
GIL에 접근하기 전 프로세스와 스레드 개념에 대해 다시 복습했다.
프로세스와 스레드 이해하기
주소값
컴퓨터 언어가 변수를 선언하면 RAM(Random Access Memory, 임의의 영역에 접근하여 읽고 쓰기가 가능한 주기억장치)에 저장이 된다. 이 램은 일시적인 장치이기 때문에 전원이 내려가는 순간 데이터는 다 사라진다.
그럼에도 불구하고 램을 쓰는 이유는 램이 빠르기 때문이다.
만일 C언어의 경우라면
a = 1
b = 1
c = 1라고 선언을 할 경우, a, b, c의 주소값은 모두 다르다.
그러나 파이썬은 모든 것을 객체로 선언한다.
즉, 위의 경우에서 int 1도 객체로 고유 주소값을 가진다.
따라서 파이썬에서는
a = 1
b = 1
c = 1 라고 선언을 할 경우, a, b, c는 모두 같은 주소값을 바라보게 된다.
여기서 만약
a += 1로 a가 2가 된다면 int 2 객체가 가진 고유 주소값으로 a의 주소값이 바뀌게 된다.
a = 1
b = 1
c = 1
print(id(1)) # 140340726208816
print(id(a)) # 140431160645936
print(id(b)) # 140431160645936
print(id(c)) # 140431160645936
a += 1
b = 2
print(a) # 2
print(b) # 2
print(id(2)) # 140480731027792
print(id(a)) # 140480731027792
print(id(b)) # 140480731027792Race Condition (feat. threading)
쓰레드는 같은 작업 공간(==프로세스)을 공유한다.
같은 변수를 가진 2개의 작업이 생기면 '같은 값은 같은 주소값을 본다'는 파이썬의 성질로 인해 혼란이 생긴다.
아래의 코드로 혼란을 경험해보았다.
import threading
x = 0 # globally shared value
def abraham():
global x
for i in range(100000000):
x += 1
def bobby():
global x
for i in range(100000000):
x -= 1
t1 = threading.Thread(target=abraham)
t2 = threading.Thread(target=bobby)
t1.start()
t2.start()
t1.join()
t2.join()
print(x)
# 988113(code reference:
https://dgkim5360.tistory.com/entry/understanding-the-global-interpreter-lock-of-cpython [개발새발로그])
함수 abraham과 함수 bobby는 같은 range를 가지며 전역변수로 선언된 x를 +1, -1을 하는 함수이다. 작성한대로 함수 abraham을 실행하는 스레드 객체 t1이 x+1하고 바로 다시 함수 bobby를 실행하는 스레드 객체 t2가 x-1한다면 이때 마지막으로 x를 프린트했을 때 내가 기대하는 x의 값은 0이 되어야 한다.
하지만 실제 x는 988113이 나온다. 이렇듯 여러 thread가 공유된 데이터(여기서는 x)를 변경함으로서 발생하는 문제를 race condition이라고 부른다. 이것이 위에서 말한 혼란의 상황이다. 그리고 이 혼란의 결과는 memory leak(메모리 유실, 메모리를 제대로 청소하지 않아 ram에 할당된 메모리가 회수되지 않는 상황)이다. 혹은 deadlock(후술)의 상황이 생길 수도 있다.
일반적으로 thread-safe하다는 상황은 이렇게 각각의 thread가 race condition을 발생시키지 않으면서 각자의 일을 잘 수행한다는 뜻이다.
파이썬에서의 스레드는 아래처럼 동작한다. GIL이 언제 어떻게 먹히는지도 보인다.
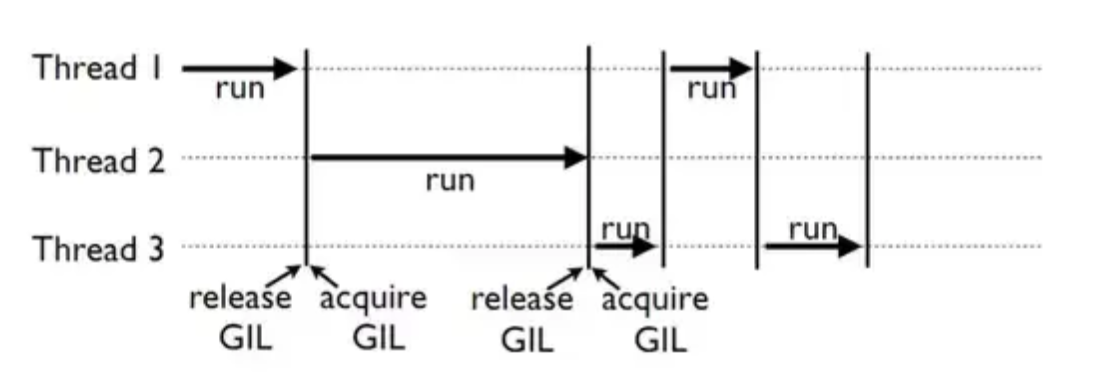
위 그림을 보니 비동기로 멀티스레드가 모두 함께 동시에 작동하면 좋을텐데 그렇지 않아보인다.
그럼에도 불구하고 이렇게 작동하도록 만든 이유는 어디에 있을까?
Garbage Collecting, Reference Counting & GIL
파이썬은 기본적으로 garbage collecting과 reference counting을 이용하여 할당된 메모리를 관리한다. 파이썬의 모든 객체는 해당 객체가 몇 개의 참조 카운팅을 가지고 있는지를 저장하고 있다. 이 참조 카운팅의 값이 0이 되면 Cpython이 알아서 garbage collecting하며 할당되었던 메모리를 회수한다.
Reference Counting
쉬운 설명
a=1,b=1선언.
이때 객체인int 1은 2라는 참조 카운팅(reference counting)을 가지게 됨.
(변수 a, b에서 한번씩 참조하여 두 번에 걸쳐 참조된다는 의미)코드로 확인하기
import sys a = [] b = a print(sys.getrefcount(a)) # 3왜 3이 나올까? 이유는 다음과 같다.
- a 객체를 선언할 때 reference +1 (현재 참조카운팅 1)
- b에 a의 reference를 할당하면서 reference +1 (이제 참조카운팅 2)
sys.getrefcount함수에 argument로 a를 넘기면서 이 함수 내부에서 a의 reference +1 (그리하여 참조카운팅 3)
--> 이 함수가 끝남과 동시에 다시 레퍼런스의 개수는 -1 되어 2인 상황으로 내부적으로 저장되어 있을 것이다.
멀티스레드의 경우에서 여러 스레드가 하나의 객체를 사용한다면
참조카운팅을 관리하기 위해 그 모든 스레드 객체에 대해 Lock이 각각 필요할 것이다.
그러나 이렇게 각각의 스레드에 각각의 mutex를 이용하여 (GIL도 하나의 Mutex임) Lock을 걸어버리면, 성능적으로도 많은 손해를 볼 수 있고 deadlock(순환참조와 같은 상황. 나도 너도 참조하고 있으니 카운팅이 0으로 가지 않아서 결국 가비지 콜렉팅의 대상이 되지 못함)이라는 문제를 일으킬 수도 있다.
이런 비효율을 방지하기 위해 GIL이 나오는 것이다.
GIL by python wiki
In CPython, the global interpreter lock, or GIL, is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecodes at once. This lock is necessary mainly because CPython's memory management is not thread-safe.
결론 : GIL이란
한 스레드는 하나의 바이트코드만을 실행시킬 수 있어야 하기에,
파이썬 코드 실행 시 단 하나의 스레드만이 파이썬 객체에 접근하도록 제한하는 것이며
하나의 스레드에 모든 자원을 허락하고 그 후에는 Lock을 걸어 다른 스레드는 실행할 수 없도록 하여 결국
하나의 lock을 통해 모든 객체들에 대한 참조 카운팅의 동기화 문제를 해결하는 것이다.
https://dgkim5360.tistory.com/entry/understanding-the-global-interpreter-lock-of-cpython [개발새발로그] '왜 Python에는 GIL이 있는가'
그리고 위코드의 훌륭한 동기들 BJ와 TS
