Passage Retrieval
Passage Retrieval이란?
-
질문에 맞는 문서(Passage)를 찾는 Task
- 질문에 대한 "답이 존재할만한 문서"를 찾는 것
-
ODQA(Open-Domain Question Answering) Task와 더불어 유명해짐
- Passage Retrieval과 MRC를 이어 2-Stage 방식으로 ODQA Task 진행 가능
-
대규모 문서 중 질문에 대한 답을 찾는 Task
Overview
- Query와 Passage를 임베딩하여 랭킹을 매김
- 유사도가 높은 N개의 Passage를 선택함
- Passage는 효율성을 위해 미리 Embedding이 되어 있는 상태이며, Query만 Embedding을 추가로 시켜 모델에 통과시킨 이후 가장 적절한(유사도가 높은) Passage를 선택하는 것
Passage Embedding Space
-
Passage Embedding의 벡터 공간
-
벡터화된 Passage를 활용해 Passage간 유사도 알고리즘 등을 통해 계산할 수도 있음
- Iner Product 연산을 통해 계산 가능
Sparse Embedding
Sparse Embedding이란?
-
단어가 문서에 등장하는지 여부를 확인하여 문서를 찾는 Passage Retrieval 방식
-
BoW(Bag-of-words)를 구성하는 방법
- N-gram 활용 방법
- Uni-gram이나 Bi-gram 방식으로 BoW를 구성하여 Sparse Embedding을 수행
-
Term Value를 결정하는 방법
- Document에서 Term의 등장 여부 확인(Binary)
- Term이 Document에서 몇 번 등장했는지 확인(Term Frequency)
- TF-IDF
Sparse Embedding 특징
-
Dimension of Embedding Vector = Number of Terms
- 등장하는 단어 수가 많아질수록 Embedding Vector의 크기가 커짐
- BoW 특징
- N-gram에서도 N이 커질수록 Embedding Vector 크기가 커짐
- 등장하는 단어 수가 많아질수록 Embedding Vector의 크기가 커짐
-
Term Overlap을 정확하게 Search해야할 때 유용
-
유사어에 대한 비교가 불가
- N-gram 혹은 BoW 활용에서의 단점
TF-IDF
TF
-
(Document 내에) 단어의 등장 빈도
-
Raw Count를 수행하고 여러 가지 방법을 통해 Normalization을 수행함
- Binary, Log Normalization 방법 등
IDF
-
단어가 제공하는 정보의 양
-
단어가 얼마나 (다른 Document)에 등장하는지 여부를 확인
-
- DF(Document Frequency) : Term t가 등장한 Document 개수
- N : 총 Document의 개수
TF-IDF
- TF-IDF는 단어가 주어졌을 때 해당 Document에 단어가 얼마나 나왔고, 다른 Document에는 해당 단어가 얼마나 나왔는지를 확인하는 방법
- (ex) 'Son Heung Min'이라는 단어가 A라는 문단에 자주 나왔다고 가정하자. 저 단어는 다른 문단에도 자주 나올만한 단어는 아니므로 다른 Document에는 나오지 않지만 A 문단에만 자주 나오므로 A문단의 특징으로 볼 수 있다
- (ex2) 'a'라는 단어가 A라는 문단에 자주 나왔다고 가정하자. 하지만, 'a'라는 단어는 다른 B, C, D,... 등의 다른 문단에도 똑같이 자주 나오는 단어이다. 즉, A 문단만의 특징은 아닌 것으로 고려할 수 있다.
- t : Term
- d : Document
- TF(t,d) : TF 점수
- Document d에 Term이 몇 개 나왔는가
- IDF(t) : term t에 대한 IDF 점수
- 모든 Document에 대해 계산하는 값이므로 Term t가 같다면 모든 Document에서 똑같은 값을 가짐
TF-IDF 특징
-
자주 출현한 단어들은 TF-IDF 점수가 낮음
- 점수가 높을수록 Term t에 대해 잘 표현하고 있는 Document임을 알 수 있음
- 고유 명사는 자주 등장하지 않으므로 TF-IDF 값이 큼(TF는 낮지만, IDF가 매우 높음)
-
TF가 낮음 : 1개의 Document에 대해 Term이 낮음
- Document의 특징이라고 보기 어려움
-
IDF가 낮음 : 모든 Document에 자주 나오는 Term
- 해당 Document만의 고유한 특징이라고 보기 어려움
TF-IDF를 활용한 (Sparse Embedding) Passage Retrieval
-
사용자가 입력한 Question을 Tokenization
- 기존 단어 사전에 없는 토큰들은 제외
-
질의(Question)을 하나의 문서로 생각하여 TF-IDF 계산
-
각 문서별 TF-IDF 값을 곱하여 유사도 점수 계산
-
가장 높은 점수를 가지는 문서 선택
BM25
-
TF-IDF 개념을 바탕으로 문서 길이까지 고려하여 점수를 매기는 ㅓㅅ
-
TF 값에 한계를 지정하여 범위를 유지함
-
평균적인 문서 길이보다 작은 문서에서 단어가 매칭될 경우 가중치를 부여
- 즉, 짧은 문서에 해당 단어가 나왔다면 해당 Document가 더 적절할 가능성이 높음
-
실제 검색엔진, 추천시스템 등에서 많이 활용되는 알고리즘
Sparse Embedding 단점
- 차원의 수가 매우 큼
- 이유 : N-gram을 활용하므로 Non-zero value가 많은 공간을 차지함
- Compressed Format으로 어느정도 해결 가능
- 유사성을 고려하지 못함
- 이 부분에 대한 해결이 어려움
Dense Embedding
Dense Embedding이란?
-
작은 차원의 고밀도 벡터로 Mapping되는 방식
-
각 차원이 특정 Term에 대응되지 않음
- Sparse Embedding은 Term에 따라 차원이 정해짐
-
대부분 요소가 Non-zero 값
Sparse Embedding VS Dense Embedding
Sparse Embedding
-
중요한 Term들이 정확히 일치해야 하는 경우 성능이 뛰어남
-
Embedding이 구축된 이후 추가적인 학습이 불가능
Dense Embedding
-
단어 유사성 및 맥락을 파악하는 경우 성능이 뛰어남
-
학습을 통해 Embedding이 만들어지며 추가적인 학습도 가능
-
최근 사전학습 모델의 등장 및 검색 기술의 발전 등으로 Dense Embedding이 활발히 이용되고 있음
Dense Embedding Overview
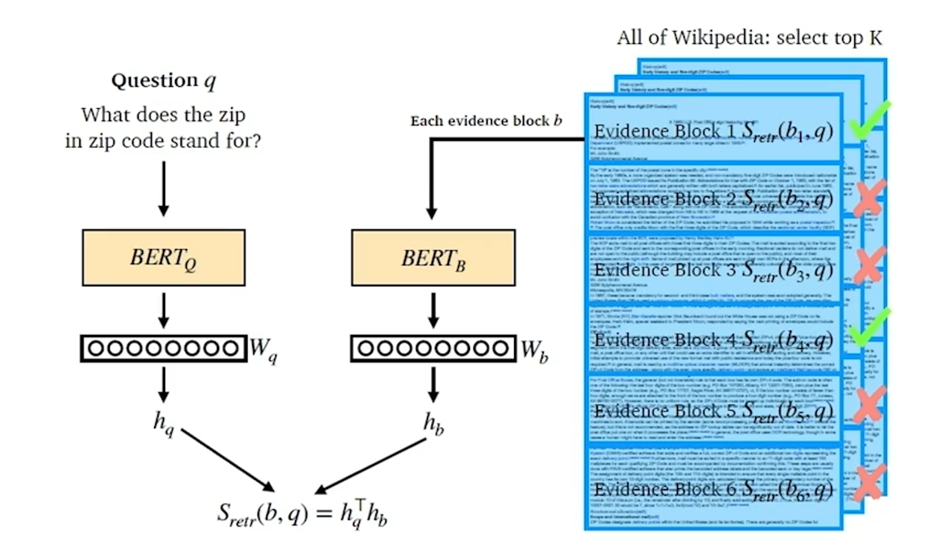
- 즉, BERT 2개에 대해 Question을 위한 BERT, Document에 대한 BERT를 따로 학습시키고, 해당 Output을 내적하여 Score를 도출한다.
Train 과정
-
학습 목표 : 연관된 Question과 Passage Dense Embedding 간의 거리를 좁히는 것
- 내적 값을 높이는 것
-
정답인 Passage일수록 점수가 높고, 아닐 경우 낮도록(음수가 나오도록) 학습이 진행됨
-
Negative Sampling : 정답이 아닌 Sample들을 추가로 뽑아 거리를 멀게 하는 학습 방법
- Corpus 내에서 정답이 아닌 N개의 Sample을 뽑는 방법
- 헷갈리는 N개의 Sample들을 뽑는 방법
- 높은 TF-IDF 스코어를 가지지만 답이 아닌 Sample들로 선택
-
성능 올리는 방법
- 학습 방법 개선
- (ex) DPR
- 인코더 모델 개선
- 데이터 개선
- 학습 방법 개선
