오늘 할 것
- Korquad 데이터를 활용하여 Train Data를 증강시키기
오늘 한 것
Korquad 데이터 활용
수행 이유
어떤 논문에서는 아래와 같이 말했다
"슬프게도, 모델이 커지고 데이터가 많아질수록 그냥 모델의 Accuracy는 높아진다"
이런 말을 생각해 볼 때, 데이터를 증강하면 자연스럽게 EM도 높아질 것이라고 생각하였다.
QA(Reader)에 대해서는 매우 좋은 Train Data인 "Korquad" Data가 존재하고, 이번 대회에서는 외부 데이터의 활용이 허락되었기 때문에 Korquad Data라는 Quality 높은 데이터를 활용하면 무조건 점수가 높아질 것이라고 생각하였다.
수행 결과
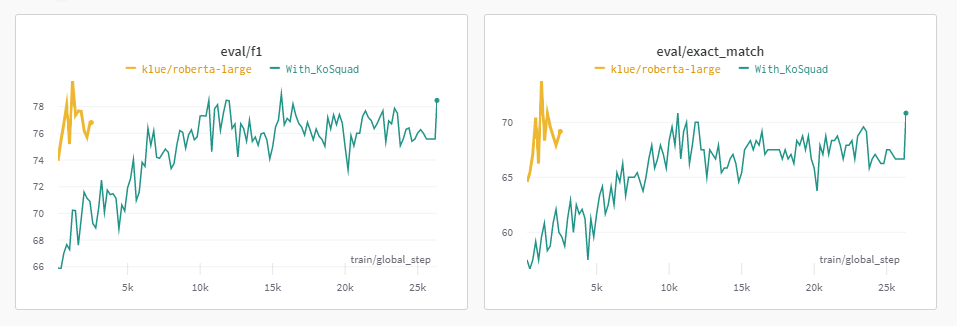
먼저, Korqud 데이터가 많기 때문에 자연스럽게 학습 Step도 많아져 그래프 형식의 차이가 있음을 볼 수 있다.
klue/roberta-large Model과 어느 정도 비슷한 EM 점수를 가짐을 볼 수 있었으나, 결국에는 낮게 나왔다.
사실, 데이터가 많아질수록 무조건 학습이 잘 진행되는 것으로 알고 있었기 때문에 매우 당황스러운 결과였고, 이 문제를 해결하기 위해 다양한 방법을 시도해보았다.
BiLSTM, CNN Classifier with Korquad
수행 이유
데이터가 많아졌는데 EM이 떨어진 것은 혹시 Parameter 개수가 부족하여 학습이 제대로 수행 되지 않은 것은 아닐까라는 의문이 들었다.
따라서, Classifier에 BiLSTM이나 CNN을 넣어 일부러 Parameter 개수를 늘려 보았다.
수행 결과
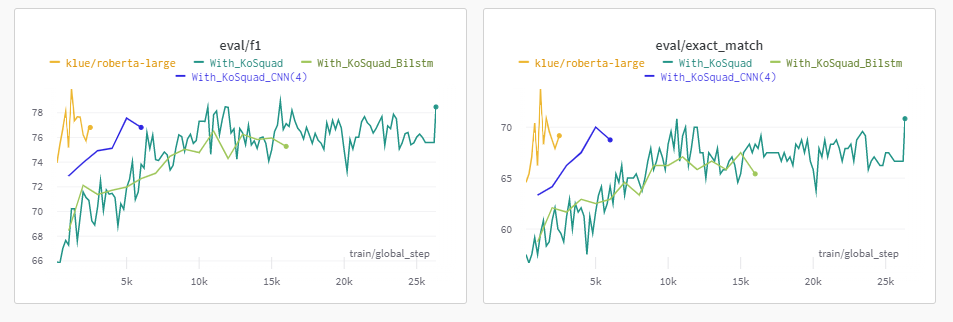
결론만 말하자면, 일반 Classifier를 활용하는 것보다 낮은 점수값을 가졌다.
그나마 CNN은 비슷한 EM 점수를 보였지만, 정확히 보면 1점 정도 낮게 결과가 나왔다.
즉, Parameter 개수 부족으로 인해 일어난 점수 하락이 아니라는 것을 의미했다.
lr_scheduler with Korsquad
수행 이유
train/loss 함수를 보니 이 모델이 Overfitting에 너무 빨리 빠지는 것이 아닌가라는 의문점이 들었다.
또한, 현재 사용하는 linear lr_scheduler를 활용하면 Local Minima 문제에 빠질수도 있을 것 같다는 생각이 들었다.
따라서, Local Minima 문제 해결을 위해 도입된 Cosine lr_scheduler를 활용해보거나, linear lr_scheduler의 Epoch을 일부러 크게하여 learning rate의 감소폭이 조금 더 작아지게 실험을 진행해보았다.
수행 결과
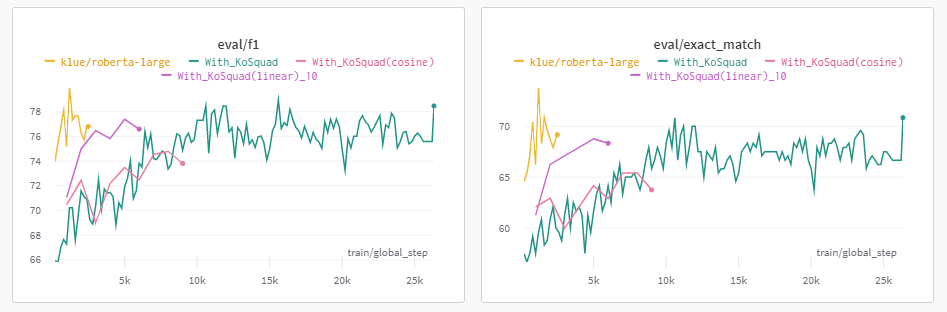
cosine은 매우 낮아졌고, Epoch을 10으로 했을 때는 그나마 나았지만, 일반적인 Model보다는 훨씬 점수가 낮았다.
즉, lr_scheduler도 Korquad를 같이 활용한 것이 오히려 점수가 떨어진 것에는 문제가 없다는 것이 밝혀졌고, 결국에는 Korquad로 데이터 증강을 한 것이 모델 성능 향상에 큰 효과가 없다고 결론지었다.
에러 내용
lr_scheduler 적용
상세 설명
사실 에러는 아니지만, 어떻게 보면 내가 원하는 lr Scheduler가 제대로 실험에 적용되지 않았었기 때문에 에러 문구 없는 에러라고 생각하여 이 부분에 추가시켰다.
내가 원하는 lr_scheudler를 Trainer에 적용하고 싶다면, 아래와 같은 과정을 거친다.
- Trainer를 상속받은 Class에서
create_optimizer_and_scheduler를 Override한다. create_scheduler메서드를 Override하여 내가 원하는 lr Scheduler로 변경시키거나,create_scheduler에서 받아오는 lr_scheduler가 아닌 내가 지정한 lr_scheduler를 활용하도록create_optimizer_and_scheduler메서드를 변경시킨다.
이 부분은 Huggingface에서 Trainer의 Source Code를 보고 수정하는 것을 추천한다
배운 점
행 무작위로 섞기
공부하게 된 이유
점수 향상이 있을 것이라고 생각한 학습 방식에 대해 점수 향상이 없다보니, Korquad 데이터는 뒤에 Concat시켰기 때문에 항상 주어진 Data를 먼저 학습하고 이후 외부 데이터를 학습하여 이런 현상이 발생하는 것은 아닐까 하는 바보같은 생각을 하였다.
그래서 한 번 Pandas 데이터의 Index를 무작위로 섞어 Model의 Input Data로 만들기로 하였다.
Data를 섞는 방식
블로그에 너무 잘 정리되어 있어, 따로 정리하지는 않았다.
느낀 점
이번 대회에서 가장 이해가 되지 않는 하루였다.
Koquad 데이터를 같이 활용하면 무조건 점수가 오를 것이라고 생각했는데 도대체 점수가 왜 떨어졌을까...?
- 추가
나중에 다른 팀원이 Korquad 데이터를 활용했을 때는 점수가 많이 올랐다는 것을 알게 되었다.
즉, 내가 데이터를 합치는 방식에 무언가 문제가 있었던 것 같고, 아이디어 자체는 잘 생각했던 것 같다.
이번 대회에서 매우 아쉬운 부분 중 하나이다.
