Scaling Up
Scaling Up이 필요한 이유
-
Passage Retrieval에서 Passage가 많아질수록 연산이 부담스러워짐
-
현재 수많은 데이터가 존재하며 Passage 또한 다양함
-
이렇게 많은 Passage에 대하여 연산을 수행하기 위해 도입하게 된 여러 기법이 Scaling Up을 위한 기법임
MIPS
-
Maximum Inner Product Search
- 내적 값이 가장 큰(유사도가 가장 큰) Passage를 구하는 것
-
Exhaustive(Brute-force) Search
- 저장해 둔 모든 Spare/Dense Embedding에 대해 모두 내적값ㅇ르 계산하여 가장 값이 큰 Passage 추출
- Passage가 많아질수록 연산 Cost가 높아져 비효율적
Tradeoffs of Similarity Search
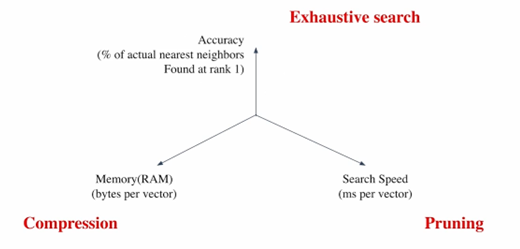
-
Search Speed
- 가지고 있는 벡터량이 클수록 오래 걸림
- Passage가 많을수록 오래 걸림
- 속도가 빠를수록 정확도가 낮아지게 됨
-
Memory Usage
- Passage Vector를 RAM에 모두 올려둘 수 있으면 빠름
- 그러나 RAM이 매우 많이 필요
- Disk에서 불러오면 용량 문제는 해결되지만 속도가 느려짐
- Corpus의 크기가 커질수록 검색이 어려워짐
- Passage Vector를 RAM에 모두 올려둘 수 있으면 빠름
-
Accuracy
- 속도를 증가시키려면 정확도를 희생해야 함
- Sparse Embedding에서 이런 문제가 부각됨
Approximating Similarity Search
Compression
-
Vector를 압축하여 하나의 Vector가 적은 용량을 차지하게 함
- 압축량이 커질수록 메모리는 덜 필요하지만 정보 손실이 많아짐
-
Memory에 대한 Tradeoff 해결 방법
-
Scalar Quantization(SQ)
- 4-byte floating point를 1-byte unsigned integer로 압축
- 4배로 공간을 아낄 수 있게 됨
Pruning
-
Search Space를 줄여 Search 속도를 개선
- Dataset Group 중 Subset만 방문
-
Speed에 대한 Tradeoff 해결 방법
-
Clustering + Inverted File을 활용한 Search
- Clustering : 전채 Vector Space를 k개의 Cluster로 나누는 것
- Inverted File(IVF) : 각 Cluster ID와 Cluster의 Vector들이 연결되어 있는 형태
- ID만 알고 있으면 해당 Vector에 접근할 수 있음
- Cluster 내에 있는 ID를 좀 더 빠르게 접근 가능하므로 더 속도가 빨라짐
FAISS
-
Facebook에서 만든 라이브러리
-
Scale up을 해야할 때 용이하게 활용 가능
-
Indexing(특히 Pruning)에 많은 도움을 줌

개념부터 확실히!