오늘 할 것
-
강의 다 듣기 & 과제 수행하기
- Fast-API 관련
-
inference.py를 완벽히 정제하기
- inference.py를 통해 나온 Ouptut을 어떻게 정제해야 더 좋은 이미지를 도출할지 고민해보기
-
Epoch을 증가시켜 학습해보기
- 실제로 Epoch이 증가할 때마다 Loss가 감소하는 것을 보니, 학습이 계속해서 진행되는거 같기는 하다. 원래는 3~4만 실행했었는데 이번에는 7 정도로 실행해보자
-
Huggingface Porting
- Text2Image 크기가 너무 커서 Dialogue Summarization 모델을 Huggingface에 올리고 이를 Text2Image 팀에서 활용하기로 함
오늘 한 것
Fast API 강의 모두 듣기
이전에 배웠던 Spring Framework의 축소판이라고 생각하니 이해하기 편했다.
사실 Spring Framework 자체는 많은 로직이 겹쳐 있어서 이해하는데 시간이 꽤 걸렸었는데, Fast API는 그래도 백엔드를 활용한다는 것 치고는 쉬웠던 것 같다.
inference.py 정제
정제를 모두 완료하였다.
모듈화는 완료하였고, 어떤 형식으로 Text to Image Model의 input으로 넣어줄지는 Text to Image 팀에서 맡아주기로 하여서 믿고 맡겼다.
Epoch을 증가시켜 학습해보기
실험 이유
Train Loss 그래프 및 STS를 보니 계속해서 점수가 증가하는 형식으로 완료됨을 볼 수 있었다.
이렇다보니 내가 설정한 3 Epoch이 Undefitting을 일으키는 것이 아닐까라는 의문이 들었다.
따라서, 5~7 Epoch 정도로 증가시켜 Overfittin이 일어날 때까지 기다리고, Overfitting이 난다고 판단하였을 때 Early Stopping을 시키거나 load_best_model_at_end Parameter를 활용하여 최고 점수의 Model을 받아오는 방법으로 고려해 보았다.
실험 결과
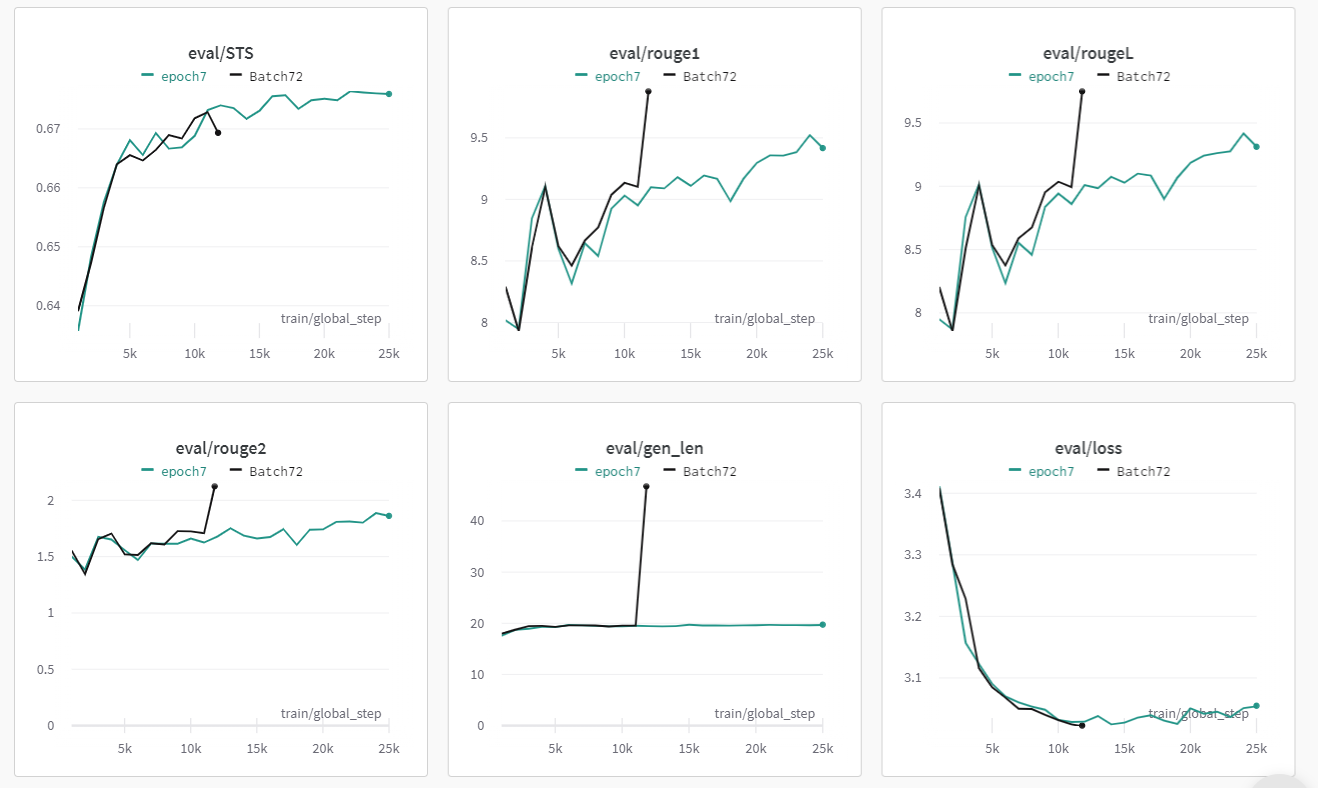
실제 Loss 함수를 봤을 때 3 Epoch이 증가하여 계속해서 학습을 시켰을 때 그렇게 큰 하락은 보이지 않았다.
오히려 Loss 값이 살짝씩 상승하며 Overfitting이 ㅇ리어남을 알 수 있었다.
또한 STS 값도 큰 증가 수치를 보이지 않았으며, 오히려 그래프가 비슷한 지점에서 왔다갔다 하는 것을 보니 큰 효과를 보이지 않을 것이라고 판단하였다.
실제로 해당 모델로 실험했을 때 Epoch 3일 때보다 조금의 성능 향상은 보였지만 그렇게 큰 차이는 아니였다.
또한 성능 향상을 보인 이유 중에 하나가 첫 문장이 조금 길게 형성되었다. 그러다보니 첫 문장이 길게 형성되어 조금 더 많은 정보를 담을 수 있고, 이에 따라 STS가 조금 상승한 것 같았다.
Image to Text Model의 Input으로 활용하기 위해서는 문장이 짧을수록 좋다는 말을 I2T Team에게 들었기 때문에, Epoch 3이 가장 Best Epoch HyperParameter라고 결정하였다.
Huggingface Porting 방법
주저리 주저리
처음에 팀원 중에 한 명이 큰 모델을 Git LFS로 전달해주는 것이 어떻느냐고 추천하였지만 그 당시 Model을 만드는데 너무 바빠서 나중에 해보겠다고 하였다.
결국 Huggingface Porting할 때 해당 기술을 활용하는 것을 보고 참 기술은 돌고 도는구나 라는 생각이 많이 들었다.
사소한 기술이라도 제대로 알고 공부하면 언젠가 도움이 될 수 있는 것 같다.
1. Git LFS 설치
<1단계> : Git LFS Download
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh<2단계> : Git LFS 설치를 위한 준비 과정
sudo bash script.sh- 원래 1단계와 2단계를
|(Pipeline)을 통해 한꺼번에 수행시켜줄수도 있다. 그런데sudo에 대한 권한이 없다면 이 부분이 연결이 되지 않을 수 있어 일부러 쪼개서 수행시켰다.
<3단계> : Git LFS 설치
sudo apt-get install git-lfs<4단계> : git-lfs를 활용하고 싶은 Directory로 이동
cd [Project Direcotry]-
나 같은 경우 학습시킨 모델을 Huggingface에 올리고 싶은 것이기 때문에 모델이 학습되는 코드인
train.py와 동일한 Directory로 이동하였다- 최종적으로 학습시킨 모델을 Huggingface에 올릴 것이기 때문
-
만약 Jupyter Notebook 등으로 따로 모델을 불러와서 저장시키려면 해당 Notebook 파일이 있는 곳으로 이동해야 한다
<5단계> : Huggingface 계정 설정해주기
git config --global user.email "Huggingface Email"
git config --global user.name "Huggingface Name"2. Huggingface에 Porting하기
- CLI와 Python 2가지 방법이 존재하지만, 나는 Python 방법을 활용하였으므로 이에 대해서만 설명함
## repo
save_name = 'model_name' # Model Name
key_value = 'API_TOKEN'
model.push_to_hub(
save_name,
use_auth_token=key_value
)
tokenizer.push_to_hub(
save_name,
use_auth_token=key_value
)- push_to_hub를 통해 Model 및 Tokenizer 저장이 가능함
use_auth_token- Huggingface에 Porting하기 위해서는 Huggingfaec에서 API key값을 받아야 함
- 아래에서 설명한대로 key값을 받았다면, 이 값을 복사하여
API_TOKEN위치에 넣어주면 된다.
결과

- 모델이 Huggingface에 올라간 것을 볼 수 있다.
Huggingface Key값 받기
1. 오른쪽 위 계정 클릭 후 Settings 클릭
2. Access Tokens Section 들어가기
New Token을 클릭후 Role을 'Write'로 지정하면 생성됨
- 위 사진에서
공유 Write의 Key값을 복사하여 활용하면 됨
여기서 중요한 점은 꼭 Role을 'Write'로 지정해야한다.
우리는 Porting하기를 원하기 때문에, Huggingface에 무언가를 쓰는 행동을 하고 싶다고 봐도 무방하다.
그런데, Read로만 설정한다면 API Key값의 권한을 넘어서는 일을 수행하고 싶어하는 것이므로, 권한에 대한 에러가 발생하게 될 것이다.
(어떻게 아냐고? 내가 그걸 직접 당해봤다....)
느낀점
inference.py 파일까지 만들고 이제는 프로젝트가 거의 막바지라는 것이 느껴진다.
Product Serving을 어떻게 해야할지 머리가 살짝 아프기는 하지만, 일단은 모델 형성을 완성했다는 것에 대해서 만족해야 할 것 같다.
내일 팀원과 얘기해서 Diagloeu Summarization 팀과 Data 팀에 어떻게 일을 분배해야 효율적으로 인력을 쓸 수 있을지 고민하여 담당하는 일을 재분배해야겠다.
(Text-to-Image 팀은 성능 향상에 신경을 많이 써야할 것 같으니, 최대한 T2I 팀은 모델에 집중하게 하고, 나머지 사람들이 Product Serving을 맡아야 할 거 같다)
