데이터로 할 수 있는 것?
데이터를 통해 사용자의 서비스 경험을 개선하고 운영비용을 감소시켜 결과적으로 회사의 의사결정을 도울 수 있다.
하지만 전적으로 데이터만 믿고 따라가기만 한다고 성공을 보장할 수 없다.
따라서, 아래의 data decision을 대표하는 두 정의를 살펴보고 '데이터에 의한 결정은 무조건 옳다'라는 편협한 사고를 없애야 한다. 결과적으로, 회사의 크기와 상황에 맞는 결정론을 기반으로 의사결정을 진행해야 한다는 것이 중요하다.
Data driven decision vs Data informed decision
Data driven decision : 결정의 주체와 수단이 모두 데이터인 data-decison
기본적으로 데이터를 기반으로 의사결정을 진행합니다. 개인의 주관을 배제하고, 어떤 선택이 나은지 결정할 수 있는 가설을 테스트 및 검증하여 결과를 의사결정에 반영하는 것입니다.
Data informed decision : 위와 같이 결정의 주체는 사람이지만, 수단에는 데이터를 포함한 다른 결정 요소들이 개입하는 data-decison
데이터를 보고 주관적인 의견을 생성하여 결론을 도출하는 것이라고 이해하면 될 것 같다. 따라서, 해당 결정을 진행하기 위해서는 기본적으로 Data Team의 인원들과 의사결정 주체가 주요 지표와 도메인 지식에 대한 이해도가 필수적으로 요구될 것이다.
Data Team 구성
모든 데이터 팀이 아래와 같이 이루어져 있다고 말할 수 없지만, 성숙한 데이터 팀의 경우 보통 아래 사진과 같은 구성을 보인다.
(그림에 재능은 없으니 이해해 주시길...ㅎ)보통 Data Team의 구성원들은 아래와 같은 직군으로 분류된다.
🔼 = Data Scientist
⏹️ = Data Analyst
⏺️ = Data Engineer
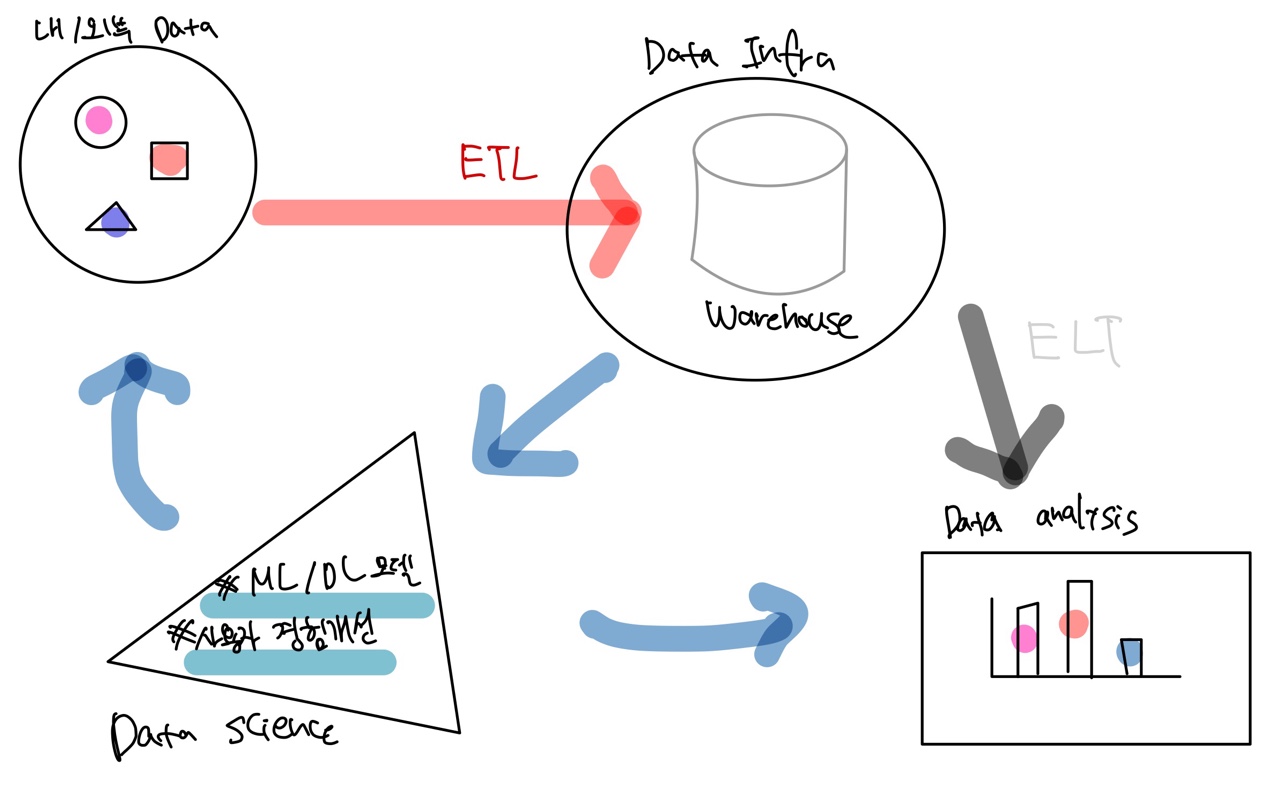
데이터 분석가
- 데이터 웨어하우스의 데이터를 기반으로 지표를 만들고 대시보드를 통한 시각화
- 내부 직원들의 데이터 관련 질문 응답
데이터 사이언티스트
- 인공지능 모델을 개발하여 서비스 개선 (개인화, 자동화, 최적화)
데이터 엔지니어는 아래에서 따로 설명하려고 한다 :)
Data Engineer's Role
소프트웨어 엔지니어링
- 기본적으로 벡엔드 프레임워크를 사용하여 API를 개발할 수 있어야 한다고 생각한다. 여러가지 상황이 있겠지만 데이터를 처리하는 전반적인 과정일 수 있고, 머신러닝 엔지니어의 역할을 한다면 프로덕션 단계에서 ML/DL 모델이 API로써 역할을 할 수 있게 만들어 줘야 할 것이다. 또한 데이터 분석가에게도 필요한 API나 데이터를 공급해야 한다.
데이터 웨어하우스 (DW) 구축
- 주로 클라우드 서비스로 관리하는 추세이다 (ex:
BigQuery,Redshift,Snowflake)
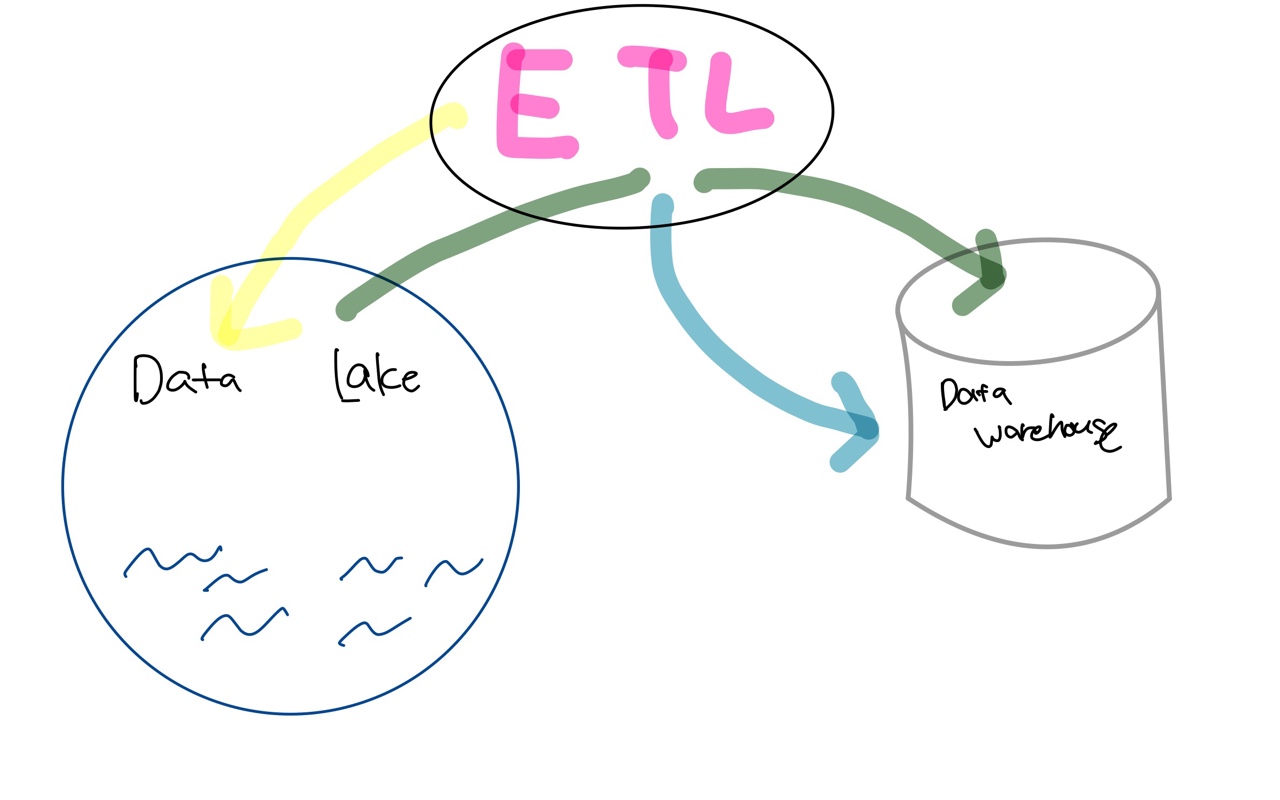
데이터 파이프라인 구축 (ETL)
-
ETL: 기존의 데이터베이스에서 원하는 정보를 데이터 웨어하우스에 적재하는 것 ⇒ 추출(Extract), 변환(Transform), 로드(Load)의 과정을 의미한다. 이러한 과정에 필요한 스케줄링은 보통 Airflow로 많이 관리한다.
-
ELT: 데이터 웨어하우스에 적재된 데이터를 새로운 정보 혹은 요약된 정보로 제공하는 것이다. 주로, DBT가 해당 역할을 포함하여 늘 데이터 엔지니어를 피곤한게 하는 data transform 과정을 효율적으로 처리하게 해주고 있어, 많은 회사들이 해당 기술을 채용하고 있다.
-
어느정도 성숙한 Data team에서는 Amazon S3와 같은 서비스를 이용하여 데이터 레이크를 구축하는데, 위 사진의 초록 화살표의 과정에서는 Spark와 같은 빅데이터 처리 시스템이 많이 쓰인다.
Why OLAP?
아예 데이터 엔지니어링 분야를 모르거나, 개발을 처음 접하는 분들은 문득 이런 생각이 들 수 있다.
'그냥 Backend Engineer가 서비스 DB에 적재된 데이터를 기반으로 위의 역할들을 잘 소화하면 되는 것 아닌가?'
아마, 이러한 물음은 '서비스를 하고 있는 OLTP 시스템 내에서 그냥 분석하면 되는 것 아니야?' 라는 물음으로 치환되어 발생하는 것으로 생각된다.
하지만, OLTP (Online Transaction Processing) 에서 직접 분석을 실행하기에는 한계점이 매우 많다.
물론, 일회성 분석이나 소규모 기업에서는 OLTP에서 직접 분석을 실행하는 경우도 있지만, 단기적으로는 효과적일 수 있어도 궁극적으로 확장성이 매우 떨어진다. 어떤 시점에서 OLTP의 구조적 제한이나 경쟁 트랜잭션 워크로드와의 리소스 경합 때문에 성능 문제가 발생할 수 있다.
따라서, 트랜잭션을 처리하기 위해 설계 된 시스템이 아닌, 대규모 분석 쿼리를 실행하도록 구축되어 있는 OLAP (Online Analytical Processing) 시스템이 필요하다.
보통의 OLAP 시스템은 열 기반으로 설계되어 있어, 대량의 데이터를 스캔하도록 최적화 되어 있습니다. 우리가 위에서 언급한 DW 솔루션들은 모두 같은 특징을 가지고 있다. 참고로, OLAP 시스템에서는 인덱스나 PK와 같은 OLTP에서 우리가 빠르게 데이터를 조회하기 위해서 사용하는 것들은 사용되지 않는다. 모든 쿼리에는 일반적으로 100MB 이상인 최소 데이터 블록을 스캔하는데, 이러한 시스템에서 초당 수천 개의 개별 항목을 조회하려고 하면 그 사용 사례에 맞게 설계된 캐싱 계층과 결합되지 않는 한 시스템이 중단될 것이다.
참고로, 초기 데이터 웨어하우스는 보통 트랜잭션 어플리케이션에 사용되는 것과 같은 RDBMS를 기반으로 구축되었었는데, MPP (Massively Parallel Processing) 시스템의 인기가 높아지면서 대용량 데이터에 걸쳐 검색 성능을 크게 개선할 수 있는 병렬 프로세싱으로 전환되었다고 한다.
구체적으로, OLTP 시스템에서 가장 많이 쓰이는 MySQL과 MongoDB, 그리고 OLAP 시스템 내에서 가장 인기있는 데이터 웨어하우스 솔루션인 BigQuery에 대한 심층적인 분석을 진행한 포스팅을 현재 게시했으니 관심이 있으시면 확인해주세요 :)
Data Discovery
사실, 데이터 엔지니어의 역할은 위에서 언급한 역할들에만 국한되지는 않습니다.
회사와 Data Team이 성장해가며 아래와 같은 시나리오가 그려질 수 있다.
Problem
- 데이터가 커지면 테이블과 대시보드의 수가 증가 → 정보과잉의 문제
- 데이터 분석 시 어느 테이블이나 대시보드를 봐야하는지 혼란 → 효율성의 문제
- 데이터 변환 때문에 데이터 집합이 동일한 경로에서 어떻게 파생되었는지 알기 어려움
위와 같은 문제들은, Data Catalog 혹은 Data Discovery 문제로 치환될 수 있기 때문에, 데이터의 계보를 유지하고 모니터링할 수 있는 것도 성장된 데이터 팀에서의 데이터 엔지니어의 역할 중 하나입니다. 보통 아래와 같은 솔루션을 통해 해당 문제를 해결합니다.
Solution
- 데이터 조회가 적은 사항에 대해 데이터 분석가와 협의하거나 자체적으로 사용 빈도를 추적하여, 주기적으로 테이블과 대시보드를 클린업 진행
- Datahub나 Amundsen과 같이 Data Discovery에서 주로 발생하는 문제를 해결해주는 서비스를 이용
참고문헌
- 견고한 데이터 엔지니어링 (written by Joe Reis & Matt Housley)
- https://dovetail.com/product-development/data-driven-vs-data-informed/
