오늘 할 것
- HyperParameter Tuning
- Batch-Size
- Decay 증가
- leraning rate
- () 지우기
오늘 한 것
HyperParameter Tuning
Batch Size
최근 모델에는 Batch Size를 크게 하는 것이 좋다고 하여 Batch Size를 증가시켰다.
그런데, Batch Size를 16보다 크게 설정하면 OOM 에러가 발생하는 것을 알 수 있었다.
따라서, Gradient Accumulation을 활용해 총 4번 Gradient값을 축적하여 Batch Size가 64인 실험과 매우 유사하게 진행되도록 하였다.
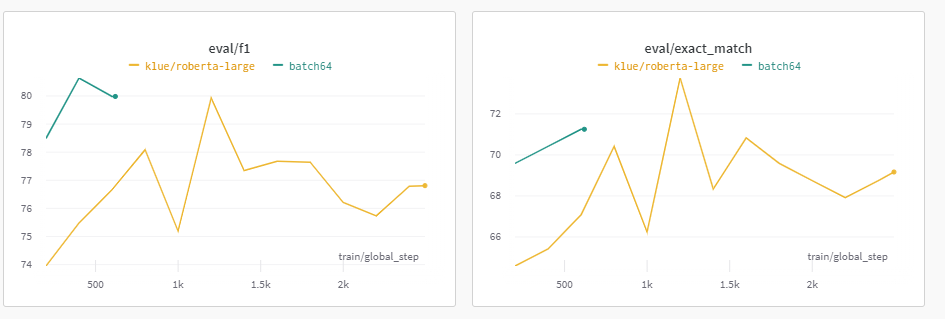
먼저, Batch Size를 키웠으니 Step은 당연히 작아질 것이다.
EM적으로는 점수가 높지 않지만, F1 점수가 상당히 높았기 때문에 한 번 제출해보았고, Public에서 EM이 떨어져서 Batch Size는 16으로 설정하였다.
Decay
현재 이 모델의 문제는 Overfitting이라고 생각하였다. 따라서, Weight Decay 값을 증가시켜 Regularization을 시켜주면 더 좋지 않을까라는 생각이 들었다.

하지만, Wandb상 EM과 f1 모두 떨어져 0.01 값이 최적 값이라고 판단하였다.
learning rate
learning rate를 0.0001로 키우는 상황에서도 실험하고, 0.00001로 작게 하여 실험을 해보았다.

learning rate를 키웠을 때는 결과가 나빴지만, learning rate를 작게 했을 때는 살짝 더 높은 EM 점수를 보이며 f1도 더욱 좋아짐을 볼 수 있었다.
하지만, 내일이 마지막 날이라 제출 횟수도 제한되어 있고, 이정도 점수 향상은 오히려 제출했을 때 점수가 떨어졌기 때문에 제출해보진 않았다.
() 지우기
수행 이유
내가 생성한 모델이 답을 "트랜스포머(Transformer)"라고 유추하여 EM이 틀린 Case가 많았다.
이번 Task에서 "트랜스포머", "Transformer"만 정답처리가 된다고 하여 생각이 들었다.
처음부터 "트랜스포머"라는 답만 반환하도록 모델을 학습시키면 어떨까?
따라서, Train Data 모든 부분에 괄호 부분을 없에 "트랜스포머"라는 답을 도출하도록 학습을 진행하였다.
수행 결과
Wandb상 그래프를 실수로 지워서 그래프로 비교하지는 못했다.
Wandb상 그래프에서 klue/roberta-large Model과 매우 유사한 EM 점수를 내서 제출하였다.
하지만 Public에서 점수는 떨어져서 결국 포기했다.
느낀 점
사실 Public 데이터가 모든 수행 결과에서 다 떨어지니 살짝 좌절감이 들었다.
그래도 이번 대회에서 내가 생각했던 모든 부분에 대해 실험을 진행한 것 같아 어느정도 만족했던 대회였던 것 같다
