Tensorboard
Tensorboard란?
학습 그래프, Metric, 학습 결과 시각화 지원하는 Tool로써, PyTorch와도 연동 가능한 DL 시각화의 핵심 도구이다.
- 표시 가능한 성질
- scalar : Metric 등 상수 값의 연속(Epoch의 진행에 따라) 표시
- graph : 모델의 Compuatational graph
- histogram : Weight 등 값의 분포 표현
- image(text) : 예측 값과 실제 값 비교 표시
- mesh : 3D 형태의 데이터를 표현하는 도구(잘 활용하지 않음)
Tensorboard 설치
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('{저장할 파일 이름}')
# 파일을 입력하지 않을 경우 Default dir 이름은 'runs'이다Tensorboard에 데이터 저장
writer.add_scalar('{그룹/변수명}', 변수, iter)- 단일 변수를 저장하는 방법
writer.add_scalars('{그룹/변수명}', 변수dict, iter)- 다중 변수를 저장하는 방법
- 한 그래프에 여러 변수를 한꺼번에 그림
writer.add_image('{그룹/변수명}', {Tensor or ndArray}, iter)- 단일 변수를 저장하는 방법
writer.add_text('{그룹/변수명}', {"Text"}, iter)- 단일 변수를 저장하는 방법
writer.add_historgram('{그룹/변수명}', {ndArray}, iter)- named_parameters에 대한 정보를 담는 방법(Weight 등에 관한 정보)
writer.add_hparams({hparam_dict}, {metric_dict})- 한 번의 Epoch마다 Scalar 값을 저장하여 Table 형태로 저장
- hparam_dict : Hyper Parameter와 관련된 Dict Data
- metric_dict : Metric에 관련된 Dict Data
- wrtier.flush()나 writer.close()를 통해 데이터 저장을 파일에 적용시켜야 함
Tensorboard 서버 활성화
tensorboard --logdir {Tensorboard Data를 저장한 파일 이름} --port=XXX
# port : Optional. Default로 6006으로 설정된다Tensorboard 서버 접근
# 방법 1 : 내가 Tensorboard를 CLI나 Visaul Studio Code에서 수행시켰다.
tensorboard --logdir {Tensorboard Data를 저장한 파일 이름} --port=XXX
localhost:[설정한 Port]
# 방법 2 : Jupyter나 Colab에서 바로 화면을 열고 싶다
%load_ext tensorboard // tensorboard extension을 Load함
%tensorboard --logdir {Tensorboard Data를 저장한 파일 이름} --port=XXXTensorboard 사용 시 주의점
만약 이전에 Tensorboard를 수행한 이후, 종료하지 않고 다른 이름을 가진 저장 데이터에 대한 그래프를 그릴 때, 이전에 그렸던 데이터도 동시에 출력되게 된다
예를 들어, train1, train2를 그린 이후 n1, n2를 새로 그리고 싶을 때, Tensorboard를 Reload시키는 것이 아닌 단순히 Load만 수행시킨다면 해당 Tensorboard는 train1, train2, n1, n2에 대해 모두 그래프를 그린다.
또한, 똑같은 Directory에 여러 가지의 Tensorboard 데이터를 저장하면, tensorboard를 Reload 시킨 후 추가된 데이터만 표시하는 것이 아닌, 저장된 모든 데이터에 대해 그래프를 그린다.
예를 들어, train1, train2를 그리고 Tensorboard를 종료시킨다. 이후 n1, n2에 대한 Tensorboard 데이터를 새로 저장하고 그래프를 그리면 train1, train2, n1, n2에 대한 그래프가 모두 출력된다
Model에 따라 당연히 개별의 그래프를 가져야 하기 때문에, 항상 "다른 디렉토리에" Tensorboard 데이터를 저장하고, 혹시 모르니 Tensorboard도 Reload시키는 방법을 활용하자
코드로 실습하는 Tensorboard 활용법
add_scalar : Scalar 데이터 그래프 그리기
logs="logs"
writer = SummaryWriter(logs)
for n_iter in range(10):
s1 = np.random.random()
s2 = np.random.random()
writer.add_scalar('Loss/train1', s1, n_iter)
writer.add_scalar('Loss/train2', s2, n_iter)
writer.flush()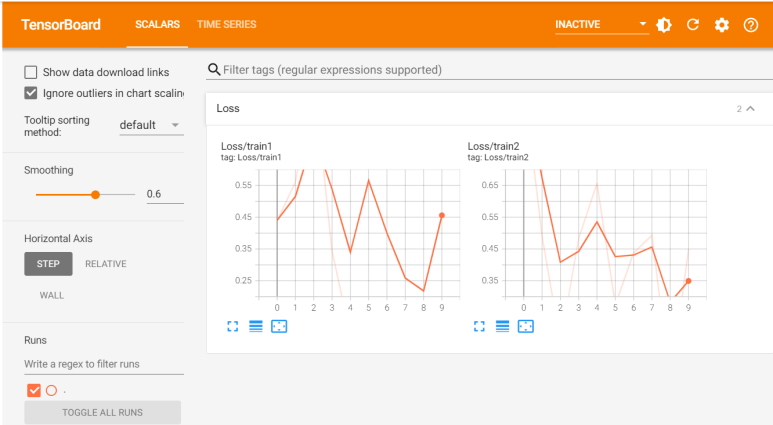
- Time Series : add_sclar 등으로 데이터를 저장할 때, Epoch이 시간의 흐름과 연관있다 판단할 경우 자동으로 생성함
add_scalars : Scalar 여러 개에 대한 그래프 한 공간에 동시에 그리기
logs = "logs"
writer = SummaryWriter(logs)
for n_iter in range(10):
s1 = np.random.random()
s2 = np.random.random()
dict = {'s1':s1, 's2':s2} // 항상 Dict Type으로 저장
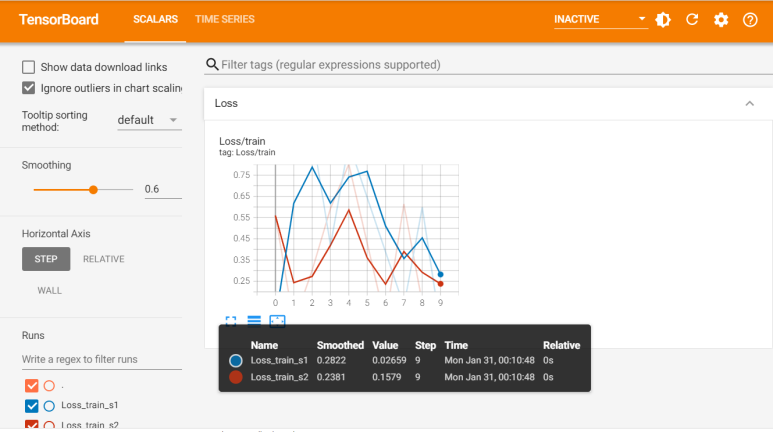
writer.add_scalars('Loss/train', dict, n_iter)
writer.flush()
"""
아래 그래프에서 파란색은 s1 data, 빨간색은 s2 data를 의미한다
한 개 공간에 2개 data에 대한 그래프를 모두 그려줌
참고로 왼쪽 아래 Runs에 존재하는 체크 표시를 풀어줌으로써
1개 data만 확인하는 것도 가능하다
"""
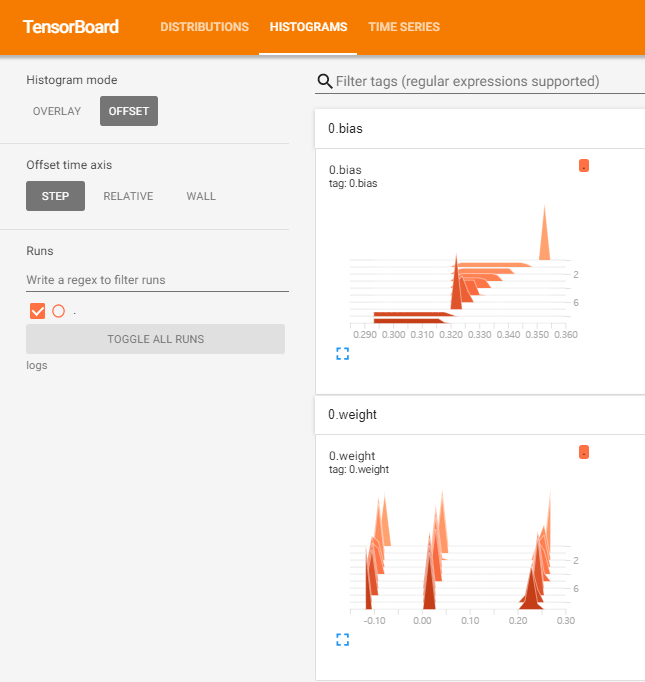
add_histogram : 주로 Parameter에 대한 정보를 많이 표현
import torch
import math
"""
Param 저장은 많이 쓸 것 같아 아예 모델을 간단히 구축하기로 했다
criterion, Optimizer 등은 무엇을 의미하는지 몰라도
그냥 모델을 만들기 위한 용도라고만 지금은 알아둬도 된다
"""
x = torch.linspace(-math.pi,math.pi,2000)
y = torch.sin(x)
p = torch.tensor([1,2,3])
xx = x.unsqueeze(-1).pow(p)
model = torch.nn.Sequential(torch.nn.Linear(3,1), torch.nn.Flatten(0,1))
criterion = torch.nn.MSELoss(reduction='sum')
learning_rate = 1e-3
optimizer = torch.optim.RMSprop(model.parameters(), lr=learning_rate)
for t in range(10):
optimizer.zero_grad()
y_pred = model(xx)
loss = criterion(y_pred,y)
loss.backward()
optimizer.step()
for name, param in model.named_parameters():
writer.add_histogram(name, param.data.numpy(), t)
# Parameter를 저장하는 공간
# t(Epoch)이 진행될 때마다 Parameter Name 아래에 Parameter 값들을 저장시킴
# 이 때 중요한 점은, 가운데 데이터를 numpy 객체로 만들어야 한다는 점이다
writer.close()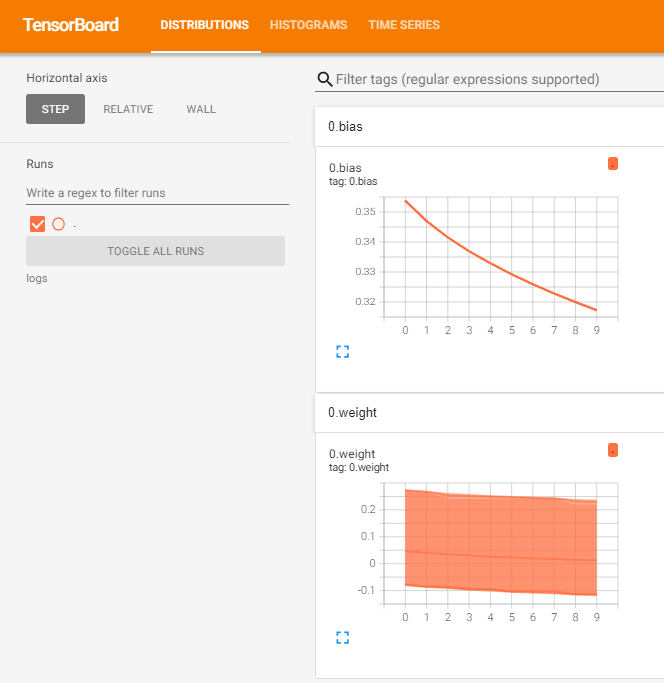
WandB
WandB란?
Weight & Biases가 공식 명칭으로, 협업, Code Versioning, 실험 결과 기록 등을 제공한다.
MLOps의 대표적인 툴로 유명해지고 있는 Tool이다.
WandB 사용 방법
1. Weight & Biases 사이트에 로그인후 API Key 확인
- Settings에서 확인 가능
2. pip install wandb -q
- wandb 설치
3. config에 Dict type으로 설정값을 저장해 놓고, wandb 객체에 적용
- epochs, batch_size, learning_rate 등의 값을 저장
- project : (내가 지정할) Project 명
config = {"epohcs":EPOCHS, "batch_size":BATCH_SIZE,
"learning_rate":LEARNING_RATE}
wandb.init(project="my_test_project",config=config)4. wandb.log({Data})를 통해 wandb에 데이터 저장
- 저장할 Data의 형태는 Tensorboar의 add_X의 형태를 따름
- (ex) 여러 개의 Scalar Data를 표현하고 싶을 때, add_scalars와 마찬가지로 Data를 Dict Type Data로 변화시켜준 이후 wandb.log의 Parameter로 넣어주면 됨
for e in range(1, EPOCHS+1):
optimizer.zero_grad()
y_pred = model(xx)
loss = criterion(y_pred,y)
train_acc = sum((y_pred-y)**2)
# train_acc를 이렇게 구하지는 않지만,
# 결과값을 보고 싶은 것이기 때문에 그냥 이렇게 계산했다
loss.backward()
optimizer.step()
wandb.log({'Accuracy':train_acc,'loss':loss})
# loss와 train_acc는 Scalar값들이고,
# 한 개의 공간에 모두 나타내고 싶으므로 add_scalars()의 형태를 따름
# 즉, Dict type Data로 Parameter를 넘겨줌6. WandB 사이트에 들어가 내가 설정한 Project명을 통해 결과 그래프를 볼 수 있음
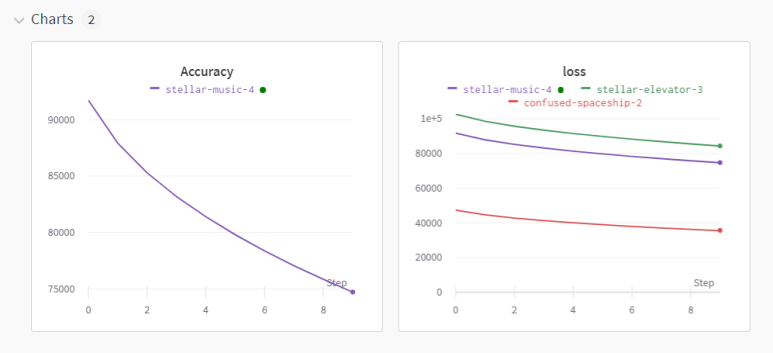
- Loss 같은 경우 여러 개의 그래프가 그려져 있는 것을 볼 수 있다. 학습을 3번 진행시켰는데, 이전에 수행된 학습에 대한 그래프까지 모두 보여주는 것이다
- WandB 같은 경우 사용하는 자원에 대한 데이터도 모두 그래프로 알려준다
