
Thread와 Process
개념 이해 1
스레드와 프로세스의 개념 자체가 생소하여 알고 싶어서 이것저것 구글링으로 돌아보았으나 ... 온갖 전문용어가 난무하는 설명에 지쳐 쓰러져갈 때쯤 위코드의 좋은 동료 BJ는 스레드와 프로세스에 대해 이렇게 설명해주었다.
한정적 CPU를 가진 컴퓨터가 한번에 할 수 있는 일이 5개라고 가정한다. (사실 깊게 들어가면 컴퓨터는 한번에 한 개의 일밖에는 처리하지 못한다고 하지만) 이 경우 당연히 한번에 돌릴 수 있는 프로그램의 개수는 5개가 될 것이다. 그런데 만일, 한글 프로그램으로 문서 작성을하던 중 문서를 두 개 켜야할 일이 생긴다. 그런데 이럴 때마다 한글 프로그램이 프로세스를 하나씩 야금 야금 가져가면 CPU의 한정된 능력(한 번에 5개만 돌림)에 의해 다른 프로그램은 돌릴 수가 없게 된다.
이런 상황에서 생기는(필요한) 개념이 스레드인 것이다. 한글 프로그램이 이미 가져간(할당받은) 프로세스 내에서 해당 프로세스를 잘게 쪼개어 스레드라는 논리 개념을 만든 것. 스레드는 한 프로세스가 사용할 수 있는 레지스터와 스택 등의 자원을 공유해서 사용하게 된다.
+) 210614 추가
이때 한번에 할 수 있는 5개의 일은
5개의 프로세스 혹은 컴퓨터 사양으로 보면 5코어 라고도 말할 수 있다.
Thread와 Process의 기본개념을 파악할 수 있는
정말 명쾌한 설명이었다. 👏🏻👏🏻👏🏻
개념 이해 2
유튜버 얄팍한 코딩사전의 설명은 아래와 같다.
윈도우의 경우 .exe라고 붙어있는 파일을 프로그램이라고 한다. 그리고 이 프로그램이 돌아가고 있는 상태, 컴퓨터가 뭔가를 하고 있는 상태를 프로세스라고 말할 수 있다. 우리가 여러 개의 프로그램을 실행시켜도 이렇게 쾌적한 환경에서 컴퓨터를 사용할 수 있는 것은, OS가 여러 개의 프로세스를 함께 돌리고 있기 때문이다. (윈도우에서의 작업관리자 화면을 보면 몇 개의 프로세스가 현재 돌아가고 있는지 체크할 수 있다.)
여러 개의 프로세스를 돌리는 과정은 동시적, 병렬적 혹은 이 둘의 혼합으로 이루어진다.
동시적(Concurrency) 작업
하나의 프로세스가 가진 작업 A, B, C, D에 대해
A->B->C->D->A->B->C->D 이런 식으로 조금 조금씩 작업을 돌아가며 일부분씩 진행하는 것을 의미한다. 이렇게 작업을 바꾸는 것을 Context Switching이라고 부른다. 이 context switching은 상당히 빨리 진행되기 때문에 결국 인간에게는 이 과정들이 '동시에' 진행되는 것처럼 느껴져서 동시적이라고 표현하는 것. 실제로 파이썬은 전역 인터프리터 락킹(Global Interpreter Lock)때문에 특정 시점에 하나의 파이썬 코드만을 실행하게 된다. 이 때문에 파이썬은 다중 CPU환경에서 동시에 여러 파이썬 코드를 병렬적으로는 실행할 수가 없고 위와 같은 Interleaving방식으로 코드를 분할하여 실행하게 된다.메모리 Interleaving
주기억장치에 접근하는 속도를 빠르게 하는데 사용
인접한 메모리 위치를 서로 다른 메모리 뱅크에 두어 동시에 여러 곳을 접근할 수 있게 하는 것
이는 블록 단위 전송을 가능하게 하기에 캐시나 기억장치와 주변장치 사이의 빠른 데이터 전송을 위한 DMA(Direct Memory Access)에서 많이 사용한다
병렬적(Parallelism) 작업
한 프로세스에 코어 여러 개가 달려, 각각 동시에 작업들을 수행하는 것을 일컫는다.
(듀얼코어, 쿼드코어, 옥타코어 등등 이런 명칭이 붙는 멀티 코어 프로세서가 달린 컴퓨터가 일을 수행하는 방식)
CPU의 속도가 발열 등의 물리적 제약에 의해 예전만큼 빠르게 발전하지 못하자 그 대안으로 코어를 여러 개 달아 작업을 분담할 수 있도록 만든 것이다.
다중 CPU에서 병렬 실행을 위해서는 다중 프로세스를 이용하는 multiprocessing 모듈을 사용해야 한다.

동시적이든 병렬적이든 컴퓨터는 여러 개의 프로세스를 함께 돌릴 수 있다. 이를테면 브라우저를 돌리는 것도 하나의 프로세스에 해당한다.
그런데, 이 브라우저를 돌릴 때에도
1) 게임을 다운 받는 동시에
2) 다른 페이지들을 돌아다닐 수 있어야 하고,
3) 유튜브 영상의 데이터를 받아오면서
4) 받아진 데이터들로 영상을 재생할 수도 있어야 한다.
다시 말해, 한 프로세스 안에도 여러 갈래의 작업들이 동시에 진행될 수 있어야 한다.
이 갈래를 바로 스레드라고 부른다.
근데 이 스레드의 특징은 위에서 언급한대로 하나의 프로세스 자원을 공유한다는 것인데, 여기서 문제가 생길수가 있다. 프로세스 안에서 공유되는 변수에 스레드 두 개가 동시에 손을 댄다고 생각해보자. 이를테면 어떤 버튼을 누를 때마다 숫자가 1씩 올라가는데, 스레드 둘이 이 버튼을 열 번씩 누른다. 그렇다면 상식적으로는 20의 숫자가 올라가 있어야 맞을 것이다. 하지만 실제 결과는 그보다 적은 숫자가 나올 것이다. 왜냐, 두 쓰레드가 동시에 접근한 경우에는 숫자가 1만 올라가기 때문이다.
(다소 순환참조 같지만) 'Race Condition'에 대한 정리글
시간 문제로 발생하는 이런 상황들을 예상하고 방지해야하기 때문에 스레드를 사용하는 프로그래밍은 코드를 짜기도, 디버깅을 하기에도 굉장히 까다로와진다는 것이다.
다행히도 이런 작업들을 더 쉽고 안전하게 할 수 있는 도구들이나 프로그래밍 방식들이 오늘날의 개발자들을 많이 도와주고 있다. (Lock, Mutex, Semaphore 등. 아래에서 Lock은 다룰 예정!)
정리
1) Thread는 프로그램의 실행 흐름이다.
2) 한 프로세스 안에는 여러 개의 스레드가 존재할 수 있다.
즉, 스레드는 프로세스에 종속되므로 프로세스 내에서 스레드가 추가로 만들어질 때 새로운 스레드는 프로세스의 자원(코드와 메모리)을 공유한다.
3) 하나의 프로세스 안에 두 개 이상의 스레드를 만들게 되면, 두 개 이상의 스레드는 동시에 일을하게 된다. (스레드 == 동시성을 위한 개념)결국 스레드는 다음의 역할을 한다.
- 루틴 흐름의 중단 없이 별개의 작업 흐름이 서브 루틴을 실행하여 동시성을 유지
- 프로그램 전체적인 성능의 향상
Thread
스레드 객체의 생성
Thread(name=, target=, args=, kwargs, *, daemon=)
1) name: [optional] 스레드의 이름.
2) target: 스레드에서 실행하게 될 함수.
3) args: [optional] target에 넘겨질 인자로 ⭐️튜플 형식으로 준다.
4) kwargs: [optional] target에 넘겨질 키워드 인자로 딕셔너리 형식으로 준다.
5) daemon: [optional] 데몬 실행 여부. 데몬으로 실행되는 스레드는 프로세스가 종료될 때 즉각 중단된다.
Daemon Thread
- Daemon Thread는 Main Thread가 종료되면 즉시 종료되는 스레드이다.
- Daemon Thread가 아니라면 Main Thread가 종료되어도 종료되지 않으며, 그대로 일을 진행한다.
이런 daemon 여부를 올바르게 설정하지 않으면 내 프로그램이 종료되어도 내가 중간에 만든 thread가 실행될 수도 있으니 주의하여야 한다.
daemon의 default 값은 False이나, Thread 객체 생성 시나 start 메소드 호출 전 daemon=True로 속성을 설정하면 daemon thread가 된다.
스레드 객체의 속성
start(): 스레드를 시작- ⭐️
join(): 해당 스레드에서 실행되는 함수가 종료될때까지 기다린다. Thread.start()는 즉시 리턴하기 때문에, 동작하고 있는 스레드들을 메인 스레드가 적절히 기다려주지 않는다면 프로그램은 중도에 끝나버릴 수도 있다. 프로세스의 종료 시점은 메인 스레드가 종료 지점에 도달했을 때이며 다른 워커 스레드의 실행 여부는 고려되지 않는다. 따라서 이상 종료를 막기 위해서는 메인 스레드가 워커 스레드들을 적절히 기다려야 하는데 이 때 사용되는 것이.join()메소드.timeout=인자를 주어 특정 시간까지만 기다리게도 할 수 있다. 그러나 이 때에는 타임아웃을 초과해도 예외를 일으키지 않고None을 리턴하므로 이 경우is_alive()를 호출하여 스레드가 실행 중인지를 파악할 필요가 있다. is_alive(): 해당 스레드가 동작 중인지 확인ident: 스레드 식별자. 정수값native_id: 스레드 고유 식별자. ident는 종료된 스레드 이후에 새로 만들어진 다른 스레드에 재활용될 수 있다.
Python의 기본은 Single Thread
파이썬은 싱글 스레드에서 순차적으로 작동하는 것이 기본인 인터프리터 언어이다.
따라서, 병렬 처리를 위해서는
1) ⭐️별도의 모듈(
threading.Thread)을 사용하여 thread를 구현하든지
2) 별도의 모듈(multiprocessing)을 사용하여 process를 구현해야 한다.
1) 방법으로 처리할 경우
- 프로세스를 이용하는 것보다는 상대적으로 가볍지만
- GIL(Global Interpreter Lock)으로 인해 계산 처리를 하는 작업은 한 번에 하나의 쓰레드에서만 작동하여 CPU 작업이 적고, I/O 작업이 많은 병렬 처리 프로그램에서 효과를 볼 수 있다.
2) 방법으로 처리할 경우
- 프로세스는 각자가 고유한 메모리 영역을 가지기 때문에 더 많은 메모리를 필요로 하나
- 각각의 프로세스에서 병렬로 CPU 작업이 가능하고
- 이를 이용하면 여러 머신에서 동작하는 분산 처리 프로그래밍도 구현이 가능하다.
Python에서의 MultiThread
파이썬은 하나의 Main Thread에서 시작하여 순차적으로 코드를 실행하나 실행 도중 Input함수와 같은 Blocking Function을 만나면 main thread는 해당 함수가 모두 실행될 때까지 기다리게 된다. Main Thread를 멈추게 되면 다른 함수는 실행할 수가 없게 되는데, 이때는 다른 Thread를 하나 더 만들어, 새로 만든 Thread 속의 함수들이 병렬적으로 Blocking Function과 같은 함수와 함께 실행이 가능하도록 만들 수 있다. 하지만 이럴 때에는 주의해야 할 점들이 몇 가지 있다.
파이썬은 GIL에 의해 한 순간에 하나의 thread만 실행이 되므로, 자원 접근도 하나의 thread만 하게 되는 것이 아닌가 착각을 할 수도 있다. 그러나 Critical Section(thread들이 동시에 접근해서는 안되는 공유 자원에 접근하도록 하는 코드 영역. 스레드에 의해 실행된 하나의 함수가 존재할 시, 이 함수 내부 코드가 다수의 스레드로 인하여 값이 이상하게 변경되는 것을 방지하는 공유 자원 접근 제한 영역)은 코드 영역을 의미하므로 코드를 실행하다가 Context Switching이 되어버릴 경우 자원이 비정상적인 값을 가질 수 있다. 이를 방지하기 위해서 Semaphore와 Mutex라는 방식이 존재한다.
실제 예제
문제 상황
만일 숫자 일억까지 +1을 하는(숫자를 세는) 프로그램이 있다고 해보자. 이 프로그램을 돌리는데 일억은 아무래도 큰 수이니, 프로그램 내 두 개의 스레드를 생성하여 스레드 하나당 5천만개씩 +1를 하도록하여 조금 더 빠른 시간안에 일억까지 카운팅을 하고자 한다고 해보자.
import threading # 스레드 사용 시 threading 모듈 임포트는 꼭 필요한 과정
import time
shared_number = 0
# 전역변수로 shared_number를 먼저 지정
def thread_1(number):
global shared_number
# 전역 변수의 값을 지역적으로 수정하려면 global 문을 사용하여야 한다
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1
def thread_2(number):
global shared_number
print("number = ",end=""), print(number)
for i in range(number):
shared_number += 1
if __name__ == "__main__":
# __init__ 함수가 아닌 모든 함수에 대해서
threads = [ ]
start_time = time.time()
t1 = threading.Thread( target= thread_1, args=(50000000,) )
# 임포트해둔 threading 모듈에서 OS 스레드를 객체화한
# threading.Thread 클래스를 사용한다.
# Thread 인스턴스를 만들 때 함수와 필요한 인자를 각각 넘겨준 다음
# 스레드 객체의 .start()를 호출하여 스레드를 시작할 수 있다. (바로 아래 코드)
# 또한 이 때, args = (50000000, )임에 주의하자.
# 여기서 콤마를 찍지 않으면 튜플 형태로 인자가 넘어가지 않는다.
t1.start()
threads.append(t1)
t2 = threading.Thread( target= thread_2, args=(50000000,) )
t2.start()
threads.append(t2)
for t in threads:
t.join()
# 위의 join() 설명을 읽고 보니 이 join()이 이해가 된다.
print("--- %s seconds ---" % (time.time() - start_time))
print("shared_number=",end=""), print(shared_number)
print("end of main")
이를 수행한 화면은 아래와 같다.
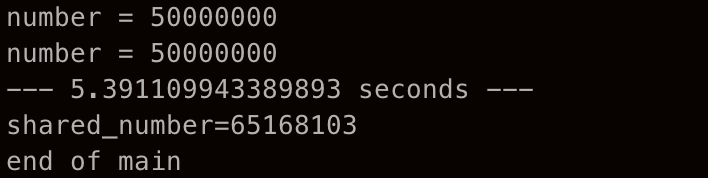
shared_number= 뒤에 일억이 붙기를 기대하고 실행한 작업이지만 6500만밖에는 되지 않았다! 이것이 바로 위에서 언급했던 두 개의 스레드가 하나의 공통 작업에 접근하는 경우에 해당하는 것이다. 그래서 인간이 예상한대로 결과가 나오지 않는다.
해결책
위와 같이 두 개 이상의 스레드가 동시에 같은 자원에 접근할 때의 자원 선점 문제를 해결하는 방법으로 스레드 동기화 가 있다. 스레드 동기화에는 대표적으로 Lock 객체가 있다.
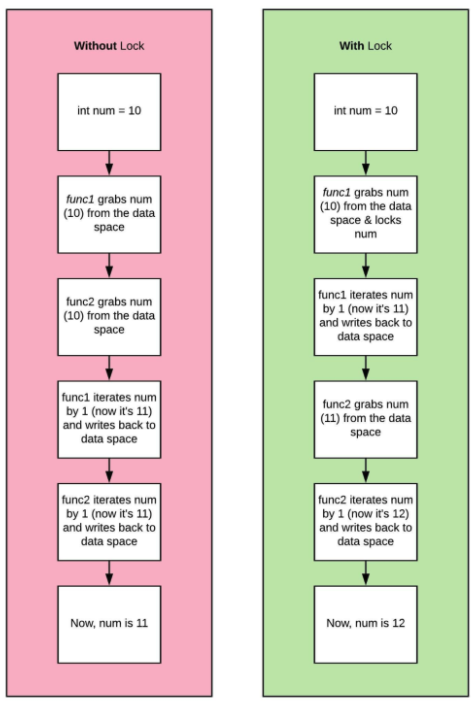
위 그림처럼, Lock을 설정할 경우 자원 선점 문제를 편안하게 해결해준다.
이 Lock을 이용하여 문제를 해결한 코드는 아래와 같다.
import threading
import time
lock = threading.Lock()
# thread 밖에서 lock 인스턴스를 생성한다
shared_number = 0
def thread_1(number):
global shared_number
print("number = ",end=""), print(number)
lock.acquire()
# 자원에 접근하는 바로 그 시점에서 acquire() 메소드를 호출한다.
# 만약 이미 다른 thread가 선점하여 lock이 잠겨있는 상태라면,
# lock을 점유할 수 있을 때까지 해당 메소드를 block할 것이다.
for i in range(number):
shared_number += 1
lock.release()
# 자원의 사용이 모두 끝나면 release()를 호출한다.
# 이렇게하면 같은 lock에 대해 acquire()를 호출한 다른 스레드 중 하나가
# 다시 lock을 점유하고 실행하는 식을 동작한다.
# thread_1에서 했던대로 lock.acquire()와 lock.release()를 모두 똑같이 해준다.
def thread_2(number):
global shared_number
print("number = ",end=""), print(number)
lock.acquire()
for i in range(number):
shared_number += 1
lock.release()
if __name__ == "__main__":
threads = [ ]
start_time = time.time()
t1 = threading.Thread( target= thread_1, args=(5000000,))
t1.start()
threads.append(t1)
t2 = threading.Thread( target= thread_2, args=(5000000,))
t2.start()
threads.append(t2)
for i in threads:
i.join()
print("--- %s seconds ---" % (time.time() - start_time))
print("shared_number=",end=""), print(shared_number)
print("end of main")lock을 걸어서 해결한 경우 다음과 같은 실행 결과를 낸다.
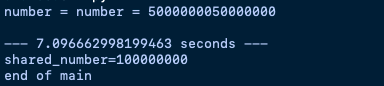
원한대로 정확히 일억번의 shared_number를 출력해준다.
위에서 작성한 방식도 괜찮지만, 아래처럼 with문을 사용하여 lock을 사용할 수도 있다.
def thread_1(number):
global shared_number
print("number = ",end=""), print(number)
with lock:
for i in range(number):
shared_number += 1
def thread_2(number):
global shared_number
print("number = ",end=""), print(number)
with lock:
for i in range(number):
shared_number += 1+) Lock 이외에도 Semaphore 객체를 이용할 수도 있다.
방법은 Lock과 상당히 비슷하다.
references:
https://coding-groot.tistory.com/103 (multithread)
https://monkey3199.github.io/develop/python/2018/12/04/python-pararrel.html (thread vs. process)
https://soooprmx.com/archives/8834 (thread의 생성과 속성)
https://www.youtube.com/watch?v=iks_Xb9DtTM (얄팍한 코딩사전 - 프로세스는 뭐고 스레드는 뭔가요?)
https://velog.io/@soojung61/Python-Thread (Lock 객체 및 Semaphore 객체 사용법)
