
ETL을 하는 이유는 결국 ELT를 하기 위함이며, 이때 데이터에 대한 품질 검증이 중요해집니다.
데이터가 점점 대용량으로 가게되면, 데이터의 품질 이슈가 발생합니다. 이는 인사이트를 뽑아낼 때 속도가 지연되거나, 잘못된 결론을 내리는 이슈로 이어지기도 하므로, 데이터의 신뢰성과 향후의 인력 및 리소스 소모를 막기 위해서는 필수적으로 해결되어야 하는 문제라고 생각합니다.
일단 ‘데이터 품질’에 대한 정의를 정리하고 가려고 합니다.
데이터 품질이란?
최근 읽고 있는 책인 조 라이스와 맷하우슬리의 ‘견고한 데이터 엔지니어링’에 따르면, 데이터 관리는 원천 시스템 단계에서 필수적이지만, 특히 변환 단계에서는 더 중요하다고 말합니다. 저자는 크게 3가지 이유에서 데이터 품질의 중요성을 강조합니다.
(참고로 해당 책은 데이터 엔지니어링 업무를 하고 계시거나, 준비 중이신 분들 이라면 꼭 추천드립니다! 현업에서 일부 경험했지만 굉장히 모호했던 개념들이 많았는데, 이를 모두 깔끔하게 정리해주는 좋은 책입니다 ^^)
정의적 정확성 (ex: semantic, metric)
일단, 변환 단계에서는 정의적 정확성을 고려하는 것에 대한 중요성을 강조합니다. 이는 변환이 예상되는 비즈니스 논리에 부합하는가? 에 대한 물음에서 파생된 체크포인트인데, 이를 지키기 위해 변환과는 독립적으로 존재하는 semantic, metric 계층이라는 개념이 점점 더 대중화되고 있습니다.
또한, 런타임 시 변환에서 비즈니스 로직을 적용하는 대신, 이러한 정의를 변화 계층 이전에 독립 실행형 단계로 유지하는 추세로 가고있다고 합니다. 이러한 문제를 효과적으로 해결할 수 있는 툴이 바로 Dbt입니다.
사실, 보통은 semantic, metric 계층을 구축하기 이전에 사용자에 대한 정보를 모으고, 값에 대한 명확한 표현 및 분리를 위해 fact, dimension 계층에 대한 테이블을 구성해놓습니다.
본 글에서는, 실제로 dbt를 통해 간단한 A/B 테스트 과정을 위한 파이프라인을 구축해 볼 예정인데, 이때 주로 사용할 계층인 fact 그리고 dimension 테이블에 대한 설명을 먼저 진행해보겠습니다. 이미 알고계신다면 넘어가셔도 좋습니다 :)
Fact 테이블
fact 테이블은 분석의 초점이 되는 양적 정보를 포함하는 중앙 테이블을 뜻합니다. 쉽게 말하면, fact 테이블은 값을 나타내는 테이블, dimension 테이블은 값을 설명하는 테이블이라고 생각하면 되고, fact 테이블은 일반적으로 dimension 테이블들과 외래 키로 연결되곤 합니다. (보통 fact 테이블의 크기가 훨씬 큽니다)
일반적으로 fact 테이블에는 비즈니스 결정에 사용될 매출 수익, 판매량, 이익과 같은 측정 항목을 포함시킵니다.
Dimension 테이블
dimension 테이블은 fact 테이블에 대한 상세정보, 즉 특정 개체의 속성값을 제공하는 테이블입니다. (예: 고객, 제품 과 같은 테이블) 따라서, fact 테이블의 데이터에 맥락을 제공하여 다양한 방식으로 분석가능하게 해줍니다. 위에서 언급했다시피, dimension 테이블은 보통 PK를 가지며, fact 테이블에서 참조합니다.
데이터의 결함
두번째로는, 변환에는 데이터의 변형이 수반되므로 사용 중인 데이터에 결함이 없고 실제 데이터를 정확히 나타내는지 확인하는 것이 매우 중요하다고 합니다. 저는 이를 일종의 ‘데이터 정합성’을 지켜야 한다는 것에 대한 강조라고 생각합니다. 본 글에서는 데이터 정합성에 대한 논의는 중점적으로 진행하지 않을 것이긴 한데, 많은 사람들이 데이터 정합성에 대한 정의를 다른 개념과 혼동하는 것 같아 한 번 정리해보려고 합니다.
데이터 정합성이란?
일반적으로 데이터 정합성이라고 하면, data set에 대한 결손값이나, 중복값, 혹은 이상값을 얼마나 잘 검증했는지를 뜻한다고 생각합니다. 엄밀히 개념을 설명하자면, 데이터 정합성이란 어떠한 데이터들에 대한 값이 서로 일치한지를 의미합니다.
데이터 정합성 검증 예시
보통, 원천 데이터에서 데이터를 가져올 경우 기본적으로 데이터가 올바르게 들어 왔는지에 대한 확인이 필요합니다. 이를 검증하기 위해서 OLTP → OLAP 형태의 데이터 파이프라인을 기준으로 설명하면 아래와 같은 2가지의 기본적인 검증 로직을 추가할 수 있습니다.
첫번째로, 원천 데이터와 목적지 데이터의 건수가 같은지 비교합니다.
원천 데이터에 로그 적재 시간이 적재되어 있다고 가정하면, created_date에 특정기간에 대한 조건을 걸어서, 레코드를 카운트하고 이를 비교하여 중복이나 결손값을 확인할 수 있습니다. 이때, 원천 데이터가 인덱스가 지원되는 OLTP 기반의 DB라면 created_date에 인덱스를 설정하면 부하를 줄일수 있습니다.
또한, 이 과정에서 전체 레코드수를 계산하지 않고 특정 기간에 필터링을 거는 이유는 보통 원천데이터 소스는 OLTP 기반의 DB에 저장되어 있기 때문에, 계속해서 데이터가 변하기 때문에 기간별로 필터링하는 것이라고 할 수 있습니다. 추가로, 이러한 모니터링 결과는 데이터의 증감률이나, 최근 데이터의 존재여부를 가시적으로 확인할 수 있다는 장점도 있습니다.
두번째로는, 목적지의 데이터의 유니크 키값을 이용하여 중복이 없는지를 비교합니다.
사실 앞서 검증한 데이터의 건수가 올바르다고 해도, 아래와 같은 SQL문을 통해 중복에 대한 검증은 추가로 진행되어야 합니다.
SELECT
id,
COUNT(*) as cnt
FROM
raw_data.user_event
GROUP BY id
HAVING COUNT(*) > 1간단하게 데이터 정합성의 개념과 검증 방법에 대해 알아보았는데, 가장 중요한 것은 이러한 데이터를 검증 하기 위한 과정에서 비용이 많이 발생하거나 시스템의 부하를 줄 경우를 고려하며 개발을 진행해야 한다는 것입니다.
이제 본론으로 돌아와, 데이터 품질에 대한 3번째 논의로 넘어가보려고 합니다 :)
데이터 카탈로그
마지막으로, 데이터 변환 때문에 데이터 집합이 동일한 경로에서 어떻게 파생되었는지 알기 어려울 수 있다는 점이 있습니다. 이는 데이터 카탈로그 문제로 치환될 수 있는데, 이렇게 데이터의 계보를 유지하고 모니터링할 수 있는 것도 중요합니다. 이를 데이터 엔지니어가 직접 작업하고 운영한다는 것은 시간이 많이 소모되고 고된 일이라는 것을 아실 것입니다. 이러한 문제는 보통 오픈소스인 Datahub를 사용하여 해결합니다.
Dbt를 본격적으로 설명하기 전에, 먼저 짚고 넘어가야 할 히스토리를 유지하는 것에 대한 중요성과 5가지 SCD Type에 대한 개념을 정리해봅시다.
history를 왜 유지해야 할까?
OLAP 환경인 데이터 웨어하우스나 데이터 레이크에서 테이블들의 히스토리를 유지하는 것이 중요한 이유는 일부 속성들은 시간을 두고 변하게 되기 때문입니다.
보통은 created_at (생성시간으로 한번 만들어지면 고정)과 updated_at (마지막 수정 시간을 나타냄)과 같은 timestamp 필드를 생성하여 관리하는 것이 좋은데, 컬럼의 성격에 따라 이를 어떻게 유지할 지에 대한 방법이 또 달라집니다. 이를 설명하기 위한 개념인 SCD Type (Slowly Changing Dimension) 5가지에 대해 설명드리겠습니다.
SCD Type 0
SCD Type 0는 한번 쓰고 나면 바꿀 이유가 없는 경우들을 뜻합니다. 예를 들어, 유저의 회원등록일이나 제품 첫 구매일과 같이 첫 이벤트 발생 시에 정해지면 갱신되지 않고 고정되는 필드들이 있을 것입니다.
SCD Type 1
SCD Type 1는 데이터가 새로 생기면, 덮어쓰면 되는 컬럼들에 대한 특성입니다. 또한, 처음 레코드 생성시에는 존재하지 않았지만, 나중에 생기면서 채우는 경우도 이에 해당합니다.
예를들어, 연간 소득 필드의 경우 지속적으로 덮어쓰면 큰 이상이 없을 것이고, 고객이 초기에 이메일을 저장하지 않았을 때, 후에 업데이트하는 경우도 예시로 적합합니다.
SCD Type 2
SCD Type 2는 특정 entity에 대한 데이터가 새로운 레코드로 추가되어야 하는 경우입니다.
예를 들어, 이커머스 서비스를 사용중인 유저의 등급이 변화했다고 가정해봅시다.

이때, rank가 update된 사항은 중요한 데이터가 될 수 있으므로 변경시간을 같이 추가하여 데이터 품질을 유지할 수 있을 것입니다. 참고로 SCD Type 2 은 이후 dbt snapshot 기능을 사용하면서 한번 더 언급할 특성입니다 :)
SCD Type 3
SCD Type 3 는 SCD Type 2의 대안으로, 특정 entity 데이터가 새로운 컬럼으로 추가되는 경우를 뜻합니다.
위의 경우와 동일한 상황이라면, 아래와 같이 새로운 컬럼 (previous_rank)를 생성하여 데이터 품질을 유지할 수 있을 것입니다. 이 경우에도 변경시간 또한 별도 컬럼으로 존재해야 할 것입니다.
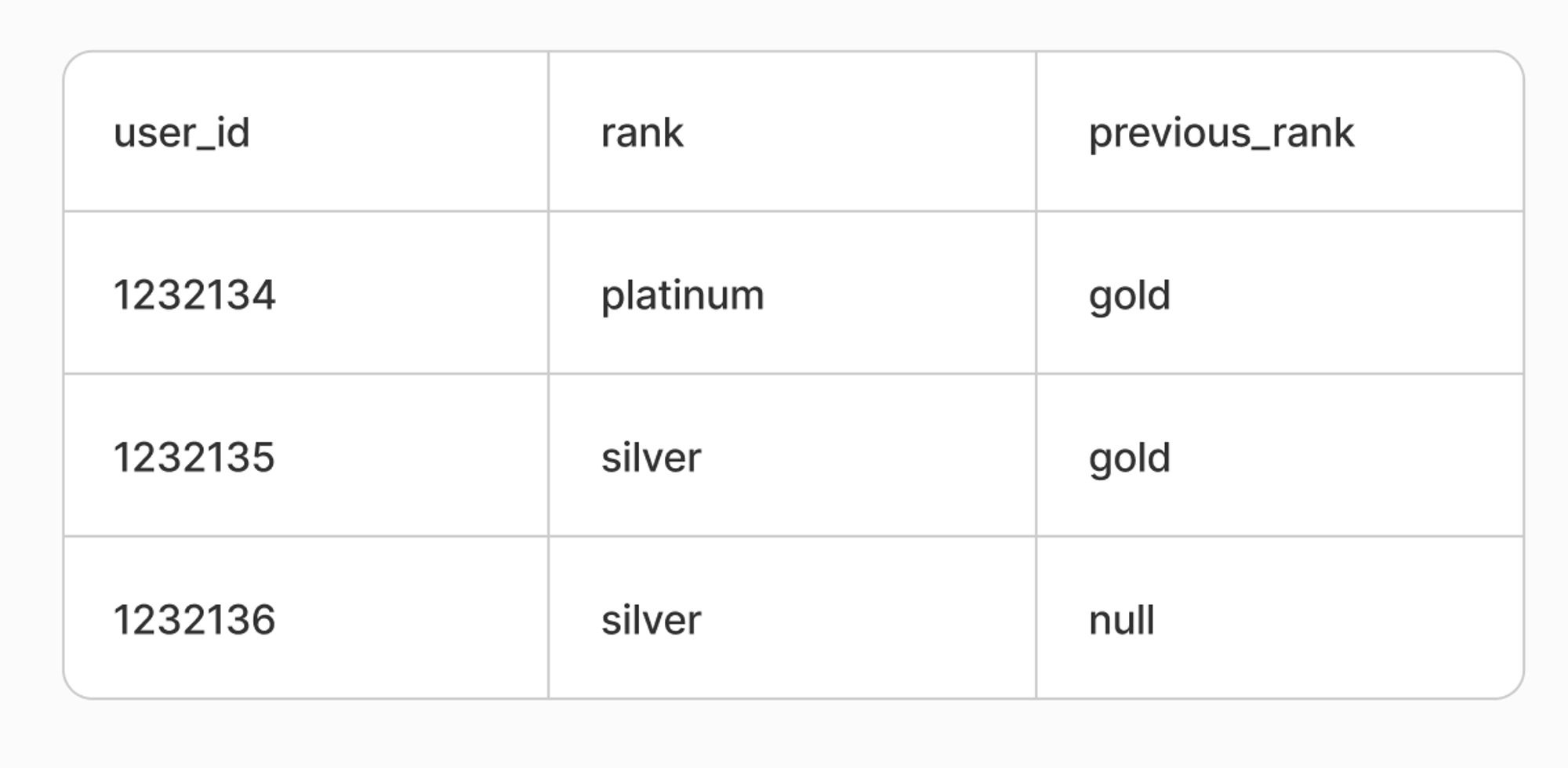
SCD Type 4
SCD Type 4 는 특정 entity에 대한 데이터를 새로운 Dimension 테이블에 저장하는 경우로, 일종의 SCD Type 2의 변종입니다. 예를 들어, 위 상황과 동일하다면 아래처럼 별도의 과거 이력 테이블을 생성하여, 아예 일반화하여 히스토리를 유지하는 방식입니다.
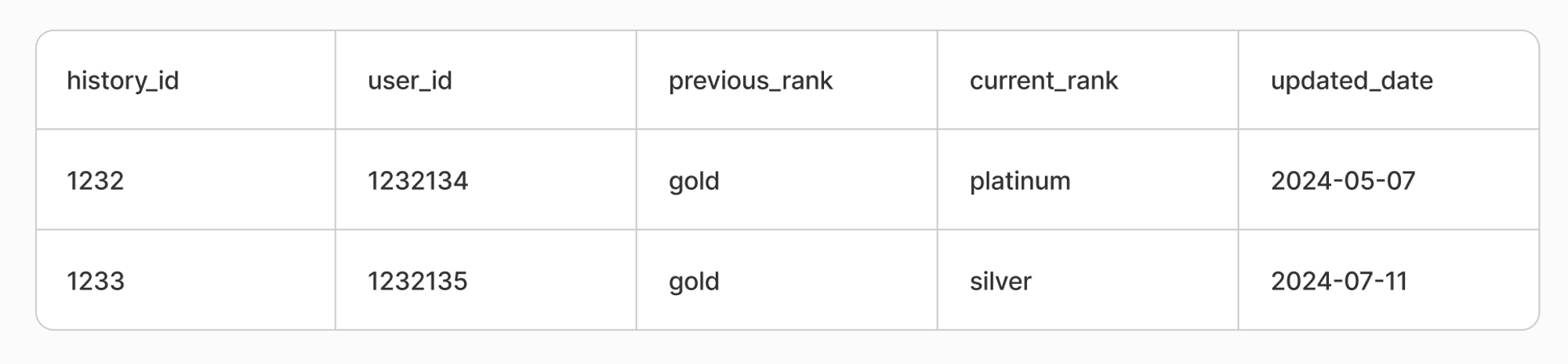
지금까지, 데이터 품질의 정의와 히스토리의 중요성, 그리고 SCD Type (Slowly Changing Dimension)에 대해 알아보았습니다. 특히, SCD Type에서 논의하는 지점들에 대해서 Dbt는 특정 세팅만 해주면 이와 같은 특성들에 대한 적절한 대처를 큰 스트레스(?)없이 효율적으로 진행할 수 있습니다.
그럼 이제 Dbt가 무엇인지, 어떤 방식으로 데이터 변환 과정에 관여하는지를 본격적으로 알아보겠습니다.
What is Dbt?
출처: https://docs.getdbt.com/docs/introduction
Dbt는 Data Build Tool의 약자로 ELT(Extract, Load, Transform)용 오픈소스 도구로, 데이터 웨어하우스 내에서 데이터 변환을 수행합니다. (ELT와 ETL의 개념에 대해서는 예전에 Data와 Data Engineer의 역할이라는 포스팅에서 짧게 언급하였으니 확인해주시면 감사하겠습니다 🙂)
여담이지만, Dbt의 등장으로 Analytics Engineer라는 직무 개념이 나왔다고 합니다.
우리가 흔히 알고 있는 BigQuery나 Snowflake와 같은 데이터 웨어하우스 솔루션들은 모두 지원하는 것으로 보입니다. 보통은 아래와 같이 Airlfow로 dbt를 스케줄링하고, DW와 연동된 dbt내의 여러 모델을 적절한 구조로 배치하고, 이를 실행한 결과를 통해 원하는 데이터를 확인할 수 있도록 데이터 파이프라인을 구성합니다.
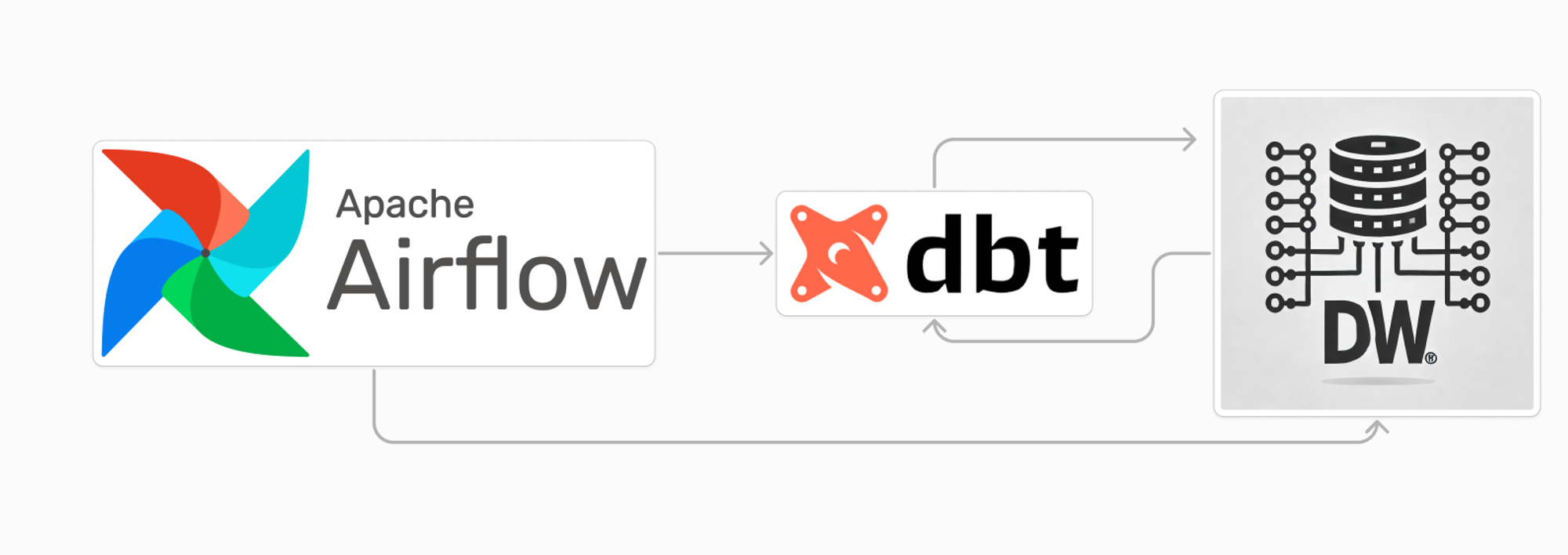
dbt는 dbt Labs에서 제공하는 Cloud 버전도 존재합니다. 워낙, 툴 자체가 가볍기 때문에 우리가 늘 고려하는 DW 비용(?)처럼 큰 무리를 주지 않고, 직접 관리하는 리소스 비용을 생각하면 비용이 적절하여 많이 사용한다고 합니다. 본 글에서는, dbt를 직접 설치(dbt core)하여 로컬에서 작업해보려고 합니다.
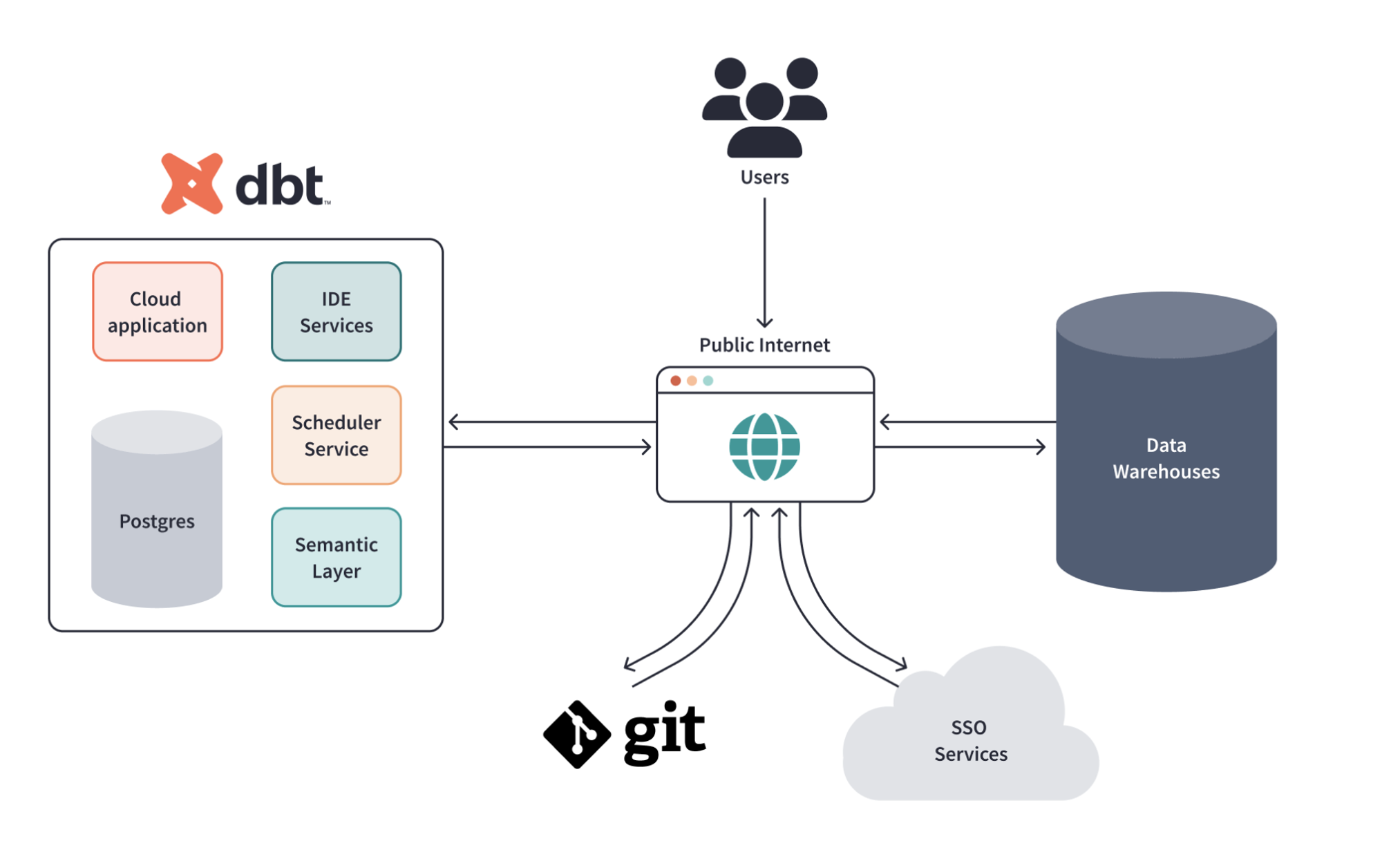
출처: https://docs.getdbt.com/docs/cloud/about-cloud/architecture
Dbt의 특징
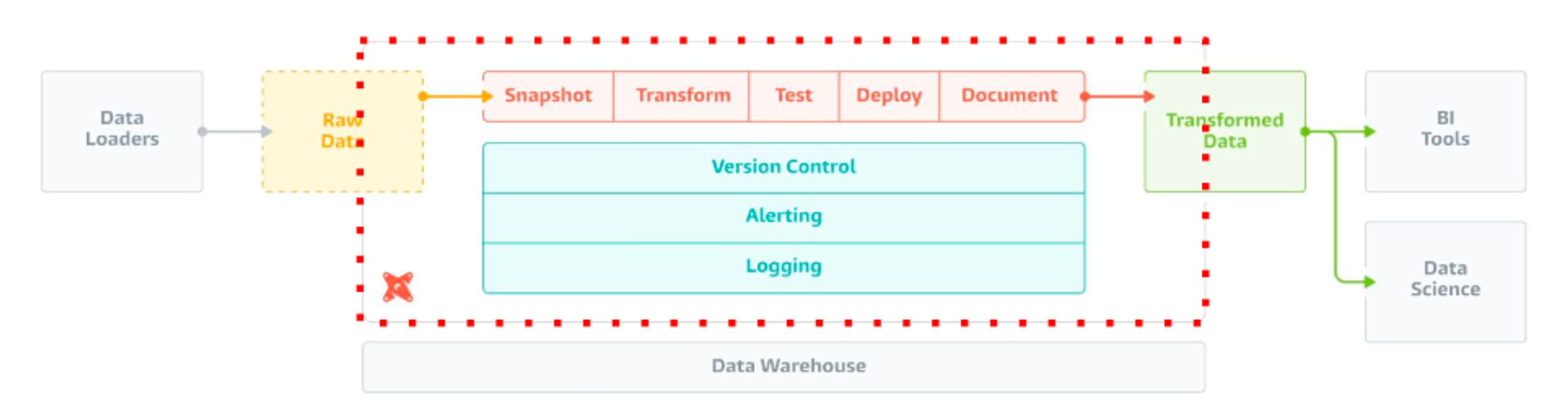
Dbt는 아래와 같은 특징들을 가지고 있어, 데이터 엔지니어의 여러 요구조건을 만족시킬 수 있습니다.
- 데이터 변경 사항을 이해하기 쉽고 rollback 가능: SQL 기반의 변환 작업을 코드로 관리하여, 변경 사항을 쉽게 추적하고 rollback을 지원
- 데이터 품질 테스트 및 에러 보고: 데이터 테스트 기능을 제공하여, 데이터 품질을 보장하고 에러를 사전에 감지 (ex:
dbt test) - Fact 테이블의 Incremental Update: Incremental Update 기능을 지원하여, Fact 테이블의 데이터를 효율적으로 갱신 가능
- Dimension 테이블 변경 추적 (history 테이블): SCD Type을 고려한 기능을 통해 Dimension 테이블의 변경 이력을 추적 가능
이외에도 dbt에서는, dbt docs generate 명령어를 통해 편리하게 documentation 기능을 활용할 수 있고, dbt docs serve 명령어를 통해 데이터간 리니지를 쉽게 확인할 수 있는 기능도 지원합니다만, 본 글에서는 위의 특징들을 중점적으로 활용하고, 실제 구현하는 방식에 대해 설명해보려고 합니다 😄
Dbt로 A/B 테스트해보기
A/B 테스트 분석을 쉽게 하기 위한 ELT 테이블을 만들어보자!
도입
먼저, Dbt 파이프라인을 구축하기 위해 DW는 AWS Redshift를 채택하였고, 입력테이블은 아래와 같이 생성하였습니다. (참고로, dummy_data는 미리 random한 데이터를 생성하여 csv형태로 테이블을 만든 뒤, 삽입하였습니다)
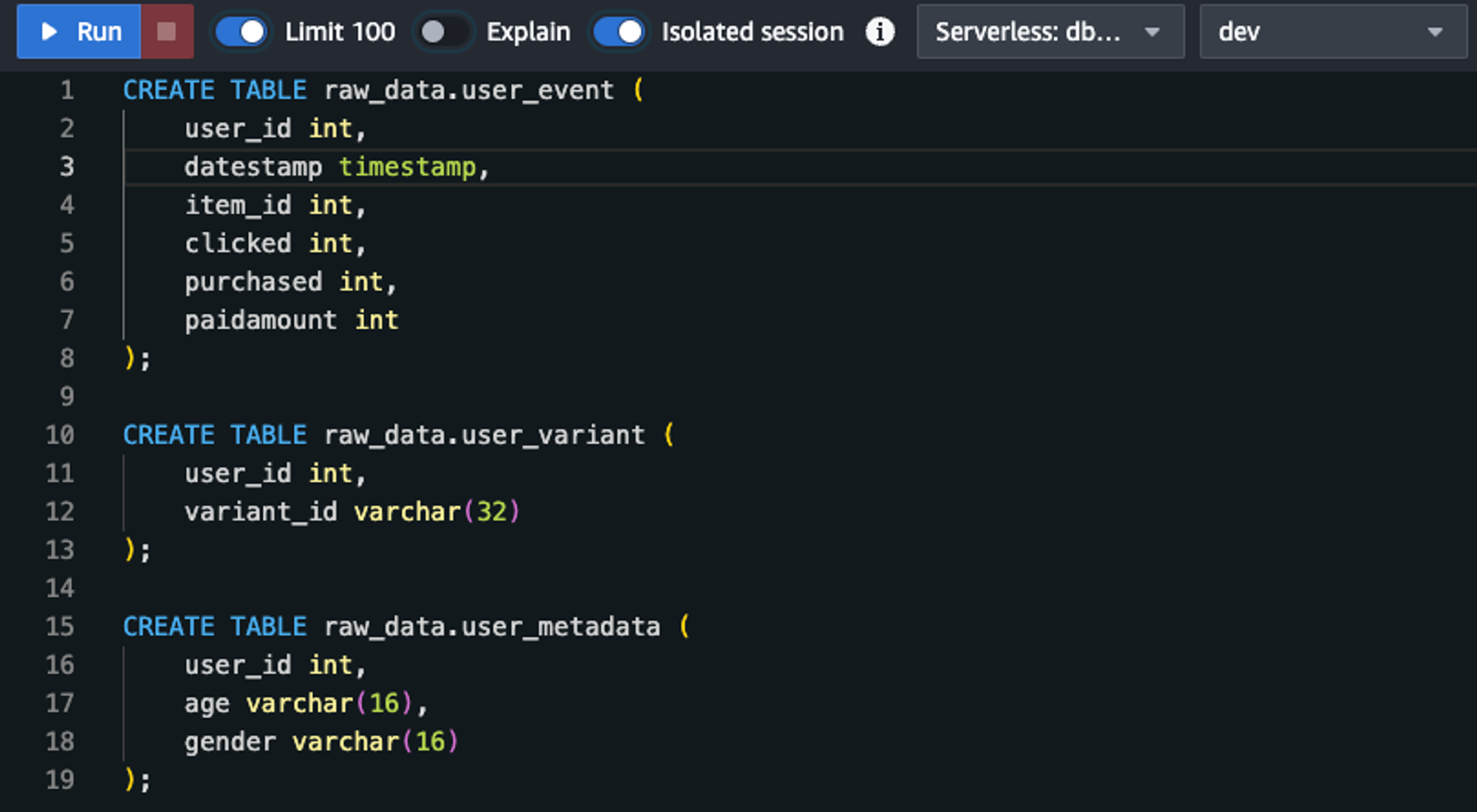
user_event: 사용자, 날짜, 아이템 별로 impression이 있는 경우에 해당 정보를 기록하고, impression으로 부터 클릭, 구매, 구매 시 금액이 기록되는 데이터- 실제 환경에서는 이러한 aggregate정보를 로그 파일등의 소스로부터 만들어내는 프로세스가 필요할 것입니다.
user_variant: 사용자가 소속한 AB test variant를 기록한 데이터입니다. (예: control vs test)- 보통은 experiment와 variant 테이블이 별도로 존재하고, 언제 variant_id로 소속되었는지를 기록하는 timestamp 필드가 존재하는 것이 일반적입니다.
user_metadata: 성별, 나이 등의 메타정보를 담은 데이터- 이를 이용하여 여러 각도에서 AB테스트를 진행하여 다양한 인사이트를 도출할 수 있습니다.
최종적으로, 저희의 목표인 ELT 테이블 (생성테이블)은 미리 SELECT문으로 표현해보면, 아래와 같은 형태일 것입니다.
SELECT
variant_id,
ue.user_id,
datestamp,
age,
gender,
COUNT(DISTINCT item_id) num_of_items, -- 총 impression
COUNT(DISTINCT CASE WHEN clicked THEN item_id END) num_of_clicks, -- 총 purchase
SUM(paidamount) revenue -- 총 revenue
FROM raw_data.user_event ue
JOIN raw_data.user_variant uv ON ue.user_id = uv.user_id
JOIN raw_data.user_metadata um ON uv.user_id = um.user_id
GROUP by 1, 2, 3, 4, 5;생성 테이블: Variant 별 사용자에 대한 daily summary 테이블
- variant_id, user_id, datestamp, age, gender (5개의 필드에 대해 그룹바이)
- 총 impression, 총 click, 총 purchase, 총 revenue (sum 분석)
추가적으로, raw_data 스키마 이외의 분석을 위한 용도로 danie 라는 스키마를 생성하였습니다.
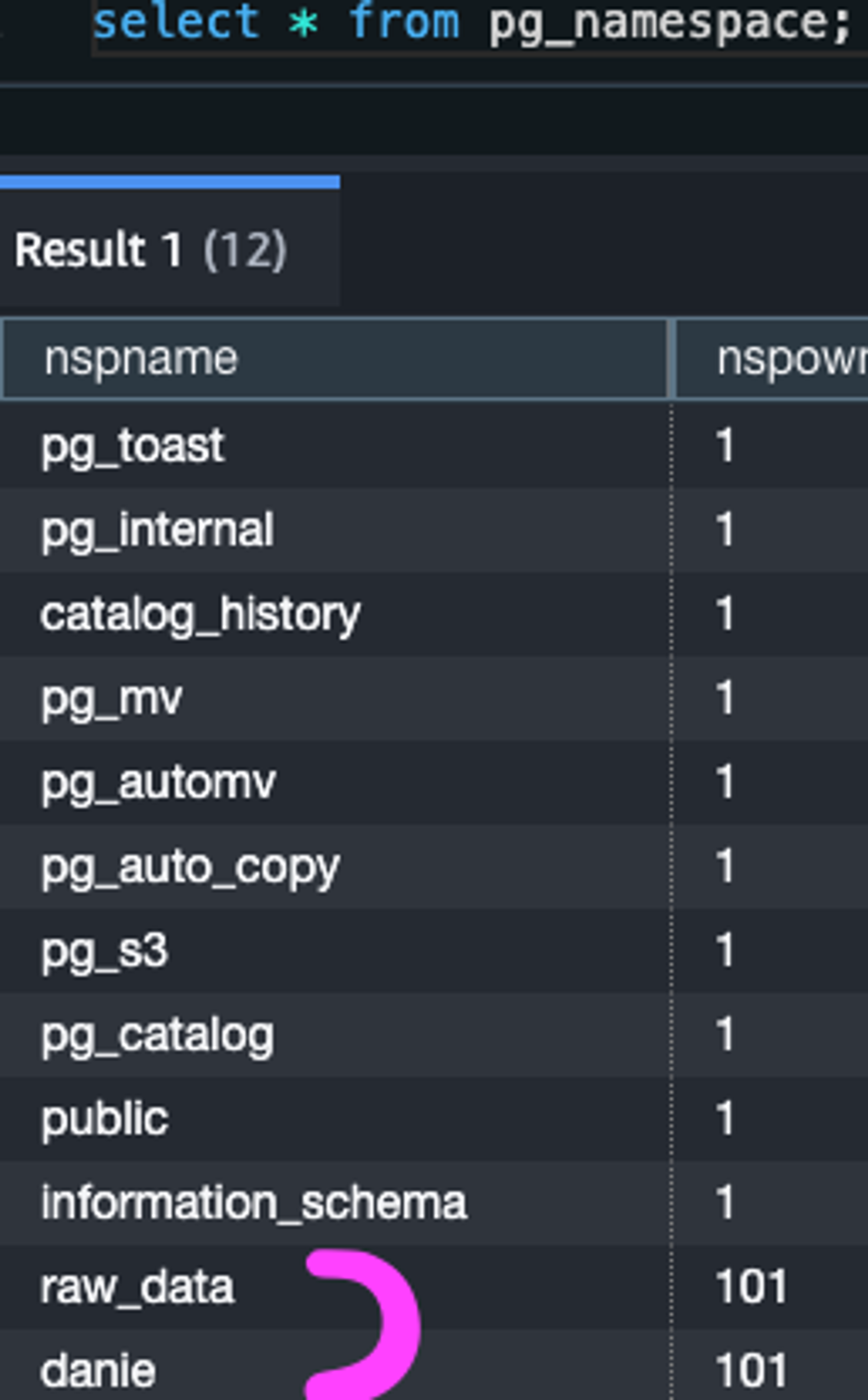
dbt 설치
이제, dbt를 직접 설치해야 하는데 저는 dbt에 대해 조금 더 깊게 알아보기 위해, dbt Cloud 대신 dbt Core를 직접 로컬에 설치하여 진행해보려고 합니다 :)
(늘 느끼는 것이지만, 공식문서보고 직접 설치 파일을 하나하나 뜯어보는 것이 나한테 가장 빠른 학습 방법인 것 같다ㅎ)
아래 명령어를 실행하여 dbt-redshift 를 설치하게 되면, dbt Core를 설치함과 동시에 redshift와의 연동을 쉽게 진행할 수 있습니다.
pip3 install dbt-redshift
참고로, python은 3.12x 버전, dbt는 1.8x를 사용하였고 각 버전 호환성은 아래 링크에 정리되어 있습니다.
What version of Python can I use? | dbt Developer Hub
dbt 프로젝트 생성
아래 명령어를 실행하게 되면, dbt 프로젝트를 생성함과 동시에 Redshift connection을 위한 config를 설정할 수 있습니다.
dbt init dbt_user_analysis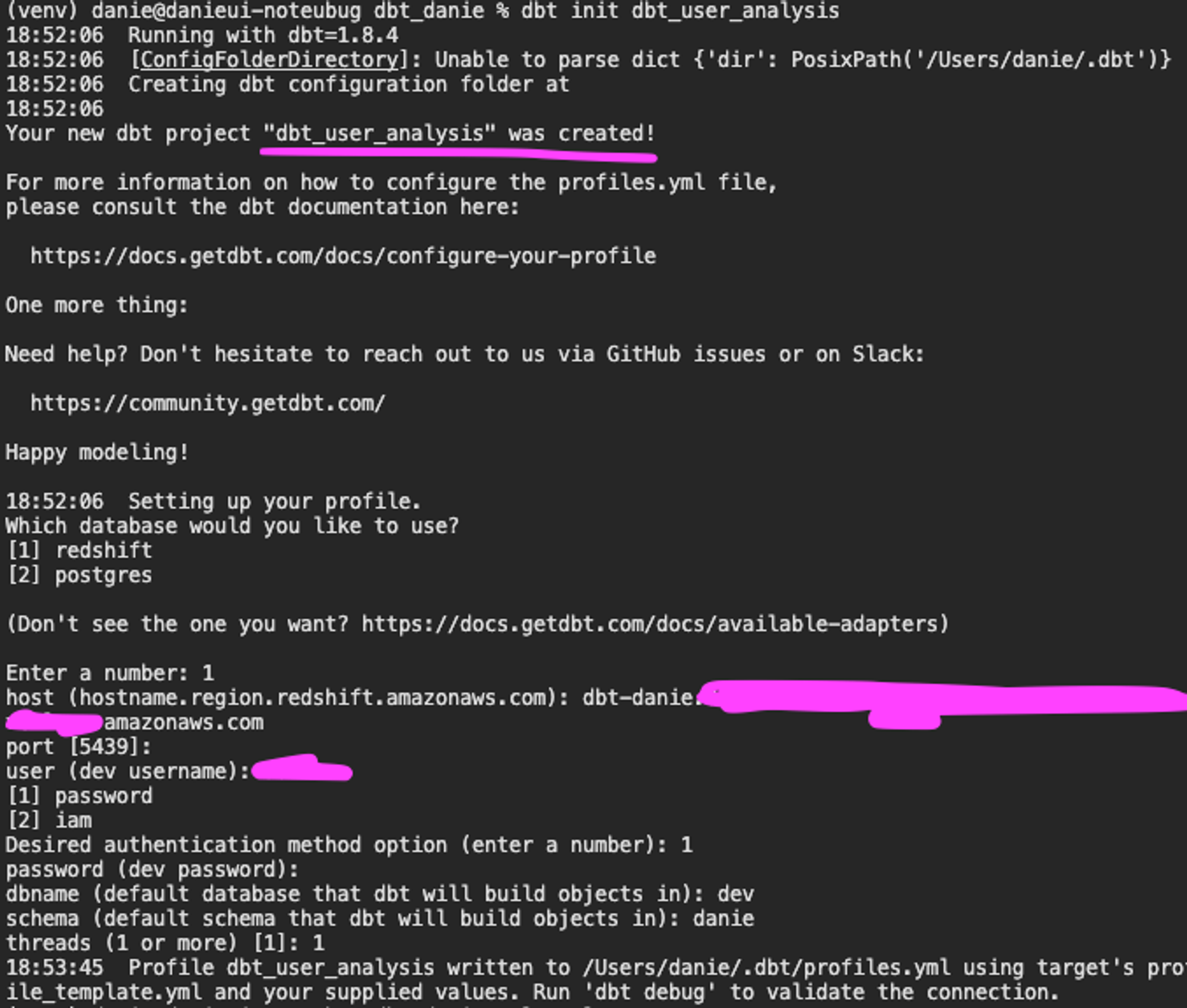
아래의 사진처럼, 프로젝트 디렉토리 dbt_user_analysis 는 dbt_project.yml, tests, snapshots, models 등을 포함하고 있습니다.
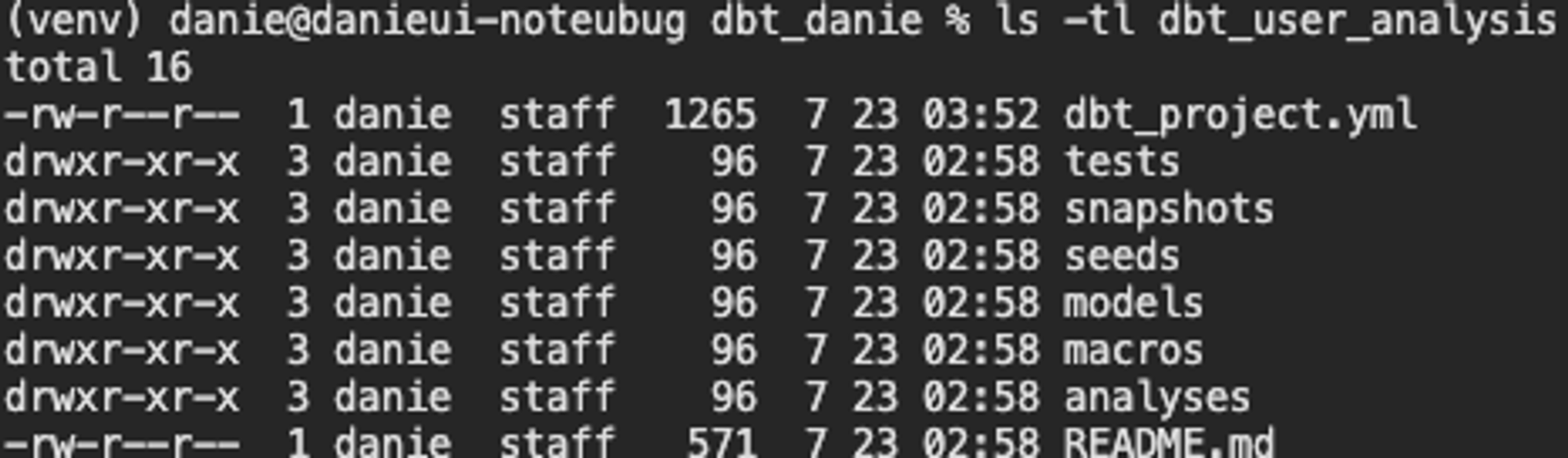
이제부터 dbt의 핵심 구성 및 기능이라고 할 수 있는 models, tests, snapshots 를 중심으로 글을 이어나가겠습니다.
dbt model
dbt model은 ELT 테이블을 만들 때 기본이 되는 빌딩 블록이고, Table이나 View 혹은 CTE의 형태로 존재합니다. 또한, model은 일종의 입력, 중간 그리고 최종 테이블을 정의하는 곳이라고 생각하면 되는데, 구체적으로 설명하면 아래와 같습니다.
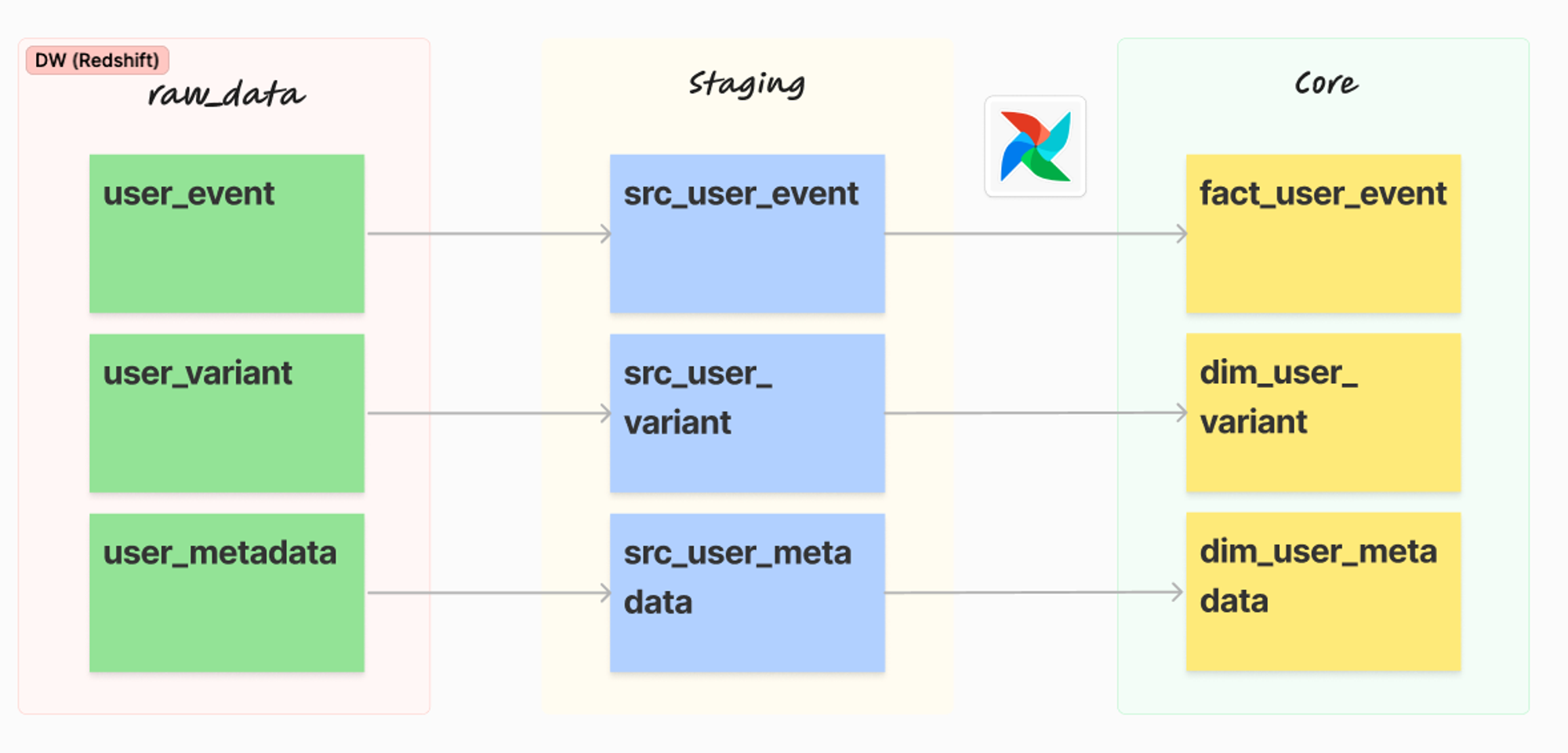
dbt model은 raw, staging, core와 같은 일종의 계층에 대한 티어 개념이 존재하는데, raw → staging (src) → core의 순서로 이해하면 됩니다.
Input
입력(raw)과 중간(staging, src) 데이터 정의
raw는CTE로 정의staging은View로 정의
Output
최종 (core) 데이터 정의
core는Table로 정의
최종적으로, 위와 같은 데이터 정의들은 models 디렉토리 아래에 SQL파일로 존재합니다.
이제 A/B 테스트를 위한 최종 ELT 테이블을 위해 raw에서부터 core까지 이어지는 과정을 총 3가지 단계를 통해 실제 구현해보겠습니다.
1단계
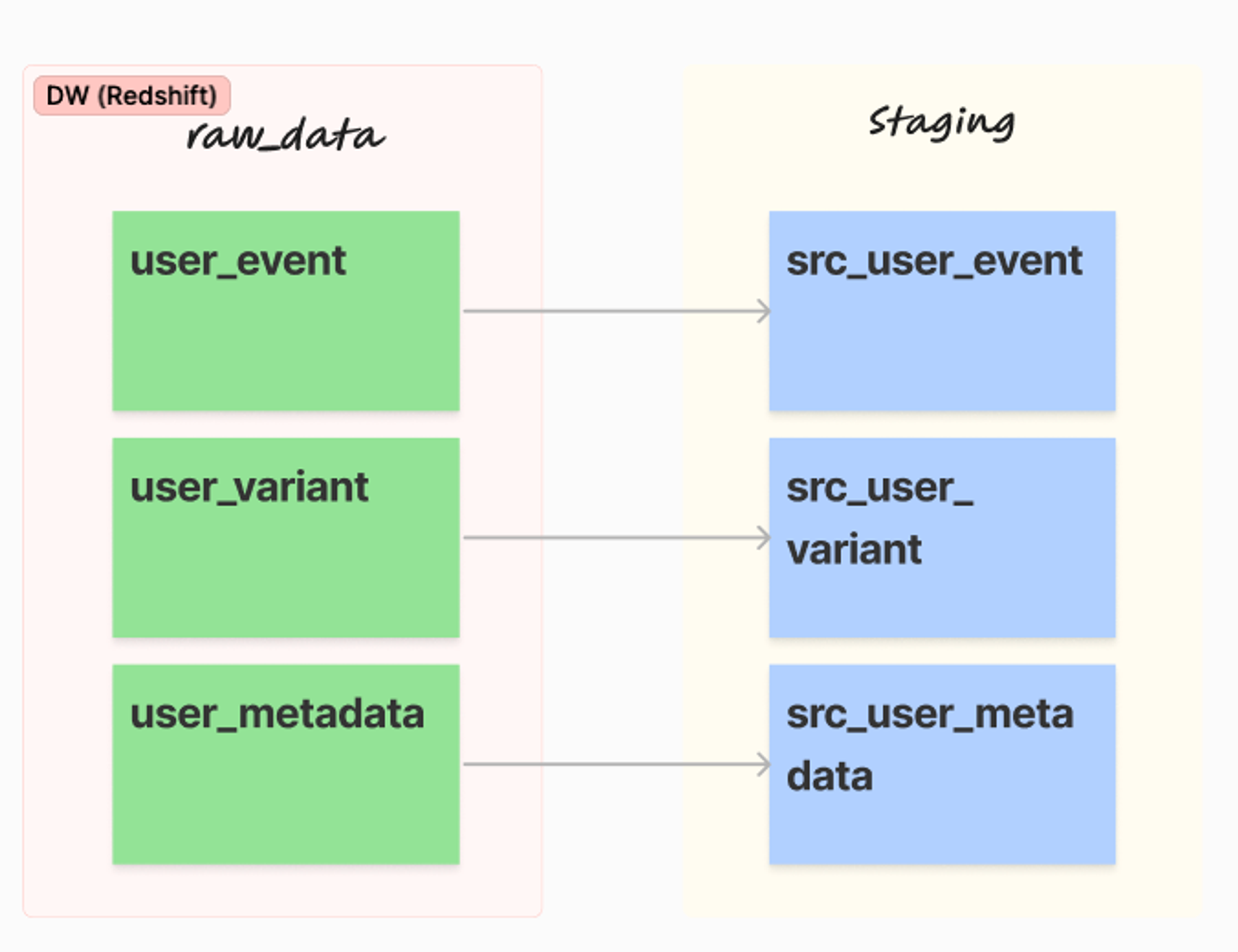
DW에 존재하는 raw_data를 기반으로 데이터 품질을 검증하여 Staging단계에 올리는 과정입니다. 데이터 용량이 매우 클 경우에는, incremental_update 타입으로 append시켜 유지하면 됩니다.
src (base) 테이블은 아래와 같이 정의하였습니다.
src_user_event.sql
WITH src_user_event AS (
SELECT * FROM raw_data.user_event
)
SELECT
user_id,
datestamp,
item_id,
clicked,
purchased,
paidamount
FROM src_user_eventsrc_user_variant.sql
WITH src_user_variant AS (
SELECT * FROM raw_data.user_variant
)
SELECT
user_id,
variant_id
FROM
src_user_variantsrc_user_metadata.sql
WITH src_user_metadata AS (
SELECT * FROM raw_data.user_metadata
)
SELECT
user_id,
age,
gender,
updated_at
FROM
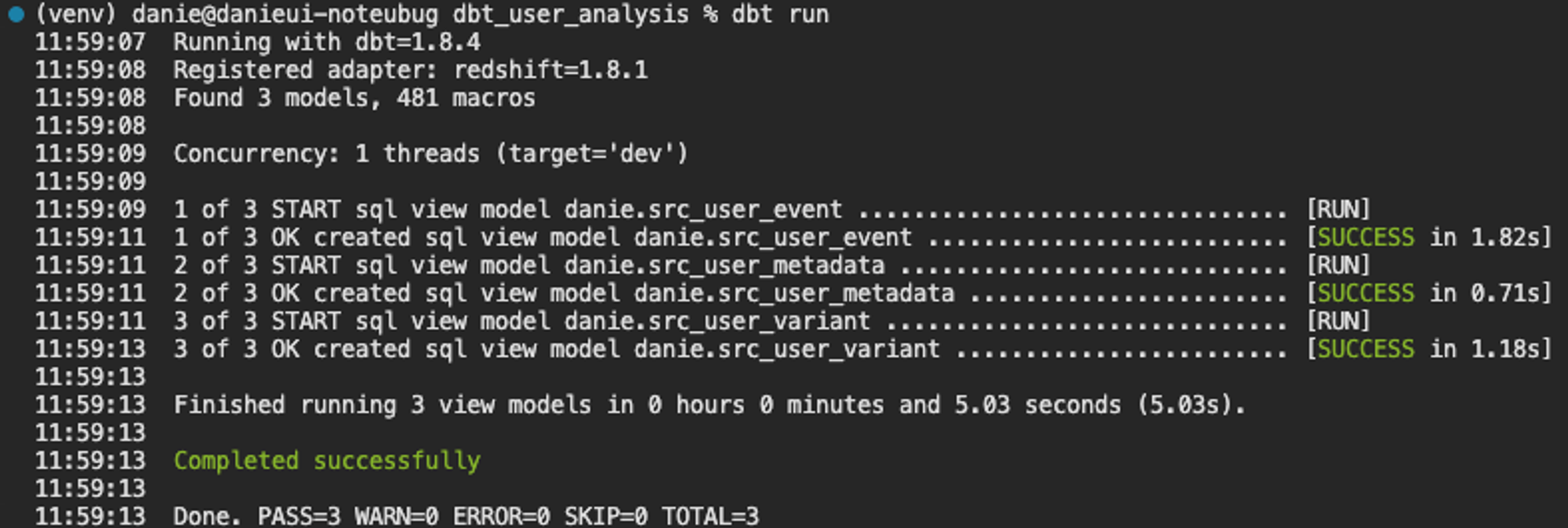
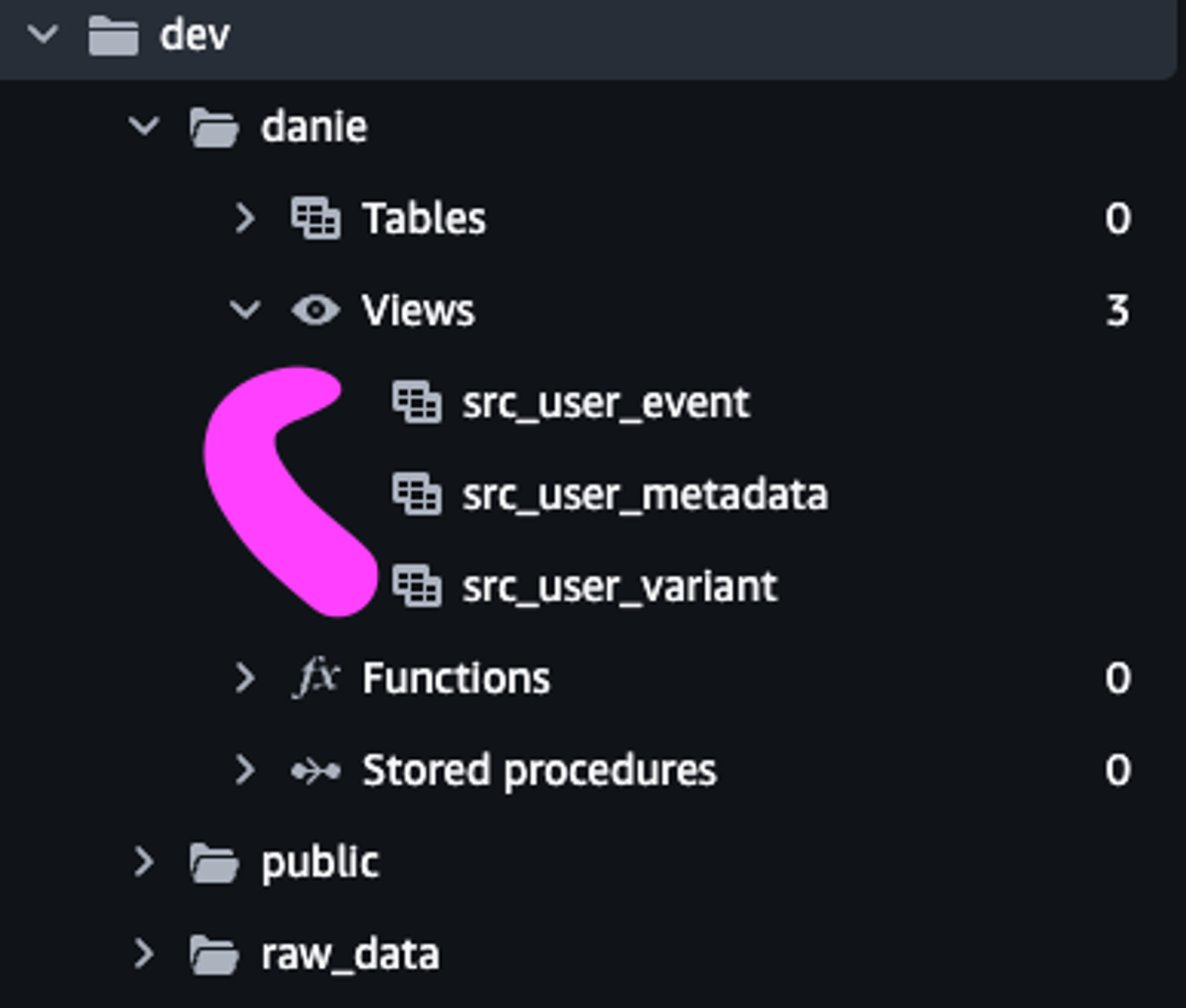
src_user_metadata 초기 dbt 프로젝트를 생성하면 기본적으로 models 디렉토리에 example이 주어지는데, 이를 삭제하고 위의 src모델들을 추가하였고, dbt run을 실행해보면 아래와 같은 결과를 볼 수 있습니다.
dbt debug
dbt run
Redshift
2단계
위 사진과 같은 과정을 진행하기 전에, dbt에서 중요한 개념인 Materialization에 대해서 알아볼 필요가 있습니다.
What is Materialization?
Materialization 은 입력 데이터들을 연결해서 새로운 데이터를 생성하는 것 (방식)을 뜻하는데, 보통 여기서 추가 transformation이나 data cleanup을 수행합니다.
dbt는 4가지의 내장 materialization을 제공하는데, 이는 아래와 같습니다.
View
- 데이터를 자주 사용하지 않는 경우
Table
- 데이터를 반복해서 자주 사용하는 경우
Incremental (Table Appends)
- Fact 테이블
- 과거 레코드를 수정할 필요가 없는 경우
- Upsert 지원
Ephemeral (CTE)
- 한 SELECT에서 자주 사용되는 데이터를 모듈화하는데 사용
materialized format을 config를 통해서 테이블마다 정해줄 수도 있지만 dbt_project.yml 파일을 수정하여 진행해도 됩니다. 저는 dbt_project.yml의 models 부분을 아래와 같이 수정하여, 프로젝트의 테이블들은 기본적으로 view로 빌드되지만, dim 디렉토리에 있는 테이블들은 모두 table로 빌드되는 구조를 유지했습니다.
models:
dbt_user_analysis:
+materialized: view
dim:
+materialized: tableJinja 템플릿
이제부터 model을 생성하는 SQL문에서는 Jinja 템플릿을 활용해 볼 것입니다.
dbt에서는 Jinja 템플릿을 기반으로 ref 태그와 config를 활용하여 dbt 작업의 효율성을 더할 수 있습니다.
아래의 SQL문에서는 ref 태그를 통해 dbt내의 다른 테이블들에 엑세스를 진행할 것이고, config문을 사용하여 materialized 종류와 입력을 할 때 스키마가 변경되었을 경우에 대응 전략을 정할 수 있는 on_schema_change 파라미터를 사용할 것입니다.
on_schema_change는 fail, sync_all_columns, ignore, append_new_columns 등이 있는데, 나머지 방식을 사용한다고 해도 성공보장이 없기 때문에, fail 처리가 가장 안정적인 방식일 것입니다.
fact_user_event.sql
그럼에도, 중복데이터가 생길 수 있기때문에 새로 생긴데이터만 incremental하게 업데이트 하려면 아래와 같이 별도의 where절을 사용하여 처리하면 된다.
{{
config(
materialized = 'incremental',
on_schema_change='fail'
)
}}
WITH src_user_event AS (
SELECT * FROM {{ ref("src_user_event") }}
)
SELECT
user_id,
datestamp,
item_id,
clicked,
purchased,
paidamount
FROM
src_user_event
WHERE datestamp is not NULL
{% if is_incremental() %}
AND datestamp > (SELECT max(datestamp) FROM {{ this }})
{% endif %}dim_user_metadata.sql
WITH src_user_metadata AS (
SELECT * FROM {{ ref('src_user_metadata') }}
)
SELECT
user_id,
age,
gender,
updated_at
FROM
src_user_metadatadim_user_variant.sql
WITH src_user_variant AS (
SELECT * FROM {{ ref('src_user_variant') }}
)
SELECT
user_id,
variant_id
FROM
src_user_variant
추가로, config에서 incremental_strategy 파라미터도 설정할 수 있는데, 아래의 값들을 사용할 수 있습니다.
- append
- merge
- insert_overwrite
상황에 따라, unique_key와 merge_update_columns필드를 사용하기도 하므로, 이러한 사항들을 고려하여incremental_strategy 를 적절하게 사용하면 좋을 것 같다.
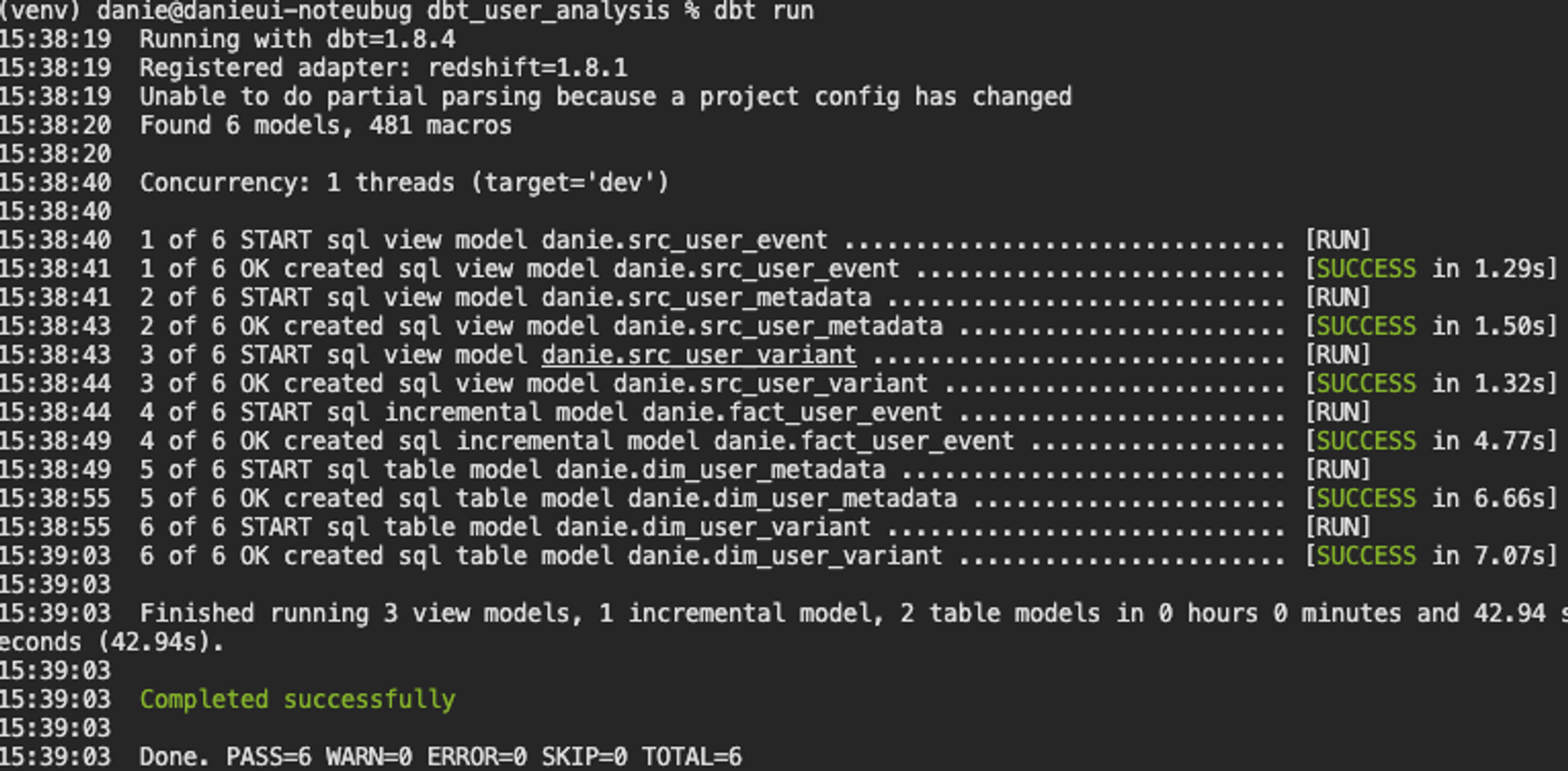
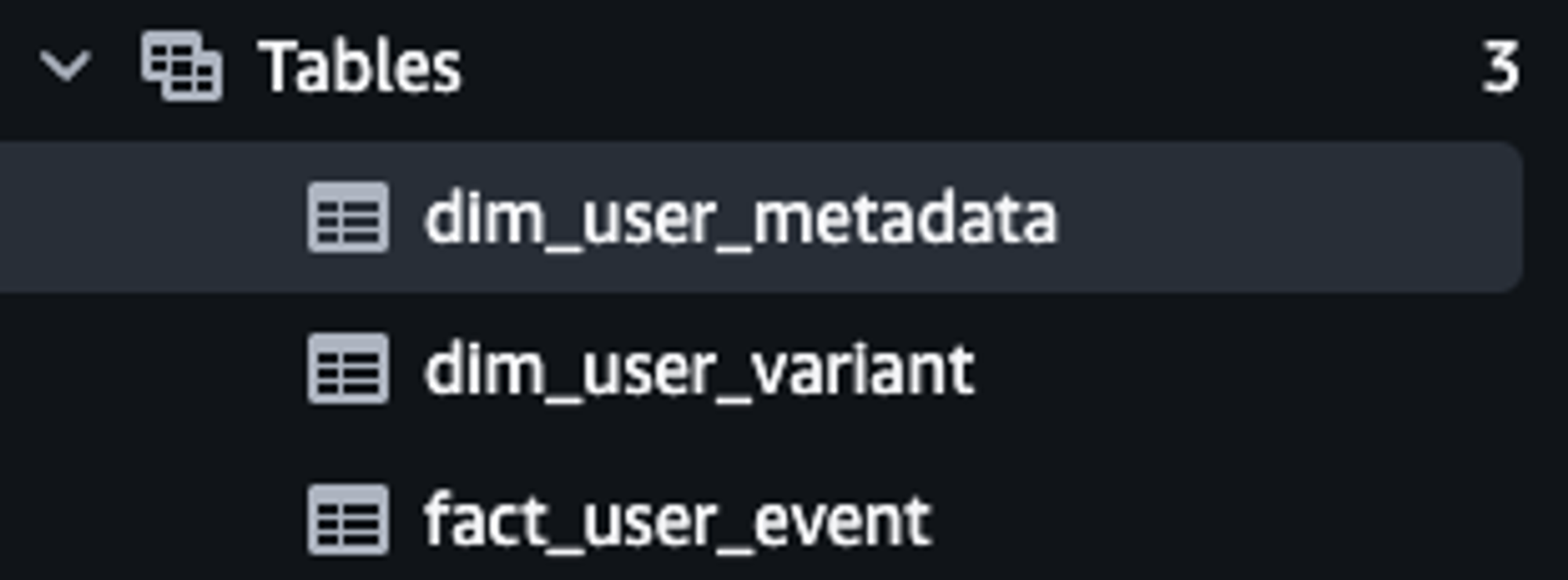
이제 dbt run 을 통해 실행해보면 아래와 같이 테이블이 생성된 것을 확인할 수 있다.
참고로
dbt compile은 SQL code 까지만 생성하고 실행하지는 않는다. 여기서 말하는 SQL code는 target디렉토리에 존재한다.
3단계
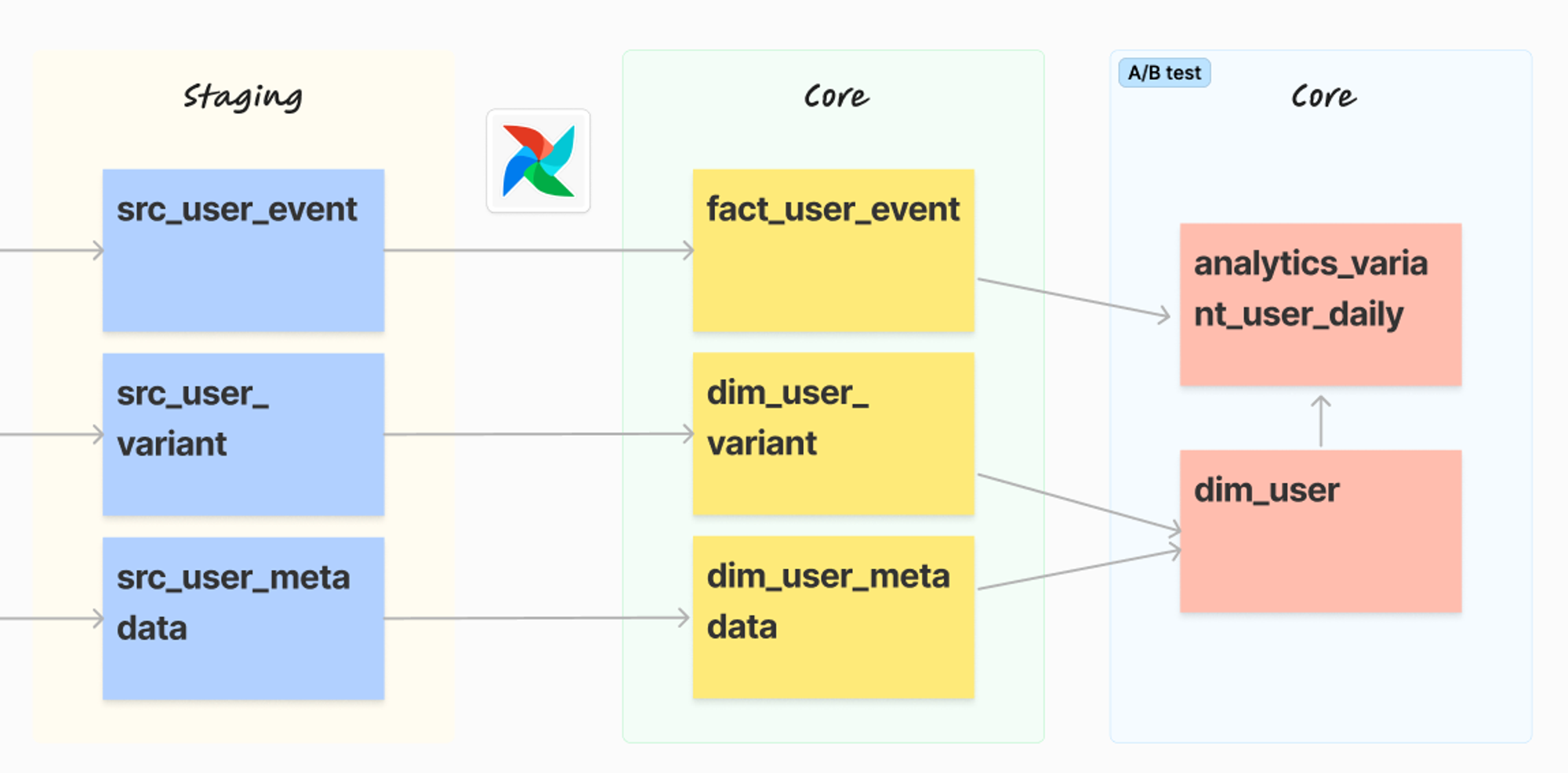
최종적으로 A/B 테스트의 결과를 도출하기 위한 작업을 진행해보겠습니다.
어느 variant에 속해있는지, 성별과 연령은 어떻게 분포하는지를 보기 위해 먼저, dim_user_variant와 dim_user_metadata를 JOIN하여 dim_user 테이블을 구성하려고 합니다.
dim_user.sql
WITH um AS (
SELECT * FROM {{ ref("dim_user_metadata") }}
), uv AS (
SELECT * FROM {{ ref("dim_user_variant") }}
)
SELECT
uv.user_id,
uv.variant_id,
um.age,
um.gender
FROM
uv
LEFT JOIN um ON uv.user_id = um.user_id마지막으로, impressions, clicks, 구매 등에 대한 통계를 살펴보기 위해 dim_user와 fact_user_event를 조인하여 새로 생성한 analytics 디렉토리 밑에 analytics_variant_user_daily 테이블을 구성합니다.
analytics_variant_user_daily.sql
WITH u AS (
SELECT * FROM {{ ref("dim_user") }}
), ue AS (
SELECT * FROM {{ ref("fact_user_event") }}
)
SELECT
variant_id,
ue.user_id,
datestamp,
age,
gender,
COUNT(DISTINCT item_id) num_of_items,
COUNT(DISTINCT CASE WHEN clicked THEN item_id END) num_of_clicks,
SUM(purchased) num_of_purchases,
SUM(paidamount) revenue
FROM
ue
LEFT JOIN u ON ue.user_id = u.user_id GROUP by 1, 2, 3, 4, 5이제 dbt run 을 통해 실행해보면 A/B 테스트를 위한 최종적인 테이블이 생성된 것을 확인할 수 있습니다.
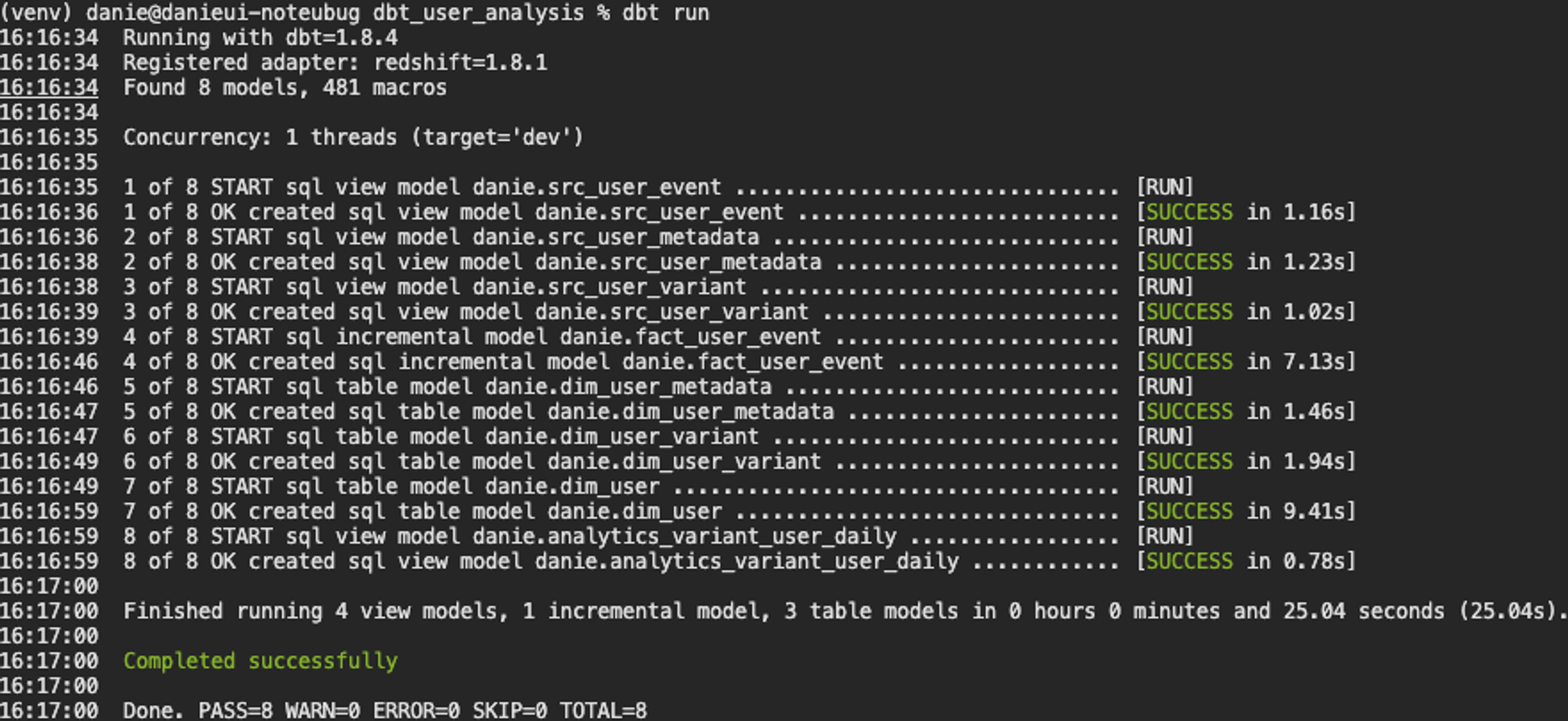
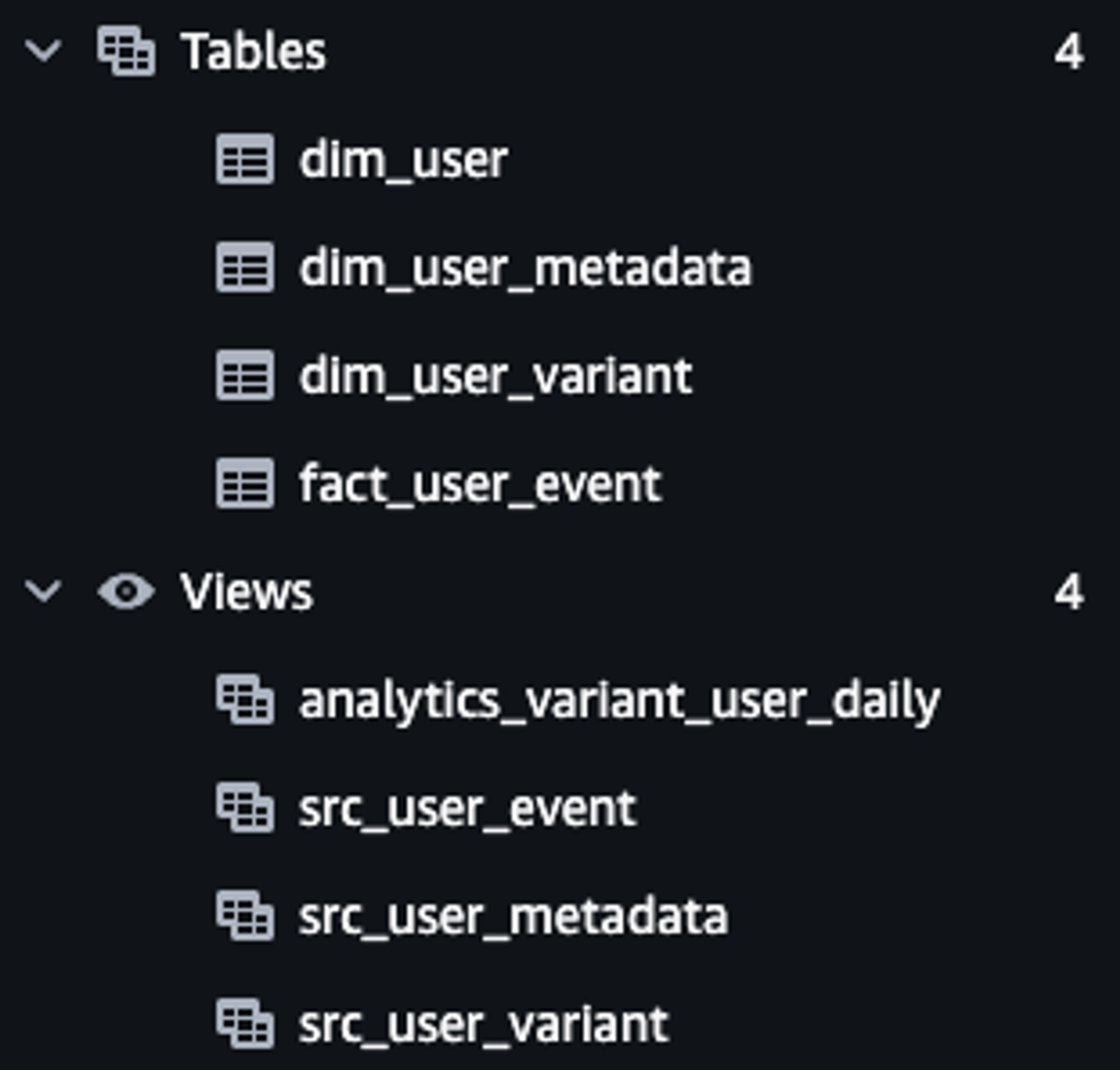
dbt snapshots
dimension 테이블은 성격에 따라 데이터 변경이 자주 생길 수 있으므로 히스토리를 유지하는 것이 중요합니다.
dbt에서 snapshot은 테이블의 변화를 계속적으로 기록함으로써 과거 어느 시점이건 다시 돌아가서 테이블의 내용을 볼 수 있는 기능을 이야기 합니다. 이를 통해, 테이블에 문제가 있을경우 과거데이터로 rollback이 가능하고, 다양한 데이터 관련 문제에 대한 효율적인 디버깅 과정이 가능하게 합니다.
스냅샷을 사용하면 글의 서두에서 언급했던 SCD Type 2 와 같은 특성에 대해 히스토리를 유지하며 데이터 품질을 보장할 수 있습니다.
기존 Dimension 테이블에서 특정 entity에 대한 데이터가 변경되는 경우 새로운 Dimension 테이블을 생성하여 히스토리를 유지하는데, 구체적인 과정은 아래와 같습니다.
기본 구조는 PK를 기준으로 변경시간이 현재 DW에 있는 시간보다 미래인 경우를 변경 감지 기준으로 삼고, updated_at을 기준으로 새로운 데이터가 업데이트되면 히스토리 테이블에 append하게 됩니다.
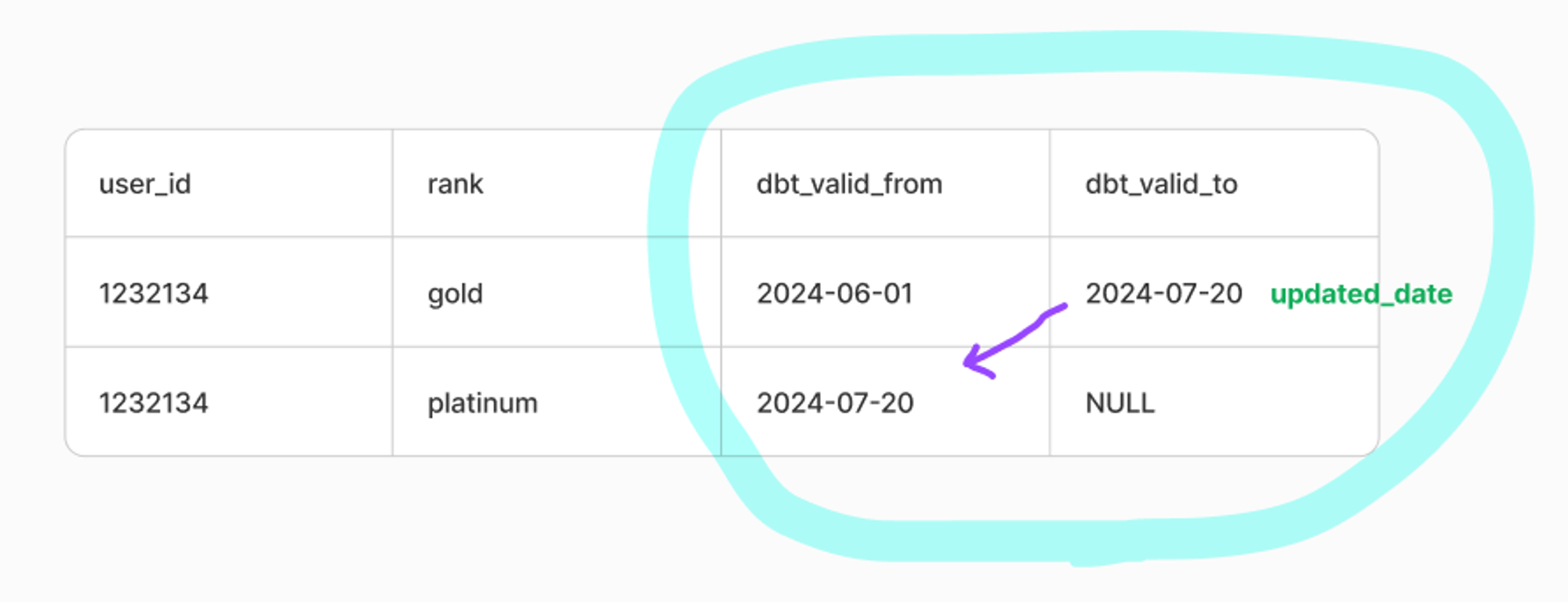
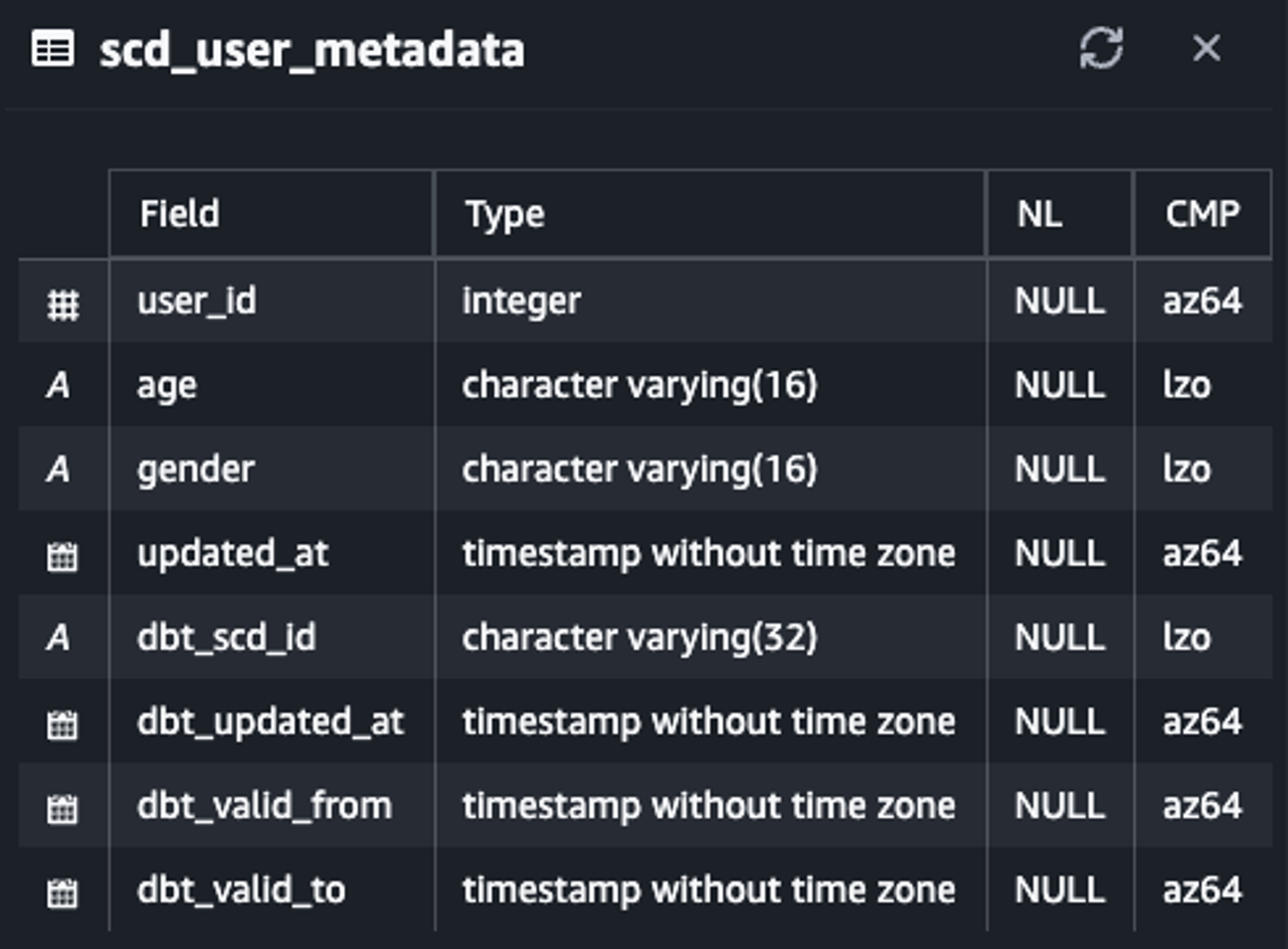
snapshots 디렉토리에 아래와 같은 scd_user_metadata.sql을 작성하고, dbt snapshot 명령어를 실행하면 히스토리 테이블이 생성된 것을 확인할 수 있습니다.
scd_user_metadata.sql
{% snapshot scd_user_metadata %}
{{
config(
target_schema='danie',
unique_key='user_id',
strategy='timestamp',
updated_at='updated_at',
invalidate_hard_deletes=True
)
}}
SELECT * FROM raw_data.user_metadata
{% endsnapshot %}dbt snapshot
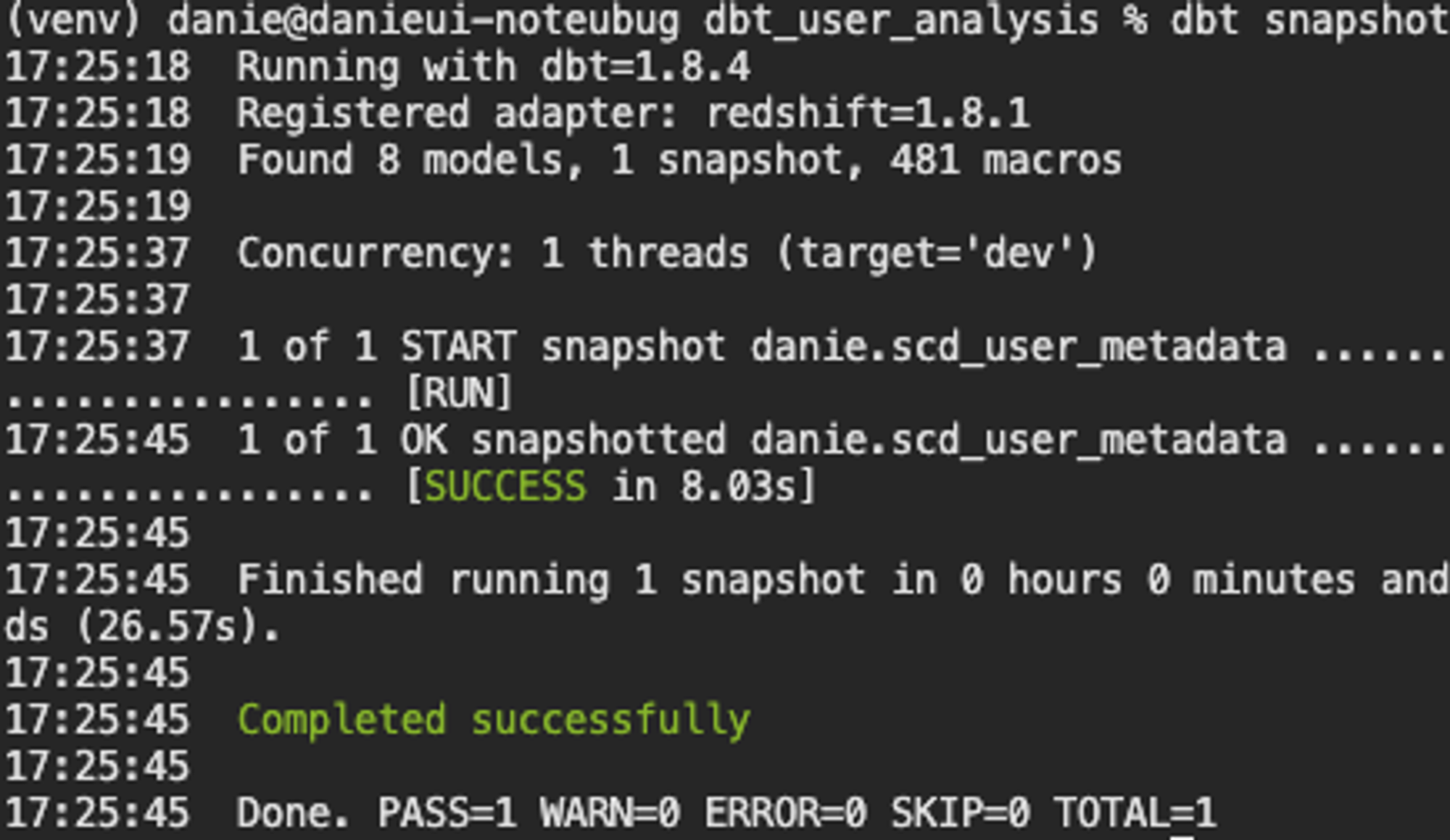
Redshift
dbt tests
여기서 말하는 테스트는 일반적으로 소프트웨어에서 말하는 테스트가 아닌 일종의 데이터 품질을 테스트하는 방법을 뜻합니다.
dbt test의 종류를 나누자면, 아래와 같이 2가지로 나눌 수 있다.
Generics Test: 내장 테스트
Generics test는 Airflow operator처럼 꺼내쓸 수 있는 일종의 dbt 내장 테스트인데, unique, not_null, accepted_values, relationships 등의 테스트를 지원합니다.
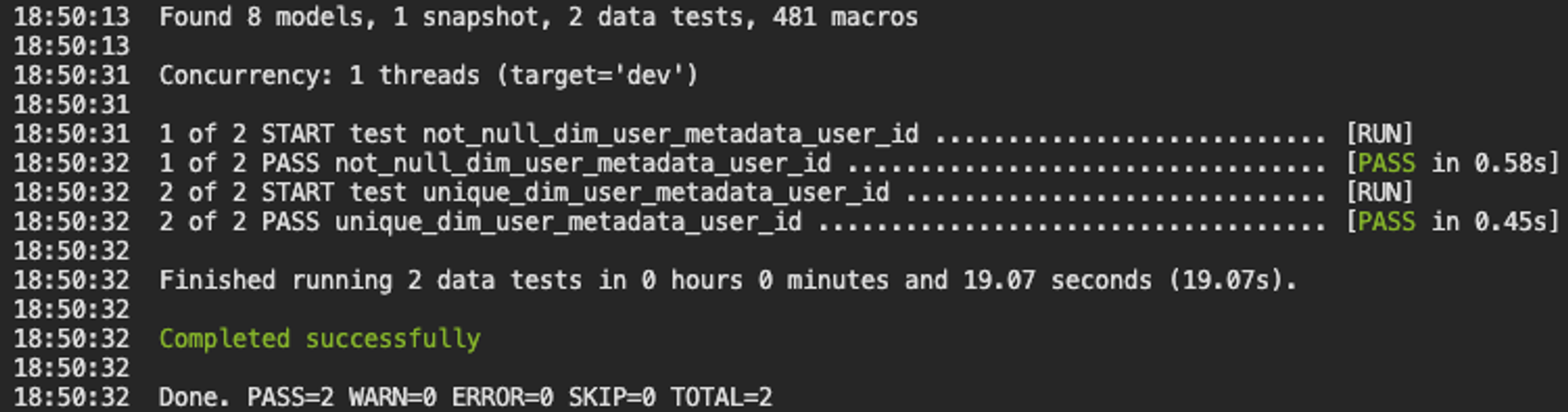
models 디렉토리에 yaml 형태로 테스트 파일을 생성하면 되는데, 저는 아래와 같이 구성하였습니다.
schema.yml
version: 2
models:
- name: dim_user_metadata
columns:
- name: user_id
tests:
- unique - not_null이를 테스트로 활용하기 위해서는 dbt test 명령어를 실행하여 아래와 같은 결과를 확인할 수 있습니다.
Singular Test: 커스텀 테스트
기본적으로 SELECT로 간단하게 실행할 수 있고, 결과가 리턴되면 “실패”로 간주되는 테스트입니다.
tests 디렉토리에 생성하고, 있으면 안될 것들이 있는지 확인하는 정도로 활용합니다.
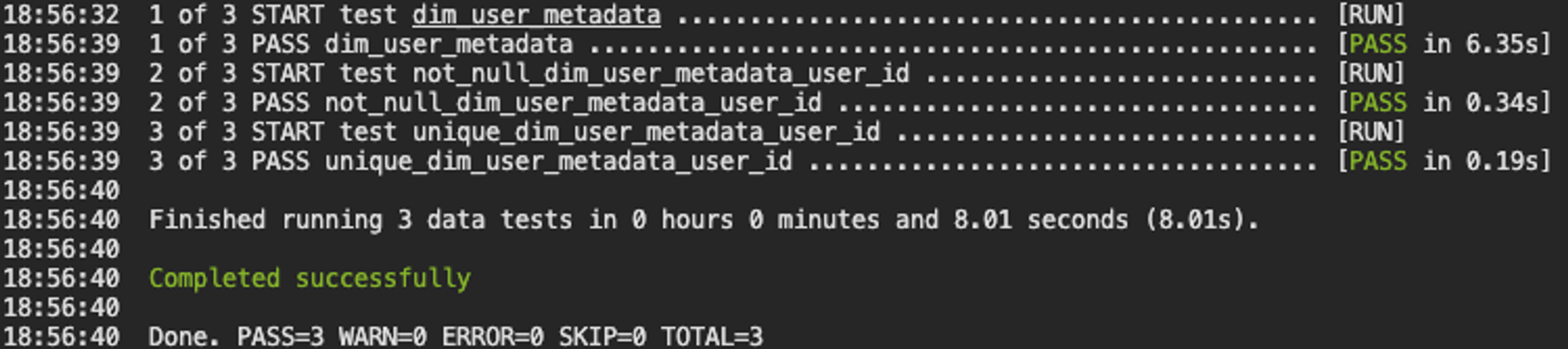
예를들어, Primary Key Uniqueness 테스트 (물론, generic test로 쉽게 검증 가능하지만 ^^)를 진행한다고 하면, tests 디렉토리에 아래와 같이 dim_user_metadata.sql파일을 작성하면 됩니다.
dim_user_metadata.sql
SELECT *
FROM (
SELECT
user_id,
COUNT(1) cnt
FROM
danie.dim_user_metadata
GROUP BY 1
ORDER BY 2 DESC
LIMIT 1
)
WHERE cnt > 1이제 위의 generic test에서 진행한 것과 동일하게 dbt test 명령어를 수행하면 되지만, 이렇게 되면 방금 진행했던 test들도 포함되어 실행되니, 아래처럼 특정 테이블을 지정하면 관련 테이블들에 대한 검증만 진행할 수 있습니다.
dbt test --select dim_user_metadata
본 글을 작성하며 개발한 사항은 아래 github public repo에 업로드하였으니 참고바랍니다 :)
참고문헌
- 견고한 데이터 엔지니어링 (written by Joe Reis & Matt Housley)
- dbt Developer Hub
- RDBMS 데이터 적재 시 데이터 정합성 체크
