Word2Vec에 대한 설명
Abstract
- Paper 목적 : 매우 많은 Datasets로부터 Continuous Vector Representations of Words를 계산하는 참신한 2개 Model 제안
- 이전까지의 모델은 많은 양의 Dataset을 활용하지 못했음을 유추할 수 있음
- 더 적은 계산을 수행하여 더 높은 Accuracy 향상을 이뤄냈음
- Syntatic과 Semantic적으로 단어간 유사성을 측정하는데에 있어 SOTA Performance를 찍음
- Syntatic : "문법적인" 유사성
- (ex) bigger - big : smaller - small 관계 파악
- Semantic : "의미적인" 유사성
- (ex) Paris와 France는 연관성이 존재함
- Syntatic : "문법적인" 유사성
Introduction
-
(논문이 나오기) 이전까지 많은 NLP System 및 technique들은 단어를 atmoic units로 다룸
- One-hot Vector를 통해 단어를 처리함
- 대표적인 예시 : BoW(Bag of Words), N-gram
- 장점 : Simplicity, Robustness
- 많은 양의 데이터를 활용해 학습한 간단한 모델이 적은 데이터로 복잡한 모델을 학습시킨 것보다 더 뛰어남
-
One-hot Vector 단어 처리의 단점
- 단어 간 연관성에 대해서는 표현하지 못함
- 오로지 Index를 통해서만 단어를 표기하기 때문
- BoW에서 모든 단어의 Euclidean Distance와 Cosine Similarity가 같음
- 많은 Task에 있어서 Limit이 존재함
- 데이터의 양에 대한 Limit이 존재함
- 단어 간 연관성에 대해서는 표현하지 못함
-
통계적인 방법을 이용하지 않고 기계학습을 활용하면서 Distributed Representations 개념이 떠오름
- 떠오른 이유 : 기계학습을 활용하며 복잡한 모델에 많은 DataSet을 먹여 학습을 더 많이 시켜주는 것이 가능해졌으며, 이는 이전 Simple Model들보다 성능이 좋았음
- 논문 저자들이 흥미롭게 보고, 이 논문에 활용했던 개념
- 분산 표현(Distributed Representation) : 단어의 의미를 다차원 공간에 벡터화하는 방법을 사용하는 것
- Word Embedding : 분산 표현을 활용하여 단어를 Vector로 표기하는 기법
- Embedding Vector : 분산 표현을 통해 표현된 단어 Vector
- 유사한 단어들을 Vector 공간에서 가까운 거리를 갖도록 표현
- G.E. Hinton, J.L. McClelland, D.E. Rumelhart. Distributed representations. In: Parallel distributed processing: Explorations in the microstructure of cognition. Volume 1: Foundations, MIT Press, 1986. 참조
Goals of the Paper
- 매우 큰 Dataset으로부터 높은 quality의 word vector를 학습하는 방법 소개
- Model의 높은 연산 정확도를 제공할 수 있는 Embedding Vector를 학습하는 구조에 대한 제안
- Word 사이의 유사성 뿐만이 아닌, 단어들이 multiple degrees of similarity를 갖도록 함
- Embedding Vector를 더하고 빼는 연산을 활용하여 다른 단어를 도출할 수 있음
- (ex) "King - Man + Woman" 연산으로 "Queen" 도출 가능
- Syntatic and semantic Regularities 모두를 측정하기 위해 새로운 Test Set을 만들었음
Previous Work
- 연속적인 Vector들의 단어 표현을 하고자 하는 것은 이번 논문이 처음이 아님
- 매우 유명한 모델 : NNLM
- 정확도나 성능 면에서는 장점을 가짐
- Computationally expensive한 단점을 가짐
- 이전까지의 모델 한계점
- 논문 상에는 Goals of the Paper 부분에 존재하지만, 이 부분으로 끌어오는 것이 더욱 자연스러울 것 같아 수정함
- 대규모 데이터를 학습할 수 있는 모델이 존재하지 않음
- Embedded Word Vector의 Dimension이 낮음
- 기존 Dimension : 50 ~ 100 정도
Model Architectures
- 기존 Model이 했던 시도
- N-gram : 통계 기반 모델링
- LDA, LSA : Continuous representations of words를 제안
- Topic Modeling
- 목표 : 주어진 문제의 추상적인 주제를 발견하는 것
- LSA(Latent Semantic Analysis)
- DTM(BoW의 확장판)의 잠재된(Latent) 의미를 이끌어내는 방법
- Truncated SVD 활용
- LDA(Latent Dirichlet Allocation)
- 가정 1 : 문서들은 Topic의 혼합으로 구성됨
- 가정 2 : Topic들은 확률 분포에 기반하여 단어를 생성함
- 문서 집합으로부터 어떤 Topic이 존재하는지 알아내는 방법
- 각 문서의 Topic 분포와 Topic에 대한 단어 분포를 이끌어내는 방법
- 단점 : 복잡도가 높아 Embedding Vector Dimension이 증가하고, 학습에 소요되는 시간이 길어짐
- DataSet이 많을수록 Accuracy는 높아졌지만, Expensive한 Model
- O(Training Complexity) 공식
- 실험을 위해 모든 Model은 Backpropagation & SGD를 활용하여 Train되었음
- E : Epoch
- T : Word(단어 개수)
- Q : Model 구조에 따라 달라지는 값
- E, T는 고정시키고 Q만 고려하여 Time Complexity를 계산하겠다
NNLM
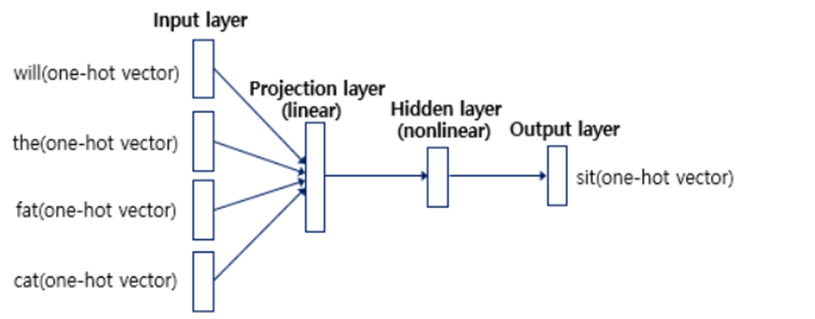
- 개념 : 현재보다 이전에 존재하는 N개의 단어를 활용하여 현재 단어를 예측하는 것
- NNLM 수행 과정
- N개의 이전 단어들이 One-Hot Vector 형식으로 들어옴
- 가중치 행렬 에 의하여 One-Hot Vector 단어들이 변환됨
- Projection Layer 원소를 구성 성분을 만드는 과정
- Lookup table : 와의 연산을 통해 만들어진 Vector
- Lookup table을 Concat시켜 Projection Layer를 형성
- One-hot Vector Dimension :
Shape :- V : Vocabulary 원소 개수
- Lookup table 1개의 Dimension은 가 될 것이며, Concat을 통해 Dimension의 Projection Layer가 형성됨
- One-hot Vector Dimension :
- 가중치 행렬 와 tanh를 활용하여 Projection Layer를 Hidden Layer로 변환시킴
- Shape :
- 와의 연산 이후 tanh(하이퍼볼릭탄젠트)함수를 Layer에 적용시켜줌
- Projection Layer는 Linear하지만, Hidden Layer는 NonLinear함을 주의하자(사진 참조)
- 수식 :
- Hidden Layer에 를 곱해주어 Output Layer를 형성
- 수식 :
- Shape :
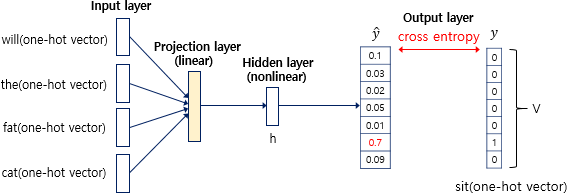
- argmax를 활용하여 현재 단어를 예측함
- Loss Function : CrossEntropy
-
NNLM의 Computational Complexity(Q만 계산)
- 유도
N개의 이전 단어들이 encode된다. 이 때 의 One-hot Vector와 행렬인 연산이 수행된다.
N번의 연산이 수행되어야 하므로 총 번의 연산이 수행된다.
Projection Layer->Hidden Layer로 가는데 총 번의 연산이 수행된다.
마지막으로, Hidden Layer->Output Layer로 가는데 총 번의 연산이 수행되기 때문에, 이 모든 값을 더한 것이 Q가 될 것이다. - Projection과 Hidden Layer 사이에 복잡한 연산이 수행됨
- 이유 : Projection Layer는 Dense Layer이기 때문
- 가장 Q에 영향을 많이 주는 Term :
사실은 연산(Hidden & Output Layer 사이 연산)의 부하가 가장 크다
하지만 Hierarchical softmax를 활용하면 로 연산량을 줄일 수 있고, 이렇게 연산량을 줄일 경우 가 가장 Q에 영향을 많이 주게 된다- 논문에 따르자면, Avoiding Normalized Models Completely by using models that are not normalized during trainig(Noramlize를 피하는 것)으로써 연산량을 줄일 수도 있다고 했지만, 가장 많이 활용하는 방법은 Hierarchical Softmax 연산의 활용이다
- 이유 : Huffman Binary tree로써 vocabulary를 표현해 Hierarchical softmax를 활용할 수 있고, Tree가 Balanced Binary Tree라면 의 Output이 필요하다.
- 유도
-
NNLM의 단점
- 고정된 길이의 입력(Fixed-length input)
- n-gram 언어 모델과 마찬가지로 다음 단어를 예측하기 위해 모든 이전 단어를 참고하는 것이 아니라 정해진 n개의 단어만을 참고할 수 있다
RNNLM
- NNLM의 한계를 극복하기 위해 제안됨
- RNN을 활용한 이유 : RNN은 이론적으로 더 복잡한 패턴을 다룰 수 있음
- NNLM과 달리 Projection Layer가 존재하지 않음
- 중간 과정을 거치지 않고 바로 Hidden Layer 생성
- 입력의 크기를 제한하지 않고 사용할 수 있음
- RNNLM의 Computational Complexity(Q만 계산)
- NNLM과 마찬가지로 V를 정도로 낮출 수 있으므로, 가장 높은 Complexity는 연산과 관련있다.
Parallel Training of Neural Networks
- DistBelief라고 불리는 큰 규모의 framework 기반으로 NNLM과 논문에서 제시한 모델들을 실행했음
- DistBelief : 구글의 첫번째 머신러닝 시스템
- 참고로, 두번째는 Tensorflow
- 그냥 Pytorch처럼 GPU마다 연산 나눠서 수행했다는 의미
- Adagrad, mini-batch 방식 활용
New Log-linear models
- 이전 Architecture를 통해 Neural Net이 매력적임을 알게 됨
- 단, 시간 복잡성을 줄여야 할 필요가 있음
- 계산 비용을 최소화하면서 Distributed Word Vector를 학습할 수 있는 2가지 모델 제안
- 대부분의 시간 복잡성은 Non-Linear Hidden Layer의 연산에서 발생함을 알 수 있었고, 이를 없애는 방식을 활용
- CBOW, Skip-gram
- Continous Word Vector를 간단한 모델로 학습시킨 뒤 N-gram NNLM을 그 위에서 학습 시킴
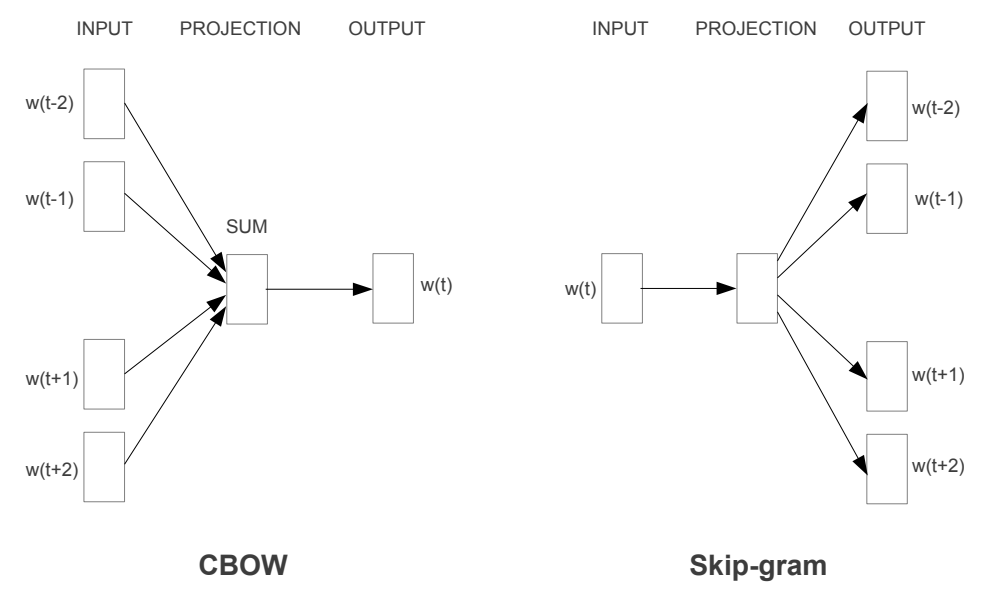
CBOW(Continuous Bag of words Model)
- https://velog.io/@idj7183/Word-Embedding#word2vec%EC%9D%B4%EB%9E%80
- 이전에 정리해놨던 CBOW 연산 과정
- Feedforward NNLM과 유사하지만, non-linear hidden Layer가 모두 제거되고 Projection Layer가 모든 단어들과 공유됨
- 전체 단어의 One-hot Vector에 가중치 행렬을 곱하고, 그 결과값을 모두 모아 평균을 구하면 Projection Layer를 만들 수 있음
- 단어의 순서가 Projection에 영향을 주지 않음
- CBOW의 Computational Complexity(Q만 계산)
Continuous Skip-gram Model
- 예측할 범위가 늘어나면 Quality도 늘어나지만, 대신 시간 복잡도가 늘어남
- 한 단어로 같은 문장 속 주위 단어들의 Classification을 Maximize하는 모델
- CBOW보다 Skip-gram이 더 성능이 좋다고 알려져 있음
- (단어 사이의) 거리가 멀수록 유사성이 떨어지기 때문에, 멀리 떨어져있는 단어는 train시 sampling을 덜 줘서 가중치를 작게 했음
- Skip-gram의 Computational Complexity(Q만 계산)
- C : maximum distance of words
- 수식 유도
[1,C) 범위에서 value R을 뽑아 현재 단어에서 R개 이전, R개 이후 단어를 모두 predict하는 것이 Skip-gram 방법이다.
1개 단어를 예측하는 것은 만큼의 Time Complexity를 가질 것이다(N = 1이므로)
이런 연산을 총 2R번 수행하게 될 것이다.
R의 평균 기댓값은 이고, 총 2R번 수행되므로 평균 수행 기댓값은 C번이다.
따라서, 가 유도된다.
Results
- 아주 단순한 대수적인 연산을 통해 두 단어의 Syntatic 및 Semantic적 유사성 측정이 가능
- (ex) Biggest - Big + samll를 Vector 연산을 수행하고, 이 연산 결과와 가장 거리가 가까운 단어를 찾으면 Smallest를 구할 수 있음
- 많은 양의 데이터로 High Dimensional Word Vector를 학습시키면, Vector들은 미묘한 의미저의 차이에 대한 응답도 수행할 수 있음
- Word Vector 간의 유사성 측정 정확도가 증가함
- NLP application의 성능을 향상시킬 수 있을 것으로 예측함
Task Description
- 5개 Type을 포함하는 Semantic quesition, 9개 type의 syntactic question에 대하여 test 진행
- 질문이 일어지는 단계
- 직접 유사한 단어 쌍 List를 작성
- 2개 단어쌍을 Connecting함으로써 많은 Question들을 형성했음
- Test Set에는 무조건 Single Token Word(New York같은 것은 제외)
- 유의어(동의어)로 예측하는 것은 틀린 것으로 봤음
- 100% 일치가 불가능하다는 것을 의미
- 특정 Application에서 Word Vector의 유용도는 Accuracy Metric와 양의 상관관계가 존재한다고 믿었음
Maimization of Accuracy
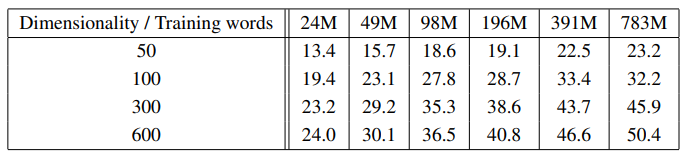
- 더 많은 데이터와 더 많은 Vector Dimension을 동시에 크게 설정하는 것이 좋음
- 한 쪽만 추가시키는 것은 어느 순간 개선성이 감소된다는 것을 알게 되었음
- 단어 임베딩 차원을 50 ~ 600차원까지 늘려보았을 때, 그리고 학습에 사용된 토큰 개수를 2400만 ~ 7억8천만개 까지 늘려보았을 때, 단어 임베딩 차원 수 및 데이터셋 크기를 늘릴 수록 정확도가 뚜렷하게 증가하는 경향이 관측됨
Comparision of Model Architectures
-
단어에 대한 제한을 주지 않았음 & 모든 Model의 Word Vector를 동일하게 하여 실험함
-
CBOW : Google News Data로 하루동안 Training
Skip-gram : 3일동안 Training -
CBOW, Skip-gram 모두 NNLM, RNNLM보다 의미론적, 문법론적 모두에서 우세한 성능 관측
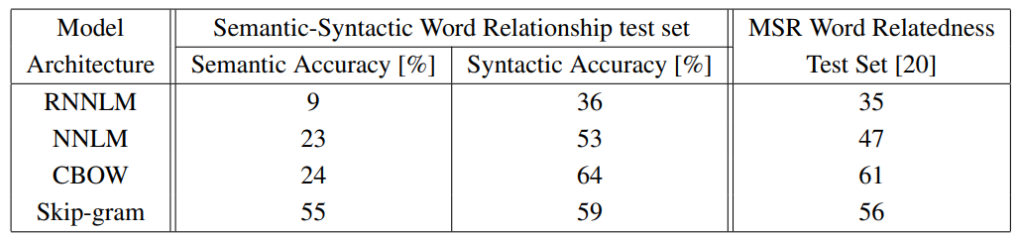
- NNLM보다 RNNLM의 성능이 떨어지는 이유
RNNLM의 Vector들은 비선형 Hidden Layer에 연결되므로(즉, Projection Layer라는 중간 단계가 없음)
- NNLM보다 RNNLM의 성능이 떨어지는 이유
-
학습 epoch를 3 epoch로 할 때와 1 epoch로 할 때, 같은 조건의 1 epoch는 시간이 훨씬 덜 걸리지만 정확도가 아주 크게 밀리지는 않았으며, 1 epoch로 벡터 차원을 늘린 경우 등에서는 3 epoch의 낮은 벡터 차원보다 전체 시간은 적게 소요되면서 정확도가 향상된 경우도 있었다.
-
분산 배치 학습을 진행하여 학습 복잡도의 한계를 더 많이 극복할 수 있었으며, 효율적인 CBOW, Skip-gram 방법론의 제시로 50~100 차원을 넘어 더 높은 차원의 임베딩에 도전해볼 수 있는 잠재력을 보여줌
Conclusion
CBOW와 skip-gram이라는 새로운 Word Embedding 학습 방법을 제안했다.
기존의 여러 model들에 비해 연산량이 현저히 적고, 간단한 model임에도 매우 높은 성능을 보였다.(뛰어난 Word Vector를 반환하도록 학습할 수 있었다)
특히, 연산 비용이 매우 작기 때문에, 큰 Dataset으로부터 high dimensional word를 정확하게 도출하는 것이 가능해졌다.
또한 Word Embedding vector의 Syntax, Semantic 성능을 측정할 수 있는 새로운 Test set을 제시했다.
마지막으로, 우리는 높은 Quality의 Word Vector들이 훗날 NLP 프로그램의 가장 중요한 Building Block이 될 것이라고 확신한다.
느낀점
사실 Word2Vec에 대한 공부보다 NNLM을 더 많이 공부한 것 같은 이상한 경험을 한 것 같다 ㅎㅎ....
처음 이 논문을 읽고 뭐에 대한 논문일지 궁금했었는데 Abstraction을 보고 혹시...? 싶었고 Introduction을 보고 Word2Vec에 대한 논문이라는 것을 알게 되었다. 우연이겠지만 내가 공부한 다음주에 해당 논문을 읽거나, 내가 논문을 읽은 다음 주에 해당 개념(BERT)를 배우는 등 좀 운이 따라주는 것 같다.
개념적으로만 알고 있던 내용인데 왜 도입되었고 어떤 이유로 도입되었는지 알아보면서 꽤 재밌게 읽었었던 것 같다. 앞으로, 논문을 읽을 때 그래도 개념 정도는 알고 읽으면 더 재밌게 읽을 수 있지 않을까 생각이 들어서, 다음엔 그렇게 논문을 읽어봐야겠다고 생각했다.
출처
https://wikidocs.net/45609
Efficient Estimation of Word Representations in Vector Space
