Interactive Visualization
Interactive Visualization이란?
- 지금까지 배웠던 정적인 Chart가 아닌, 내가 원하는 대로 Chart를 확대하거나 움직일 수 있게, 동적으로 Chart를 만드는 것
- 활용 이유
- 사람마다 원하는 그래프가 다를 수 있음
- Interaction을 통해 원하는 정보에 대한 그래프만 얻을 수 있음
- 장점 : 원하는 메시지를 압축해서 담을 수 있음
Interactive Library
-
Matplotlib
- Jupyter Notebook 환경 또는 Local에서만 활용 가능
- 다른 라이브러리들은 Web에 Deploy 가능하지만, Matplotlib은 불가
- mpld3를 활용하면 D3-based Viewr를 활용해 볼 수는 있으나 의미는 없음
-
Plotly
- 가장 많이 활용되는 Interacitve Library
- Python, R, JS에서도 제공
- 예시가 많고 문서화가 잘 되어 있음
- 다양한 시각화 기능 제공
- 웹에서 활용 가능
- 형광 Color 활용 가능
-
Plotly Express
- seaborn과 Plotly를 유사하게 만들어 문법을 쉽게 만든 Interactive Library
- Custom 부분이 부족함
- 다양한 함수 제공
- CPU가 많이 필요하므로 적절하게 활용해야 함
- Input Data type이 유연함
- List, Dict, Dataframe, GeoDataFrame 모두 가능
- seaborn 기능 다수 제공
- plotly 시각화 제공
- 3D animation 제공
-
Bokeh
- Matplotlib과 문법이 유사함
- 기본 Theme이 Plotly에 비해 깔끔함
- 문서화가 부족함
-
Altair
- Vega 라이브러리를 활용하여 만든 Interactive Visualization
- 문법이 Pythonic하지 않음
- Custom 자체가 깔끔하지 않음
- 다른 라이브러리들과 다르게 데이터 크기 제한(5000)이 존재
- Bar, Line, Scatter, Histogram에 특화되어 있음
- '+' 연산을 활용하여 시각화 차트를 배치하는 특징을 가짐
코드로 보는 Plotly Express
최근 많이 활용되는 Interactive Vsiaulization Library는 Plotly이다.
하지만, Plotly 공부는 시간이 오래 걸려 마스터님께서 짧은 시간 내에 설명할 수
없으셨다고 한다.
따라서, 일단 Plotly Express로 간단히 배운 이후,
나중에 Plotly를 따로 공부해보도록 하자- Plotly Express 설치 :
pip install plotly statsmodels - Plotly Express 모듈 다운 :
import plotly.express as px - Scatter Plot 그리기
- 일단 Scatter Plot 그리는 방법과 동일
- px.scatter로 plotly.express만 활용하면 됨
- 활용할 수 있는 Interactive
* zooming : 특정 부분 확대. 더블 클릭하면 기본 Chart 볼 수 있음- pan : 카메라 움직임. 차트를 움직일 수 있음
- 우측 상단에 존재하는 여러 개 Interact 활용 가능
- 마우스를 점 위에 올리면 해당 Data에 대한 정보 출력
fig = px.scatter({data}, x, y, size, color)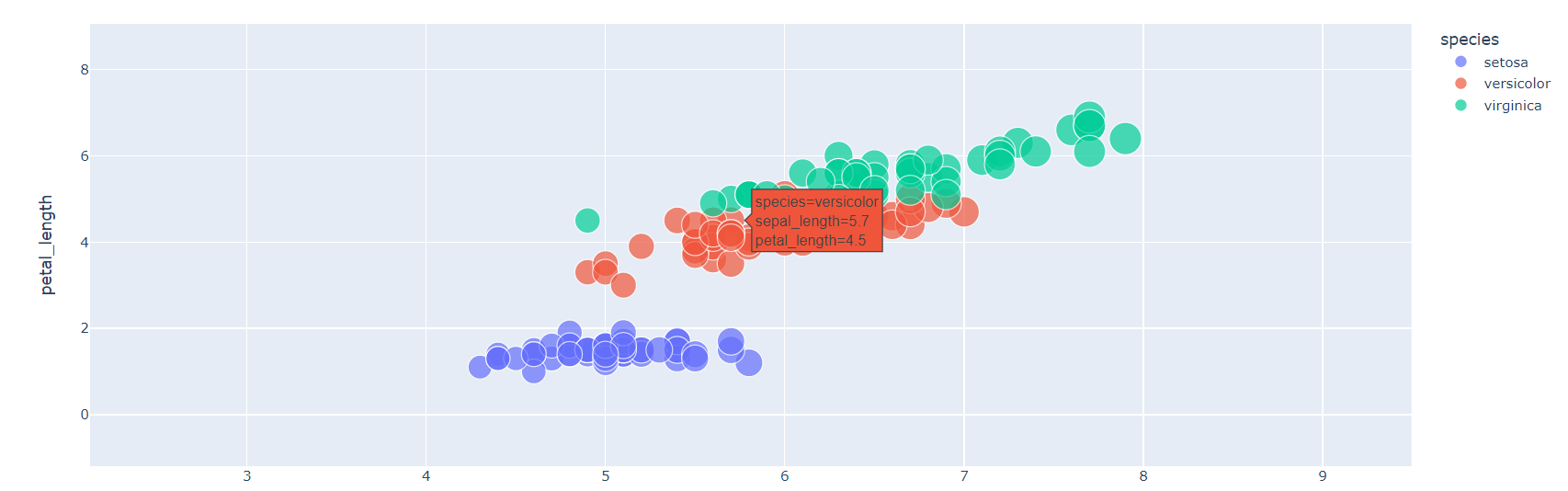
-
Scatter Plot의 여러 가지 Parameter
- range_x, range_y : 처음으로 보여줄 Default Chart의 x, y범위 설정
- marginal_x, marginal_y : 축으로 설정한 Feature에 대한 Data 분포를 볼 수 있음
fig = px.scatter(iris, x='sepal_length', y='petal_length', color='species', marginal_y="violin", marginal_x="box", ) fig.show()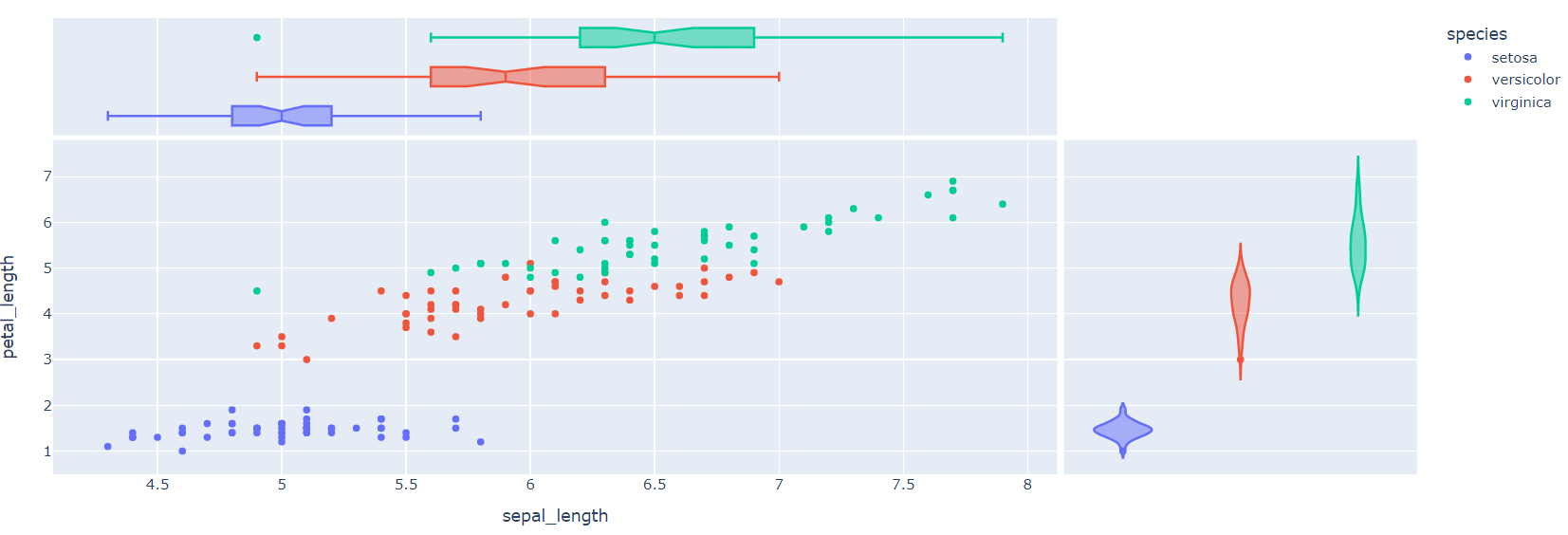
tradeline = 'ols': 회귀선을 그림- facet_col, facet_row : Feature값으로 설정하여 Facet Grid를 그릴 수 있음
- hover_data : 점에 마우스를 대면 볼 수 있는 Data Feature를 추가해 줄 수 있음
- hover_name : 점을 마우스를 댔을 때 보이는 창의 대표 이름으로 할 Feature 설정
fig = px.scatter(iris, x='sepal_length', y='petal_length', color='species', hover_data=['sepal_width', 'petal_width'], hover_name='species' ) fig.show()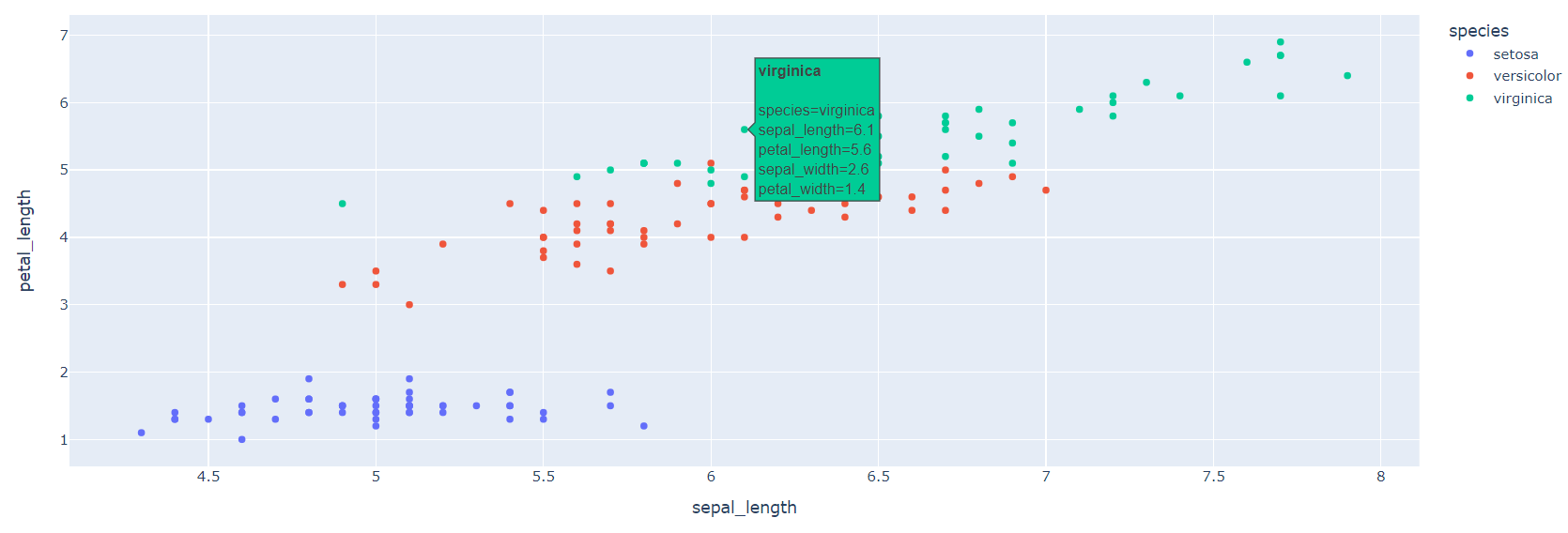
- 위 사진과 비교해봤을 때, virginica라는 특별한 이름이 생겼고, sepal_width와 petal_width Data가 추가되었음을 알 수 있다.
-
Bar Plot :
px.bar
Line Plot :px.line- Bar Plot은 기본적으로 Stacked Bar Plot으로 그리지만, interactive가 그렇게 유용하지는 않다. 속도는 느려지지만 Seaborn에 비해 큰 장점이 없기 때문에, 잘 활용하진 않는다.
-
Sunburst
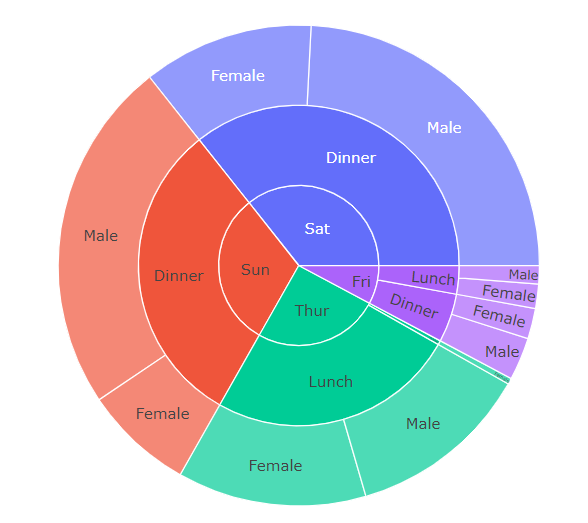
fig = px.sunburst({data}, path={우선순위 순서의 Feature List})fig = px.sunburst(tips, path=['day', 'time', 'sex'])
fig.show()
"""
path에 지정한 순서대로 Sunburst Chart를 그릴 것이다.
즉, day를 기준으로 Data를 나누고, 이렇게 나눠진 Data에 대해 또 time으로
나누는 식으로 SunBurst를 그리는 것이다.
"""
- treemap : 구현 방법은 Sunburst와 완전 동일하다
fig = px.treemap({data}, path={우선순위 순서의 Feature List})- Seaborn의 다양한 내용과 겹치므로, 나중에 필요할 때 공부하면 좋을 것들
- hist : histogram, density_heatmap
- kdeplot : density_contour
- boxplot : box
- violinplot : violin
- stripplot : strip
- heatmap : imshow
- pairplot : scatter_matrix
- Multidimensional
다차원 데이터를 시각화하는 방법론이다.
사실 3-Dimensional로 Data표현이 가능하지만, 그 부분은 생략하고
Multidimensional만 설명하는 이유는 아래와 같다.
(먼저 개인적인 생각임을 알고 있자...)
3-Dimensional Chart를 보면 생각보다 보기가 힘들다.
해당 Chart를 보고 든 생각은 '이럴거면 차라리 2-Dimensional Graph를
여러 개 그리겠다'라는 생각을 했다.
하지만, Multidimensional은 2차원 형태로 다차원 데이터를 시각화하기 때문에,
Feature간 연결성을 보기 더 편했던 것 같다.
예를 들어, A와 B Feature는 그렇게 관계는 없지만, A의 특정 Feature들이
C Feature에 큰 연관성을 가지고 있구나 라는 것을 잘 알아볼 수 있을 것 같았다.
따라서, 훗날 활용할 유용성을 비교해봤을 때 MultiDimensional은 조금 더 많이
활용할 수 있을 것이라고 생각했으므로, 이 부분을 조금 더 공부했다.-
parallel_coordinates : Feature에서의 데이터 분포를 한 줄로 표현하고, 동일한 Data를 줄로 연결하여 Pattern을 볼 수 있음
fig = px.parallel_coordinates(iris, color="species_id") fig.show() # iris : data # color : 지정한 Feature로 색을 나눠 Chart를 그림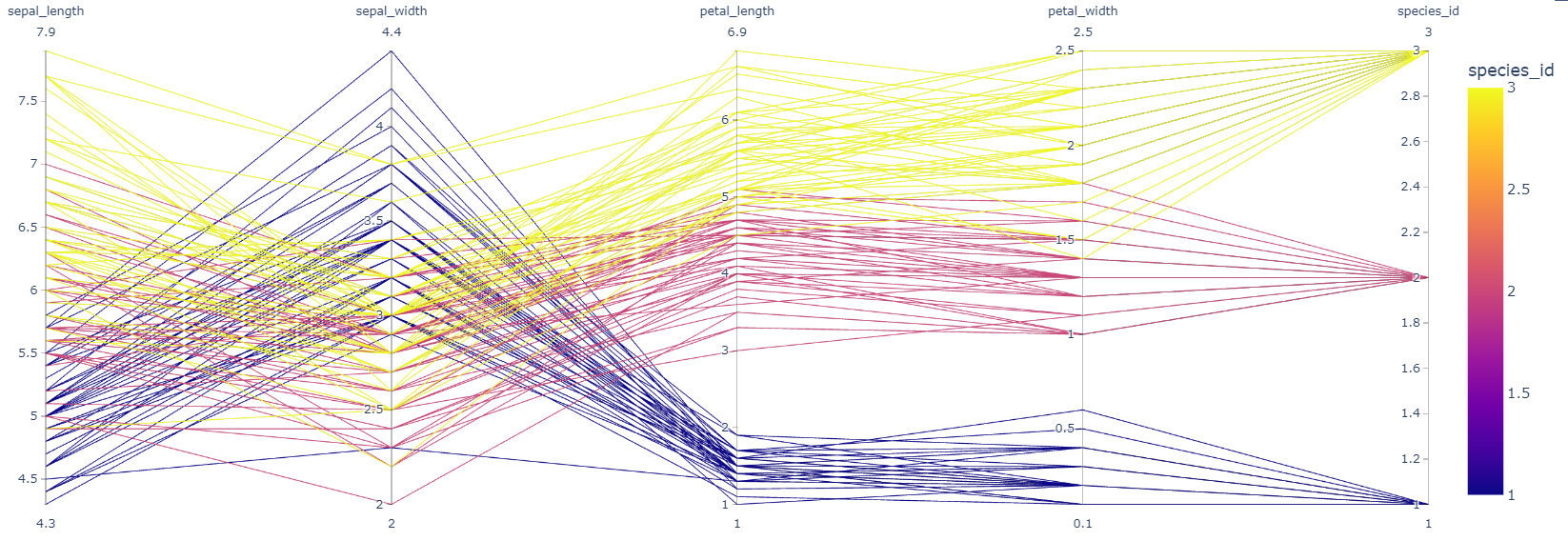
-
parallel_categories : 점주형 Data를 평행한 선으로 시각화
tips = px.data.tips() tips['sex'] = tips['sex'].apply(lambda x : 'red' if x=='Female' else 'gray') fig = px.parallel_categories(tips, color='sex') fig.show() # color : 지정한 Feature에 대해 그래프를 그림. # 이 때, 색을 지정해줌으로써(위에서는 apply로 바꿔줌) Chart 색 지정 가능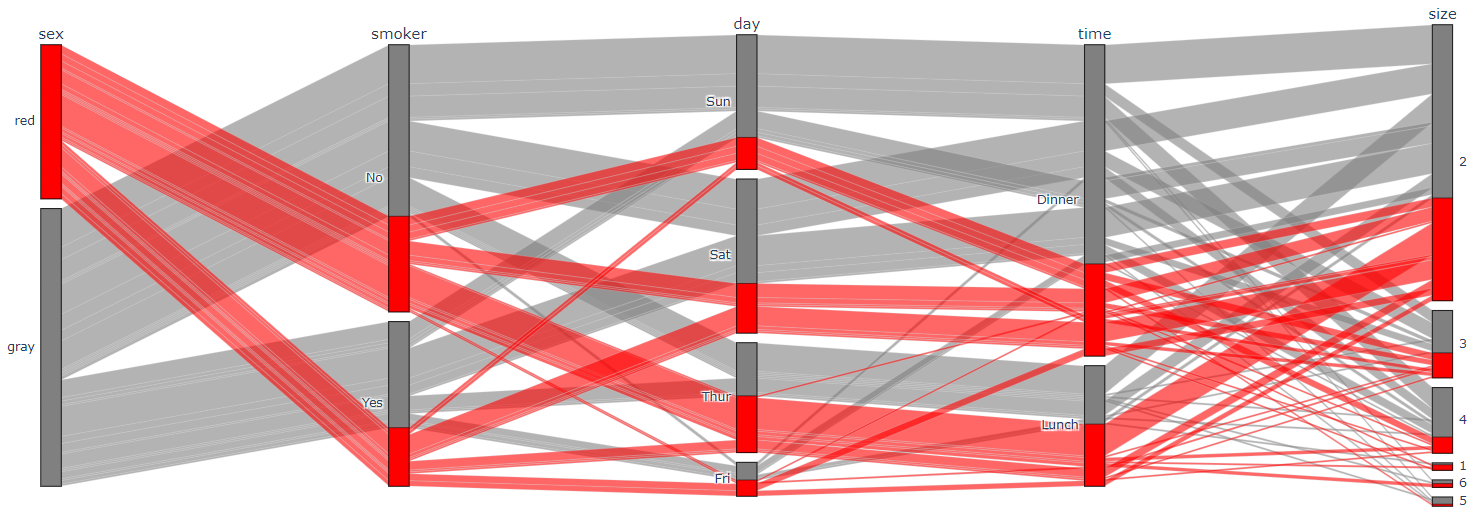
-
지리 데이터 시각화 방법에는
scatter_geo,choropleth가 존재한다는 것 정도만 알고 있자

개념부터 확실히!