다중 GPU 활용
Model Parallel
모델을 나눈 뒤 여러 개 GPU에서 학습시키는 방법이다.
모델의 병목, Pipeline 구축의 어려움 등으로 인해 난이도가 높은 편이다
사진으로 이해하기
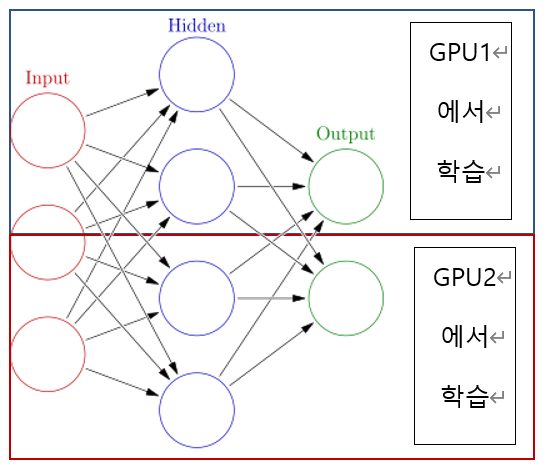
코드로 이해하기
class exModule(nn.Module):
def __init__(self):
super(exModule, self).__init__()
self.seq1 = nn.Sequential(self.conv1, self.bn1).to('cuda:0')
# 1번째 GPU에서 학습 시킬 모델
self.seq2 = nn.Sequential(self.layer3, self.layer4).to('cuda:1')
# 2번째 GPU에서 학습 시킬 모델
self.fc.to('cuda:1')
# 다른 GPU에서 학습시킨 모델들을 결국은 "합쳐야" 완전한 모델이 나올 것임
# 이런 모델을 합치는 과정을 cuda:1,
# 즉 2번째 GPU에서 fc를 통해 수행하는 것이다
def forward(self,x):
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0),-1))
"""
cuda:0에서 수행한 모델 학습 결과를 seq2에 반영하기 위해
cuda:1로 데이터값을 넘겨줬다
또한, cuda:1에서 seq2에 저장된 모델까지 활용했다면,
해당 데이터는 cuda:1에 존재할 것이다
fc는 cuda:1에 저장되었기 때문에, self.seq2를 거쳐 처리된 data를 그대로
self.fc에 적용시키면, 2개 모델을 모두 활용하면서 두 모델을
합치는 연산까지 잘 수행될 것이다
"""위 코드가 좋지 않은 Model Parallel인 이유
self.seq1(x).to('cuda:1')로써 seq1의 결과값을 seq2에 보내 계산을 수행하는 코드이다.
생기는 문제점 1 : 그럼 굳이 GPU를 나눌 필요가 존재하는가?
Data를 다른 GPU에 전달해줄 때도 시간이 소요된다. 그렇다면, 굳이 그런 시간까지 낭비해가면서 seq1과 seq2를 나눌 필요가 있을까?
그냥 한 개의 GPU에서 seq1과 seq2를 연속으로 수행시켜버리면 될 것이다.
- 시간적 문제가 아니라 연산에 드는 "메모리" 양의 한계 때문에 이러한 방식을 활용하기도 한다
생기는 문제점 2 : 파이프라인 구축이 되어 있지 않다.
이 문제는 더욱 큰 문제이다
seq1이 2번 실행될 때 seq2는 1번 실행되는 시간적 차이를 가지고 있다고 가정하자
그렇다면 seq2가 이전 seq1에 대한 연산을 수행하고 있을 때 seq1의 다음 결과값이 seq2에 도착할 것이다.
1,2번은 문제 없을 수도 있지만, 이게 1000,2000번으로 쌓이면 데이터 병목 현상이 일어나거나 데이터가 유실될 가능성이 존재할 것이다.
따라서, 파이프라인을 잘 구축하여 이러한 문제를 해결해줄 필요가 있다
DP(DataParallel)
대용량의 Data를 나눠 각각의 GPU에 할당하여 Parameter를 계산한 이후, 각각의 GPU에서 계산한 Gradients의 평균값을 통해 Parameter를 구하는 방식으로, 단순히 데이터를 분배한 이후 평균을 취하는 방법이다.
DP 방식에는 몇 가지 문제가 발생한다.
-
GPU 사용 불균형 문제
DP에서는 여러 개의 GPU에서 Parameter의 평균을 구하고, 이 Parameter에 대한 계산을 수행하는 과정이 추가되어야 한다.
즉, 1개 GPU에서는 여러 개의 GPU Parameter를 모으고 평균을 구한 뒤, 추가적인 계산을 수행하는 과정이 원래 Parameter 학습 과정에서 추가되어야 한다.
이런 추가적인 연산 때문에 1개 GPU에서는 다른 GPU보다 더 많은 연산 Memory가 필요하게 될 것이고, 자연스럽게 받을 수 있는 Data Memory는 줄어들 것이다
Data는 "공평하게" 분배되어야 하기 때문에, GPU1에는 추가적인 연산이 수행된다면 GPU1의 공간에 맞춰 Data가 분배될 것이고, 자연스럽게 GPU2 ~ N까지는 추가적인 연산을 수행하는 만큼의 Memory가 놀게될 것이다(GPU 사용이 불균형해짐) -
GIL 문제 발생
GIL이란 Global International Lock으로, Python 코드에서 여러 개의 Thread를 활용할 경우, 단 하나의 Trhead만이 Python object에 접근할 수 있도록 제한하는 "Mutex"이다.
GIL이 존재해야지만 임계 영역(CS)에 대해 안전한 관리가 가능해지므로, 필수적인 요소이다. 하지만, GIL 때문에 Python Object에 대한 Lock이 풀릴 때 까지 기다려야 되는 상황이 발생할 수 있으며 이러한 이유로 시간이 낭비될 수 있다.
코드를 통한 DP 구현
model = torch.nn.DataParallel(model)
# 1줄로 설정이 끝난다!
# 원래 model을 DP 형태로 바꿔줌
...
loss = criterion(y_pred, y_value)
loss.mean().backward() # 중요! "평균"을 구해서 학습을 진행DDP(DistributedDataParallel)
CPU마다 Process를 생성하여 개별 GPU에 할당하는 것으로, 기본적으로 GPU마다 개별적인 연산을 수행하는 경우가 많다.
데이터도 GPU 개수만큼 나누고, 모델 연산 또한 GPU 개수만큼 나눠 수행하는 연산이다.
코드를 통한 DDP 구현
train_sampler=torch.utils.data.distributed.DistributedSampler(train_data)
# DDP에서는 Sampler 형성이 중요
trainloader = torch.utils.data.DataLoader(train_data, batch_size=20,
shuffle = False, pin_memomry = True, num_workers = 3,
sampler = train_sampler)
# sampler : 위에서 설정한 대로 index 설정
# num_workers : 사용하는 SubProcess 개수. 일반적으로 GPU 개수 * 4정도로 설정
# pin_memory : 입력 데이터를 pin memory에 고정시킨 후 전송하는 방법.
# 시스템 메모리가 충분할 경우 사용하면 속도가 빨라지고 병목 현상이 줄어듬
def main():
n_gpus = torch.cuda.device_count() # GPU 개수 세기
torch.multiprocessing.spawn(main_worker,nprocs=n_gpus,args=(n_gpus,))
# GPU 각각에 대해 main_worker 수행
def main_worker(gpu, n_gpus):
... # 입력 데이터 만지기, 배치 사이즈 정하기 등
torch.distributed.init_process_group(backend='nccl',
init_method='tcp://127.0.0.1:2568')
# 멀티프로세싱 통신 규약 정의.
... # model 정의
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[gpu])
# DDP 정의DP와 DDP 차이점
- 참조 사이트 : https://algopoolja.tistory.com/56
DP는 단순히 Data를 쪼개서 GPU에 분할해주는 것이다.
즉, Model에 대한 모든 정보는 GPU가 모두 가지고 있어야 한다.
하지만 DDP는 Data를 쪼개는 것과 동시에 Model에서 학습할 부분도 쪼개는 것이다.
예를 들어 Model의 Layer가 6개 존재할 때, GPU 1은 1~2, GPU 2는 3~4, GPU3는 5~6 Layer의 학습을 도맡는 것이다.
물론, Data도 쪼개서 각각의 GPU에 분할된다
즉, DP는 GPU 1 ~ N까지 Data를 나누고, 모든 GPU마다 Model의 모든 Layer 정보가 저장되어 있어야 한다. 하지만 DDP는 Data도 나누고, 각각의 GPU마다 Model에서 학습시킬 Layer도 나누어 학습을 진행시키는 것이다
Hyperparameter Tuning
Model의 정확도 높이는 3가지 방법
- Model 바꾸기
- 가장 효율적이지만, 최근에는 가장 효율적인 모델을 가지고 와 변형시키는 방식을 활용하므로 실제로 많은 영향을 끼치지는 않음
- Data 추가 or 기존 Data 변경
- 현재로썬 가장 효율 좋은 정확도 높이기 방법
- 실제 기업에서는 Model은 어느 정도 구현된 상태로 Data를 만지는데 집중하고 있다.
- Hyperparameter Tuning
Hyperparameter Tuning이란?
모델 스스로 학습하지 않는 값들을 사람이 직접 지정하는 것으로, 수정할 값들은 학습율, 모델 크기, Optimizer 등이 존재한다.
예전에는 큰 효과가 있었지만 현재는 큰 효과가 없다는 의견이 있다. 단, 시간 효율을 쥐어 짜야할 때 사용해 볼 만 하다.
Tuning 방법으로는 3가지가 존재한다.
1. Grid
모델 하이퍼 파라미터에 넣을 수 있는 값들을 순차적으로 입력한 뒤 가장 높은 성능을 보이는 하이퍼 파라미터들을 찾는 탐색 방식이다.
2. Random
Grid는 파라미터에 넣을 수 있는 값들을 "순차적으로", 즉 "일정한 간격으로" 탐색하여 찾지만, Random은 파라미터를 무작위로 대입하여 최적값을 찾는 작업을 지원한다.
언뜻보면 랜덤성이 존재하여 나빠 보일 수도 있지만 '유한 자원'을 기반으로 할 때는 오히려 좋다고 한다.
Bengjo 박사의 "Random search for Hyperparameter optimization"에 따르면 시간이 한정되어 있을 경우 Random search가 더 좋은 결과를 내는 경향이 있다고 한다
3. Bayesian Optimization
최근 가장 많이 활용하는 Tuning 방식이다.
현재 까지의 실험 결과를 바탕으로 통계적인 모델을 만들고, 그것을 바탕으로 다음 탐색을 효과적으로 정하는 것이다. 즉, Parameter를 찾을 때 이전 연산을 활용하는 방법이다
HyperParameter Tuning할 때는 Ray라는 기구를 많이 활용하므로, 훗날 공부하는 것을 추천한다.
Ray를 활용하기 위해서는 하나의 함수에 모든 (DL) 과정들이 저장되어 있어야 함
DL에서의 OOM 문제 해결
OOM이란?
Out of Memory의 약자로, 메모리가 없어 발생하는 에러이다.
AI는 대용량 데이터를 다루기 때문에 OOM이 많이 발생하므로, 이 에러 처리 방법을 잘 알고 있어야 한다.
OOM 해결 방법
1. GPUUtil을 활용하여 GPU 상태를 확인한 후 OOM 발생 근원 GPU 찾기
!pip install GPUtil # GPUtil 설치
================================
import GPUtil
GPUtil.showUtilization()2. torch.cuda.empty_cache()
사용되지 않는 GPU Cache 정리하는 명령문으로, del 과는 구분이 필요하다
- del : 내가 원하는 Object를 메모리에서 삭제시키는 것
- empty_cache() : Garbage Collector를 강제로 실행시켜 Garbage 값을 삭제시켜 메모리를 확보하는 방식
3. del 명령어 활용
필요하지 않은 객체를 삭제시키는 명령어 이다.
Python 특징 상 Loop가 끝나도 해당 공간 내의 Obejct는 메모리를 차지하므로, 이런 필요없는 객체들을 del을 통해 지워주는 것이다.
4. Batch Size를 바꾸어가며 OOM을 발생시키지 않는 Batch Size 찾기
batch size = 1일 때도 OOM이 발생한다면 Code에 문제가 있는 것이므로, 일단 batch size = 1로 변경시켜 OOM이 발생하는지 확인하는 것도 좋은 방법이다.
OOM을 해결할 수 있는 가장 쉬운 방법이다.
(Batch Size를 작게 하여 OOM 해결)
5. Tensor 객체를 과도하게 활용하지 않기
Tensor 객체는 GPU 상에 계속해서 메모리 공간에 존재하고 있는데, Loop 속 연산에 Tensor 객체로 처리할 경우 GPU 메모리를 잠식하게 된다.(Loop를 돌 때마다 생성되는 Tensor객체가 계속 존재하므로)
따라서 1번만 활용하는 Data를 Python 객체로 변환하는 방법을 활용한다. {tensor 객체}.item()을 통해 Tnesor 객체 중 Value(값)만 가지고 와 Python 객체로 변환할 수 있고, 이를 활용해 Tensor 객체 사용을 줄일 수 있다.
6. torch.no_grad() 활용
