
SQL basic concept
SQLD를 공부하면서, SQL의 basic concept와 주의하거나 알면 좋은 지점들에 대해서 정리해보았습니다.
What is SQL?
SQL(Structured Query Language)은 관계형 데이터베이스 관리 시스템(RDBMS)에서 데이터를 관리하고 조작하기 위해 사용되는 표준 언어입니다. SQL을 사용하면 데이터베이스에 저장된 데이터를 삽입, 수정, 삭제 및 조회할 수 있습니다. SQL은 강력한 데이터 조작 기능과 함께 데이터베이스 스키마 생성 및 변경을 위한 명령도 제공합니다. SQL의 주요 구성 요소로는 DDL(데이터 정의 언어), DML(데이터 조작 언어), DQL(데이터 질의 언어) 등이 있습니다.
SQL 입문자를 위한 Tip
- 다수의 SQL문은 세미콜론으로 분리합니다.
- SQL 주석
--: 인라인 한 줄짜리 주석/* ... */: 여러 줄에 걸쳐 사용 가능한 주석
- SQL 키워드는 나름대로의 포맷팅이 필요합니다(팀끼리 상의하여 컨벤션을 정하는 것이 중요)
- 테이블 및 필드 이름 명명 규칙 정하기
- 단수형 vs 복수형 예)
UservsUsers _vs CamelCasing 예)user_timevsUserTime
- 단수형 vs 복수형 예)
- 테이블 및 필드 이름 명명 규칙 정하기
SQL vs Pandas
Pandas가 등장할 당시에는, '전반적인 데이터 처리 트렌드가 SQL에서 Pandas로 넘어오겠다'라고 생각하는 개발자들도 존재했다고 한다. 하지만, SQL과 달리 코드 관계자가 아닌 인원이 코드를 보고 한눈에 어떤 의미인지를 모른다는 치명적인 단점이 존재하여, 여전히 SQL은 데이터 조작 언어로서 입지를 공공히 하고 있다.
물론 설계 목적 자체가 다르기 때문에 비교하는 것이 무의미할 수 있지만, 데이터를 다룬다는 큰 범주안에서 유사한 역할을 담당한다고 볼 수 있기에 같이 설명을 드리려고 합니다.
- SQL: 관계형 데이터베이스에 저장된 데이터를 효율적으로 관리하고 질의할 수 있도록 설계된 언어입니다.
- Pandas: Python 환경에서 데이터 분석 및 조작을 위해 설계된 라이브러리로, 데이터프레임을 사용하여 다양한 데이터 조작을 간편하게 수행할 수 있습니다.
보통 SQL은 디스크 기반의 대규모 데이터베이스에서 효율적으로 작동하고, 데이터베이스 서버에서 실행됩니다. 반면에 Pandas는 데이터프레임 형태로 메모리에 데이터를 로드하여 빠르고 유연한 데이터 조작을 가능하게 합니다. 사실, Pandas의 메모리 할당 방식은 대규모 데이터를 다루기 어렵기 때문에, 이 때 유사한 용도로 PySpark가 많이 쓰입니다. 대규모 데이터에 대한 명확한 기준은 없지만, 경험 상 10GB가 넘어가는 데이터를 처리할 때는 PySpark를 사용하는 것이 유리한 것 같습니다.
DDL
CREATE TABLE
- primary key 속성을 지정할 수 있으나 무시됩니다.
- CTAS:
CREATE TABLE ... AS SELECT ...을 통해 서머리 테이블을 생성할 수 있습니다.- ELT의 역할을 할 수 있지만, 테스트할 수 없고 테이블 컬럼에 대한 디테일한 관리가 어렵습니다.
- 초기 설정한 데이터 타입이 최종 타입입니다.
CREATE TABLE→INSERT→SELECT- 보통 DBT(Data Build Tool)를 사용합니다.
DROP TABLE
DROP TABLE ...;:- 없는 테이블을 지우려고 하면 에러가 발생합니다.
DROP TABLE IF EXISTS ...;사용을 권장합니다.- VS DELETE FROM:
DELETE FROM은 조건에 맞는 레코드들을 삭제합니다(테이블 자체는 유지).
ALTER TABLE
- 새로운 컬럼 추가:
ALTER TABLE 테이블이름 ADD COLUMN 필드이름 필드타입;
- 기존 컬럼 이름 변경:
ALTER TABLE 테이블이름 RENAME 현재필드이름 TO 새필드이름;
- 기존 컬럼 제거:
ALTER TABLE 테이블이름 DROP COLUMN 필드이름;
- 테이블 이름 변경:
ALTER TABLE 현재테이블이름 RENAME TO 새테이블이름;
DML
SELECT, FROM, WHERE 절은 너무 기초적인 문법이기에 설명에서 제외
IN
WHERE channel IN ('Google', 'Youtube'):WHERE channel = 'Google' OR channel = 'Youtube'
LIKE(구별) and ILIKE (대소문자 구별 안 함)
WHERE channel LIKE 'G%'→'G*'WHERE channel LIKE '%o%'→'*o*'NOT LIKE또는NOT ILIKE- mysql은 대소문자 구별을 하지 않음
- PostgreSQL/Redshift는 구별함
BETWEEN
- DATE RANGE MATCHING
String functions
LEFT(str, N)REPLACE(str, exp1, exp2)UPPER(str)LOWER(str)LEN(str)LPAD,RPADSUBSTRING
INSERT INTO VS .COPY
- 일반적으로 INSERT가 더 느립니다. (배치 삽입 메커니즘 이해 필요)
INSERT INTO table SELECT * FROM ...:- 필드의 타입을 제어하려면
CREATE TABLE table AS SELECT보다 낫습니다. - 그러나 varchar 길이를 맞추는 것은 쉽지 않습니다.
- Snowflake와 BigQuery는 string 타입을 지원합니다.
- 필드의 타입을 제어하려면
GROUP BY
- DAU, WAU, MAU 계산할 때 GROUP BY가 필요합니다.
--- mau 계산 sql예시 SELECT TO_CHAR(A.TS, 'YYYY-MM') AS month, COUNT(DISTINCT B.userid) AS mau FROM raw_data.session_timestamp A JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid GROUP BY 1 ORDER BY 1 DESC;
ORDER BY
- NULL value ordering (NULL이 가장 큰 값?)
- In Redshift, NULL은 최대값으로 간주됩니다.
ORDER BY 1 DESC;→ NULL이 가장 앞에 위치ORDER BY 1 DESC NULLS LAST;→ NULL이 맨 뒤로 이동
- In Redshift, NULL은 최대값으로 간주됩니다.
- ORDER BY와 GROUP BY → 포지션 번호 vs 필드 이름
GROUP BY 1==GROUP BY month==GROUP BY TO_CHAR(A.ts, 'YYYY-MM')
Type Cast and Conversion
- Type casting
cast또는::연산자 사용channel::int(본 예시는 PostgreSQL기반의 Redshift에 해당, SQL마다 다를 수 있음)cast(channel as int)
- Conversion
- Date conversion
convert_timezoneconvert_timezone('America/Los_Angeles', ts)SELECT pg_timezone_names()
date,truncatedate_trunc- 첫 번째 인자가 어떤 값을 추출하는지 지정
extract또는date_part: 날짜, 시간에서 특정 부분의 값을 추출datediff,dateadd,get_current...
- Date conversion
TO_CHAR(A.TS, 'YYYY-MM') AS month은 아래와 같이 사용해도 같은 output을 도출LEFT(A.ts, 7)DATE_TRUNC('month', A.ts)SUBSTRING(A.TS, 1, 7)
NULL
값이 존재하지 않음을 의미하고, 0과 비어있는 문자열과는 다르다는 점을 인지해야 한다.
IS NULL,IS NOT NULL형식으로 사용- Boolean 타입의 필드도
IS TRUE,IS FALSE형식으로 비교
- Boolean 타입의 필드도
- LEFT JOIN 시 매칭되는 것이 있는지 확인할 때 유용
- NULL 값을 다른 값으로 변환하고 싶다면?
COALESCENULLIF
- 특정 값을 NULL이나 0으로 나누면?
- NULL로 나누면 결과는 NULL
SELECT 10 / NULL; -- 결과: NULL - 0으로 나누면 오류(Division by zero error)가 발생
SELECT 10 / 0; -- 결과: 오류 (Division by zero)
- NULL로 나누면 결과는 NULL
Count
| … | … | value |
|---|---|---|
| … | … | NULL |
| … | … | 1 |
| … | … | 1 |
| … | … | 0 |
| … | … | 0 |
| … | … | 4 |
| … | … | 3 |
COUNT(0) FROM Table = 7
COUNT(value) FROM Table = 6
COUNT(DISTINCT value) FROM Table = 4SQL 실행순서
세부적으로 들어가면 사실 최종적인 실행순서는 보통 쿼리 옵티마이져에 의해서 결정된다. 다만, 기본적으로 아래 사진과 같이 이해하고 있다면 SQL문을 작성할 때 크게 도움이 된다.
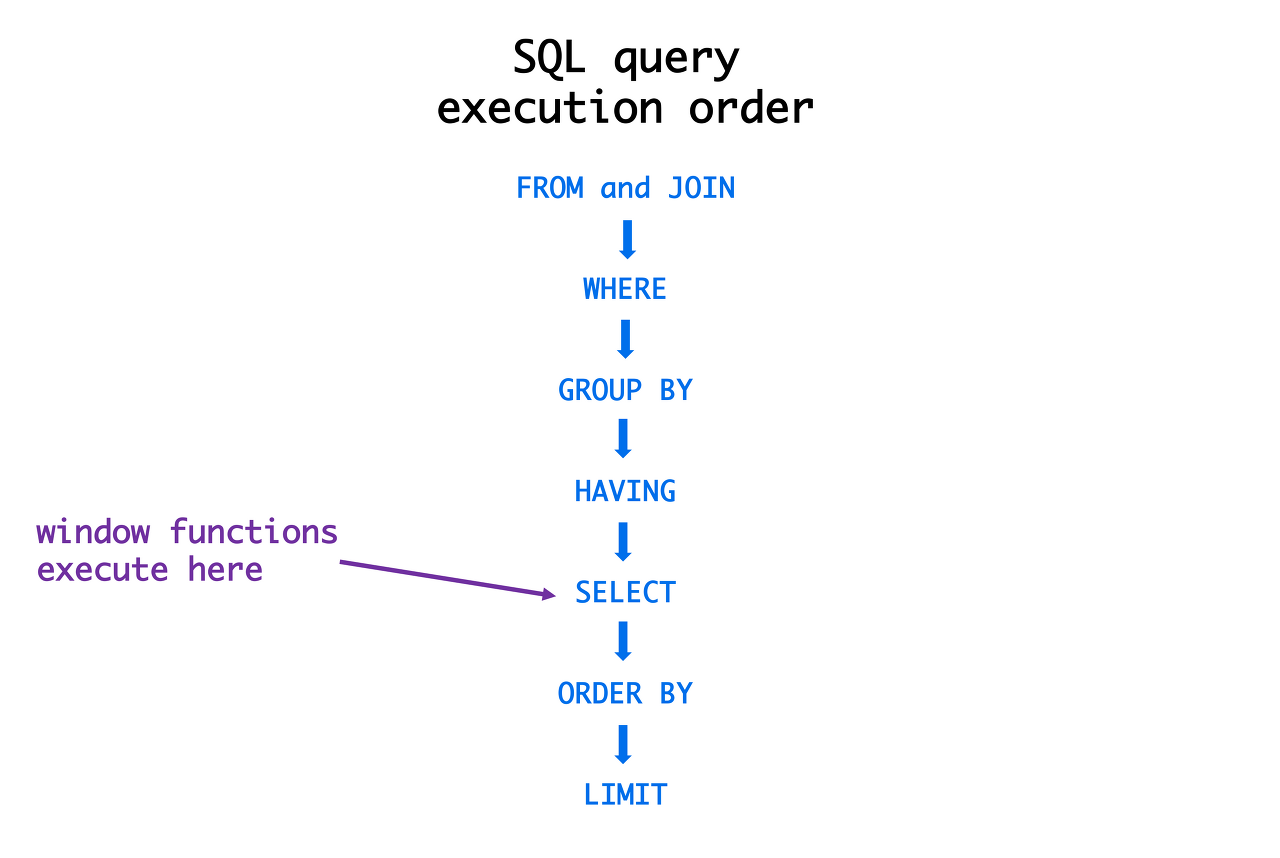
참고문헌
