
이 글에서는 기본적으로 OpenAI API(ChatGPT)를 활용하여 chatbot을 개발할 때, 중요한 API 2가지를 parameter 중심으로 풀어보고, 경험에서 얻은 Tip과 개인적인 견해를 소개해보려고 합니다.
참고로 각 API 제목에 공식문서 링크가 첨부되어 있습니다 :)
서론
개인적은 생각으로는, Attention is all you need 논문이 나온 뒤, LLM 모델에 대한 연구와 관심도가 폭발적으로 늘어났던 것 같다.
최근 몇년 간, 아카이브(인공지능 한정)는 90프로정도가 중국 연구원분들의 논문으로 채워져 있는 것 같다…
현업에서는 독자적인 LLM 모델을 만들거나 LLAMA와 같은 오픈소스를 활용하여 챗봇을 개발하려는 시도가 많아졌던 것 같다.
OPENAI에서 ChatGPT4가 나오기 전까지는….
ChatGPT가 워낙 general하기도 하고, 답변 생성 성능이 타 모델에 비해 좋기도 해서 이제는 "OpenAI를 잘 활용하자"로 많은 분들의 생각이 변한 것 같다. 물론, 연구비 지원이 가능한 기업들은 독자적인 모델을 지속적으로 개발 중이신 것 같긴하다. 언젠가는 나도 기여하는 날이 왔으면...ㅎ
다만, ChatGPT와 같이 general한 모델 보다는 특정 도메인에 customized된 챗봇을 개발하는 방향으로 산업이 변화하는 것으로 보인다.
이제 어떻게 OpenAI의 API를 사용하여, 나만의 customized chatbot을 제작할 수 있는지 알아보자.
추가로, 본 글에서 설명하는 API는 모두 OpenAI playground에서 미리 체험해볼 수 있으니 꼭 먼저 사용해보길 추천드립니다 :)
1. Text generation API
우리가 흔히 사용하는 웹 ChatGPT를 API로 만들었다고 생각하면 됩니다 :)

Code
공식문서에서 제공한 코드 예시는 아래와 같다.
MODEL = "gpt-3.5-turbo"
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain asynchronous programming in the style of the pirate Blackbeard."},
],
"""
parameters
ex) temperature=1,top_p=1, frequency_penalty=0, presence_penalty=0
"""
)
print(response.choices[0].message.content)
Parameter
message에 해당하는 prompt구성법은 굳이 언급하지 않겠다. 또한, prompt를 구성하는 절대적인 해답 또한 없다. 나중에 prompt-engineering은 따로 포스팅 하겠다.
API parameter가 여러가지 있지만, 아래 5개 정도가 개략적인 답변의 형태를 결정한다.
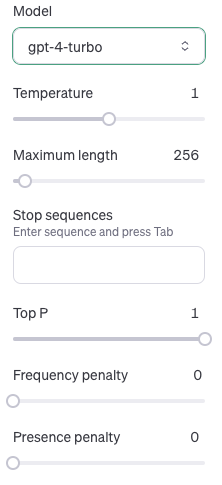
- N: 생성하는 답변 개수 (default = 1)
- Temperature: 값이 높을수록 창의성 & 무작위성 증가 (default = 1)
- TopP: 값이 높을수록 다양한 답변을 생성 (default = 1)
- Frequency Penalty: 값이 높을수록 반복을 더 많이 피하려고 함 (default = 0)
- Presence Penalty: 값이 높을수록 이미 언급된 내용을 피하려고 함 (default = 0)
모두 optional한 것이라 굳이 사용하지 않아도, OpenAI 에서 default로 설정한 값이 사용되도 큰 무리는 없을 것이다. (아마, 우리가 웹 ChatGPT에서 사용하는 값이 default값이 아닐까 생각한다)
다만, 우리가 특정 도메인을 타겟하여 customize한다면 파라미터 운영을 해야하는 순간이 온다.
예를들어, 어떤 도메인은 general하지 않은 즉 창의성이 돋보이는 답변이 생성되어야 할 수도 있고, 어떤 도메인은 outlier가 절대 나타나면 안되고 보편적인 답변이 우선시되어야 할 수 있다는 말이다. 따라서 해당 파라미터를 컨트롤하며, 특정 도메인에 맞는 최적해를 여러 실험을 통해 도출해야 한다. 막상 생각은 안나지만 이해를 돕기위해 도메인 예를 굳이 들어보자면, 전자는 '막장 드라마 대본 생성기', 후자는 '공공기관 고객 응대 챗봇'라고 생각할 수 있겠다.
N
N (응답 개수): 이 파라미터는 챗봇이 한 번에 생성하는 답변의 개수를 결정합니다. 높은 값은 더 많은 수의 다양한 답변을 생성하며, 낮은 값은 적은 수의 답변을 생성합니다.
위 코드에서 아래 line의 인덱스를 보고 의문을 가진다면, 아래의 N parameter 설명을 읽게 되면 이해하게 될 것이다.
print(response.choices[0].message.content)우리가 웹에서 ChatGPT를 사용할 때, 우리는 답변을 1개 받는 이유는 N이 default값 1로 설정되어 있기 때문이다!
가끔, 우리가 답변 2개를 제시받고 그 중 더 선호하는 답변을 선택하라고 할 때가 있는데 그때는 N=2인 상태로 API response를 받는 것이다. 아마, 내부 로직 상에서 해당 답변을 선호된 답변으로 저장하고 아래 2가지 방향으로 develop되지 않을까? 라는 개인적인 생각이다.
- 해당 chat session에 한하여, 선호된 답변의 방향성으로 prompt를 생성하도록 유도
- 후에, 해당 모델을 선호된 답변을 바탕으로 학습모델 fine-tuning
N 파라미터를 활용하는 방법은 2가지로 축약된다.
1. 실험에 대한 검증: N=1로 설정했을 때, 실험 진행 중 생성된 답변에 대한 신뢰성이 보장할 수 없을 때 N값을 증가시켜 생성되는 답변의 양상을 지켜볼 수 있다.
2. 다양한 답변을 도출: 1번의 의도와는 다르게, 애초에 여러 prompt를 생성하고 싶을 수 있다. 다만, 최적 파라미터와 input prompt설정에 대한 실험이 완료되었을 때 추천한다 :)
그 이유는 N=n (n>1)일 때 경험 상, 전체적인 답변의 질이 낮아지는 점, 실험 결과를 객관적으로 분석하기 힘든 점 등이 있어 실험 단계에서는 위 의도를 관철시키는 것이 어렵기 때문이다.
결국 우리의 목표는, N=1인 상태에서 최적의 답변이 생성되어야 한다는 것이다.
Temperature & TopP
Temperature: 이 값은 챗봇의 응답이 얼마나 예측가능한지 또는 창의적인지를 조절합니다. 낮은 온도(예: 0.2)는 더 예측가능하고 일관된 답변을 생성합니다. 높은 온도(예: 2.0)는 더 창의적이고 예상치 못한 답변을 생성합니다. (range: 0 <= Temperature <=2)
TopP: 이 값은 챗봇이 고려하는 답변의 다양성을 조절합니다. 낮은 TopP 값은 챗봇이 더 일반적이고 보편적인 답변을 선택하게 하며, 높은 TopP 값은 더 다양하고 예측 불가능한 답변을 생성합니다.
공식문서에서의 TopP 설명을 번역하면 아래와 같다.
이 설정은 모델이 토큰을 선택할 때, 확률이 높은 상위 일정 비율의 토큰들만 고려하도록 합니다. 예를 들어, top_p가 0.1(10%)로 설정되어 있다면, 모델은 가능한 토큰들 중 확률 합이 상위 10%에 해당하는 토큰들만을 고려하여 다음 토큰을 선택하게 됩니다.
이 방법은 텍스트 생성에서 더 다양성을 부여하거나, 너무 예측 가능한 결과를 피하고자 할 때 유용합니다. 일반적으로 top_p 설정이나 temperature 설정 중 하나를 조정하는 것을 권장하지만, 두 설정을 동시에 조정하는 것은 권장하지 않습니다. 이는 두 설정 모두 생성 텍스트의 다양성과 예측 가능성을 조절하는 역할을 하기 때문입니다.
여기서 중요한 점은, 두 파라미터를 동시에 조작변인으로 설정하지 말아야 한다는 점이다!
물론, 정확하게 파라미터가 프롬프트에 작용하는 방식은 다르지만 중요한 것은 공식문서에서도 명시된 것처럼, 실제 실험을 진행할 시에 두 파라미터를 조작변인을 설정한다면, 답변의 창의성에 대한 명확한 수치를 평가하기 어려울 것이다.
그래서 추천하는 방식은, 아예 전체적인 파라미터 운영에서 두 파라미터 중 한 가지를 제외시키는 것이다.
이외에는 아래와 같은 2가지 방식으로 활용할 수 있을 것 같다.
- Temperature vs TopP: 명확하게 아래와 같이 변인을 통제하여 둘 중 어떤 파라미터를 선택할지 선택
실험 A: Temperature=0.5, TopP=1.0
실험 B: Temperature=1.0, TopP=0.5 - 여러 실험을 거쳐 (Temperature, TopP)에 대한 최적 조합 찾기
물론, 3번과 같이 여러 실험을 거쳐 조합에 대한 최적해를 찾는 것이 이상적이긴 합니다만 현실적으로 모델링을 직접 한 것이 아니기 때문에, 해당 파라미터가 실제로 어떤 작용을 하는지는 모른다는 점이 있습니다.
결론: 하나는 default값 쓰고, 나머지를 조작하며 최적해 찾기
Frequency Penalty & Presence Penalty
Frequency Penalty (빈도 패널티): 이 설정은 챗봇이 반복되는 단어나 구문을 얼마나 피할지 결정합니다. 높은 값은 챗봇이 반복을 피하도록 하며, 낮은 값은 반복이 더 자주 발생하게 합니다.
(range: -2.0 <= fp <= 2.0)
Presence Penalty (출현 패널티): 이 값은 챗봇이 이전에 사용한 내용을 얼마나 피할지 조절합니다. 높은 값은 챗봇이 같은 내용을 반복하지 않도록 하며, 낮은 값은 챗봇이 이미 언급한 내용을 다시 사용할 가능성이 높아집니다.
(range: -2.0 <= pp <= 2.0)
두 parameter 모두 단어에 대한 중복 & 반복에 관한 논의이지만 구체적으로 어떤 차이점이 있는지에 대한 이해가 쉽지 않을 것 같아서 아래 코드와 예시를 통해 설명해보려 한다.
mu[j] -> mu[j] - c[j] * alpha_frequency - float(c[j] > 0) * alpha_presence
- Logits (mu[j]): Logit은 모델이 특정 단어를 선택할 확률을 나타내는 로그 확률입니다. 모델은 이러한 로그 확률을 사용하여 다음에 올 단어를 결정합니다.
- c[j]: 이는 모델이 현재 위치 이전에 특정 단어를 선택한 횟수를 나타냅니다.
- alpha_frequency (빈도 패널티 계수): 이 계수는 특정 단어가 반복될 때마다 그 단어의 로그 확률을 감소시키는 데 사용됩니다. 즉, 단어가 더 자주 나타날수록, 그 단어가 다시 선택될 가능성이 낮아집니다.
- alpha_presence (존재 패널티 계수): 이 계수는 단어가 한 번이라도 나타난 경우, 그 단어의 로그 확률을 일정량 감소시키는 데 사용됩니다. 즉, 단어가 이미 한 번 사용되었다면, 다시 나타날 가능성이 줄어듭니다.
예를들어 '고양이'라는 단어를 이미 한 번 사용했다면, '존재 패널티'는 '고양이'라는 단어가 다시 사용될 확률을 감소시키기 위해, 그 단어의 로그 확률에 직접적인 감소를 적용합니다. 만약 '고양이'가 여러 번 반복되었다면, '빈도 패널티'는 그 단어가 선택될 때마다 로그 확률을 더욱 감소시켜, 모델이 같은 단어를 계속해서 반복하는 것을 방지합니다.
결론적으로, 빈도 패널티는 특정 단어가 반복될수록 점점 더 큰 패널티를 적용하는 반면, 존재 패널티는 단어가 문장에서 한 번이라도 나타나면 일정량의 패널티를 적용합니다.
위 설명이 어렵다면 아래 2가지 사항만 알고 넘어가자!
- 빈도 패널티는 특정 단어의 과도한 반복을 방지하는 데 유용하며, 존재 패널티는 다양한 단어와 구가 생성된 텍스트에 등장하도록 유도하는 데 더 적합합니다.
- 공식문서에서도 명시되어 있지만, 두 값 모두 1.0 이상으로 parameter 설정 시에는 답변의 퀄리티가 확실히 떨어지는 것으로 보입니다.
2. Fine-tuning API
Fine-tuning의 필요성
우리가 웹에서 사용하는 ChatGPT은 굉장히 general한 모델을 사용하고 있습니다.
그렇기에, 어떤 질문에도 평균 이상의 답변을 생성해냅니다. 그러나, 각자 아래와 같은 경험이 있을 것입니다.
특정 채팅 세션에서, 특정 보고서 형식에 맞게 질문 몇 가지를 던져주고 원하는 응답을 이끈다. 그리고, 일주일 뒤 다시 돌아와 해당 채팅을 다시 활용합니다. 나만의 모델을 제작한 셈입니다. 아래에서 말하는 개념과는 살짝 다르지만, 학습이 별도로 필요하단 말을 하려고 하는 것입니다.
결론적으로, 특정 도메인에 맞춰 커스텀하기 위해서는 별도의 학습, 즉 fine-tuning이 필요합니다.
fine-tuning은 머신러닝에서 특정 작업에 최적화된 성능을 달성하기 위해 이미 훈련된 모델을 추가적으로 조정하는 과정을 말합니다. 이 과정은 특히 딥러닝에서 널리 사용되며, 큰 데이터셋으로 사전에 훈련된 모델을 새로운, 종종 더 작은 데이터셋에 적용할 때 일반적으로 수행됩니다.
fine-tuning을 진행할 때는 기존 모델의 구조를 유지하면서 일부 매개변수만을 조정합니다. 이를 통해 모델은 새로운 데이터에 특화되어 성능이 개선되는 것을 목표로 합니다.
예를 들어, 대규모 이미지 데이터셋으로 사전 훈련된 모델을 특정 동물을 분류하는 작업에 맞게 파인튜닝할 수 있습니다. 이 과정은 학습 시간을 크게 단축시키고, 필요한 데이터의 양을 줄이며, 전반적인 효율성을 높이는 효과가 있습니다.
일단 먼저 OpenAI에서 제공하는 fine-tuning API를 사용하는 방법부터 공식문서의 코드를 통해 알아봅시다.
Code
1. Training data 제작하기
from openai import OpenAI
client = OpenAI()
client.files.create(
file=open("mydata.jsonl", "rb"),
purpose="fine-tune"
)Code에서 확인할 수 있듯이, 먼저 jsonl파일 형식으로 dataset을 준비해야 한다.
아래는 공식문서에서 제공하는 prompt 형식이다.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}참고로, fine-tuning API에 활용될 수 있는 OpenAI 모델은 아래와 같습니다.
gpt-3.5-turbo, babbage-002, davinci-002
모델마다 각각 지원하는 prompt형식이 다를 수 있습니다.
본 글은 가장 최신 모델인 gpt-3.5-turbo를 기준으로 설명하겠습니다.
gpt-4.0-turbo model이 작년 11월 DevDay 컨퍼런스를 통해 공개되고 이전 모델인 gpt-4.0을 fine-tuning 가능한 모델로 일부 파트너에게만 공개했습니다만 그 이후 업데이트 소식은 없습니다... 아마 ChatGPT웹에서 나만의 모델을 제작할 수 있는 gpt-store가 출시되고 이제 fine-tuning API는 관심밖으로...?
2. Fine-tuning 모델 제작
모델 제작시에 Parameter managing이 가능하다. 이 부분은 아래 Parameter section에서 제대로 설명하겠다. 일단 아래는 별다른 parameter를 넣지 않고 fine-tuning 작업을 생성하는 코드이다.
from openai import OpenAI
client = OpenAI()
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-3.5-turbo"
)1번 과정에서 만든 training_file의 이름과 사용할 fine-tuning에 사용될 gpt 모델명을 명시해야 합니다.
소요시간은 추가로 학습시키는 데이터의 양에 따라 달라지고, 경험 상으로 prompt 10개 정도를 학습할 경우 5~10분 정도 소요됩니다.
참고로, 이미 fine-tuning으로 학습한 모델도 다시 fine-tuning을 진행할 수 있습니다!
이 경우, 기존에 제작한 모델명을 명시해주면 됩니다 :)
ex) 별다른 네이밍 작업을 하지 않으면 ft:gpt-3.5-turbo:my-org:custom_suffix:id와 같은 스타일로 모델명이 할당됩니다
3. Fine-tuning 진행상황 추적
같은 OpenAI key(token)을 사용하며, 여러명이 작업을 할 경우 작업이 겹칠 수 있다.
같은 시간에 여러 작업이 병렬처리 되는 것이 아니라, 큐 형태로 먼저 시작된 작업부터 한번에 하나의 작업만 처리하게 되기 때문이다. 이 경우, 각자 상황에 맞게 해결하면 되지만 예상하다시피 아래 명령어들이 분명 필요해질 것 입니다 :)현재는 처리 방식이 달라졌을 수 있습니다ㅎ
현재 진행중인 fine-tuning job list
client.fine_tuning.jobs.list(limit=10)현재 fine-tuning job 상태 호출
client.fine_tuning.jobs.retrieve("ftjob-abc123")진행중인 fine-tuning job 취소
client.fine_tuning.jobs.cancel("ftjob-abc123")fine-tuning model 제거
client.models.delete("ft:gpt-3.5-turbo:acemeco:suffix:abc123")
4. Fine-tuning 모델 사용
fine-tuning job이 끝나면 모델 제작이 완료된 것이니....바로 사용하면 됩니다ㅎ
위에서 설명했다시피 Text-generation API를 사용할 때, 우리는 사용할 모델명을 명시한다.
해당 변수에 우리가 제작한 fine-tuning model 명을 넣어주면 된다.
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)Parameter
아래의 코드에서와 같이 fine-tuning job을 생성할 때, hyperparameter 설정을 하면 됩니다 :)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-3.5-turbo",
hyperparameters={
"n_epochs":2,
"batch_size":1,
"learning_rate_multiplier":1
}
)
fine-tuning API의 경우 아래 사진에서 보여지는 3가지 parameter에 대해 설명할 것입니다 :)
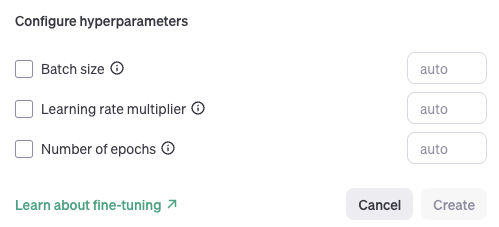
batch_size
batch_size: 배치 크기는 한 번의 학습(iteration)에 사용되는 데이터 샘플의 수를 의미합니다.
배치 크기가 크면 모델 파라미터가 업데이트되는 빈도가 줄어들지만, 업데이트할 때의 변동성이 낮아집니다. 큰 배치 크기는 계산 효율성을 높일 수 있지만, 때로는 과적합을 피하기 위해 작은 배치 크기가 더 적합할 수 있습니다.
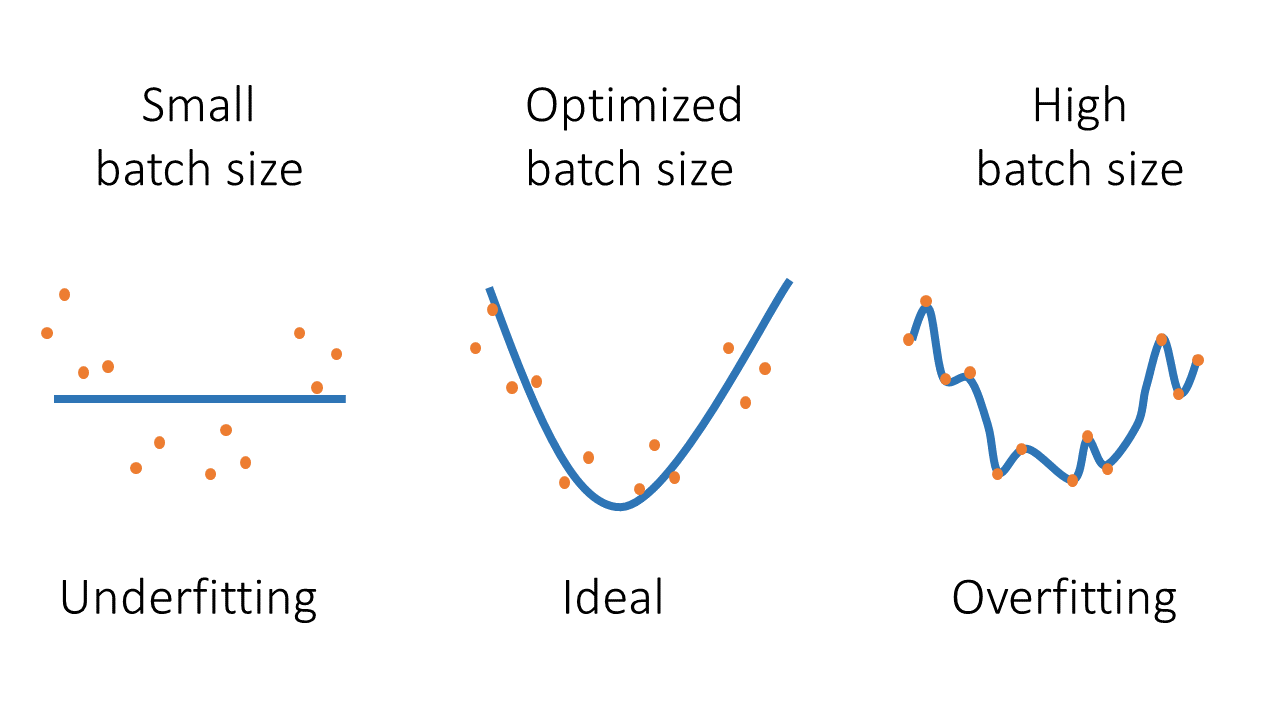
배치 크기에 대한 직관적인 이해를 위해, 훈련 데이터셋에 1000개의 샘플이 있다고 가정해 보겠습니다.
이 경우 배치 크기가 10이라면, 데이터셋은 100개의 배치로 나뉘며, 각 배치에는 10개의 샘플이 포함됩니다. 모델은 각 배치를 처리할 때마다 가중치를 업데이트하고, 이러한 과정을 전체 데이터셋에 대해 반복합니다.
배치 크기가 1이라면 (확률적 경사 하강법), 각 샘플을 독립적으로 처리하고, 각 샘플마다 가중치를 업데이트합니다. 이는 높은 변동성을 가지지만 더 빠른 수렴을 가져올 수 있습니다. 흔히, 배치 사이즈가 작을 때, underfitting(과소적합)의 위험성이 있다고 합니다.
배치 크기가 1000이라면 (전체 배치 학습법), 전체 데이터셋을 한 번에 처리하고, 한 번의 큰 가중치 업데이트를 합니다. 이는 계산적으로 안정적이지만, 메모리 사용이 많고, 때로는 지역 최소값에 갇힐 위험이 있습니다. 흔히, 배치 사이즈가 클 때, overfitting(과적합)의 위험성이 있다고 합니다.
이처럼 배치 크기는 메모리 사용, 학습 속도, 모델의 성능에 영향을 주기 때문에 신중하게 운영할 필요가 있습니다.
learning_rate_multiplier
learning_rate_multiplier: 학습률은 모델이 학습하는 속도나 정도를 조절하는 값입니다.
기본적으로는 모델이 학습할 때 각 파라미터를 얼마나 조정할지 결정합니다.
학습률 배수는 일종의 기본 학습률에 적용되는 스케일링 인자입니다. 이 값을 조정하여 모델의 학습률을 늘리거나 줄일 수 있습니다.
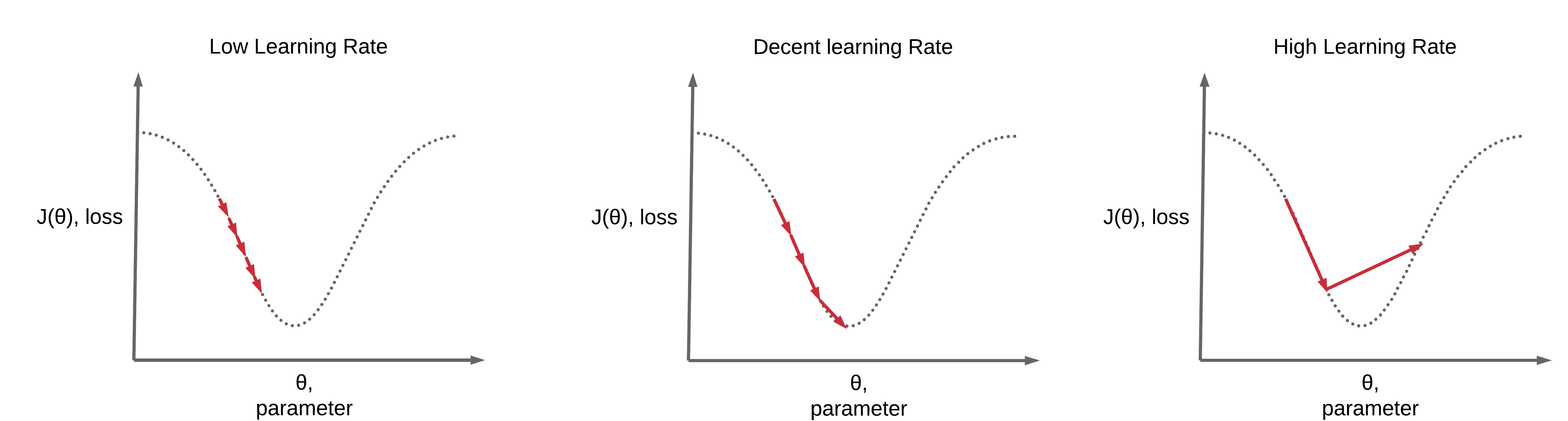
학습률이 너무 높으면 모델이 최적의 해를 지나쳐 버리는 현상이 발생할 수 있어, 결국에는 학습 과정에서 불안정해지고, 모델의 성능이 안좋아집니다.
반면, 너무 낮은 학습률은 모델이 데이터의 핵심 특징을 충분히 학습하기까지 매우 오랜 시간이 걸릴 수 있습니다. 이는 효율적이지 않으며, 오히려 충분한 학습이 이루어지지 않을 경우 예상치 못한 결과를 초래할 수 있습니다.
n_epochs
n_epochs: 전체 훈련 데이터가 학습에 한 번 사용되는 주기를 의미합니다.
즉, 에포크 수는 머신 러닝 모델이 전체 훈련 데이터 세트를 한 번 완전히 통과하는 횟수를 의미합니다.
모델이 한 에포크 동안 훈련 데이터 전체를 한 번 통과하므로, 에포크 수를 늘릴수록 모델은 데이터를 더 많이 볼 수 있으며, 이는 복잡한 문제를 더 잘 학습하는 데 도움이 될 수 있습니다.
하지만 에포크 수가 지나치게 높으면 훈련 시간이 길어지고, 모델이 훈련 데이터에 과도하게 적합되어 과적합을 초래할 수 있습니다.
Tip
토큰 관리는 필수!
기본적으로 토큰은 곧 돈입니다. 따라서, 무작정 사용하다가는 돈쭐날 수 있을 위험이 있으므로 아래 몇 가지 추천드리는 가이드라인을 참고해주세요.
1. max_token 운영으로 사용되는 토큰의 양 제한
max_tokens 변수를 설정하면, 사용할 토큰의 양을 제한할 수 있다. max_token의 값은 입력과 답변의 목적에 따라 달라지겠지만, 이러한 부분도 실험을 통해 조절하길 권장한다.
2. 한글 사용으로 인한 지나친 토큰 소모 지양
기본적으로, 한국어 문자에 사용되는 토큰 개수는 영어 문자에 사용되는 토큰 개수보다 훨씬 많다. 상황에 따라 다르기 때문에, 구체적인 수치를 제시하기 어렵지만 적어도 2배 이상은 소요된다고 예상된다. 굳이 한국어에 대한 입출력이 필요하지 않은 모델이라면, 아래의 사항을 고려해보길 바란다.
- 유료 번역 API 사용: google-translate api, deep-l api (추천), papago api
- 웹 번역기 크롤링: 동적 크롤링을 활용하여, 웹 번역기에 사용할 한국어 텍스트를 입력하고 결과값을 다시 크롤링하여 사용
명확한 실험기준과 평가 파이프라인 구축 중요!
본 글을 요약하자면, OpenAI API를 사용하여 Chat-completion을 하거나 fine-tuning을 할 때 중요한 두가지는 아래와 같다.
- parameter 운영
- prompt-engineering
전자에 대해서는 본 글에서 설명한 개념을 이해하고, 이를 바탕으로 실험기준을 세워야 합니다.
당연히, 파라미터 값은 context와 적용할 도메인의 성격에 따라 달라질 수 있기에 더더욱 명확한 실험기준으로 빠르게 최적해를 찾는 것이 중요합니다.
그러나, 결국 중요한 것은 신뢰성 있는 training_data에 대한 확보 + 도메인 전문가의 평가 라고 생각이 듭니다. 뻔한 소리지만, data의 퀄리티는 늘 중요한 것이겠지요ㅎ
후자에 대해서는, 본 글에서 따로 다루고 있지 않지만 prompt를 잘 구성하는 것도 LLM 성능에 지대한 영향을 끼칩니다. 그러니, 기본적인 prompt 구성법과 이에 대한 실험 기준을 명확하게 하는 것도 중요하다.
최근 mlflow에서는 LLM prompt 운영에 용이한 template도 제공하고 있고, 당연히 모델에 대한 evaluate 파이프라인도 구축할 때 활용할 수 있으므로 mlflow도 적극 활용하길 추천합니다.
https://mlflow.org/docs/latest/llms/llm-evaluate/index.html
첨언
- 혹시, 머신러닝에 대한 이해가 부족한 것 같다면 제가 이전에 올린 ML/DL 용어 정리 포스팅을 참고해주시면 좋을 것 같습니다ㅎ
- 꼭, API를 사용하기 전에 OpenAI playground에서 체험해보세요!
참고문헌
- https://platform.openai.com/docs/api-reference
- https://platform.openai.com/playground/chat
- https://www.trustedreviews.com/versus/chat-gpt-4-vs-chat-gpt-3-4309130
- https://www.researchgate.net/figure/Schematic-drawing-of-the-fine-tuned-pipeline-left-branch-and-in-the-zero-shot-pipeline_fig1_374642679
- https://blog.paperspace.com/how-to-maximize-gpu-utilization-by-finding-the-right-batch-size/#resources
- https://etd.ohiolink.edu/apexprod/rws_etd/send_file/send?accession=osu1587693436870594&ref=blog.paperspace.com
- https://www.deeplearningwizard.com/deep_learning/boosting_models_pytorch/lr_scheduling/#step-wise-decay-every-epoch
