cuda:0로 옮겼더니 에러를 해결할 수 있었다.
Batch Size가 위치한 곳
ValueError: Expected input batch_size (1) to match target batch_size (64)
발생 이유
nn.LSTM에는 batch_first라는 Parameter 값을 설정할 수 있다.
이전 Level1 학습 과정에서 LSTM을 활용했던 적이 있었는데, 그 당시에는 batch_first = True로 설정하였기 때문에, 이번에도 아무 생각 없이 True로 설정하였다.
하지만, 이번 ODQA 대회에서는 Batch Size가 2번째에 위치해 있기 때문에 True로 설정할 경우 내가 원하는 Input 형식과는 전혀 다른 형태로 LSTM에 들어가게 된다.
이 때문에 나타나는 에러이며, batch_first=False, 혹은 아무런 설정을 하지 않아 첫 번째 위치가 Batch Size 위치가 아님을 나타내주기만 하면 해결되는 에러이다
ReLU(Dropout)의 활용법
argument ‘input’ (position 1) must be Tensor, not ReLU
발생 이유
nn.ReLU나 nn.Dropout을 활용하기 위해선, nn.Module을 상속받은 Class 중 __init__() 부분에 self.relu, self.dropout 등으로 설정한 이후 활용해줘야 한다.
예를 들어보자.
forward() 과정에서 A라는 값에 ReLU 함수를 적용시키고 싶다고 생각해보자.
이 때, nn.ReLU(A)가 forward 과정에 존재한다면 위 에러 코드가 발생한다.
우리는 먼저 __init__()에 self.relu = nn.ReLU()라고 relu 함수를 선언해 준 이후, forward()에서 self.relu(A)로 수행해야 정상적으로 ReLU 함수를 적용시킬 수 있음을 알 수 있다.
참고로, ReLU가 아닌 Dropout을 위와 같은 방식으로 적용시켜도 (에러 내용은 다르지만) 에러가 발생함을 알 수 있다.
배운 점
BiLSTM의 활용법
BiLSTM을 제대로 이해하지 못했을 때 StackOverflow에 올라와 있는 예시 코드를 보고 BiLSTM에 대해서 제대로 이해했었다.
BiLSTM을 이해하는데 매우 좋은 코드라고 생각하여 사이트를 첨부한다
또한, BiLSTM을 위 StackOverflow에서 대충 이해한 뒤, PyTorch API에서 LSTM에 대한 것을 찾아 한 줄 씩 읽어보며 이해하니 완벽히 BiLSTM 활용법을 이해하게 되었다.
아래 사이트는 내가 이해하지는 못했으나, 나중에 BiLSTM을 이해하고 난 뒤 다시 들어갔을 때 매우 정교한 코드라고 이해가 되었던 코드이다.
만약 BiLSTM가 잘 이해되었다고 생각하면 아래 사이트의 코드를 쭉 읽어보며 제대로 이해했는지 검토하는 것이 좋을 것 같다
느낀점
BiLSTM을 할 때 너무 많은 에러가 터져서 진짜 360도로 돌아버리는 줄 알았는데, 결국에는 이를 활용했을 때 매우 기뻤었다.
앞으로 무언가를 활용하고 싶을 때에는 활용할 대상에 대한 완벽한 이해가 필수적인 것 같다. BiLSTM을 이해하지 않고 그냥 활용만 해야지라고 대충 쓰다가는 위의 Error 내용처럼 수많은 에러들을 만날 수 있을 것이라는 것을 꼭 명심해두자.
