추천 시스템 Recommender System
졸업 프로젝트에서 레트로 콘텐츠 추천을 통해 2030세대의 지친 삶을 위로해주는 추억 회상 힐링 앱 'Neverland'를 기획했다. 멘토링을 통해 우리가 하고자 하는 사용자 맞춤 콘텐츠 추천이 협업 필터링(Collaborative Filtering)으로 가능하다는 것을 알게 되었다.
예를 들어, 내가 A 영화를 재미있게 봤다면, A 영화를 본 다른 사람들이 재밌다고 한 B 영화를 나에게 추천해준다는 것이다. 즉, 다른 사람들과의 교집합을 바탕으로 다른 합집합을 보여준다는 것이다.
협업 필터링이 어떤 개념인지 알게 되었지만, 여전히 많은 부분에서 해당 알고리즘에 대한 공부가 필요하다고 느꼈다. 따라서 추천 알고리즘을 주제로 포스팅 해보려 한다.
목차
추천 시스템
- 추천 시스템 정의
- 유사도
- 유사도 종류
- 추천 시스템의 종류와 장단점
추천 알고리즘 구현
- 콘텐츠 기반 필터링 Content-based Filtering
- 사용자 기반 협업 필터링 User-based Collaborative Filtering
References
추천 시스템
다들 한 번쯤은 OTT나 SNS에서 스스로 검색하진 않았지만, 내가 봤던 콘텐츠와 비슷한 류의 콘텐츠들이 피드에 자동으로 올라와 신기했던 경험이 있을 것이다. 이는 추천 시스템에 의한 것이다. 그렇다면 추천 시스템이란 무엇일까?
추천 시스템이란?
- 사용자의 정보 데이터를 분석하여 개인의 취향에 맞는 아이템을 추천하는 알고리즘
- 학습 데이터를 통해 유저의 선호도를 정확하게 예측하는 Prediction version of Problem(Matrix Completion Problem)을 목적으로 함
유사도
추천 시스템을 이해하기 위해 먼저 수학적 개념인 유사도에 대해 알아보자. 추천 시스템에서 유사도는 다음과 같은 방식으로 적용된다.
- 영상, 이미지, 텍스트 등 다양한 형태의 아이템 정보 데이터를 벡터화한 후, 아이템 벡터간의 유사도를 측정함
- 측정된 유사도를 바탕으로 고객이 선호하는 아이템과 비교하여 유사도가 높은 아이템을 추천함
유사도 종류
추천 시스템에서 주로 사용되는 유사도는 다음의 4가지로 분류할 수 있다.
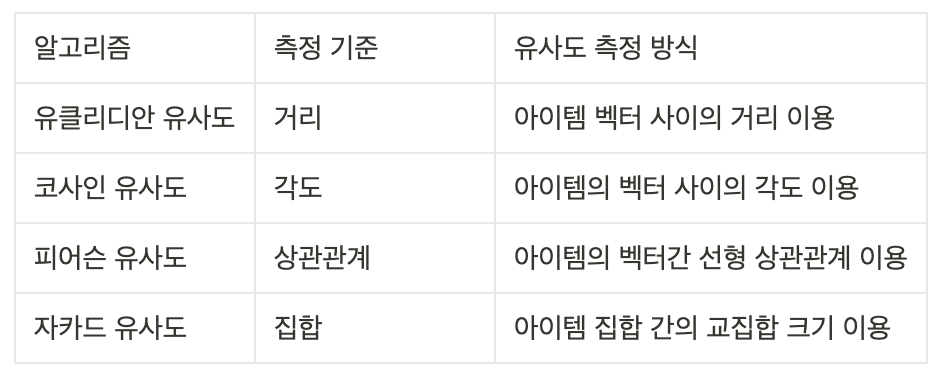
(1) 유클리디안 유사도
- n차원에서 두 점 사이의 최단 거리를 이용하여 서로가 얼마나 유사한지 산정함
- 값의 범위가 지정되지 않음, 거리가 가까울수록 유사함
- 스케일 차이가 크지 않을 때 주로 사용
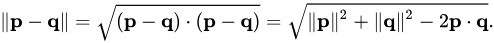
(2) 코사인 유사도
- 벡터간의 코사인 각도를 이용하여 서로가 얼마나 유사한지 산정
- 값이 -1~1, 1에 가까울수록 유사함
- 스케일 차이가 클 때 주로 사용
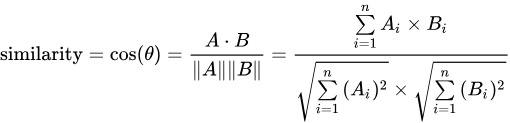
(3) 피어슨 유사도
- 두 벡터 간의 선형 상관 관계를 측정
- 값이 -1~1, 1에 가까울수록 유사함
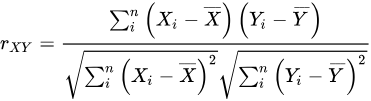
(4) 자카드 유사도
- (교집합)/(합집합)
- 공식이 매우 간단하여 속도 보장
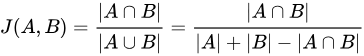
추천 시스템의 종류
📌 콘텐츠 기반 필터링(Content-based Filtering)
- 콘텐츠 자체의 특성과 사용자의 이전 행동 기록을 기반으로 사용자에게 추천함
- 예를 들어, 사용자가 영화 '캡틴 마블'을 재밌게 보았다면 '캡틴 마블'에 대한 분석을 바탕으로 성격이 유사한 영화 '블랙 위도우'를 추천함
👍🏻 장점
- 개인화된 추천: 사용자의 개별적인 취향을 반영 가능함
- 새로운 아이템 대응: 아이템 자체의 특성을 기반으로 하기 때문에 새로운 아이템에도 상대적으로 잘 대응 가능함
- 콜드 스타트에 강함: 사용자의 이력이 없는 초기 상태에도 추천 가능함
👎🏻 단점
- 제한된 다양성: 각 콘텐츠에서 얻을 수 있는 정보가 달라 다양한 형식의 항목 추천이 어려움
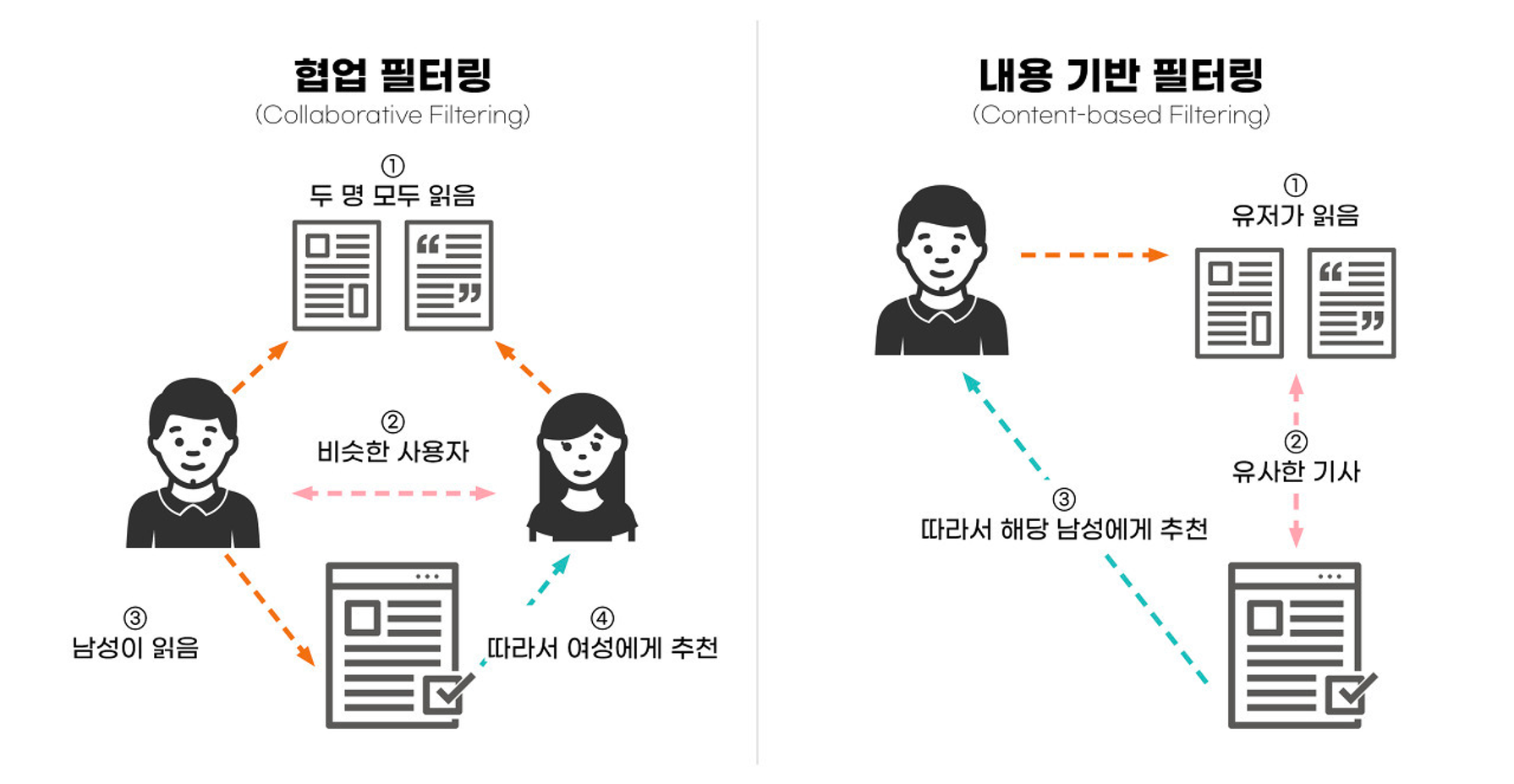
📌 협업 필터링(Collaborative Filtering)
- 어떤 아이템에 대해서 비슷한 취향을 가진 사람들이 다른 아이템에 대해서도 비슷한 취향을 가지고 있을 것이라고 가정하고 추천을 하는 알고리즘
- 추천의 대상이 되는 사람과 취향이 비슷한 사람들, 즉 neighbor을 찾아 이 사람들이 공통적으로 좋아하는 제품 또는 서비스를 추천 대상인에게 추천하는 것
👍🏻 장점
- 알고리즘의 결과가 직관적
- domain knowledge free: 항목의 구체적인 내용 분석이 필요하지 않음
👎🏻 단점
- 콜드 스타트: 신규 사용자에 대해서 정보 데이터가 없어 추천 어려움
- 롱테일: 사용자들이 소수의 인기 있는 항목에만 관심을 보여서 관심이 저조한 항목은 추천되지 못함 → 비대칭적 쏠림 현상
- 계산 효율의 저하: 사용자들의 수가 많아 데이터가 많이 쌓이게 되면, 정확도는 증가하지만 시간이 오래 걸려 효율성은 하락함
협업 필터링은 접근 방식에 따라 다시 기억 기반과 모델 기반으로 나뉜다.
기억 기반(Memory based)
- Matrix를 이용하는 추천시스템 중 사용자의 평점 혹은 사용여부를 바탕으로 구매 패턴을 파악해 그 메모리를 바탕으로 추천을 진행
- 관점에 따라 사용자 기반 협업 필터링과 아이템 기반 협업 필터링으로 구분됨
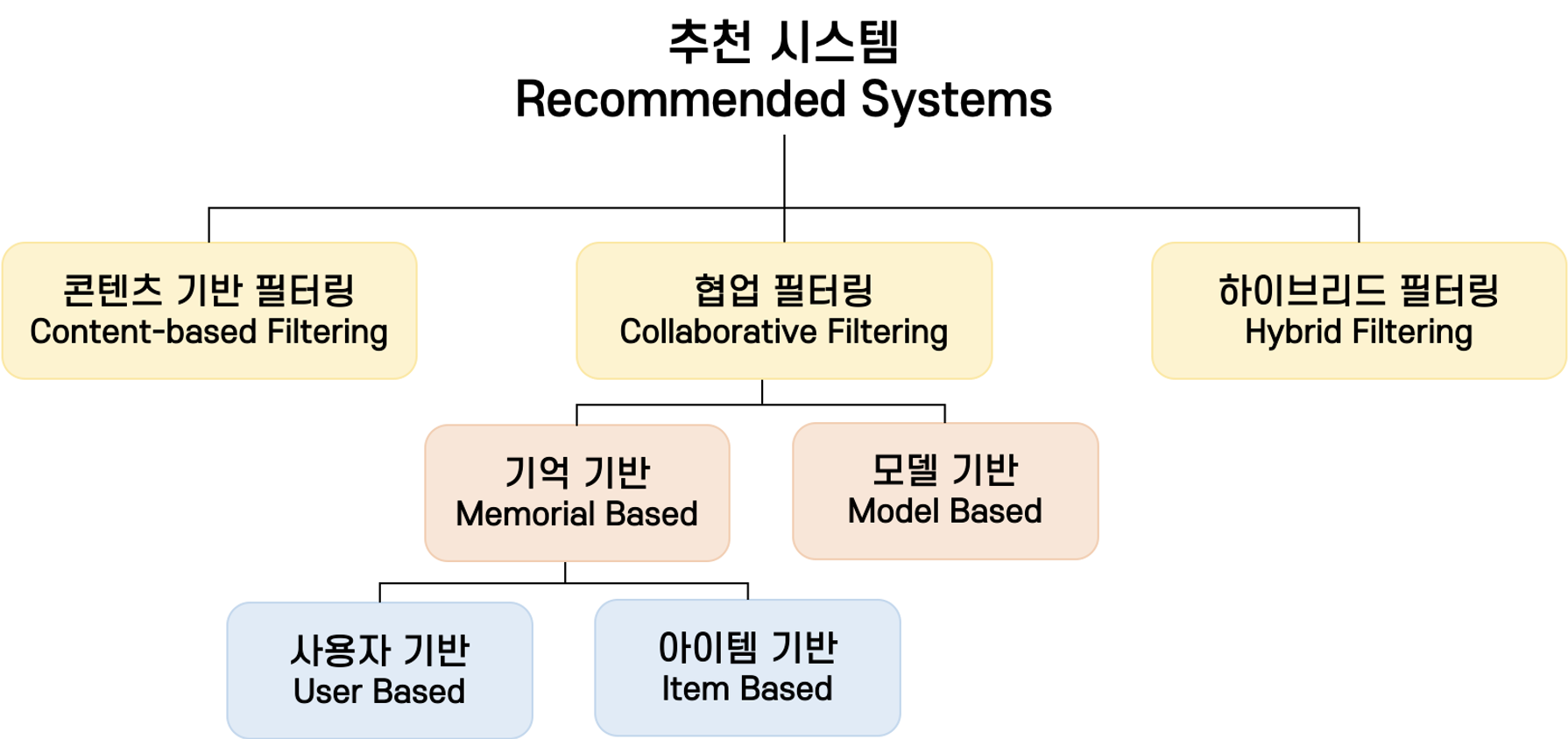
사용자 기반 협업 필터링(User-based collaborative filtering)
: 나와 성향이 비슷한 사람들이 사용한 아이템을 나에게 추천해주는 방식
 {: width="50"}
{: width="50"}
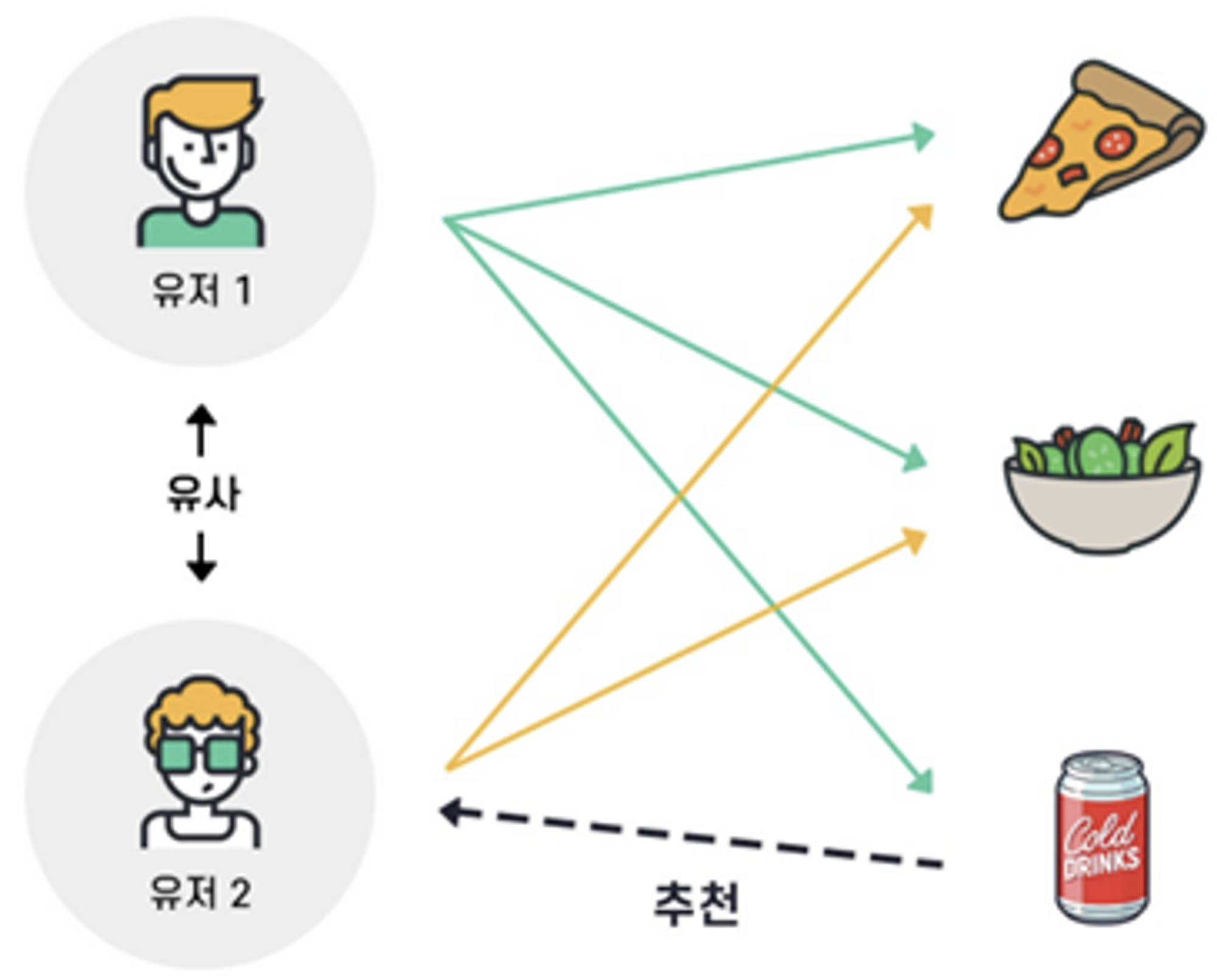
아이템 기반 협업 필터링(Item-based collaborative filtering)
: 내가 구매하려는 물품과 함께 많이 구매된 아이템을 나에게 추천해주는 방식
모델 기반(Model based)
: 머신러닝이나 데이터 마이닝 방법에서 예측 모델의 context를 기반한 방법이다. 모델이 파라미터화 되어 있다면, 이 모델의 파라미터는 context 내에서 학습된다.
정리하자면!
📌 하이브리드 필터링 (Hybrid Filtering)
- 2가지 이상 다양한 종류의 추천 시스템 알고리즘을 조합하는 방법
- 다양한 알고리즘들의 단점은 보완하고 장점은 결합함
추천 알고리즘 구현
우리 팀이 기획한 앱은 영화, 드라마, 애니메이션, 음악 등 과거를 회상할 수 있는 다양한 콘텐츠들이 포함된다. 구글 코랩 환경에서 🎬 영화 데이터셋을 활용해 콘텐츠 기반 필터링, 사용자 기반 협업 필터링을 구현해보자.
콘텐츠 기반 필터링 Content-based Filtering
영화의 genres 속성을 이용하여 콘텐츠 기반 필터링을 수행해보자.
데이터셋
IMDB의 주요 5000개 영화에 대한 메타 정보를 새롭게 가공해 Kaggle에서 제공한 TMDB movie 데이터를 이용한다. 데이터셋은 다음의 링크를 통해 다운받을 수 있다.
https://www.kaggle.com/datasets/tmdb/tmdb-movie-metadata
라이브러리 및 데이터 로드
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
movies_df = pd.read_csv('/tmdb_5000_movies.csv')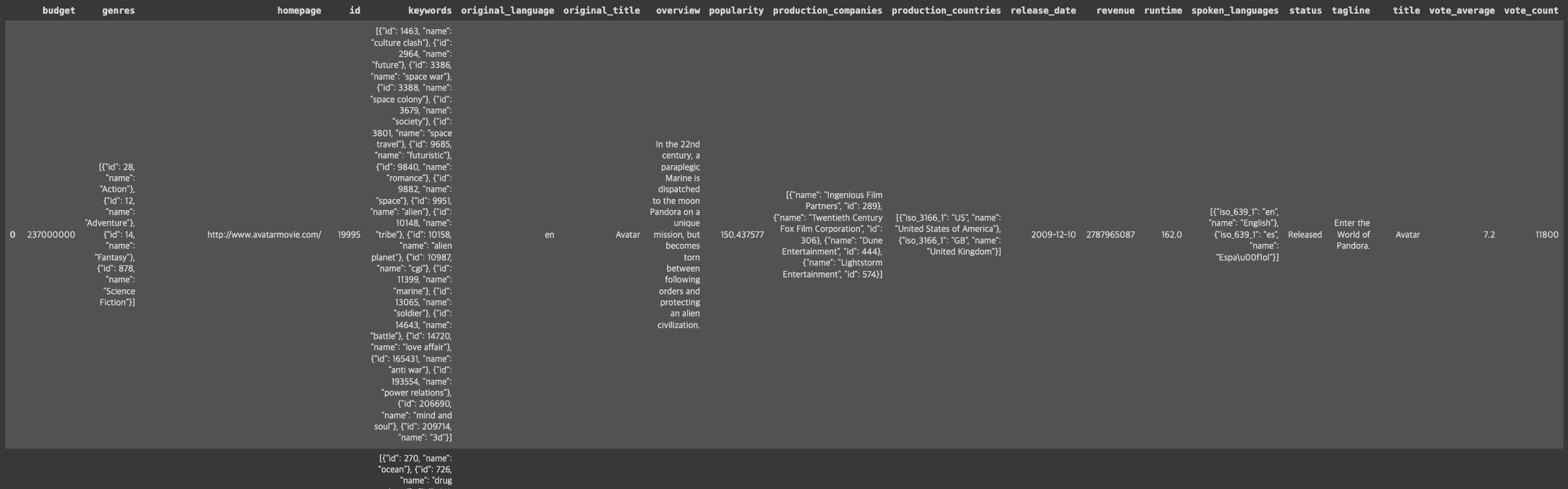
케이스 수: 4803
칼럼:
budget, genres, homepage, id, keywords, original_language, original_title, overview, popularity production_companies, production_countries, release_date, revenue, runtime, spoken_languages, status, tagline, title, vote_average, vote_count
→ 총 20개
데이터 전처리
# 중요한 칼럼만 선택
selected_columns = ['id', 'title', 'genres', 'keywords']
movies_df = movies_df[selected_columns]
# 결측치 처리
movies_df = movies_df.dropna()
genres 와 keywords 칼럼만 선택하여 데이터를 간결하게 유지하고 계산 비용을 줄인다.
genres 칼럼은 TF-IDF 변환을 위한 텍스트 데이터로 사용되므로, 결측치를 빈 문자열('')로 대체하여 문제 없이 변환이 가능하도록 한다.
TF-IDF 변환
# TF-IDF 변환을 위한 벡터화 객체 생성
tfidf_vectorizer = TfidfVectorizer(stop_words='english', lowercase=True)
# 'genres'와 'keywords' 칼럼을 합친 새로운 칼럼 생성
movies_df['content'] = movies_df['genres'] + ' ' + movies_df['keywords']
# TF-IDF 행렬 생성
tfidf_matrix = tfidf_vectorizer.fit_transform(movies_df['content'])movies_df를 출력해보면 *런타임 연결 끊어져서 주피터 이용 *

두 개의 칼럼(genres , keywords)이 content 칼럼으로 합쳐진 것을 볼 수 있다.
각 영화를 나타내는 텍스트 데이터를 TF-IDF 행렬로 표현한다. 이때 TF-IDF 변환은 각 영화의 장르가 얼마나 빈번하게 나타나는지를 고려하여 해당 장르에 중요도를 부여하기 위함이다.
유사도 측정
# 코사인 유사도 계산
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)각 영화의 장르를 벡터 형태로 표현하면, 이 벡터들 간의 코사인 유사도를 계산하여 영화 간의 유사성을 판단할 수 있다. 각 영화의 특징을 잘 반영하고, 유사한 장르를 가진 영화들끼리 묶을 수 있게 된다.
콘텐츠 기반 필터링 함수 정의
# 콘텐츠 기반 필터링
def content_based_filtering(title, cosine_sim=cosine_sim):
# 제목에 해당하는 인덱스 찾기
idx = movies_df[movies_df['title'] == title].index[0]
# 해당 영화에 대한 유사도 측정
sim_scores = list(enumerate(cosine_sim[idx]))
# 유사도에 따라 정렬
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# 상위 10개 영화 선택
sim_scores = sim_scores[1:11]
# 선택된 영화의 인덱스
movie_indices = [i[0] for i in sim_scores]
# 선택된 영화의 제목으로 반환
return movies_df['title'].iloc[movie_indices]측정된 유사도를 기준으로 내림차순 정렬하여 유사도가 높은 상위 10편의 영화를 선택한다. 이때 자기 자신(테스트하려는 영화)은 제외한다. 선택된 영화들의 인덱스를 활용하여 해당 영화들의 제목을 리턴하는 콘텐츠 기반 필터링 함수가 완성되었다.
테스트
# 예시
result = content_based_recommendation('Avatar')
print(result)영화 '아바타'를 이용하여 알고리즘을 시험해보자.

'아바타'와 비슷한 10개의 영화가 잘 추천된 것을 확인할 수 있다.
사용자 기반 협업 필터링 User-based Filtering
n번 사용자에 대해 영화 추천을 하는 사용자 기반 협업 필터링을 수행하보자.
데이터셋
추천 시스템 연구 분야에서 공식적으로 성능 평가 등을 측정하는데 많이 사용되는 MovieLens 데이터를 이용한다. 데이터셋은 다음의 링크를 통해 다운받을 수 있다.
https://grouplens.org/datasets/movielens/
라이브러리 및 데이터 로드
import pandas as pd
import numpy as np
movies_df = pd.read_csv('/content/movies.csv')
ratings_df = pd.read_csv('/content/ratings.csv')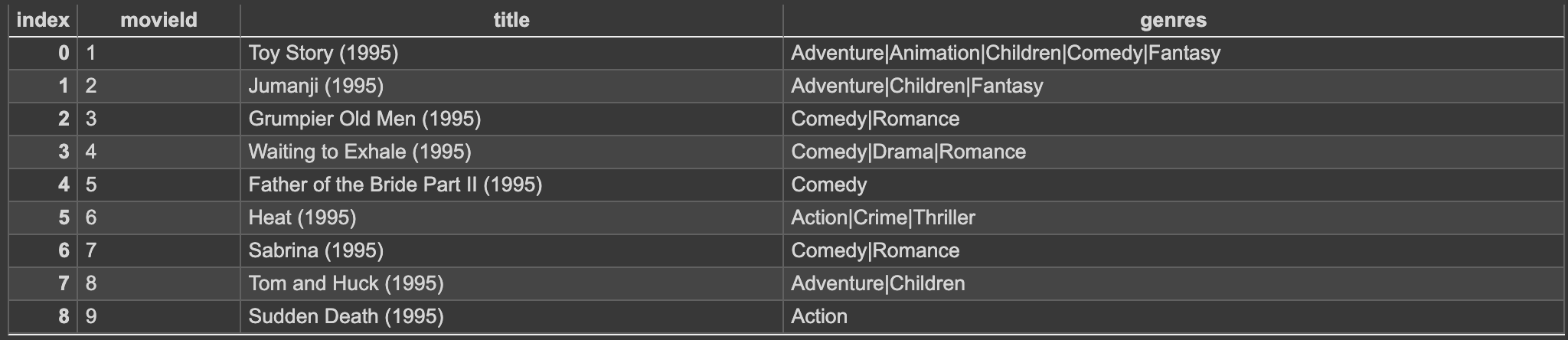
movies.csv 케이스 수: 62424
ratings.csv 케이스 수: 25000096, user 수: 162541
데이터 전처리
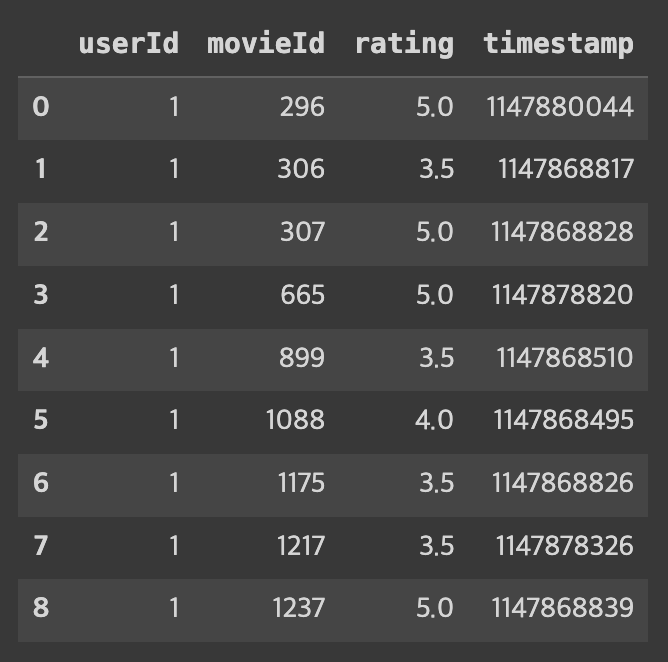
ratings_dict = {}
for index, row in ratings_df.iterrows():
user_id = str(row['userId'])
movie_id = str(row['movieId'])
rating = row['rating']
if user_id not in ratings_dict:
ratings_dict[user_id] = {}
ratings_dict[user_id][movie_id] = rating
사용자별로 영화와 그에 대한 평점을 딕셔너리 형태로 저장하면 이와 같은 결과를 얻는다. 사용자 '1'에 대해 '296'번 영화의 평점은 5.0, '306'번 영화의 평점은 3.5이다.
딕셔너리 형태로 저장하면 사용자별로 아이템에 대한 평가 데이터를 쉽게 조회할 수 있다. 또한 sparse한 형태를 가지기 때문에, 딕셔너리를 사용하면 0이 아닌 값이 있는 부분만을 저장하므로 메모리를 효율적으로 사용할 수 있다.
사용자 기반 협업 필터링 함수 정의
from sklearn.metrics.pairwise import cosine_similarity
def user_based_collaborative_filtering(ratings_dict, target_user, k=5):
# 1. 특정 사용자와 다른 사용자 간의 유사도 계산
similarities = {}
target_user_ratings = np.array(list(ratings_dict[target_user].values())).reshape(1, -1)
for user in ratings_dict:
if user == target_user:
continue
other_user_ratings = np.array(list(ratings_dict[user].values())).reshape(1, -1)
similarity = cosine_similarity(target_user_ratings, other_user_ratings)[0, 0]
similarities[user] = similarity
# 유사도를 기준으로 내림차순 정렬
sorted_similarities = sorted(similarities.items(), key=lambda x: x[1], reverse=True)
# 상위 k명의 이웃 선택
top_k_neighbors = sorted_similarities[:k]
# 평가하지 않은 영화 추출
not_rated_movies = set(movies_df['movieId']) - set(ratings_dict[target_user].keys())
# 2. 추천 영화 평점 예측
movie_recommendations = {}
for movie_id in not_rated_movies:
weighted_sum = 0
similarity_sum = 0
for neighbor, similarity in top_k_neighbors:
if movie_id in ratings_dict[neighbor]:
weighted_sum += ratings_dict[neighbor][movie_id] * similarity
similarity_sum += similarity
predicted_rating = weighted_sum / similarity_sum
movie_recommendations[movie_id] = predicted_rating
# 예측 평점을 기준으로 상위 영화 선택
top_movies = sorted(movie_recommendations.items(), key=lambda x: x[1], reverse=True)[:10]
return top_movies-
특정 사용자와 다른 사용자 간의 유사도 계산
scikit-learn의 cosine_similarity 함수를 사용하여 두 벡터(사용자 평점 벡터) 간의 코사인 유사도 계산한다. -
추천 영화 평점 예측
유사도가 높은 상위 k명(미리 정해둔 k=5)의 이웃을 선택하여 해당 사용자가 평가하지 않은 영화에 대한 평점을 예측한다.
현재 이웃 사용자가 현재 예측하려는 영화에 대해 평점을 남겼는지 확인한다. 만약 해당 영화에 대한 평가가 있다면, 가중 평균과 유사도 합을 업데이트한다.
🚨 여기서 잠깐!
유사한 사용자들이 평가한 영화 중에 현재 예측하려는 영화를 아무도 평가하지 않은 경우에는 어떡하지?
이 경우에 similarity_sum 이 0이지만 predicted_rating 이 계산될 수 있다. 즉, ZeroDivisionError가 발생한다. 따라서 if similarity_sum > 0 조건을 추가하여, 적어도 한 명 이상의 유사한 사용자가 평가한 경우에만 가중 평균을 계산하여 예측 평점을 저장하게 한다.
사용자 기반 협업 필터링
다음은 수정된 코드를 포함한 사용자 기반 협업 필터링 전체 코드이다.
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
# 데이터 로드
movies_df = pd.read_csv('/content/movies.csv')
ratings_df = pd.read_csv('/content/ratings.csv')
# 사용자 x 아이템 평가 데이터 생성
ratings_dict = {}
for index, row in ratings_df.iterrows():
user_id = str(row['userId'])
movie_id = str(row['movieId'])
rating = row['rating']
if user_id not in ratings_dict:
ratings_dict[user_id] = {}
ratings_dict[user_id][movie_id] = rating
# 사용자 기반 협업 필터링 함수
def user_based_collaborative_filtering(ratings_dict, target_user, k=5):
# 특정 사용자와 다른 사용자 간의 유사도 계산
similarities = {}
target_user_ratings = np.array(list(ratings_dict[target_user].values())).reshape(1, -1)
for user in ratings_dict:
if user == target_user:
continue
other_user_ratings = np.array(list(ratings_dict[user].values())).reshape(1, -1)
similarity = cosine_similarity(target_user_ratings, other_user_ratings)[0, 0]
similarities[user] = similarity
# 유사도를 기준으로 내림차순 정렬
sorted_similarities = sorted(similarities.items(), key=lambda x: x[1], reverse=True)
# 상위 k명의 이웃 선택
top_k_neighbors = sorted_similarities[:k]
# 평가하지 않은 영화 추출
not_rated_movies = set(movies_df['movieId']) - set(ratings_dict[target_user].keys())
# 추천 영화 평점 예측
movie_recommendations = {}
for movie_id in not_rated_movies:
weighted_sum = 0
similarity_sum = 0
for neighbor, similarity in top_k_neighbors:
if movie_id in ratings_dict[neighbor]:
weighted_sum += ratings_dict[neighbor][movie_id] * similarity
similarity_sum += similarity
if similarity_sum > 0:
predicted_rating = weighted_sum / similarity_sum
movie_recommendations[movie_id] = predicted_rating
# 예측 평점을 기준으로 상위 영화 선택
top_movies = sorted(movie_recommendations.items(), key=lambda x: x[1], reverse=True)[:10]
return top_movies테스트
# 예시
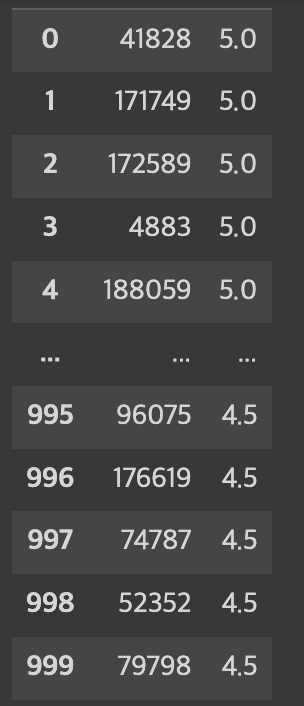
target_user_id = '1'
recommendations = user_based_collaborative_filtering(ratings_dict, target_user_id)
result = pd.DataFrame(recommendations, columns=['Movie ID', 'Predicted Rating'])
print(result)1번 사용자에 대한 추천을 한다고 가정하면, 다음과 같은 결과를 얻을 수 있다. 0번 컬럼은 movieId를, 1번 칼럼은 추천된 영화에 대한 1번 사용자의 예상 평점이다.
이번 포스팅에서는 추천 시스템을 다뤘다. 특히 콘텐츠 기반 필터링과 사용자 기반 협업 필터링은 파이썬으로 구현 및 영화 데이터셋으로 실험해보았다.
🤔 What's next ?
우리 프로젝트에서는 Spring 상에서 추천 알고리즘을 구현할 예정이다. 오늘 연습했던 추천 알고리즘을 Spring 환경에서 프로젝트 방향에 맞춰 재구성해볼 것이다.
References
협업 필터링
https://deepdaiv.oopy.io/articles/1
사용자 기반 협업 필터링 구현
https://data-science-hi.tistory.com/73
콘텐츠 기반 필터링 구현
https://nicola-ml.tistory.com/67
