오늘 할 일
-
모델 성능 올리기
- Input Data 변경해보기
- model이 생성한 Output을 정제해보기
-
현재 num_beams를 활용하여 문장을 생성하고 있는데, 다음 단어로 판단하는 기준을 바꾸거나 새로운 방식으로 문장을 생성하는 방법을 알아보고, 적용하기
오늘 한 것
Input Data 변경해보기
Input Data 앞에 화자에 대한 정보 전달
- 논문 : Controllable Neural Dialogue Summarization with Personal Named Entity Planning
위 논문에서 사람에 관련된 NER을 수행하고, 이를 활용해 Input Data를 형성해주면 더욱 좋은 결과가 나온다고 말하고 있다.
물론, Encoder과 Decoder 사이에 Fusing Conference Layer를 넣어줘야 하며, 화자 뿐만이 아닌 대화에서 나온 모든 Person에 대하여 NER을 수행해야한다.(이 논문에 따르자면)
하지만, 팀원과 했던 대화에서 우리는 더 이상 모델을 키우지 말자라는 의견이 나왔었다.
따라서, 새로운 Layer를 추가하거나 새로운 Model을 덧붙이는 방식은 지양하고 싶었고, Modeling 없이 쉽게 수행할 수 있는 화자에 대한 정보만 앞에 덧붙이는 방식을 활용해보았다.
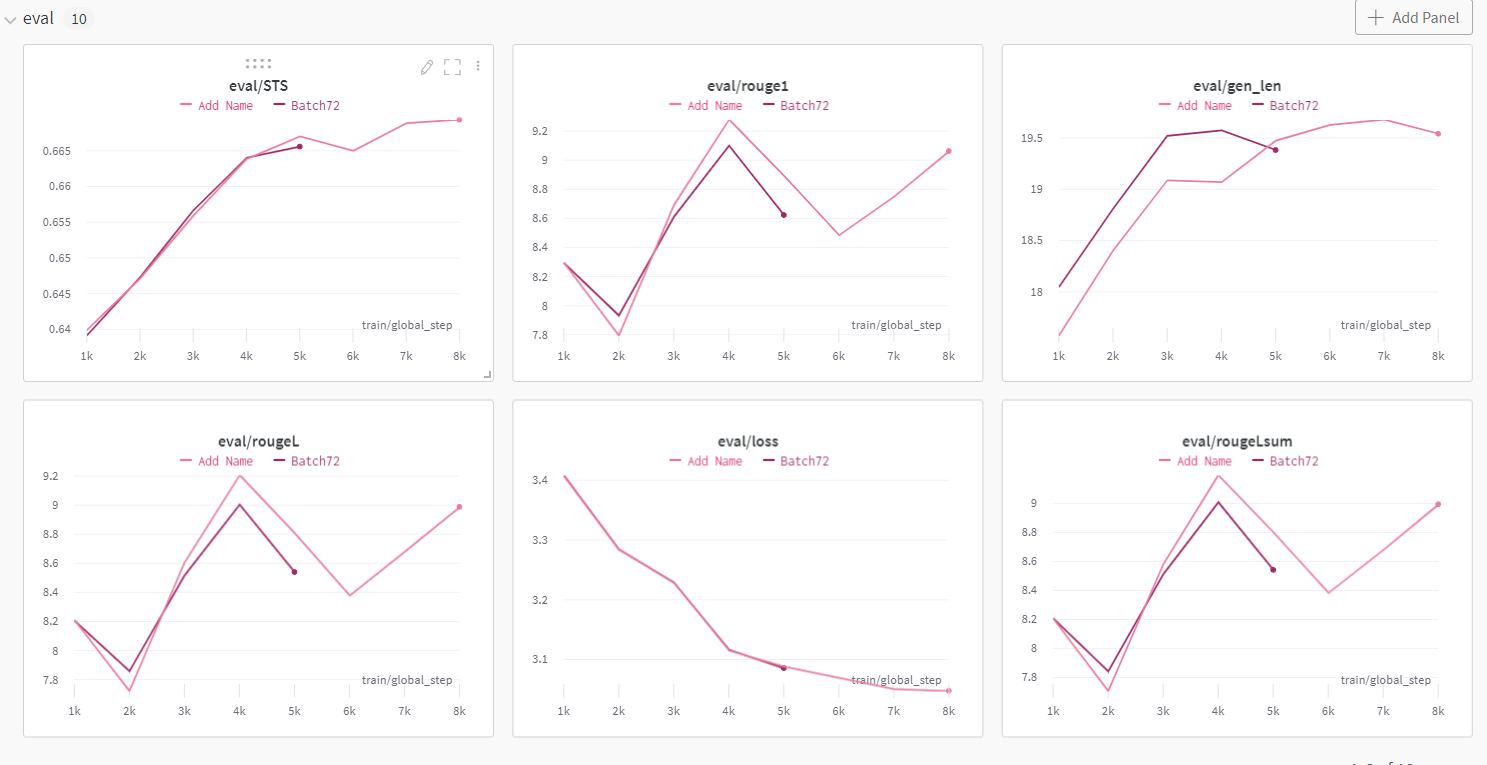
분홍색이 이름을 추가한 건데, 생각보다 점수가 조금은 올랐음을 알 수 있었다.
이를 활용하여 한 번 학습을 시켜봐야겠다.
당황한 점
내가 저번에 확인했을 때는 이름 붙인게 더 나쁘게 나왔었는데 그 때 진짜 많이 피곤했었나보다. 실제로 점수가 향상되는 것을 보니, 다음 학습 때부터는 이를 활용해봐야겠다.
Model Ouput 정제
이 부분에 대해서는 우리가 1문장만 Text2Image 팀에 전달하면, 그 팀에서 필요한 후처리를 진행하기로 하여 따로 건들지는 않았다.
Generation 전략
매우 흥미로운 사이트를 찾았고, 여기에서 많은 정보를 얻었다.
Top-K라는 확률 순위가 K보다 낮다면 제거하는 기법, Top-p라는 누적 확률을 고려하는 기법, 샘플링 전략 등에 대해 알게 되었고 이를 실제로 적용해보니 결과가 더 좋게 나오는 것을 알게 되었다.
Task에 따라, 그리고 상황에 따라 안 좋을 수도 있다고 하였지만 내 모델의 경우 더 좋은 Output을 내게 되어 이를 활용하기로 했다.
단지, Sampling 기법은 Beam Search 방법보다 더욱 많은 단어 중복이 되도록 문장이 생성되어 Beam Search 기법을 활용하는 것이 더 좋아보인다.
느낀 점
정말 많은 것을 배웠던 3일이였다.
beam Search에 대해서만 알고 있었는데, 찾아보니 많은 생성 방법이 있었고, 이런 방법을 실행해보면서 많은 재미를 느꼈었다.
조금 아쉬운 점은 Input Data를 변경시키는 몇 가지 방법이 그렇게 좋은 성능을 내지 않았다는 것이다.
물론, 논문에서 구현한 대로 실험해보진 않아 확신을 가지고 성능이 오를 것이라 예측하지는 않았지만, 그래도 살짝 오르기를 기대한 건 사실이다.
어쨌든, inference.py도 만들면서 Dialogue Summarization 모델은 어느정도 완료된 것 같다.
다음 주는 파이프라인 및 백엔드 쪽을 구현해보며 프로젝트의 끝을 어느 정도 봐야할 것 같다.
1주만 더 고생하자!
