오늘 할 것
- 질문 형식 변경
- 답을 내기 쉬운 데이터 먼저 학습
- Title과 유사도를 가진 질문이라면 조금 더 답을 내기 쉽지 않을까?
- 쉬운 데이터부터 학습을 먼저하면 모델 입장에서도 학습하기가 더 쉽지 않을까?
오늘 한 것
질문 형식 변경
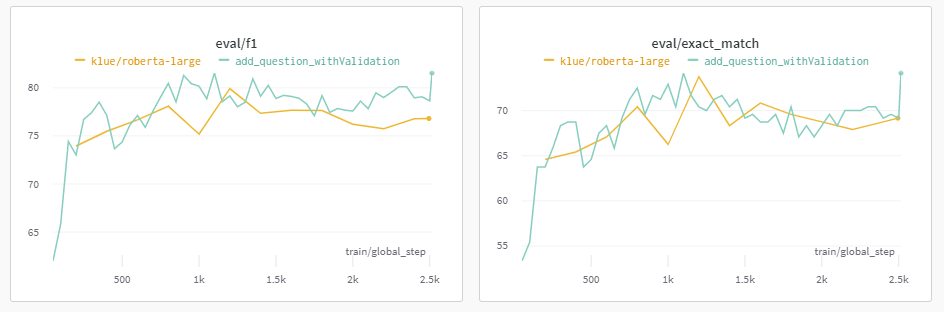
수행 이유
저번 대회에서 느꼈지만, 모델 변경보다는 데이터를 학습하기 쉬운 형태로 바꾸는게 점수 향상에 더 많은 기여도를 지녔다는 것이 생각났다.
내가 현재 수정할 수 있으며 Model의 EM에 영향을 끼치게 할 수 있는 것은 "title, Context, Question"이다
이 중 Title은 직접적으로 Model에 영향을 끼치지 않기 때문에 후순위로 밀렸으며, Context 또한 \n 같은 HTML에 활용되는 문자를 지울까도 고민했으나, 이것 또한 데이터가 아닐까? 라는 생각에 수정하지 못했다.
따라서, 직접 수정할 수 있는 데이터는 Question밖에 없었다.
이런 고민을 하던 와중 특정 논문에서 질문을 보강하는 형식으로 학습을 진행하면 QA가 더 잘 수행된다는 결과를 읽게 되었다
예를 들어, "A를 발견한 사람은?"보다는 "A를 발견한 사람은 누구인가?"로 질문하여 질문이 사람에 관한 답을 원한다는 데이터를 붙여주는 것이 더욱 좋다는 것이다.
따라서, 이 방식을 적용해보기로 하였다.
수행 과정
먼저, 데이터를 Google Translator를 활용하여 영어로 번역하였다.
이후, 2가지 기준으로 질문을 보강하기로 하였다.
- 영어의 의문사를 보고 이 질문이 어떤 것을 물어볼지 결정하자
- 예를 들어, "Who ~"라는 질문이라면 사람에 관한 질문일 것이므로 질문 뒤에 "~는 누구인가?"를 붙이자
- 영어 의문사를 보지 않더라도, 한국어 질문에 무엇을 물어볼지에 대한 단어가 명시되어 있다면 질문을 보강하자
- 예를 들어, "A를 발견한 사람은?"이라는 질문이 있다면, "사람은"이라는 부분 때문에 인물에 관한 질문이라는 것을 알 수 있다. 따라서, 질문 뒤에 "~는 누구인가?"로 질문을 보강하였다
Train과 Validation, 그리고 Test 모든 Question에 대하여 위와 같은 방식으로 질문을 보강하여 실험을 진행하였다.
수행 결과
매우 기쁘게도, Wandb 상에서는 처음으로 기본 모델보다 높은 점수가 나왔다.
내 생각이 맞았다는 생각에 제출을 했지만, Public 점수에서는 오히려 떨어졌다.
따라서, 분명 이 방법이 점수 향상을 가지고 올 것이라고 생각했지만 이번 Data에서는 효과를 못보는건가? 라는 의문을 가지며 다른 방법을 시도해 볼 수 밖에 없었다.
Similarity를 활용한 학습
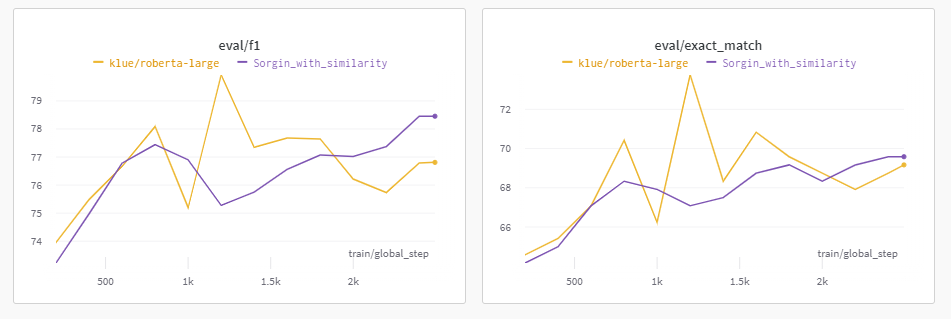
수행 이유
AI가 정말 사람의 뇌와 비슷한 과정으로 학습이 진행된다면, 쉬운 데이터부터 학습을 먼저하면 모델 입장에서도 학습하기가 더 쉽지 않을까?라는 생각을 하였다.
수행 과정
이 실험에서는 "학습하기 쉬운 데이터"가 무엇인지 아는 것이 중요했다.
나는 Question과 Title 사이에 유사도를 계산하여, 유사도가 높다면 더 쉬운 문제라고 생각하였다.
왜냐하면 Title은 Context를 대표해주는 단어이며, Title에 대한 설명이 Context에는 나와 있을 것이다.
따라서, Question과 Title과 연관성이 있다면 더욱 많은 정보를 가진 상태에서 쉽게 답을 찾을 수 있다고 생각하였다.
Similarity를 구하는 공식은 Jaccard Similarity와 Cosine Similarity가 대표적이였는데, 나는 중복을 고려하지 않고 단순히 동시에 존재하는 단어의 종류를 고려하는 jaccard Similarity를 활용하기로 하였다.
수행 결과
EM 및 F1이 많이 떨어졌다.
지금 생각해보니, 많은 데이터는 오히려 정답을 맞추는데 독이 될 수도 있다는 생각이 들었다.
또한, 중복 없이 단어 종류만 고려하는 것이 좋다고 생각했는데, 오히려 단어의 중복까지 고려하는 Cosine Similarity가 유사도를 평가하는데에는 더 적합하지 않았을까라고 생각하였다.
하지만, 제일 큰 것은 Title의 길이를 EDA 해보니, 길이가 매우 짧았다.
따라서, Similarity 계산을 해도 대부분 0.0의 값을 가졌고, 쉬운 데이터로 뽑힌 데이터의 양이 너무 적었음을 알게 되었다.
이런 부분에서 내가 원하는 효과를 제대로 보지 못했던 것 같았다.
에러 내용
Pickle 파일에 내용 없음
Pickle - EOFError: Ran out of input"
에러 설명
말 그대로 Pickle에 데이터가 저장되어 있지 않은 것이다.
내가 Google Translator를 활용하여 번역한 파일을 Pickle 형식으로 저장했는데(Google Translator는 하루에 정해진 번역 단어 개수가 정해져있기 때문), 실수로 Empty Array를 Pickle에 저장하여 위와 같은 에러가 발생하였다.
tqdm의 활용
tqdm: 'module' object is not callable
에러 설명
나는 import tqdm을 활용하면 tqdm을 사용할 수 있는 줄 알았다.
그런데, 우리가 활용하는 tqdm은 tqdm.tqdm이였다.
즉, from tqdm import tqdm으로 import 시켜야 우리가 원하는 대로 tqdm을 활용할 수 있었던 것이였다.
분명히 이런 에러를 과거에 겪었을 텐데, 또 이런 에러를 겪는 것을 보니 정말 정리가 중요하다고 생각이 들었다.
배운 점
Pyarrow
개념
Python에서 제공해주는 Apache Arrow이다.
Parquet파일을 읽고 변환하는데 효과적인 것이 Apache Arrow인데, 간단히 설명하자면 더욱 빠르게 CSV 데이터 등을 읽어올 수 있게 도와주는 도구라고 생각하면 된다.
- Parquet에 대한 설명 : https://pearlluck.tistory.com/561
그렇다면, Pandas를 왜 사용할까?
바로, Pyarrow는 CSV 포맷 중 "쓰기"를 지원하지 않는다.
즉, pyarrow Data는 변경불가 데이터가 된다.
__index_level_0__란?
- 이와 관련된 질문 : https://github.com/apache/arrow/issues/2244
간단히 말하자면, 만약 CSV 파일 등을 pyarrow로 읽어올 때 index를 보존한다면 위 Column Data로 들어오게 된다.
따라서, 가끔씩 __index_level_0__ Column을 남겨 놓고 Pandas로 변환한 이후 다시 Pyarrow Dataset으로 변환시키면 Error가 뜨는 경우가 있는데, 에러 내용을 보면 __index_level_0__ 가 중복된다는 것이다
즉, Index는 하나만 존재해야 내가 Index 표기를 할 수 있는데, 다른 값을 지닌 Index가 2개 있으니 어떤 Column을 Index로 설정할지 모르겠다는 에러 의미를 지닌다.
Pyarrow to Pandas
위에서 말했듯, Pyarrow의 Dataset은 "변경이 불가"한 데이터이다.
즉, Data를 변경시키기 위해는 pandas 데이터로 변경시킬 필요가 있다.
다행히 Pyarrow Dataset은 Pandas로 변환할 수 있는 메서드를 가지고 있다.
바로 .to_pandas()이다.
pyarrow Data에 그냥 .to_pandas()만 붙여주면 바로 Pandas 데이터로 변경 가능하다.
오히려 Pandas to Pyarrow Dataset이 조금 복잡하다.
과정은 아래와 같다.
import datasets.arrow_dataset as da로 라이브러리 Importda.Dataset.from_pandas(Pandas 데이터)
참고로, 위 과정은 Pyarrow의 Dataset Source Code를 읽고 이해한 것으로써, 정확한 과정을 알고 싶다면 Source Code를 읽어 보는 것을 추천한다.
(Huggingface와 비슷하게 꽤 괴랄한 Source Code를 가지고 있다)
느낀 점
Wandb상에도 분명히 점수 향상이 있었던 것 같고, f1도 괜찮았던거 같은데 그냥 roberta-large 보다 Public 점수가 1~2점이 떨어지니 사실 좌절감이 조금 드는 하루였다.
하... 어떻게 해야 점수가 오를까 많은 생각이 드는 하루다.
내일은 Hyperparmaeter 깎으면서 대회 마지막날을 대비해야겠다.
