도입
본 글은 Baekjoon에서 제공하는 알고리즘 문제 및 유저 데이터를 분석하는 solved.ac 서비스 및 API를 사용하여 관련 데이터를 추출한 뒤, DW/DM을 생성하고 ETL을 구축하는 프로젝트의 일부 과정에 해당하는 내용입니다 :)
본 내용에서 설명하는 구체적인 상황과 문제점은 아래와 같습니다.
상황
solved.ac API를 호출하여, 알고리즘 문제 관련 데이터를 추출하여 csv에 저장해야 한다.
아무런 성능 개선 코드가 적용되지 않은 기본 API호출 코드는 아래와 같을 것이다.
import requests
url = "https://~~~"
headers = {"Accept": "application/json"}
page = 1
while True:
querystring = {"query": '', "page": str(page)}
response = requests.get(url, headers=headers, params=querystring)
data = response.json()
for item in data['items']:
if item['tier'] < 27: # If the 'tier' is less than 7
break
page += 1문제점
일단 프로젝트 여건 상 로컬에서 파이프라인 실행해야 하기 때문에, 데이터가 커질수록, 메모리나 디스크 i/o와 같은 성능 이슈 발생한다. 또한, 위와 같은 이유일 수도 있겠지만 기본적으로 API를 호출하여 데이터를 추출하여 DW/DM에 적재하는 총 파이프라인 실행시간이 매우 길다.
문제가 발생한 이유를 pandas를 이용하여 데이터를 csv에 저장하는 방식에서 병목이 일어났다고 판단하여 디스크 i/o와 Memory를 활용하여 csv에 데이터를 저장하는 방식을 비교해보려고 한다. 또한, 전체적인 파이프라인 실행속도를 높이기 위해 우선 데이터를 추출하는 과정에서 파이썬 비동기 (async)를 도입한다.
디스크 i/o vs Memory
일반적인 상식으로 생각해보면, 메모리를 활용한 방식이 더 빠를 것이고 코드의 가독성도 좋다.
아무리 좋은 SSD를 구비하여 i/o속도를 높여도, 메모리 용량을 업그레이드하는 것보다 컴퓨터 성능 개선에 효과적이지 않다는 것을 들어 보았을 것이다.
pandas 공식 문서에서도 메모리를 활용한 방식을 채택한다.
https://pandas.pydata.org/docs/user_guide/scale.html
그래도 일단 비교를 위해 두 방식을 모두 실행해보자.
디스크 i/o를 활용한 추출
한번에 모든 데이터를 csv를 적재하는 것이 아닌 일정 bunch단위를 미리 정해놓고, 데이터가 정해놓은 데이터 단위 기준에 다다르면 그때마다 csv를 적재하는 방식이다.
디스크 i/o를 활용한 code
async def collect_data_and_save_to_csv():
url = "https://~~~"
async with aiohttp.ClientSession() as session:
count = await fetch_page(session, url, 0, ua.random)
max_page = count['count'] // 50 + 1
csv_file = os.path.join(os.getcwd(), 'async_get_user.csv')
start_time = time.time()
user_agent = ua.random
try:
page = 1
while page <= max_page:
if page % 100 == 0:
user_agent = ua.random
data = await fetch_page(session, url, page, user_agent)
if data is None:
continue
items = data['items']
filtered_items = []
for item in items:
if item['tier'] == 6:
print("Tier 6 reached. Stopping data collection.")
return
filtered_item = {
'handle': item['handle'],
'solvedCount': item['solvedCount'],
'tier': item['tier'],
'rating': item['rating'],
'ratingByProblemsSum': item['ratingByProblemsSum'],
'ratingByClass': item['ratingByClass'],
'ratingBySolvedCount': item['ratingBySolvedCount'],
'ratingByVoteCount': item['ratingByVoteCount'],
'class': item['class'],
'maxStreak': item['maxStreak'],
'joinedAt': item['joinedAt'],
'rank': item['rank']
}
filtered_items.append(filtered_item)
df = pd.DataFrame(filtered_items)
if page == 1:
df.to_csv(csv_file, index=False, encoding='utf-8')
else:
df.to_csv(csv_file, mode='a', header=False, index=False, encoding='utf-8')
page += 1
print(f"현재 페이지: {page}")
except Exception as e:
print(f"An error occurred: {e}")
return
end_time = time.time()
execution_time = end_time - start_time
print(f"Task 실행 시간: {execution_time}초")
print("Data collection and saving completed successfully.")
실행시간
Tier 6 reached. Stopping data collection.
총 소요 시간: 512.5091943740845
메모리를 활용한 추출
위와 달리, 데이터를 호출하고 메모리에 담은 뒤 한번에 csv형태로 저장하는 방식이다.
async def collect_data():
url = "https://~~~"
async with aiohttp.ClientSession() as session:
count = await fetch_page(session, url, 0, ua.random)
max_page = count['count']//50+1
data_list = []
try:
page = 1
user_agent = ua.random
while page <= max_page:
if page % 100 == 0:
user_agent = ua.random
data = await fetch_page(session, url, page, user_agent)
if data is None:
continue
items = data['items']
filtered_items = []
for item in items:
if item['tier'] == 6:
print("Tier 6 reached. Stopping data collection.")
return data_list
filtered_item = {
'handle': item['handle'],
'solvedCount': item['solvedCount'],
'tier': item['tier'],
'rating': item['rating'],
'ratingByProblemsSum': item['ratingByProblemsSum'],
'ratingByClass': item['ratingByClass'],
'ratingBySolvedCount': item['ratingBySolvedCount'],
'ratingByVoteCount': item['ratingByVoteCount'],
'class': item['class'],
'maxStreak': item['maxStreak'],
'joinedAt': item['joinedAt'],
'rank': item['rank']
}
filtered_items.append(filtered_item)
data_list.extend(filtered_items)
print(f"현재 페이지: {page}")
page += 1
except Exception as e:
print(f"오류 발생: {e}")
return
return data_list
실행시간
아래와 같이 특정 상황에서 멈추는 상황이 발생하였다. 여기서 주목할 점은, 멈추는 페이지의 지점이 실행 시마다 비슷하다는 점이다. 따라서, 디스크 i/o를 활용하는 방식을 채택하지 않는다면, 메모리 제한 및 gc 관리가 필요할 것으로 예측할 수 있다.
Problem
사실 현재 측정하는 실행 속도는 로컬 환경의 요소로만 결정되지는 않는다.
외부적 요소인 네트워크 상태와 request수 제한, 그리고 내부적 요소인 python garbage collection와 pandas 메모리 할당 등의 여러 변수가 있기 때문에 총 소요시간을 통해 명확한 결론을 낼 수는 없다.
단지, 이러한 모든 가능성을 인지하고 상황에 따른 엔지니어링을 해야한다는 것이 중요하다.
일단, 문제점을 정리해보면 아래와 같을 것이다.
외부적 요인: 네트워크, API request 제한
주의
크롤링을 할 때는 robots.txt, API를 호출할 때는 어디가에 숨어있을 API가이드라인을 통해 명확히 request수 제한과 같은 제한사항을 꼭 체크하자. 이미 IP block이 이루어졌다면, 제한이 풀리길 기다리거나 VPN을 사용하는 방법을 사용해야 하니, 미리미리 인지하고 따르자.
어떠한 내부적인 요소를 fix하여 퍼포먼스를 개선한다 해도, 네트워크 환경이 작업을 제한하면 의미가 없다.
제한을 지키며 극한의 퍼포먼스를 내기 위해서는 최대한 API 가이드라인에 따라 호출 시간을 sleep()을 활용하여 지연시키거나, asyncio에서 await을 사용하여 API 서버에 피해를 주지 않아야 한다.
위 사항으로 만족(?)되지 않는다면, 극한의 최적화를 위한 다음과 같은 방법들이 있을 수 있다. (권장 X)
User agent 변경
Python에서는 fake user agent 라이브러리를 활용하여 매 호출, 혹은 특정 횟수마다 user-agent를 변경해주면 다른 유저로 인식하여 request수 제한 같은 요소를 피할 수 있다.
하지만, 이러한 이상한(?)행위도 봇으로 쉽게 식별될 수 있다는 점을 인지하자.semaphore 활용
멀테쓰레딩을 사용하고 있다면, semaphore로 쓰레드 수를 제한하여 실행 속도를 조절할 수 있다.
내부적 요인: 메모리 부하
한번에 모든 데이터를 메모리에 저장하고, 이를 변환하는 행위는 메모리의 부하를 발생시킬 수 있다.
해결책은 뻔하겠지만, 나눠서 변환하면 된다! 또한, gc를 사용하여 적절히 메모리 관리를 개선할 수 있다.
아래 코드는 10페이지마다 한 번씩 gc.collect()를 호출하여 메모리 관리를 개선한 code이다.
import gc
import aiohttp
import asyncio
from fake_useragent import UserAgent
ua = UserAgent()
async def fetch_page(session, url, page, user_agent):
headers = {'User-Agent': user_agent}
params = {'page': page}
async with session.get(url, headers=headers, params=params) as response:
if response.status == 200:
return await response.json()
return None
async def collect_data():
url = "https://~~~"
async with aiohttp.ClientSession() as session:
count = await fetch_page(session, url, 0, ua.random)
max_page = count['count'] // 50 + 1
data_list = []
try:
page = 1
user_agent = ua.random
while page <= max_page:
if page % 100 == 0:
user_agent = ua.random
data = await fetch_page(session, url, page, user_agent)
if data is None:
page += 1
continue
items = data['items']
filtered_items = []
for item in items:
if item['tier'] == 6:
print("Tier 6 reached. Stopping data collection.")
return data_list
filtered_item = {
'handle': item['handle'],
'solvedCount': item['solvedCount'],
'tier': item['tier'],
'rating': item['rating'],
'ratingByProblemsSum': item['ratingByProblemsSum'],
'ratingByClass': item['ratingByClass'],
'ratingBySolvedCount': item['ratingBySolvedCount'],
'ratingByVoteCount': item['ratingByVoteCount'],
'class': item['class'],
'maxStreak': item['maxStreak'],
'joinedAt': item['joinedAt'],
'rank': item['rank']
}
filtered_items.append(filtered_item)
data_list.extend(filtered_items)
print(f"현재 페이지: {page}")
page += 1
# 특정 간격으로 가비지 컬렉션 실행
if page % 10 == 0:
gc.collect()
except Exception as e:
print(f"오류 발생: {e}")
return
return data_list
위와 같이 코드 개선은 기존에 비해 20배 이상의 실행속도 개선을 가져왔다.
실행시간 (개선)
Tier 6 reached. Stopping data collection.
총 소요 시간: 25.1141256242419
결국은 Multi-Process?
모든 개선 과정을 끝내고 문득 이러한 생각이 들었다. 그냥 멀티 프로세싱을 쓰면 안되나?
이러한 흐름으로 처음 멀티 프로세싱을 접하게 되었다.
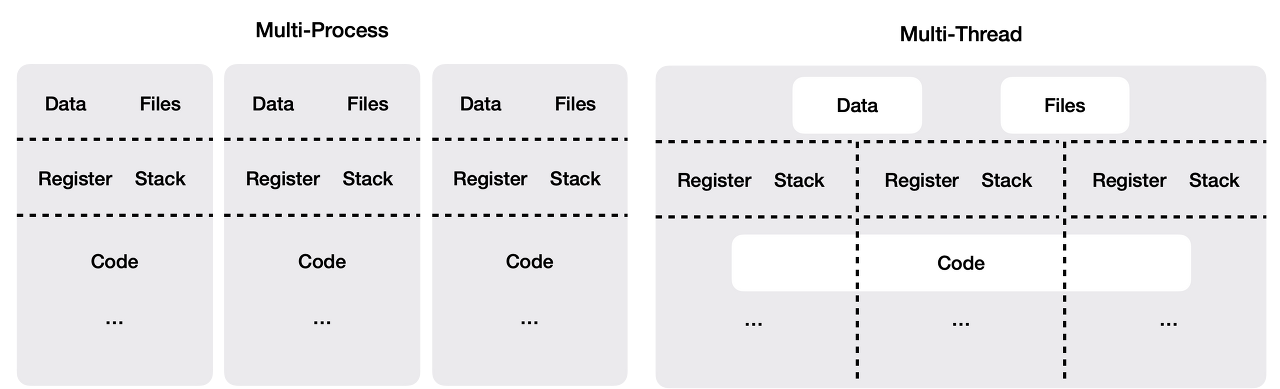
일반적으로, 실행속도 개선을 위해서 멀티 쓰레드, 비동기 호출, 멀티 프로세싱을 활용할 수 있다.
각각의 대한 정의를 간단하게 정리해보면 아래와 같을 것이다.
멀티프로세싱 (Multi-processing)
멀티프로세싱은 여러 프로세스를 생성하여 병렬로 작업을 수행하는 방식으로, 각 프로세스는 별도의 메모리 공간을 사용하여 CPU 집약적인 작업에서 성능을 향상시킨다.
비동기 (Asynchronous)
비동기 프로그래밍은 작업이 완료될 때까지 기다리지 않고 다른 작업을 계속 수행하는 방식으로, 주로 io 바운드 작업에서 효율성을 높이고 응답성을 개선한다.
멀티쓰레딩 (Multit-hreading)
멀티쓰레딩은 단일 프로세스 내에서 여러 쓰레드를 생성하여 병렬로 작업을 수행하는 방식으로, 메모리를 공유하며 CPU 및 io 바운드 작업의 성능을 향상시킨다.
하지만 python은 GIL때문에 멀티 쓰레딩에 제한적일 수 밖에 없고 데이터의 매우 커질 경우 극한의 퍼포먼스를 위해서는 병렬처리를 선택할 수 밖에 없다고 생각한다. 멀티 프로세싱을 적용하여 최종 코드를 개선하면 아래와 같을 것이다.
import gc
import aiohttp
import asyncio
from fake_useragent import UserAgent
from concurrent.futures import ProcessPoolExecutor
ua = UserAgent()
async def fetch_page(session, url, page, user_agent):
headers = {'User-Agent': user_agent}
params = {'page': page}
async with session.get(url, headers=headers, params=params) as response:
if response.status == 200:
return await response.json()
return None
async def process_page(session, url, page):
user_agent = ua.random
data = await fetch_page(session, url, page, user_agent)
if data is None:
return []
items = data['items']
filtered_items = []
for item in items:
if item['tier'] == 6:
print("Tier 6 reached. Stopping data collection.")
return filtered_items
filtered_item = {
'handle': item['handle'],
'solvedCount': item['solvedCount'],
'tier': item['tier'],
'rating': item['rating'],
'ratingByProblemsSum': item['ratingByProblemsSum'],
'ratingByClass': item['ratingByClass'],
'ratingBySolvedCount': item['ratingBySolvedCount'],
'ratingByVoteCount': item['ratingByVoteCount'],
'class': item['class'],
'maxStreak': item['maxStreak'],
'joinedAt': item['joinedAt'],
'rank': item['rank']
}
filtered_items.append(filtered_item)
return filtered_items
async def collect_data():
url = "https://~~~"
async with aiohttp.ClientSession() as session:
count = await fetch_page(session, url, 0, ua.random)
max_page = count['count'] // 50 + 1
loop = asyncio.get_event_loop()
tasks = []
with ProcessPoolExecutor() as executor:
for page in range(1, max_page + 1):
tasks.append(loop.run_in_executor(executor, process_page, session, url, page))
data_list = await asyncio.gather(*tasks)
# Flatten the list of lists
data_list = [item for sublist in data_list for item in sublist]
# 특정 간격으로 가비지 컬렉션 실행
gc.collect()
return data_list하지만, 로컬과 같이 제한된 상황에서 core 수를 늘릴 수 있는 상황이 아니면, 사실상 멀티프로세싱을 통한 개선은 의미가 없다.
결국, 앞서 i/o vs Memory에서의 논점과 같이 문제가 발생하는 상황에 따라 적절한 대응방식을 상이하기 때문에, 단순 비교를 하는 것은 불가능하다.
고찰
결국 개발자의 실력은 기술적 이해도를 바탕으로 상황에 맞는 최적의 방법을 도출하는 수준에 비례하는 것 같다. 그래서, 경험과 지식을 기반으로 나름의 기준을 미리 설정하는 습관이 중요하다고 생각한다.
나는 고민의 시간을 줄이기 위해 나름의 3가지 고려사항 및 기준을 세웠다.
- 간단한 태스크인가?
개인적으로 가지고 있는 기준은 일단 간단한 태스크라면 15분 안에 실행이 끝나야 한다.
15분의 기준은 AWS Lambda와 같은 severless 환경에서 요구하는 최대 실행 시간이다.
말 그대로, severless에서 task를 돌릴만큼의 심플한 태스크이어야 한다.
(Airflow의 과부하를 줄이고 간단한 task는 Lambda에서 진행 -> Lambda task call Dag) - 쓰레드 간의 연관성이 결과에 주요한 영향을 미치지 않아야 한다.
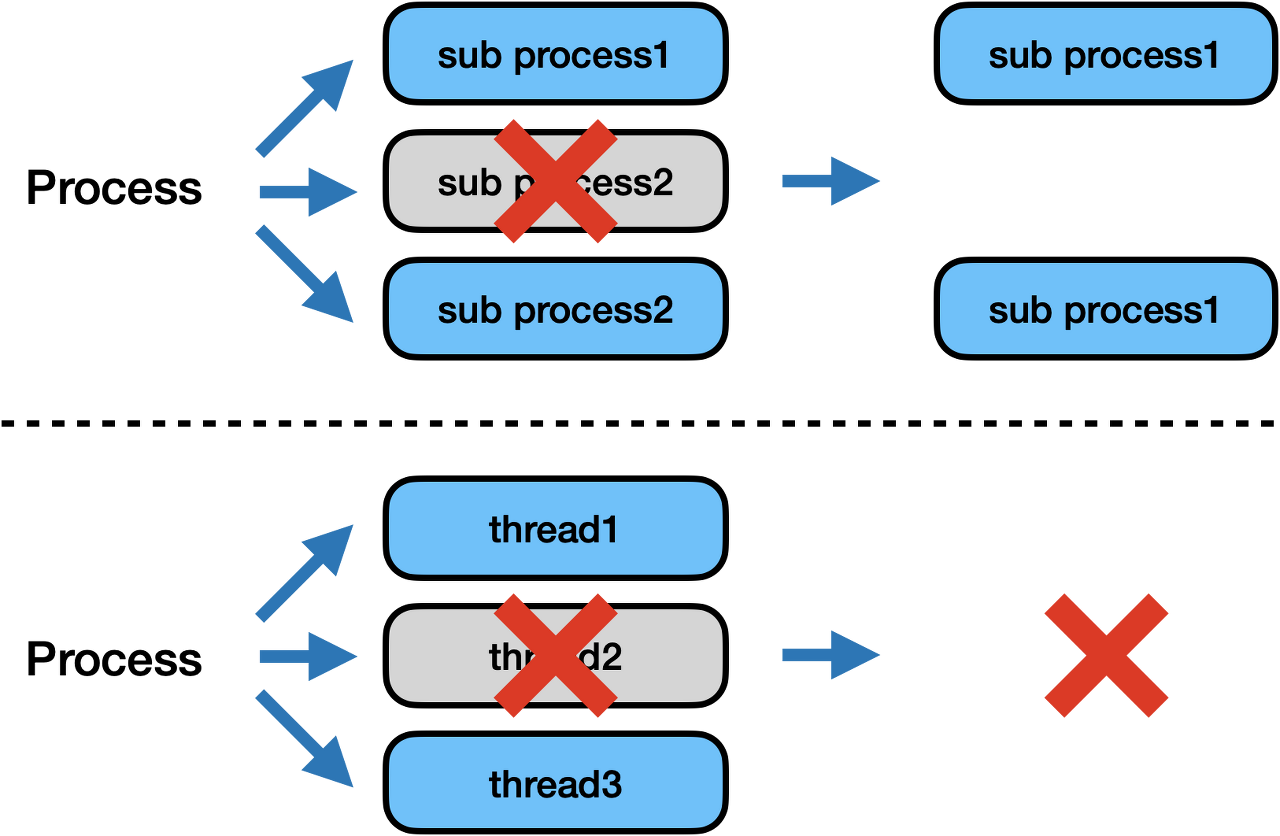
예를 들어, 크롤링 작업이라면 페이지 순서가 고려하지 않아도 된다는 점이다. - 하나의 쓰레드가 실패한다면?
하나의 쓰레드가 실패하면 아래의 사진처럼 전체 프로세스에 영향을 미치게 된다. 따라서 하나의 쓰레드가 하는 일을 정확하게 파악하는 것이 중요하다.
참고문헌
ps. 2024년에서 이 글을 다시 보니, 약간 민망하다. 하지만, 당시에는 해당 인사이트를 얻기까지 엄청난 고뇌의 시간이 들었던 것으로 기억한다.
