
Product Serving 과정
GCP 선택 계기
원래는 AWS를 통해 Service를 배포하기로 했다.
그런데 T2I 모델의 크기가 너무 크다는 것이 우리의 불안심을 자극시켰다.
그래서 한 번 T2I 모델을 포함시켜서 Backend를 돌려보기로 했고, 결과적으로 1번의 Request당 40분이 걸린다는 것을 알게 되었다.
40분? 40초도 너무 길다고 줄이는 판에 40분?
무조건 GPU를 활용해아하는 모델이였던 것이다.
우리의 Cloud에 대한 요구조건은 아래와 같다.
-
무료로 GPU 활용이 가능할 것
-
1달 정도는 Service 운영이 가능하여 시연을 해 볼 수 있을 것
-
어느 정도의 CPU 공간이 존재할 것
- T2I Model에 대한 데이터가 5GB정도 되기 때문에, 이를 저장할 CPU가 필요 모듈을 설치하는 공간까지 생각하면 최소 9~10GB 정도는 필요할 것이다
AWS는 GPU를 활용할 수가 없다.
정확히는, 활용할 수는 있으나 유료로 활용 가능하다
AWS 자체 기능도 유료 활용이 꺼려져서 매번 새로운 계정을 파는데 유료로(심지어 싸지도 않다) 시연 영상을 위해 Cloud를 사용해야할까?
따라서 우리는 GCP를 활용하기로 했다.
GCP에서는 Tesla T4라는 GPU를 활용할 수 있었고, 처음에 주는 Credit으로 1달정도는 무료 배포가 가능했기 때문에 위 조건과 딱 맞았다
또한, CPU(디스크; /dev/sda1 용량)도 50GB까지 설정해 줄 수 있어서 최적인 Cloud Platform 이였다.
requirements.txt
먼저 requirements.txt에 필요 모듈을 모두 입력하는 것이 필요했다.
그런데, 이 때 버전 충돌이 나는 경우가 존재하였다.
이럴 경우 제대로 설치가 되지 않아 하나하나 일일히 설치하고, 안되는 경우를 찾아서 해결책을 찾아야 하는 어려운 점이 존재하였다.
이런 문제 해결을 위해 팀원이 좋은 방법을 찾아왔다.
pip install -r requirements.txt --use-feature=2020-resolver
--use-feature Parameter로 Resolver를 지정해준다면 버전 충돌이 나지 않도록 설치 가능하다는 것을 알게 되었다.
따라서 버전 충돌 문제를 Argument 하나로 처리 가능하므로, 이 부분에 많은 시간을 들일 필요가 없었다.
모델 깨짐 현상
이전에 내가 다른 팀원에게 .pickle 파일을 보내줬을 때 파일이 깨졌던 경우가 발생하였다.
이 때 나눴던 얘기가 압축이나 카톡을 통해 데이터를 보내면 큰 데이터 같은 경우 약간의 손실이 발생할 수도 있을 것 같다라는 얘기였다.
이번 .ckpt 같은 경우 파일 크기가 워낙 크기 때문에 거의 무조건 파일 손상이 있을 것이라고 생각하여 어떻게 하면 파일 손상 없이 T2I Model에 대한 정보를 가져올 수 있을까 고민을 많이 하였다.
따라서 ssh를 통해서 아예 팀원 서버에서 데이터를 통째로 가져와서 실험해보기로 하였다.
ssh를 처음에는 CLI로 수행하다, 나중에는 WinSCP라는 편한 Tool을 알게되어 WinSCP에서 쉽게 모델을 꺼내와서 GCP 서버에 올렸다.
이렇게 얻어온 Model 정보로 backend를 수행해봤을 때, 제대로 사진 출력이 나오는 것을 보고 이 방법을 그대로 활용하기로 하였다.
방화벽 및 포트 문제
분명히 제대로 명령어가 수행되어 서버가 동작하는 것까지 봤는데, Internet에서 검색이 불가했다.
원래라면 이 문제에 많은 시간을 들였겠지만, (다행히도) 나는 백엔드를 예전에 공부했던 사람! 분명 GCP에서 해당 Port를 열어주지 않았거나 방화벽 문제라고 생각하였다.
일단 방화벽 문제로 접근하여 문제 해결을 시도해보았다.
방화벽 해제 방법 및 결과
- 이 부분은 이전에 배웠던 Linux에 자세한 방법이 있으니 다시 확인해보자
- Docx에 정리한 Linux 공부한 것도 블로그에 옮겨놔야겠다. 이걸 쓰네...
방화벽 활용법1 : 포트 등록
# 방화벽을 위한 Tool 설치
yum install firewalld
# 특정 포트 방화벽 등록
firewall-cmd --permanent --zone=public --add-port=3690/tcpsuccess
# 방화벽 변경 사항을 적용시키기 위해 Reload
firewall-cmd --reload
# 결고 확인
firewall-cmd --list-ports
# 결과 : 3690/tcp ->위에서 지정한 3690 port가 방화벽에 등록 되었음을 알 수 있음방화벽 활용법2 : 포트 해제
# 위에서 지정한 3690/tcp 방화벽 해제
firewall-cmd --permanent --zone=public --remove-port=3690/tc결과
딱히 문제가 해결되지는 않았다.
생각해보면 firewall(방화벽)은 내가 해당 Tool을 설치해서 설정해 준 이후에야 활용할 수 있는 것인데, 처음부터 모든 방화벽이 막혀있다는 것은 이상했다.
즉, GCP 자체에서 해당 Port를 막은 것이다.
외부에서 GCP Port 통과 가능하도록 설정
사실 이 가능성이 처음부터 매우 높다고 생각하였다.
이전에 Serving 했을 때도 AWS의 Port 보안이 닫혀 있어 실제 시연을 할 때 크게 망쳐본 적이 있는 사람으로써(아... PTSD.....) 항상 외부 Cloud를 활용할 때는 해당 Port가 열려있는지 확인해야 한다는 교훈을 얻었기 때문이다.
방법은 순서대로 아래와 같다
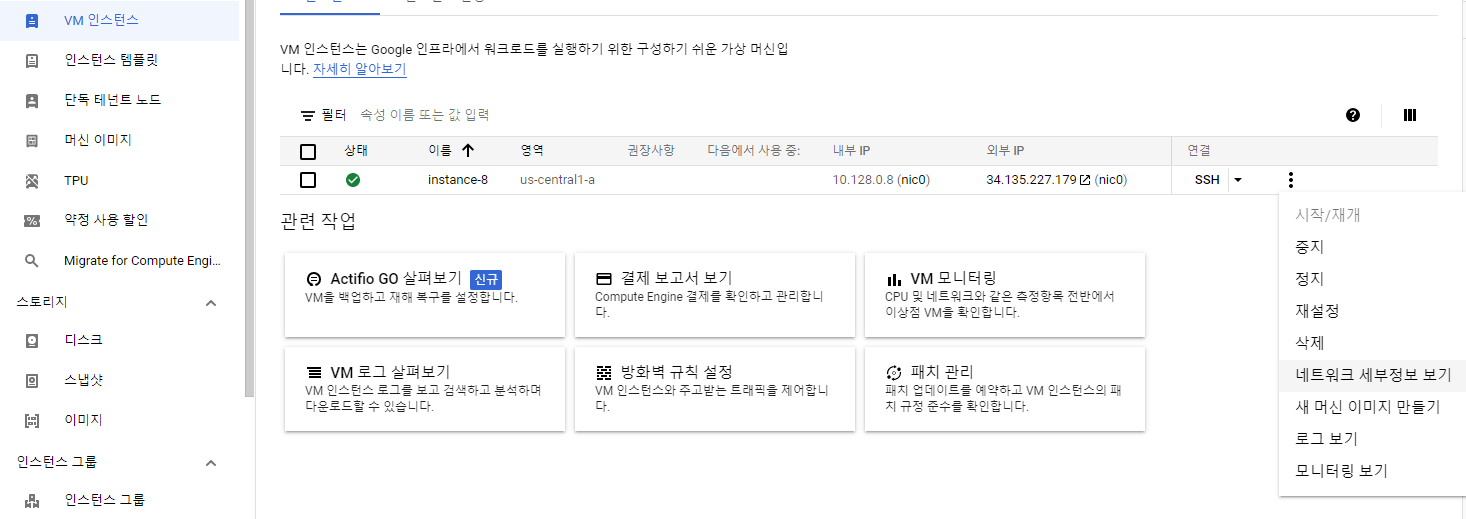
1. 생성한 인스턴스의 점 3개 부분 클릭 후 "네트워크 세부정보 보기" 클릭
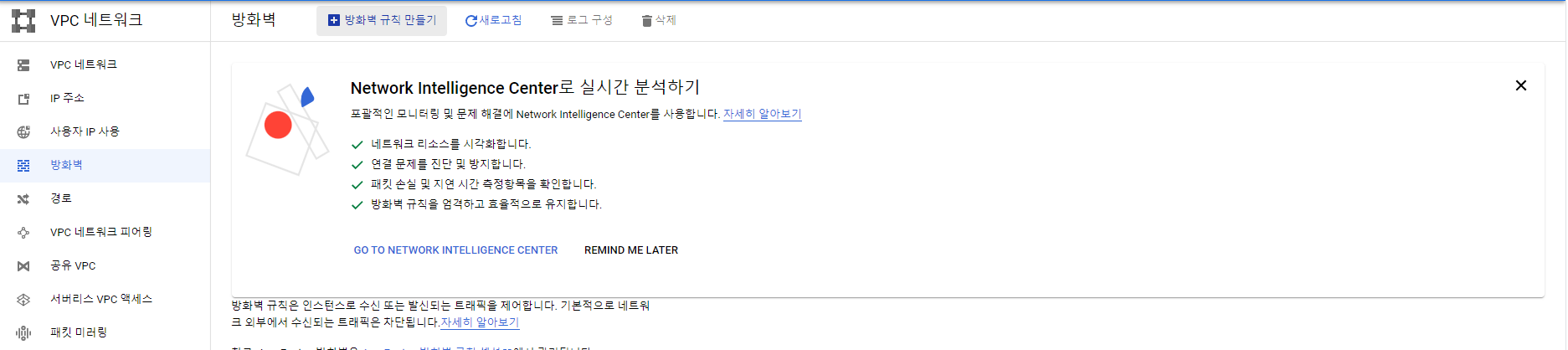
2. 왼쪽 방화벽 Section 선택 & + 방화벽 규칙 만들기 클릭
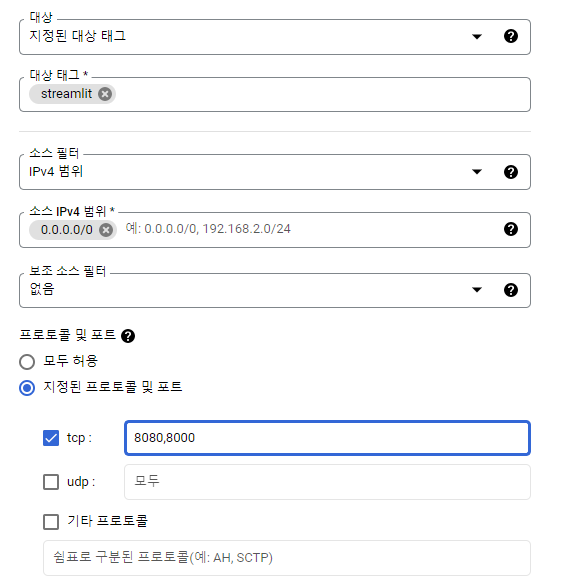
3. 설정 값 입력 & 만들기
-
대상 태그
- 매우 중요한 부분
- 나중에 활용하겠지만, 이 창에서 설정한 태그 값을 무조건 기억해 놓고 있어야지 나중에 VM 인스턴스에 적용할 수 있다!
- 정해진 Rule 같은게 존재하지는 않지만, 나는 최대한 왜 이 방화벽 규칙을 만들었는지 구분하기 쉽게 정하는 편이다. 예를 들어, 이번 프로젝트에서 방화벽 규칙을 만든 이유는
streamlit명령어로 실행한 Frontend 서버를 외부에서 접근 가능하게 하기 위한 용도이므로 streamlit으로 지정했다.
-
소스 IPv4 범위
- 어떤 IP에서 접근 가능하도록 하게 할 지 설정하는 값
- 예를 들어
192.168.2.0/24로 설정하면, 이 값에 해당하는 IP 주소를 가진 컴퓨터만 접근 가능하다는 것이다. 그렇다면 이 값이 왜 필요할까? - 나중에 조금 심화하면 따로 "서버 운영자용 Port"를 열어 놓는 경우가 있다. 그래서 이 Port로 접근하는 것은 운영자만 가능하도록 설정하는 경우가 존재한다.
이 경우, 운영자 IP 주소값을 모두 조사하여 직접 소스 IPv4 범위값으로 설정해주면, 올려 놓은 주소값을 가진 관리자들만 해당 Port로 접근하여 서버를 설정할 수 있게 되는 것이다. 0.0.0.0/0: 모든 주소에서 접근 가능하도록 설정해라!- 우리는 Streamlit으로 실행한 Frontend 주소를 모든 서버에서 접근 가능하도록 만들고 싶기 때문에,
0.0.0.0/0으로 설정했다.
-
지정된 프로토콜 및 포트
- 핵심 입력 값
- 어떤 포트를 열어주어 외부에서 접근 가능하도록 할 것인지 정하는 부분이다.
- 위 처럼 입력하면 8000, 8080 포트는
0.0.0.0/0IP 주소 유저에게 연다는 의미이다. - Streamlit으로 서비스를 실행하면 Default로 8501포트에 서비스를 시작하기 때문에 나는 실제로는 tcp 8501 포트를 열어놨다.
-
최종 정리
- 위 값으로 설정하면
0.0.0.0/0IP 주소를 가진 User(즉 모든 User)에게8000, 8080/tcp접근을 허용하는streamlit이라는 이름을 가진 방화벽 규칙이라는 의미이다.
- 위 값으로 설정하면
와 끝났다!!!!!
4. 만든 방화벽 규칙 적용시키기
...가 아니다.
위까지는 어디까지나 "규칙"을 만든 것일 뿐, 이 규칙을 실제로 서버에 적용시켜야지만 제대로 동작을 할 것이다.
(법을 만들기만 하고, 등록을 안해버리면 어디에 쓸 수 있겠는가?)
먼저 규칙을 적용시키고 싶은 Instance의 이름을 클릭하면 위와 같은 창이 맨 위에 존재할 것이다.

여기에서 수정 버튼을 클릭하여 아래와 같이 설정해주면 이제 3까지 만들어 놓았던 규칙을 우리가 원하는 서버에 적용한 것이다
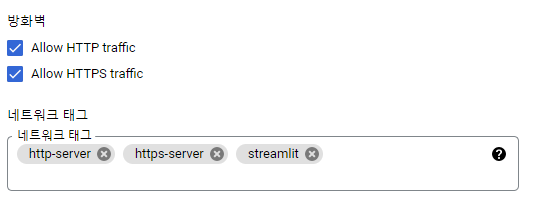
- 이제 여기에서 왜 태그 이름을 잘 지어야 하는지 알게 될 것이다. 아까 지정했던
streamlit이라는 태그 이름을 그대로 활용하는 것을 볼 수 있다.
즉, 이름을 내 맘대로 지어버리면, 그만큼 규칙을 서버에 적용시키기도 어려워지고, 나중에 서버를 유지보수할 때도 어려워지는 것이다.
GCP Key 생성
이전에 말했던 대로, 우리는 WinSCP(ssh)를 통해 T2I Model 정보를 전달하여 from_pretrained 메서드로 불러올 것이다.
그렇다면 ssh를 통해 GCP에 접근할 수 있어야 할 것이다.
그런데 GCP를 활용하다보면 브라우저에서 직접 ssh로 접근하게 하여 Key값을 어떻게 얻는지에 대해서는 잘 나와 있지 않다
(AWS는 그냥 처음부터 주던데.... 쩝)
따라서 우리는 GCP 접근을 위한 Key를 만들어 줄 필요가 있다.
- GCP Key 만들기 : https://jybaek.gitbook.io/with-gcp/appendix/gce_to_ssh
GCP에서 GPU 활용하기
- 먼저, 이 부분은 억울해서 정리해놓긴 했지만 정말 개 뻘짓이라는 것을 알고 가뒀으면 한다. 이미 GCP에서 NVIDIA를 손쉽게 활용할 수 있도록 다 환경을 저장해 놨기 때문에, 그냥 저장해 놓은 Environment를 끌어다 활용만 하면 된다.
GPU 할당량 요청
먼저, GCP에서 GPU를 활용하기 위해서는 유료 계정 전환이 필요하다.
유료 계정으로 전환되더라도 처음에 주어진 Credit을 먼저 소모하기 때문에, 기간만 잘 맞춘다면 무료로 활용 가능하다.
유료 계정 전환 방법
1. 결제 Section 선택
2. 지정해 놨던 결제 계정 한 개 클릭
3. 오른쪽 아래 무료 체험판 크레딧 업그레이드 클릭
GPU 할당량 요청
- 유료 계정 전환이 되었다면, 따로 과정을 거치지 않더라도 Instance측에서 할당 요청을 수행하라고 문구가 뜬다. 그 문구를 클릭하면 자동으로 요청된다.
GPU 인스턴스 생성
1. 인스턴스 만들기 선택

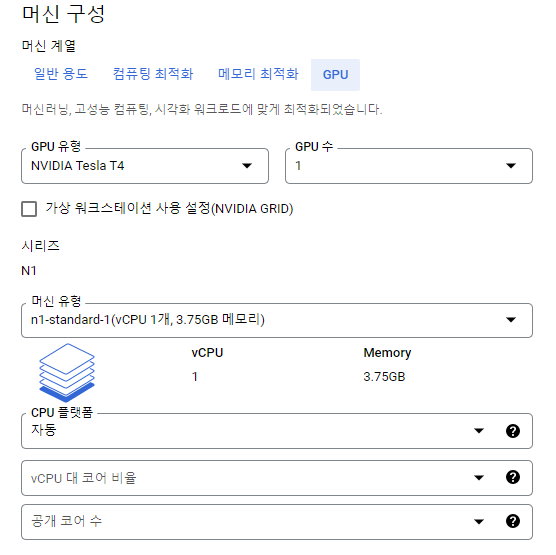
2. 머신 구성 Section에서 GPU 선택
3. 부팅 디스크 Section 확인 후 '이미지 전환' 클릭
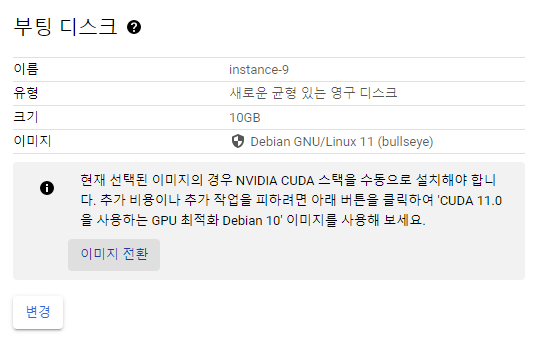
- 공개 이미지에서 자동으로 Search 해주는 버전을 선택
4. 생성 완료!
진짜로, 3~4 과정이 진짜로 중요하다.
왜냐하면 이 과정을 수행하면 아래에 나올 수많은 에러들 및 힘든 설치들을 하지 않아도 되기 때문이다.
나도 이 부분을 처음엔 몰랐어서 1부터 NVIDIA CUDA 스택을 설치했기 때문에, 다시는 나같은 희생자가 생기지 않기를 바라며 여기에 크게 강조한다.
(왜 Docker를 활용하는지에 대한 간접적인 경험이었다)
자... 그럼 안 쓰기엔 억울하지만 사실은 전혀 필요 없었던 NVIDIA CUDA 스택 설치법을 알아보자
NVIDIA CUDA 스택 설치(중요하지 않음; 위 섹션 마지막 부분 참조)
NVIDIA 그래픽 드라이버 설치
1. 원래 설치된 Nouveau 드라이버 제거
sudo apt-get remove nvidia* && sudo apt autoremove
sudo apt-get install dkms linux-headers-generic
sudo apt-get install build-essential linux-headers-`uname -r`2. blacklist.conf 파일 수정
sudo nano /etc/modprobe.d/blacklist.conf- blacklist.conf 파일 열기 + 수정을 위한 코드
- 아래 내용을 blacklist.conf 파일에 추가
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off3. 수정한 설정을 적용하여 커널 재빌드 & 시스템 재부팅
# 만일을 위해 실행하는 코드. 실행하지 않아도 됨
echo options nouveau modeset=0
| sudo tee -a /etc/modprobe.d/nouveau-kms.conf
sudo update-initramfs -u- 시스템 재부팅 :
sudo reboot
4. NVIDIA 사이트에서 필요한 Driver 설치
- 설치 사이트 : https://www.nvidia.com/Download/index.aspx?lang=en-us
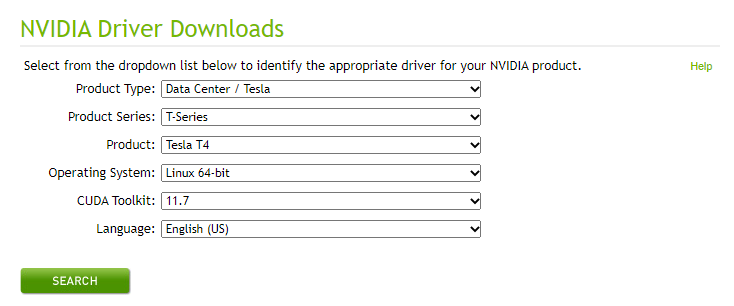
- 내가 GPU 요청했던 Spec을 그대로 입력하여 Search 하면 됨
- 리눅스용 run 파일을 선택하여 다운받음
5. 다운받은 run 파일을 GCP Console에 Upload & 실행
chmod +x ./~.run
sudo ./~.run- 아마 처음에 run 파일은 실행 권한이 없을 것이다. 따라서, +x를 통해 실행 권한을 추가시켜주고, 이후 해당 run 파일을 실행시켜주면 된다
6. NVIDIA Driver 설치 확인
nvidia-smi- GPU에 관련된 정보가 잘 출력되면 설치가 잘 된 것이다!
7. CUDA Toolkit 설치
- 설치 사이트 : https://developer.nvidia.com/cuda-downloads
- 리눅스용 run 파일 다운로드
- 설치 시 드라이버 설치는 "N" 선택
8. CUDA Toolkit GCP에 Upload & 설치
chmod +x ./cuda~.run
sudo ./cuda~.run9. ~./bashrc에 2줄 추가
export PATH=$PATH:/usr/local/cuda-8.0
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-8.0/lib64 10. 설치 완료!
- python을 실행하여
torch.cuda.is_available()이 True값을 반환하면 설치가 완료된 것이다 nvcc -v를 통해 확인할 수도 있다.
Error 내용 및 해결
Uvicorn 실행 에러
-bash: uvicorn: command not found```-
질문 : https://stackoverflow.com/questions/59025891/uvicorn-is-not-working-when-called-from-the-terminal
-
이유
Uvicorn이라는 명령이 사실은python -m uvicorn이라는 명령의 함축어이다.
이게 무슨 말이냐, uvicorn으로 명령문이 실행되더라도 사실은 Python으로 Uvicorn이 실행된다는 의미이다. -
해결 방법
이게 사실은 GCP가 아닌 Local에서는 많이 발생하지 않는 에러이다. 왜냐하면, 대부분 Python이나 JAVA를 $HOME 등의 PATH로 지정해 놓았을 것이기 때문이다.
하지만, GCP에서는 이런 Default 설정을 해주지 않았으므로 생성되는 에러이다.
따라서, 아래 문구를 통해 PATH를 설정하면 손쉽게 해결 가능하다
export PATH=$PATH:$HOME/.local/bintorch 관련 에러
from torch._C import * ModuleNotFoundError: No module named 'torch._C'-
이유
정확한 이유는 사실 지금도 잘 모르겠다. 하지마 내가 해결한 방법을 통해 유추해보자면, torch의 버전 문제 때문이 아닌가 싶다. -
해결 방법
나 같은 경우 torch를1.9.0버전으로 Update 하였을 때 해결 되었다.
torch 설치 관련 문구는 아래와 같다
pip install torch==1.9.0 torchvision==0.10.0 torchaudio==0.9.0distutils 오류
AttributeError: module 'disutils' has no attribute 'version'-
이유
이전에 이미 많이 발생되었던 에러인가 보다. 이미 PyTorch 측면에서 Bug를 Fix했다고 한다. -
해결 방법
아래 문구를 입력하여setuptools를 설치하면 바로 해결되는 문제이다.
(PyTorch의 해결 방법이 담긴 Versionsetuptools를 설치)
pip install setuptools==59.5.0PyYAML 에러
ERROR: Cannot uninstall 'PyYAML'. It is a distutils installed project
and thus we cannot accurately determine which files belong to it
which would lead to only a partial uninstall.-
이유
PyYAML 버전을 업그레이드 할 때 PyYAML 라이브러리르 지우고 다시 설치하는데, 이 떄 발생하는 에러이다. -
해결 방법
PyYAML Update를 무시해버린 이후 다른 라이브러리를 설치한 다음 그래도 실행되지 않을 경우 기존 Readme 설명을 따라가는 방법으로 해결하면 된다.
PyYAML 에러를 무시하고 install 하는 명령어는 아래와 같다.
pip install --ignore-installed PyYAMLclip.load 메서드 에러
RuntimeError: Method 'forward' is not defined.-
이유
질문을 읽어 봤지만 그나마 내가 이해한 바로는 model_path가 JIT archive가 아닐 때 발생하는 에러라는 것이다.
원래는 발생하지 않았는데, pytorch 버전이 Upgrade되고 CUDA 버전도 Upgrade되면서 발생하는 에러라는 것 같다.
(OpenAI 쪽에서 학습시킨 모델은 Jit Archive 형식으로 저장한 뒤 Parameter를 우리에게 전달해주고, 우리가 학습시킨 model은.ckpt파일 등을 통해 불러오다보니 이런 에러가 발생한 게 아닐까 싶다) -
해결 방법
우리가 학습시킨 model은 Jit Archive 파일 형식이 아니기 때문에jit=False로 설정하면 해결되는 문제이다.
model, preprocess = clip.load({학습시킨 model_path}, jit=False)Permission 에러
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: UNPROTECTED PRIVATE KEY FILE! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
Permissions 0644 for '/Users/tudouya/.ssh/vm/vm_id_rsa.pub' are too open.
It is required that your private key files are NOT accessible by others.
This private key will be ignored.
bad permissions: ignore key: /Users/tudouya/.ssh/vm/vm_id_rsa.pub
Permission denied (publickey,password).-
이유
상당히 재미있는 에러였다. Window에서 발생했던 에러였는데, Key값의 "권한" 때문에 발생한 에러였다.
Key와 관련된 파일의 권한은 400, 즉 나만 읽을 수 있게 하는 권한이여야 된다는 것이다. -
해결 방법
MAC 등이라면 그냥 CLI로chmod 400 {key File}을 통해 접근을 변경해주면 되고, Windows라면 조금 귀찮지만 직접 파일의 고급 설정에 들어가 나만 읽기 권한을 가지도록 권한을 변경해주면 된다.
NVIDIA 관련 에러
Found no NVIDIA driver on your system.
Please check that you have an NVIDIA GPU and installed a driver from...-
에러 내용
분명히nvidia-smi명령어를 통해 설치가 된 것을 봤는데 이상하게 GPU를 활용하려 하면 발생한 에러였다. -
질문 : https://discuss.pytorch.org/t/found-no-nvidia-driver-on-your-system-but-its-there/35063
-
이유
nvidia Driver는 설치되었는데, 이를 활용하기 위한 CUDA Tool을 설치하지 않아 발생하는 에러이다. -
해결 방법
cuda Toolkit 등을 활용하여 PyTorch 버전과 맞는 CUDA 버전을 설치하면 된다.
(즉, CUDA가 설치되었고, 설치한 CUDA와 호환되는 PyTorch 버전이 깔려 있으면 해결되는 문제이다)
메모리(CPU) 부족
pip install :: No space left on device-
이유
사실 직관적인 해결 이유이다.
CPU의 공간이 없어 필요한 모듈 설치가 불가능하다는 것이다. -
해결 방법
사실 제일 좋은 방법은 빵빵한 CPU이다.(역시 돈이 짱...)
하지만, 나는 돈이 없기 때문에 Stack Overflow에서 나온 여러가지 방법을 활용해 보았다.
-
df -h로 Disk 체크 & Remount 명령어로 CPU 공간을 더 할당해줌 -
TMPDIR 환경 변수 Setting
-
cache/temp directory를 내가 원하는 곳으로 설정하기
- 그나마 디스크 여유가 있는 곳에 설치
-
Cache Directory를 활용하지 않기
- 자세한 실행 방법은 위 Stack Overflow 사이트의 5번 설명에 들어가 있다.
