Abstract
용어 정리
- Representation : 원시 Data를 Feature Vector로 Mapping 시키는 것
- Pre-training : 주어진 Data 및 Task에 맞춰 Model을 학습시키기 이전, 다른 Data를 활용하여 먼저 학습을 시키는 것
Fine-tuning
- 기존에 학습되어져 있는 모델(Pretrained Model)을 기반으로 Architecture를 새로운 목적에 맞게 변형하고, 이미 학습된 모델의 가중치를 미세하게 조정하여 학습시키는 방법
- BERT에서 생각해보자면, 먼저 학습 Data가 아닌 외부 Data를 활용하여 BERT Model을 학습시키고, 이렇게 만들어진 Pretrained Model을 Fine-tuning을 활용하여 내가 원하는 Task에 적절한 Parameter 값을 가지도록 미세 조정시키는 것이다.
- Fine Tuning 전략
- Strategy 1 : 모델 전체를 새로 학습
- Strategy 2 : 모델 중 아랫 Layer는 고정(Freezing) & 모델의 윗 Layer와 Classifier만 새로 학습
- 아랫 Layer : Input Data가 Model에 Feed되는 부분과 가까운 Layer(Block)
- Strategy 3 : Pretrained Model 전체를 고정(Freezing) & Classifier만 새로 학습
- 사실상 Classifier만 학습시키기 때문에 Fine tuning이 아니라고 하는 시각도 존재
- 상황에 맞는 Fine-tuning 전략 활용
- Case 1 : 크기가 크고 (선행 학습 때 활용했던 Datset과) 유사성이 작은 Dataset
- Strategy 1 활용
- Case 2 : 크기와 유사성이 큰 Dataset
- Strategy 2 활용
- Case 3 : 크기와 유사성이 모두 작은 DataSet
- 가장 문제가 되는 Case
- 일단은 그나마 Strategy 2를 활용
- 하지만, Data Augmentation 등의 방법을 활용하는 것이 더 좋은 성능을 이끌어냄
- Case 4 : 크기는 작지만 유사성이 높은 DataSet
- Strategy 3 활용
- Case 1 : 크기가 크고 (선행 학습 때 활용했던 Datset과) 유사성이 작은 Dataset
- 주의할 점 : FC Layer(Classifier)도 어느 정도는 학습이 완료되어 있는 상태에서 Pretrained Model에 붙여 활용해야 함
- Image Classification Competition에서도 이런 방식을 활용했어야 함
- Classifier가 학습되지 않은 상태에서 Pretrained Model에 바로 붙여 학습을 진행한다면, Pretrained Model의 Parameter도 큰 값으로 변환되기 때문에 적절한 Transfer Learning이 수행된다고 말할 수 없고, 적절한 Fine tuning 방식도 아님
- 참조 사이트 : https://inhovation97.tistory.com/31
BERT
- Bidirectional Encoder Representations from Transforms
- 모든 Layer에서 왼쪽과 오른쪽 Context를 동시에 활용하여 Unlabel된 Text로부터 pretrain하도록 디자인 된 Model
- 중요한 부분 : 양방향으로 학습이 진행됨
- Output Layer 1개만 추가시켜 여러 Task의 SOTA Model로 Fine-tuning 시킬 수 있음
- Architecture 구조 없이 Classifier만 추가시켜 원하는 Task Model로 변경 가능
- 거의 모든 Case에서 SOTA Model을 형성하는 매우 좋은 방식이라는 것을 알리고 있음
Introduction
BERT 이전 NLP
- Language Model Pre-training은 여러 NLP Task의 성능을 향상시키는데 매우 좋음
- 대부분의 Task에서 성능을 향상시켜줌
- 기존 Pretrained Language Representation 적용 방식으로는 Feature-based, Fine-tuning 방식이 존재
- Feature-Based approach
- 대표적 모델 : ELMo
- 동음이의어가 같은 Vector를 가지는 Word2Vec이나 GloVe의 단점을 해결하기 위해 나옴
- 같은 표기의 단어라도 문맥에 따라 다르게 워드 임베딩을 하기 위하여, 전체 문장을 고려하여 Word Embedding을 수행하는 것
- 특정 Task를 수행하는 Network에 Pre-train Language representation을 추가적인 Feature로 제공
- ELMo Case : Corpus -> ELMO -> ELMO로 처리된 Data -> LSTM or GRU 같은 모델 -> 원하는 결과
- 2개의 Network를 붙여서 활용하는 것
- 대표적 모델 : ELMo
- Fine-tuning approach
- 대표적 모델 : OpenAI GPT-n
- Pretrained된 Parameter들을 Downstream Task 학습을 통해 조금씩 바꿔주는(Fine-tuning) 방식
- 특정 Task에 적합한 Parameter를 줄여 Pretrain
- 특정 Task에 적합한 Paraemter가 많으면, 특정 Task 이외의 목적으로 활용하기가 어려워짐
- Unlabel된 Text Corporus에서 Language Model을 Pretrain하고, 각 Task에 맞게 Fine-tuning
BERT 논문에서 제기하는 문제점
- Feature-Based나 Fine-tuning approach 같은 경우, Pretrain된 Representation에 대한 제한이 너무 많음
- 특히 Fine-tuning approach에서 이러한 제한이 부각됨
- 주요 제한 : N-gram 방식을 활용하기 때문에 Unidirectional으로 학습이 진행됨
- Pre-trainig을 위해 활용할 수 있는 Architecture 선택에 제한을 가지고 옴
- 예시 : GPT
GPT는 left-to-right Architecture를 활용했는데, 우측에 있는 정보를 활용하지 않고 Train을 진행한다.
다음 단어 예측 정도의 Task라면 큰 문제가 되지 않을 수도 있지만, Sentence-Level Task로 가면 말이 달라진다.
Sentence-Level Task를 수행할 때 Unidirectional 특징은 큰 위험성을 가지고 오고, 이런 위험성은 Fine-tuning을 적용하면서 더더욱 커진다.
(특히 QA 같은 양쪽 방향 맥락을 파악하는 문제에서는 이런 문제가 더욱 심각해진다)
이런 문제를 해결하기 위해서 GPT에 BiLSTM을 같이 활용하기도 했지만, 결국은 얕은 방향성밖에 적용될 수 없다.
BERT의 특징
- MLM(Maksed LM)을 활용하여 Unidirectional Limitation을 해결함
- Mask는 랜덤하게 수행됨
- 목적 : Mask 공간에 존재했던 원래 Vocabulary를 예측하는 것
- Left-to-right과는 다르게 MLM 방식은 양쪽 Context를 모두 활용하는 방식으로, Deep Bidirectional Transformer로 Pretrain을 가능하게 해줌
- Next Sentece Prediction을 활용
- Text-pair representation을 Pretrain시킬 수 있음
- 아래 자세히 설명
Related Work
- 위에 설명했던 ELMo나 GPT에 대한 설명 같다. BERT를 이해하기 위해 필수적인 설명은 없는 것 같으므로 설명은 생략한다.
BERT
Bert 소개
- 대표 framework : pre-training, fine-tuning
- pre-trainig : Unlabel된 Data로부터 train
- Fine-tuning : Pre-train된 Parameter 값으로 초기화한 다음, (Labeld Data를 활용하여) Parameter를 fine-tune시킴
- Pre-trained architecture와 Final downstream architecture 사이 Parameter 차이가 크지 않음
- 이유 : 다양한 Task에 대한 Architecture를 합쳤다는 Bert의 독특한 특성 때문
Model 구조
- Multi-layer bidrirectional Transformer의 Encoder를 활용
- BERT의 풀네임에 모두 나와 있음
- Bidirectional Encoder Representations from Transforms
- L : Transformer Blocks 개수
A : Self-attention Head 개수
H : Hidden size - : L = 12, H = 768, A = 12
- Total Parameters : 110M
- Comparsion 목적의 OpenAI GPT와 동일한 Model Size를 가짐
- : L = 24, H = 1024, A = 16
- Total Parameters : 340M
- comparisoin 목적의 OpenAI GPT와 동일한 model size를 가짐
Input/Output Representation
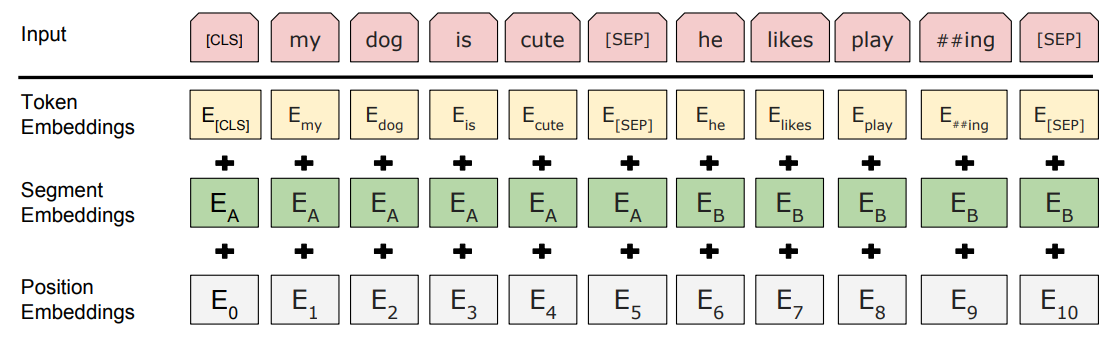
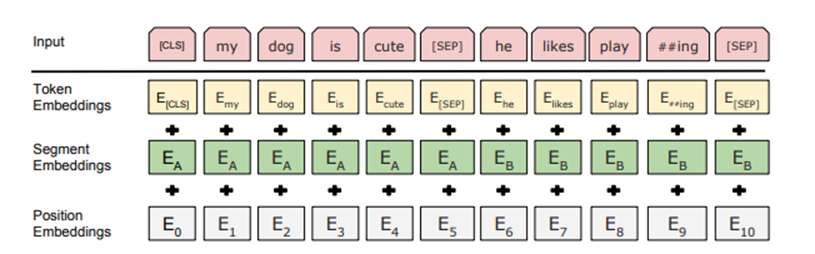
- 초기 Token : WordPiece Embeddings를 활용
- Corpus를 Word Embedding 시킨 Algorithm
- Input의 첫 부분 : [CLS]로 표시
- Sentence Pair를 한 Sequence로 묶어 Input으로 넣어 줌
- 2개 방법으로 Sequence에 존재하는 Sentence를 구분함
- [SEP] 기호를 활용해 구분
- A, B Sentence 중 어느 Sentence에 속해있는지를 나타내는 token을 붙임
- 학습된 embedding을 추가하는 방식
- Segment Embeddings
- 위와 같은 방식으로 만들어진 Token에 Segment Embeddings와 Position Embeddings 값을 더해주어 최종적인 (BERT Model에 들어갈) Input Data를 생성함
Pre-trainig BERT
Task1 : Maksed LM(MLM)
-
이전에는 Bidirectional Model을 활용하지 못한 이유
기존에 존재하던 Model은 Text의 왼쪽에서 오른쪽으로 또는 오른쪽에서 왼쪽으로만 훈련될 수 있다(Unidirectional)
양방향 학습(Bidirectional)은 각 단어가 간접적으로 "자신을 볼 수 있게 하고", 이에 따라 대상 단어를 3중으로 예측할 수 있기 때문이다. -
단어가 간접적으로 "자신을 볼 수 있다는" 의미는 무엇이죠?
- https://stats.stackexchange.com/questions/438072/why-cant-standard-conditional-language-models-be-trained-left-to-right-and-ri
- 간단히 말하자면, Ouput을 도출하기 위해 이미 Output을 참조하는 상황이 발생하여 예측을 하기 위해 예측값을 활용하는, 3중 예측이 진행 될 수 있다는 의미
- 예를 들어 보자. "I drink coffee"를 학습한다고 가정하자. 만약 Bidirectional하게 학습이 진행된다고 가정하자. 그렇다면, 왼쪽에서 오른쪽으로 가는 학습에는 아무 문제가 없을 것이다.
문제는 오른쪽에서 왼쪽으로 가는 학습에서 발생한다. 알고 있듯이 RNN 계열은 모두 동일한 모델을 활용하게 된다. 즉, 위 학습에서 "다음 단어"를 예측하는 모델을 학습했기 때문에 역 방향에도 똑같은 반환 값을 낼 것이다. drink라는 단어를 Model의 Input으로 넣게 되면 coffee를 예측하게 될 것이다. 문제는 오른쪽에서 왼쪽으로 학습이 진행된다면 이전 과정에서 coffee라는 값이 Model의 Hidden State에 들어가 있는 상태라는 것이다.
즉, coffee를 예측하기 위한 Model에서 coffee라는 값을 활용하여 예측하기 때문에 3중 예측이 진행될 수 있는 문제점이 발생하게 되는 것이다.
-
MLM : 위 문제를 해결하기 위해 BERT에 도입된 개념
- Percentage를 정하고, 이 확률에 의해 input token을 Random하게 Mask를 씌운다. 이후, Transformer 중 Encoder 구조에 넣어 주변 단어의 Context를 활용해 Mask된 단어를 예측하는 업무를 수행시키는 것이다.
- 단어를 일부러 가린다음(숨긴 다음) 가려진 단어를 예측하는 업무를 수행
-
GPT도 Transformer 구조를 활용하는데 왜 Bidirectional을 생각하지 못했을까?
- GPT는 Transformer 중 Decoder 구조를 활용한다. Transformer를 공부했으면 알겠지만, Decoder는 미래 Data에 대해 Masking을 진행하여 미래 Data를 활용하지 못하도록 사전에 막아 놓는다. 따라서, GPT는 Unidirectional한 Model이 된다.
- BERT는 이름에서도 나와 있듯 Transformer 중 Encoder 구조를 활용한다. Encoder의 Self-Attetnion 과정에서는 단어 위치에 관계 없이 모든 단어와 연산이 진행되므로, Bidirectional한 Model이 된다.
-
주의점 : [MASK]를 활용하면 Pretrain의 성능을 올릴 수 있지만, pretrain과 fine-tuning 과정에서 mismatch가 발생할 수 있음
- 이유 : [MASK]라는 것은 fine-tuning에서는 활용하지 않음
- Fine-tuning 시에는 Label이 존재하는 Text Data를 활용하고, [MASK]를 활용하여 일부러 단어를 가리지 않는다.
- 즉, Pretrain 때는 [MASK]를 활용하고 Fine-tuning 시에는 활용하지 않으므로 이런 구조적 차이에 의해 Mismatch가 발생할 가능성이 생김
-
위 주의점 해결법
- [MASK]로 바꿔주는 단어의 비율을 약 15%정도로 맞춤
- 15%보다 낮음 : Train이 Expensive하여 학습 효율이 떨어짐(아래 Appendix에도 나오지만, 결국 학습을 위해 우리가 활용할 수 있는 단어는 전체 단어의 15%밖에 없어서 Expensive한데, 이보다 낮으면 더 비싸짐)
- 15%보다 높음 : Capture Context가 충분하지 않음
- Pretrain을 수행할 때, [MASK]로 숨겨진 단어를 80%는 Mask를 씌운 상태에서, 10%는 [MASK]가 아닌 랜덤한 단어로 변경한 상태에서, 10%는 원래 단어인 상태로 학습을 수행함
- (ex) my dog is hairy라는 Unlabel Sentence에 대하여 Pretrain을 수행한다고 가정하자. 그리고, [MASK]시킬 단어로 hairy가 뽑혔다고 가정하자.
먼저, Epoch의 80%는 my dog is [MASK]의 문장으로 BERT Model이 수행된다.
그리고 Epoch 중 10%는 my dog is apple의 문장으로 BERT Model이 수행된다(apple이 아닌 다른 Random한 단어여도 됨)
마지막 10%는 my dog is hairy라는 원래 단어로 BERT Model에 통과시키는 것이다.
- (ex) my dog is hairy라는 Unlabel Sentence에 대하여 Pretrain을 수행한다고 가정하자. 그리고, [MASK]시킬 단어로 hairy가 뽑혔다고 가정하자.
Next Sentence Prediction(NSP)
- Sentence 사이의 (선후) 관계를 파악하는 목적으로 Train시키기 위한 방법
- QA나 NLI같은 선후 관계가 중요한 Task의 Model을 학습시킬 때 유용하게 활용됨
- 5:5 비율로 IsNext 문장쌍과 NotNext 문장쌍을 만들고 이를 BERT Model의 Input Data로 활용하여 학습시키는 것
- (A,B) 문장쌍을 만든다고 가정하자
- IsNext : 실제로 문단에서 A sentence 다음 B sentence가 나오는 (A,B) Pair
- NotNext : 랜덤하게 추출된 두 문장으로 만든 (A,B) Pair. 즉, A와 B는 선후 관계가 존재하지 않음
- (A,B) 문장쌍을 만들고, Label을 IsNext 혹은 NotNext로 지정하여 학습을 진행시킴
Pre-trainig data
- 이전에 존재했던 Model과 매우 유사
- BERT_ENGLISH : BooksCorpus와 English Wikidepida를 활용
- text passage만 추출해 활용함
- 이유 : Long contiguous sequence만을 학습시키고 싶었기 때문
Fine-tuning BERT
- BERT가 적절한 입력과 출력을 내주기 때문에 미세 조정이 간단함
- 아래 실험에서 보면 알겠지만, [CLS]에서 반환하는 Class Label을 활용하는 등 Bert Model의 Ouptut을 Classifier에 통과시키는 형식으로 Model이 형성됨
Experiments
11 NLP Task에 대하여 fine-tuning을 시켜 결과를 확인해봤다.
GLUE
- 연산 방법 : [CLS]의 Input를 Model에 통과시켜 반환되는 C Vector를 활용
- 연산을 통해 Classification loss를 계산하였음
- 결과 : 모든 Task에 대하여 SOTA를 달성
- 주목할 점 : 데이터 크기가 작아도 Fine-tuning 때 좋은 성능을 냈음
SQuAD
- Task : 질문과 질문에 대한 답이 포함된 지문이 있을 때, Substring을 찾는 것
- Input Data
- Question은 A Embedding, 지문은 B Embedding을 활용하여 Embedding 시킴
- 2 Embedding Vector를 Single Packed Sequence로 묶어 Input Data로 넣어줌
- 연산 방법
- 지문 중 정답이 되는 Start 부분과 End 부분을 활용
- Start Vector : S, End Vector : E를 Fine-tuning 과정에서 찾도록 학습시킴
- S Vector를 지문의 각 Token들과 dot product시켜 Substring을 찾는 학습을 진행
- 결과 : 기존의 모든 시스템보다 큰 폭의 차이를 두고 좋은 성능을 냄
- 특히, 를 활용했을 때 성능이 좋았음
SWAG
- Task : 앞 문장이 주어지고 보기로 주어지는 4문장 중 가장 잘 이어지는 문장을 찾는 것
- Input Data
- 앞 문장과 뒷 문장 후보들을 합쳐 총 4개의 Input Sequence를 구현
- 연산 방법
- Task-spcific한 Parameter를 학습시킴
- 4개의 Input Sequence의 [CLS] Input에 대한 Output 와 위에서 구한 Task-specific Parameter를 Dot product 시킨 후, softmax를 통과시킴
- 결과 : 사람보다 좋은 성능을 가지게 됨.
- 물론, SOTA를 달성
Abalation Studies
Pre-trainig Task의 영향
- MLM & No NSP
- LTR & No NSP
- LTR: Left-context-only model
- Left-to-right Model
- BiLSTM을 활용하여 양방향성을 (Shallow하더라도) 적용시키려고 노력했음
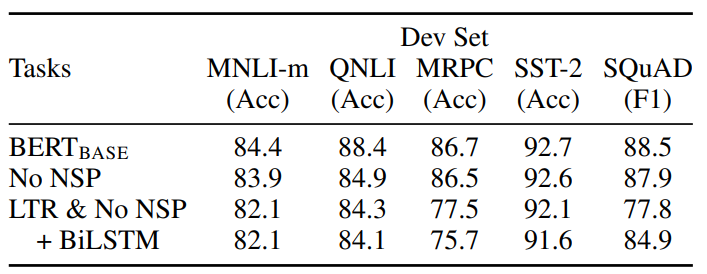
- 실험 결과
- 와 No NSP를 비교하면, SQuAD 같은 문장의 순서가 중요한 Task에선 NSP가 매우 큰 성능 향상을 가져다 준다는 것을 알았다
- LTR과 MLM의 결과를 보면, 아무리 BiLSTM을 적용했더라도 Bidirectional 특성을 Deep하게 적용할 수 있는 MLM이 우수한 성능을 낼 수 있음을 알 수 있다
Model Size 영향
- GLUE task 기준으로 Accuracy 측정
- 용어 설명
- L : Transformer Blocks 개수
A : Self-attention Head 개수
H : Hidden size
- L : Transformer Blocks 개수
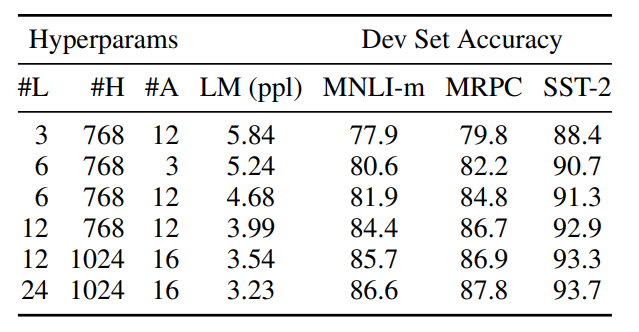
- PPL
- LM(Language Model)의 평가 방식
- LM을 활용하여 Test Sentence에 대한 확률(Likelihood)를 구하고, PPL 수식에 넣어 성능을 측정
- 수식 : 확률을 Sentence 길이에 대해 Normalization
- Normalization : 기하 평균 활용
- PPL(W) =
- W : 문장, L : 문장 길이, : i번째 단어
- Test Sentence에 대한 확률(P()이 높을수록 좋은 LM이다. 즉, PPL이 작을 수록 좋은 LM이 된다
- 실험 결과
- 모델이 커질수록 정확도가 상승함
- Large-scale task(번역, language modeling)은 모델 사이즈가 클수록 성능이 상승함
Feature-Based Approach with BERT
- 지금까지 설명한 BERT는 Pre training을 진행하고 Classifier를 학습시키는 방법을 활용
- ELMo와 같이 Feature Based Approach로도 BERT를 활용 가능하다.
- Feature Based Apporach 이점
- 모든 Task는 Transformer Encoder 구조로 표현되기 쉽지 않다. 따라서, 특정 NLP Task-Specific Model 구조를 활용할 수 있다
- Computational Benefit을 얻을 수 있음
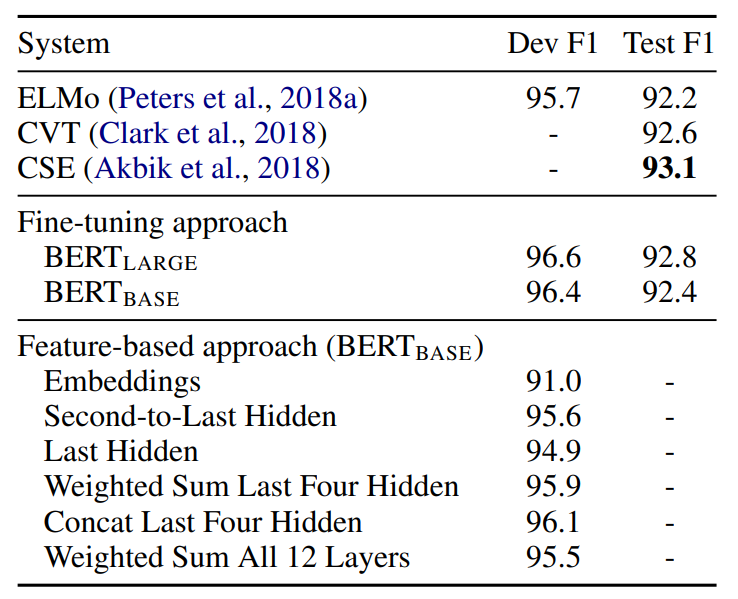
- 실험 결과
- Fine-tuning approach와 Feature-based approach의 결과가 큰 차이를 보이지 않음
- Fine-tuning, Feature-Based 모두 효과적임
원래라면 아래 나오는 Abalation Studeis는 Appendix에 나와야 한다. 하지만, 이런 제한 실험 같은 경우 한꺼번에 표현하는 것이 더 읽기 좋다고 생각하여 약간 순서를 끌어 올렸다.
Training Step
- Q&A 형식으로 의문을 해결
- Q1 : BERT는 정말 Pre trainig을 많이 시킬수록 Fine-tuning Accuracy가 높아지나요?
- A : 네, 그렇습니다. 같은 경우 (MNLI에서) 1%의 추가적인 Accuracy 상승을 보였습니다
- Q2 : MLM Pre-training은 LTR Pre-training보다 수렴 속도가 느릴까요?
- 수렴 속도가 느린 이유 : LTR은 Sentence에 존재하는 모든 단어에 대해 Predict 연산을 수행하지만, MLM은 오직 15%의 단어에 대해서만 Predict 연산을 수행하기 때문
- LTR은 왼쪽->오른쪽 방향으로 모든 단어에 대해 연산이 수행되지만, 위에서 말했듯 MLM은 15%의 단어만 [MASK]로 가리고, [MASK]라는 단어가 실제 어떤 단어일지 예측하는 연산만 수행하기 때문
- A : 네. 실제로 MLM은 수렴 속도가 느립니다. 하지만, Absolute Accuracy 측면에서 MLM은 LTR model보다 (거의 즉시) 성능이 높아지기 때문에, MLM을 활용하는 것이 좋습니다.
Q2에 대한 실험
- 정말로 MLM은 수렴 속도가 느리지만, Step이 커지면 LR보다 성능이 좋아질까?
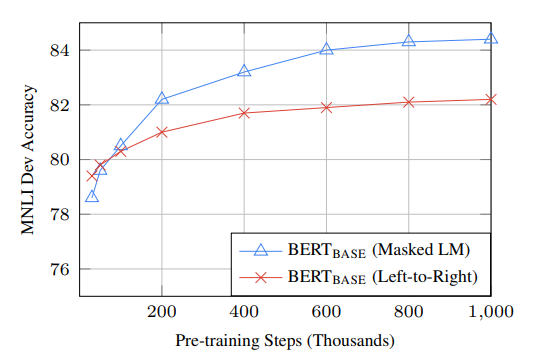
- 그래프 해석
- 먼저, 초기 단계(Step이 적은 시기)를 보면 LR의 Accuracy가 높음을 볼 수 있음
- 하지만, 200(Thousands)부터 확실히 MLM이 LR보다 Accuracy가 높아짐을 쉽게 확인 가능하다
- 즉, MLM은 Step이 적으면 15%만 활용하므로 수렴 속도가 느리지만(즉, Accuracy가 LR보다 작지만) Step을 증가시키면 LR보다 더욱 Accuracy가 높아진다
MLM을 수행할 때, 80:10:10 비율에 대한 실험
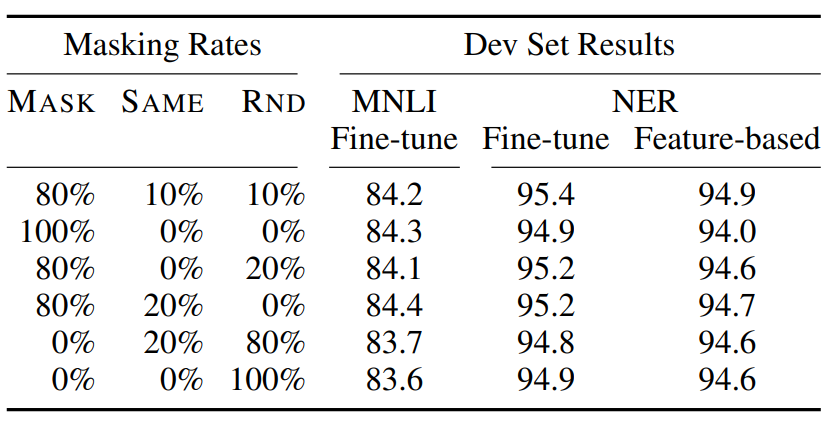
- 80:10:10이란?
- MLM을 설명할 때, Fine-tuning과 Pre-trained Architecture가 Mismatch되는 것을 막기 위해 활용한 기법
- 모르겠으면 MLM을 다시 보고 오자
- MASK : [MASK]로 변경, SAME : 원래 단어 활용, RND : 원래 단어 대신 랜덤한 다른 단어로 바꿈
- 실험 결과를 보면, 80%, 10%, 10%의 비율로 지정했을 때 가장 Accuarcy가 높아짐을 확인할 수 있다.
Conclusion
최근 여러 연구에 의해 Unsupervised pretraining은 많은 Language Understanding System의 필수 요소라는 것이 입증되고 있다.
BERT의 도입으로 Unsupervised Pretraining을 양방향 아키텍처로 수행하는 것이 더욱 일반화 될 것이며, 이 방법이 NLP 작업을 더욱 성공적으로 처리할 수 있게 도와줄 것이라고 기대한다.
Appendix
Pre-trainig Procedure
- 1 Batch당 256 Sequence를 활용
- 1 Sequence는 512 Token으로 이루어졌으므로, 1 Batch당 총 128,000 Token이 존재했음
- 1,000,000 step만큼 학습을 진행했음
- 3.3 billion word corpus를 40 Epoch 돌려 Train 시킨 것과 유사함
- 사용한 Optimizer : Adam
- Learning Rate : 1e-4
- : 0.9, : 0.999, L2 weight decay of 0.01
- 사용한 활성함수 : gelu
Fine-tuning procedure
- Dropout 확률 : 0.1로 고정시켰음
- Hyperparameter : Task에 따라 다양했음
- 일반적으로 Fine-tuning은 매우 빠르게 수행되므로, 많은 Hyperparameter에 대해 실험해보고 가장 적절한 값을 찾는 것 추천
- 활용한 Optimizer : Adam
- Large Data Set으로 Fine-tuning을 시도하면 Hyperparameter에 대하여 결과가 민감하지 않음
GPT와 BERT 차이
- 개념적 차이가 아닌, 실험 환경 차이를 서술
- 표를 활용한 두 Model 비교
| GPT | BERT | |
|---|---|---|
| Pre-train 때 활용된 Tken | BooksCorpus 활용 | BooksCorpus & Wikipedia 동시 활용 |
| [SEP], [CLS] | Fine-tuning 시에만 해당 개념을 도입 | Pre-trainig 과정에서도 활용됨 |
| 학습율 | 항상 동일한 학습율(5e-5) 활용 | Task 별로 다른 (Fine-tuning) Learning Rate 활용 |
성능 측정을 위해 수행한 Experiments
MLNI, QQP, QNLI, SST-2, CoLA, STS-B, MRPC, RTE, WNLI, SQuAD, NER
느낀점
일단 논문을 읽은 수가 별로 안되는데, 읽으면 읽을수록 도대체 어떻게 이런 방식들을 생각할 수 있을지 존경심이 드는 논문들밖에 없는 것 같다.
Appendix같은 경우 "부록" 개념이라고 생각하여 그렇게 큰 관심을 가지지 않았는데, 이번 논문을 읽으며 처음 Appendix부분도 집중해서 읽어봤다.
그리고 Appendix와 본문을 잘 번갈아가며 읽어야 논문의 이해가 빨라진다는 것을 알게 되었다.
특히 내가 이해하기 어려웠던 부분을 예시를 통해 설명한 부분을 읽고 살짝 현타(?)가 오기도 했다.
Q&A 형식으로 논문을 읽으며 발생할 수 있는 의문들에 대해서도 해결해준 점도 좋았다.
많은 멘토님들이나 마스터님들께서 말씀해주신 것처럼 Abstract부분과 Conclusion부분을 집중해서 읽었고, 본문을 읽는데 상당한 도움이 된 것 같아 다음에도 이런 방식으로 논문을 읽어봐야겠다고 생각했다.
BERT 개념 자체에 대한 생각은, (지금 읽었으니 쉽게 느껴지겠지만) MLM과 NSP같은 어렵지 않은 개념을 적용하여 매우 큰 성능을 올렸다는 것을 보이고, 실제로 실험을 통해 증명하는 것을 보며 존경심이 느껴졌다.
(도대체 어떻게 생각했을까...)
MLM을 읽으며 Label Smoothing의 Cutout이 생각났다. 다른 곳에서 활용하는 개념도 NLP적으로 해석하여 적용하면 큰 성능 향상을 이끌수도 있다는 생각이 들었다.
사진 및 내용 출처
BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
