
최근 근무를 하면서나 개인적으로 사이드 프로젝트를 진행할 때도 Python 기반의 DataOps 업무를 주로 진행했기에, SQL 관련공부에 소홀해졌던 것 같다. 물론 데이터를 전처리하거나 데이터마트를 생성할 때, DW 상에서 SQL 쿼리를 꽤 작성했지만, 유사한 구조를 지속적으로 사용하다보니 이전에 자격증을 공부할 때 학습한 스킬이나, 이미 사용하던 것들도 점점 개념이 잊혀져 간 것 같아, 유용하게 사용한 SQL function에 대해 복기해보려고 합니다 🔥
With문
With문을 사용하는 이유에 대해서 물어본다면, 가장 먼저 떠오르는 것은 ‘가독성’이다. 당장 ‘왜 사용했지?’ 라는 물음에, 기억을 더듬어보면 2개 이상의 서브쿼리(Subquery) 개수로 인한 가독성 이슈를 해결하고 싶어 활용했던 이유가 가장 컸던 것 같다. 개념을 설명하기 위해, 특정한 상황을 가정해봅시다 :)
예를 들어, 직원 테이블에서 부서별 평균 급여를 계산한 후, 각 직원의 급여가 해당 부서 평균보다 높은 직원을 조회하는 서브쿼리가 포함된 질의문이 있다고 해봅시다.
SELECT employee_id, salary, department_id
FROM employees e
WHERE salary > (
SELECT AVG(salary)
FROM employees
WHERE department_id = e.department_id
);위 쿼리에 With문을 적용하여 변환해보면 아래와 같을 것입니다 :)
WITH DeptAvgSalaries AS (
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
)
SELECT e.employee_id, e.salary, e.department_id
FROM employees e
JOIN DeptAvgSalaries d
ON e.department_id = d.department_id
WHERE e.salary > d.avg_salary;이런식으로, 일명 CTE(Common Table Expression)를 사용하여 쿼리를 작성하면 복잡한 쿼리를 더 읽기 쉽게 만들고, 무엇보다 쿼리의 각 부분을 특정 이름으로 재사용할 수 있게 해줍니다.
특히 서브쿼리를 2개 이상 사용했을 때, With문을 적용한다면 이러한 재사용성의 장점이 더욱 부각됩니다.
아래는 부서별 평균 급여를 계산한 후, 이 데이터를 두 번 참조하여 각각 급여가 평균보다 높은 직원과 낮은 직원을 조회하는 예제입니다.
-- 서브쿼리로 평균보다 높은 직원 조회
SELECT e.employee_id, e.department_id, e.salary,
(SELECT AVG(salary)
FROM employees
WHERE department_id = e.department_id) AS avg_salary
FROM employees e
WHERE e.salary > (SELECT AVG(salary)
FROM employees
WHERE department_id = e.department_id)
UNION ALL
-- 서브쿼리로 평균보다 낮은 직원 조회
SELECT e.employee_id, e.department_id, e.salary,
(SELECT AVG(salary)
FROM employees
WHERE department_id = e.department_id) AS avg_salary
FROM employees e
WHERE e.salary < (SELECT AVG(salary)
FROM employees
WHERE department_id = e.department_id);이를 아래와 같이 With문을 적용하여, 사전에 정의한 DeptAvgSalaries (쿼리 실행 시 메모리 상에 생성된 가상의 테이블)를 재사용한다면, 쿼리 실행 횟수를 2회에서 1회로 줄일 수 있기 때문에 효율성(쿼리 성능)을 높일 것이라고 쉽게 예상할 수 있을 것입니다 🙂
WITH DeptAvgSalaries AS (
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
)
-- 평균보다 높은 직원 조회
SELECT e.employee_id, e.department_id, e.salary, d.avg_salary
FROM employees e
JOIN DeptAvgSalaries d ON e.department_id = d.department_id
WHERE e.salary > d.avg_salary
UNION ALL
-- 평균보다 낮은 직원 조회
SELECT e.employee_id, e.department_id, e.salary, d.avg_salary
FROM employees e
JOIN DeptAvgSalaries d ON e.department_id = d.department_id
WHERE e.salary < d.avg_salary;하지만 여기서 중요한 점은 With문의 동작 방식에 따라 효율성이 높아질 수도, 낮아질 수도 있다는 점입니다!
일단, 앞서 설명했던 흐름에 따라 우리가 예상하는 With문의 동작 방식은 Materialize 일 것입니다. 해당 방식은 With문을 통해 일종의 임시 테이블을 생성하고, 서브쿼리를 매번 실행하는 대신, 사전에 생성한 임시 테이블을 재사용하는 경우입니다.
물론 옵티마이저의 최적화 과정에 따라 달라질 수 있겠지만, 경험 상 일반적으로 대부분의 DBMS 상에서의 With문의 동작은 Inline View 방식으로 처리됩니다. 해당 방식은 말그대로 View 와 같이 쿼리 그 자체만 저장되기 때문에, With문을 통해 정의한 테이블을 조회할 때마다 쿼리를 실행합니다. 따라서, 실제로는 서브쿼리를 사용했을 때와 동일한 성능을 보일 것입니다. 대신, 가독성을 높일 수 있다는 점은 가져갈 수 있겠죠?
그렇다면, Materialize 방식을 채택한다면 늘 성능 개선을 이끌 수 있을까요?
정답은 예상하셨다시피 'NO' 입니다. 아래의 2가지 상황에서는 위 동작방식의 With문의 적용을 지양해야 할 수 있습니다 😅
-
결과 rows가 매우 클 경우:
Materialize방식의 쿼리 결과가 매우 큰 데이터셋을 포함하게 되면, 임시 테이블을 메모리에 생성하고 유지하는 데 드는 자원이 크게 증가하여 시스템의 부하를 가져올 수 있습니다. 상식적으로 임시 테이블을 생성(CREATE)하고, 쿼리가 끝난 후 임시 테이블을 삭제(DROP)하는 과정을 거치기 때문에, rows가 너무 많을 경우에는 이 과정 자체에서 시스템의 부하가 발생할 것입니다. 이때는 CTAS로 임시테이블을 생성하여, 인덱스나 파티셔닝을 적용하는 등의 별도의 최적화 과정을 고려하는 것이 좋을 것으로 예상됩니다 :) -
필터링이나 조건이 변경될 때:
Materialize방식으로 임시 테이블을 생성하면, CTE가 한 번 실행된 후 결과를 재사용합니다. 하지만 각 참조 시마다 조건이 달라질 경우, 그리고 심지어 rows가 많을 경우에는 임시 테이블이 효율적이지 않고 원하는 필터링이 잘 이루어지지 않을 확률이 높기 때문에 불필요한 데이터를 읽게 될 수 있습니다.
그렇다면, 언제 With문을 Materialize 방식으로 처리하는 것이 좋을까요?
I/O 비용이 크지만, 결과 dataset이 작을 경우 매우 유용하게 사용할 수 있습니다! 🎉
예를 들어, 결과를 도출하는 과정에서 (예: join문 중첩) 복잡한 연산이 진행될 경우, 단 한번의 비용소모로 재사용의 이점을 극대화할 수 있고, 결과 rows가 작기 때문에 디스크나 메모리에 부하를 주지 않다는 점도 장점으로 작용할 것입니다.
TIP💡
앞서 언급했듯이 대부분의 DBMS에서는 기본적으로 Inline View를 채택하기 때문에 (물론, 옵티마이저의 최적화 과정에 따라 다를 수 있음!), Materialize 방식을 강제하기 위해서는 각 DBMS 별로 최척화 방법에 대해 이해하고, 이에 따른 대처를 달리 해야 합니다.
예를 들어, Oracle에서는 /*+ MATERIALIZE */를, MySQL에서는 /*+ NO_MERGE(cte) */ 와 같은 방식으로 옵티마이저에게 힌트를 제시해야 합니다. 따라서, 쿼리 성능 개선을 위해 With문을 적용하려고 한다면, 먼저 사용하는 DBMS이 With문을 어떻게 처리하는지에 대한 이해가 선행되어야 합니다 :)
Window 함수
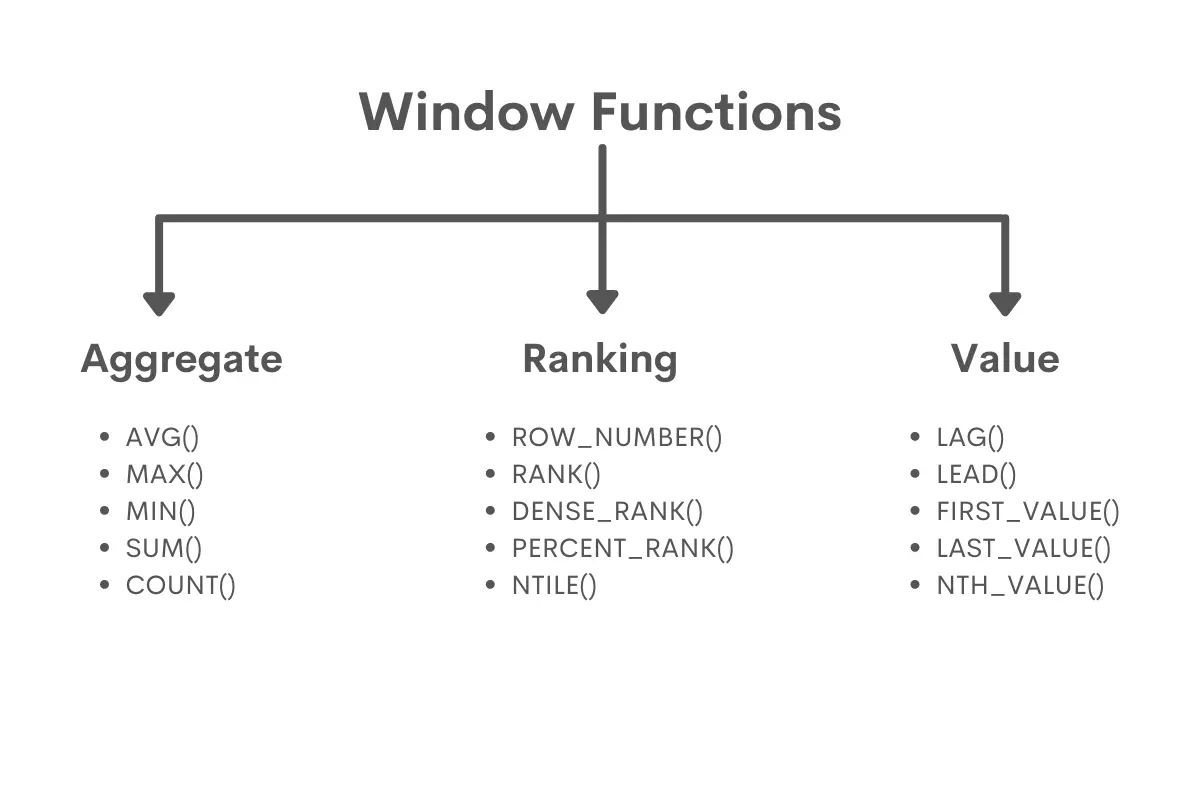
Window 함수는 쿼리 내에서 특정 레코드 집합을 기준으로 데이터를 처리할 수 있게 하는 SQL 함수입니다.
일반적인 집계 함수와 달리, 결과를 그룹으로 묶지 않고도 각 행에 대해 연산을 수행할 수 있기 때문에, 유용하게 사용할 상황이 꽤 발생합니다. 이번 포스팅에서는 대표적인 윈도우 함수인 RANK(), ROW_NUMBER(), LAG(), LEAD()에 대해서 소개하겠습니다.
RANK(): 순위 계산
RANK()함수는 특정 기준에 따라 데이터의 순위를 계산합니다. 동일한 값에 대해 같은 순위를 부여하고, 동일한 순위 이후에는 건너뛰는 순위가 적용됩니다. 예를 들어, 1위가 여러 개 있으면 다음 순위는 2위가 아닌 3위가 됩니다.
예시 쿼리
아래 쿼리는 직원의 급여를 기준으로 내림차순으로 정렬하여 순위를 계산합니다. 또한, 동일한 급여를 가진 직원들은 같은 순위를 부여받고, 다음 순위는 건너뛰게 될 것입니다.
SELECT employee_id, salary,
RANK() OVER (ORDER BY salary DESC) AS salary_rank
FROM employees;쿼리 실행 결과
| employee_id | salary | salary_rank |
|---|---|---|
| 101 | 10000 | 1 |
| 102 | 10000 | 1 |
| 103 | 9500 | 3 |
| 104 | 9000 | 4 |
앞서 설명한 동작 원리에 따라, 급여가 10,000인 직원들은 1위를 공유하고, 그 다음 순위는 2가 아니라 3이 됩니다.
ROW_NUMBER(): 행 번호 반환
ROW_NUMBER()함수는 특정 기준에 따라 각 행에 고유한 번호를 부여합니다. 동일한 값에 대해서도 중복 없이 번호가 매겨지며, 데이터의 순서에 따라 고유 번호가 부여됩니다.
예시 쿼리
아래 쿼리는 직원의 급여를 내림차순으로 정렬하고, 각 직원에게 고유한 행 번호를 부여합니다. 또한, 동일한 급여 값이라도 번호는 중복되지 않습니다.
SELECT employee_id, salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num
FROM employees;쿼리 실행 결과
| employee_id | salary | salary_rank |
|---|---|---|
| 101 | 10000 | 1 |
| 102 | 10000 | 2 |
| 103 | 9500 | 3 |
| 104 | 9000 | 4 |
결과를 보면, ROW_NUMBER()는 순위와 달리 동일한 값에 대해 중복된 번호를 부여하지 않고, 고유한 번호를 차례대로 부여하는 것을 알 수 있습니다.
UPSERT
UPSERT는 Update + Insert를 합친 데이터 업데이트 방식입니다. 이름에서도 알 수 있듯이, UPSERT는 중복되는 값이 없다면 삽입(Insert)을 하고, 중복되는 값이 있다면 최신화(Update)를 하는 쿼리를 뜻합니다.
데이터 엔지니어로서 ROW_NUMBER()를 처음 접했던 때는 UPSERT 방식을 DW 상에서 구현하려고 시도했을 때였던 것 같아, ROW_NUMBER()에 대한 이해를 돕기 위해 추가로 설명해보려고 합니다 🔥
보통의 데이터웨어하우스 솔루션에서는 나름의 방식으로 UPSERT 방식을 지원하지만 (예: BigQuery의 merge into 문), 일단 이를 활용하지 않고 Incremental Update를 한다고 가정해봅시다 🫡 (참고로 Full refresh를 하는 경우는, 어차피 모두 재호출하여 적재하기 때문에 상관없을 것)
예를 들어, 최근 7일 간의 날씨 데이터에 대해 refresh하는 실행문을 작성해야하는 상황을 생각해본다면 아래와 같은 고려사항이 있을 것입니다.
보통의 RDBMS의 경우에는 DATE에 PK가 걸려있기 때문에 중복이 일어나지 않을 수 있지만, 데이터 웨어하우스 솔루션은 빅데이터에서의 성능을 보장하기 위해 일반적으로 PK를 지원하지 않기 때문에, 오늘 호출하고 내일 호출하면 데이터가 겹칩니다. 추가로, 같은 날짜에 대한 데이터라도 최근에 호출한 데이터의 신뢰도가 높기 때문에, 비교적 최근 데이터로 refresh 하려는 수요 또한 존재할 것입니다.
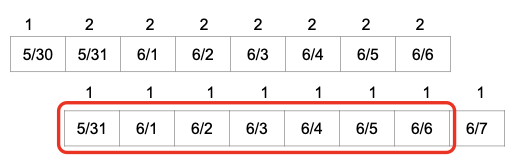
따라서, 이를 해결하기 위해서는 DATE가 동일한 것들끼리 grouping을 하고, created_date(DATE)가 큰 것부터 역순으로 sorting한 뒤, 일련번호를 붙여서 가장 최근 값만 채택을 해야합니다. 이때, ROW_NUMBER() 함수를 적용하여 아래와 같이 처리하면 됩니다.
INSERT INTO weather_daily_table
SELECT date, temp, min_temp, max_temp, created_date
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY date ORDER BY created_date DESC) seq
FROM t
)
WHERE seq = 1위와 같이 처리하면, 아래 사진과 같은 과정을 통해 Primary Key Uniqueness 보장하면서 신규 데이터로 refresh할 수 있습니다.
LAG(): 이전 행의 값 참조
LAG()함수는 현재 행 이전의 행 값을 가져옵니다. 주로 시계열 데이터나 이전 값과 비교가 필요한 상황에서 사용됩니다. 기본적으로 이전 행을 참조하지만, 참조할 행의 간격(몇 번째 이전 행)을 지정할 수 있습니다.
예시 쿼리
아래 쿼리는 직원의 고용일(hire_date)을 기준으로 이전 직원의 급여를 가져옵니다. 또한, 이전 행이 없을 경우 기본값으로 0을 반환합니다.
SELECT employee_id, salary,
LAG(salary, 1, 0) OVER (ORDER BY hire_date) AS prev_salary
FROM employees;쿼리 실행 결과
| employee_id | salary | prev_salary |
|---|---|---|
| 101 | 8000 | 0 |
| 102 | 9000 | 8000 |
| 103 | 10000 | 9000 |
| 104 | 9500 | 10000 |
첫 번째 행의 이전 행이 없기 때문에 prev_salary는 0을 반환하고, 이후 행들은 각각 이전 직원의 급여를 참조합니다.
추가로, 이해를 돕기 위해 주식 가격 데이터에서 각 주식의 전일 대비 가격 변동을 계산해야 하는 상황을 가정한다면,
LAG()함수를 활용하여 아래와 같은 쿼리를 작성할 수 있을 것입니다.
SELECT stock_id, date, price,
LAG(price, 1) OVER (PARTITION BY stock_id ORDER BY date) AS prev_price,
price - LAG(price, 1) OVER (PARTITION BY stock_id ORDER BY date) AS price_change
FROM stock_prices;LEAD(): 다음 행의 값 참조
LEAD()함수는 현재 행 이후의 값을 가져옵니다. 주로 시계열 데이터나 다음 값과 비교가 필요한 상황에서 사용됩니다. LAG()와 반대로 다음 행을 참조하며, 몇 번째 이후의 값을 참조할지 지정할 수 있습니다.
예시 쿼리
아래 쿼리는 직원의 고용일을 기준으로 다음 직원의 급여를 가져옵니다. 또한 LAG() 함수와 비슷하게, 다음 행이 없을 경우 기본값으로 0을 반환합니다.
SELECT employee_id, salary,
LEAD(salary, 1, 0) OVER (ORDER BY hire_date) AS next_salary
FROM employees;| employee_id | salary | next_salary |
|---|---|---|
| 101 | 8000 | 9000 |
| 102 | 9000 | 10000 |
| 103 | 10000 | 9500 |
| 104 | 9500 | 0 |
쿼리 실행 결과
마지막 직원의 경우 다음 행이 없기 때문에 next_salary는 0을 반환하고, 다른 행들은 각각 다음 직원의 급여를 참조합니다.
추가로, 이해를 돕기 위해 로그 데이터에서 사용자 행동의 다음 단계를 분석해야 하는 상황을 가정한다면,
LEAD()함수를 적용한 아래와 같은 쿼리를 활용하여, 사용자가 현재 페이지를 방문한 후에 다음 페이지로 어디를 방문했는지 추적할 수 있을 것입니다.
SELECT user_id, page, timestamp,
LEAD(page, 1) OVER (PARTITION BY user_id ORDER BY timestamp) AS next_page
FROM web_logs;TIP💡
LAG() 와 LEAD() 함수는 SCD Type 2와 같은 데이터 히스토리 관리 방식에서 데이터를 시간순으로 비교하거나 추적하는 할 때도 유용합니다. 이러한 함수들은 데이터의 변경 내역을 시간별로 분석하고, 각 데이터의 이전 상태나 다음 상태를 확인하는 데 활용될 수 있습니다.
참고로, 이전 올렸던 DBT 관련 포스팅에서 SCD Type에 대해 설명하였으니, 아래 포스팅을 확인해주시면 감사하겠습니다 :)
Why DBT? (feat. A/B 테스트, 데이터 품질)
참고문헌
- https://livesql.oracle.com/ords/livesql/file/tutorial_GMLYIBY74FPBS888XO8F1R95I.html
- https://livesql.oracle.com/ords/livesql/file/content_CZUCT0MCOQZMJM7TI553HC8S9.html
- https://dev.mysql.com/doc/refman/8.4/en/subquery-materialization.html
- https://dev.mysql.com/doc/refman/8.0/en/optimizer-hints.html
- https://www.stratascratch.com/blog/the-ultimate-guide-to-sql-window-functions/
- https://towardsai.net/p/l/databricks-upsert-to-azure-sql-using-pyspark
- https://schatz37.tistory.com/46
