[WiselyClone] 1st project - wisely 10일차: 상품 리뷰 크롤링

내 크롤링의 역사
첫 크롤링 세션이 약 한 달전에 있었다. 세션은 약 한 시간 반가량 진행되었고 당시의 나는 1도 이해하지 못했다. (이쯤되니 '나는 1도 이해하지 못했다' 를 모든 글에 데코레이터처럼 달아도 괜찮을 것 같다.) 진도의 압박으로 당시에는 이해와 학습, 실습을 모두 포기하고 약 3주 뒤, 크롤링을 직접 실습할 기회가 생겼다. 첫번째로는 Billboard hot 100 Chart 크롤링(Rank, Artist, Song) 두번째로는 Vogue Korea 크롤링(Headline), 세번째로는 모델링까지 학습한 후, 모델링 기반으로 스타벅스 코리아 크롤링(카테고리, 메뉴 이름, 용량, 가격 등)이었다. 첫번째와 두번째 크롤링은 성공했다. 그 두 과제들은 Selenium을 사용하지 않고도 BeautifulSoup으로만으로도 크롤링이 가능하기 때문에 그나마 남들의 접근 방법을 이해하기에 수월한 편이었으나 크롤링 코드를 내가 스스로 짤 수는 없었다. 스타벅스 크롤링과제는 모델링부터 막혀 모델링에 시간을 많이 썼고, 결국 메뉴 이름 긁어보기 구경 정도밖에 할 수 없었다. 이후 바로 1차 프로젝트가 시작되었다. 나는 회원가입과 로그인, 그리고 마이페이지(뼈대)를 어느 정도 구현한 상황이라 상품 리뷰 크롤링(5페이지까지만)에 들어가게되었다. 말했듯 크롤링을 한 번도 제대로 직접하고 들어오지 않았기 때문에 매우 걱정스러웠지만 언젠가는 혼자해서 해봐야한다고 생각했다. 그리고 방금 와이즐리 리뷰 크롤링이 끝났다.
와이즐리 > 상품보기 > 리뷰

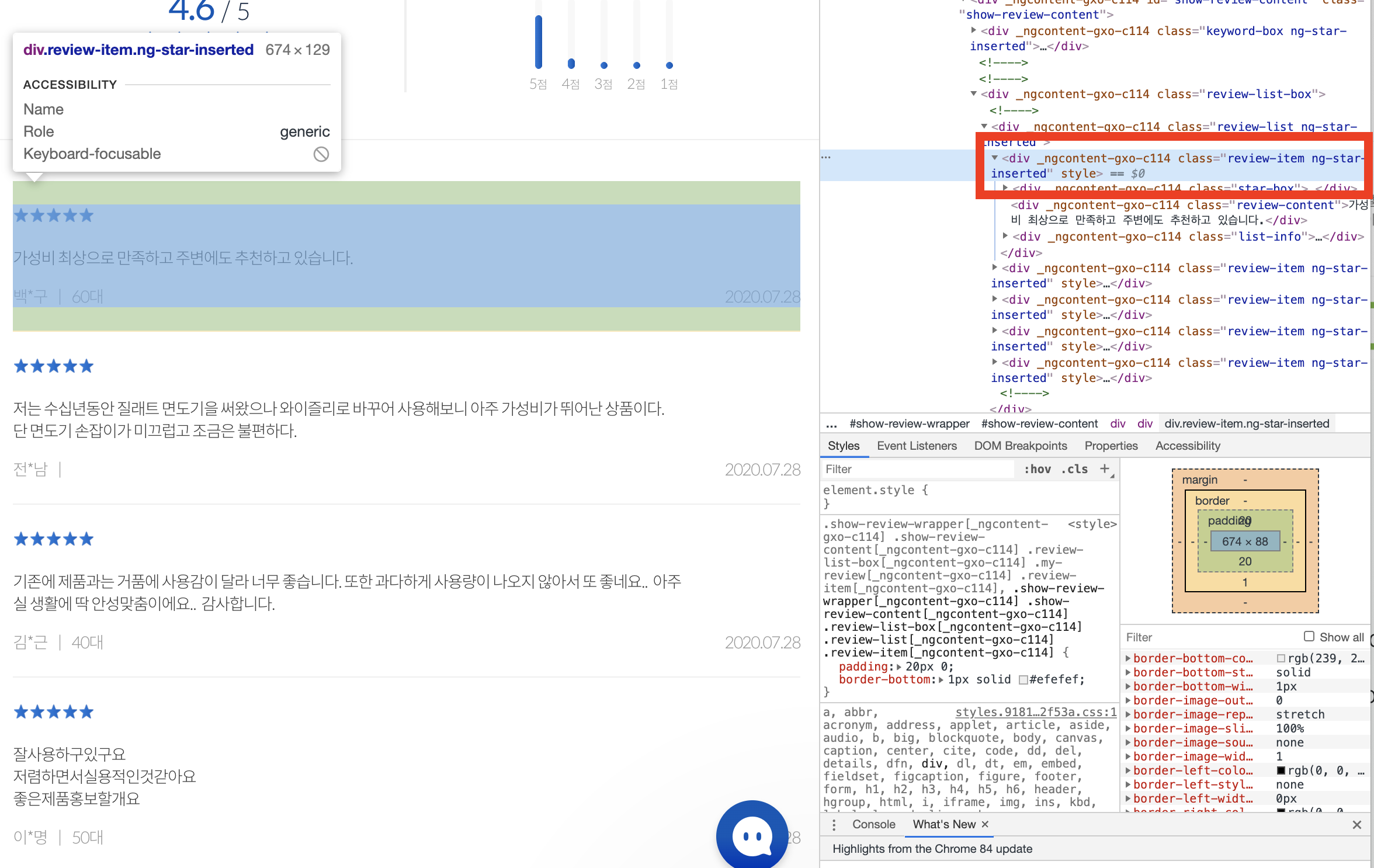
클릭 후, 하단으로 내리면 이렇게 리뷰가 뜬다.
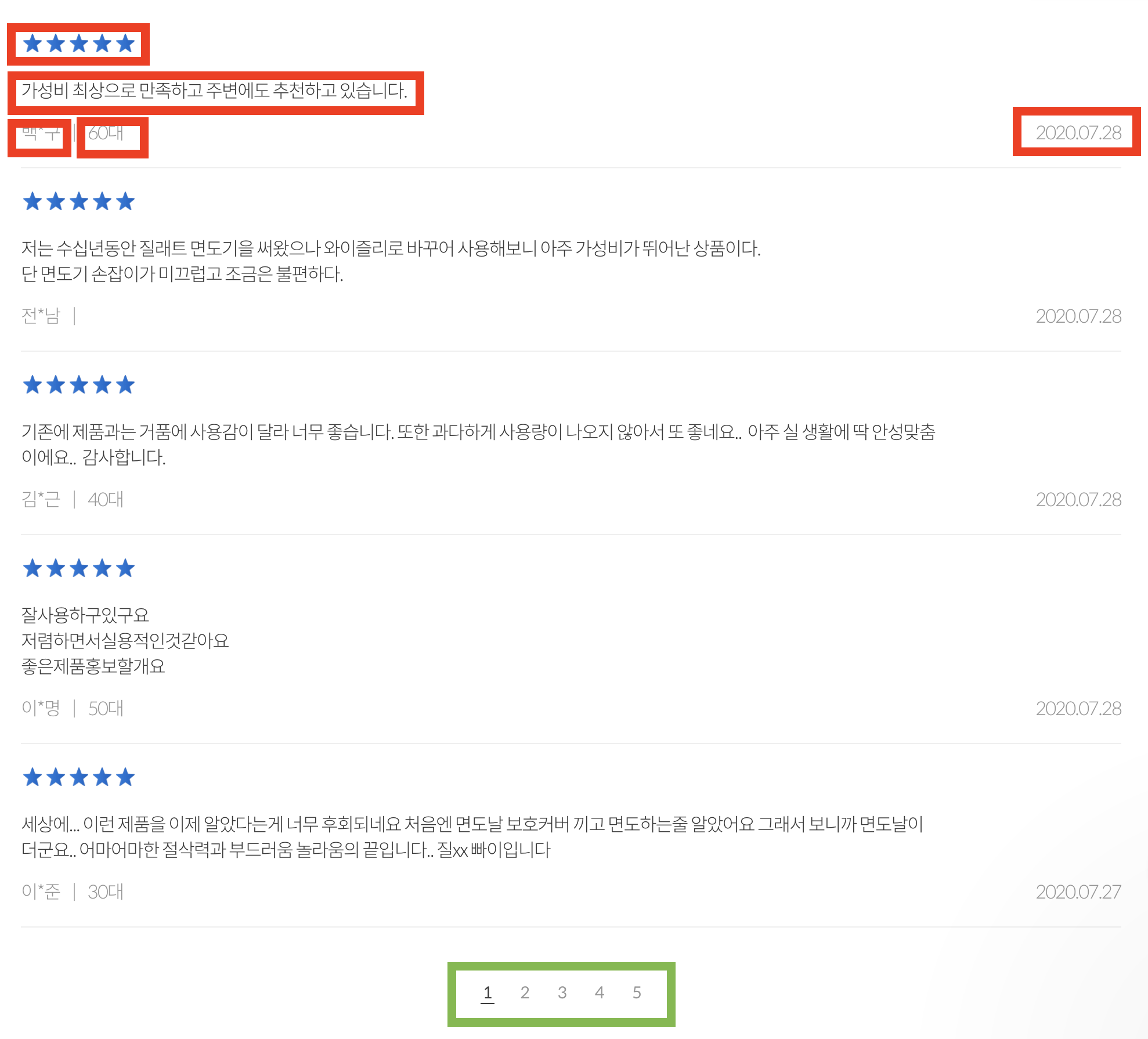
빨간 박스로 표시한
1. 별점
2. 리뷰 내용
3. 리뷰한 유저 이름
4. 리뷰한 유저 연령대
5. 리뷰 적은 날짜
를 모두 크롤링으로 긁어서 CSV 파일에 넣어야 한다.
그리고 녹색 박스로 표시한 부분은, 페이지네이션 부분인데 이 부분 X-Path의 규칙을 이용해 셀레니움 .click()을 작성해야했다.
코드 리뷰
1) 크롤링을 위한 초기 세팅: Import
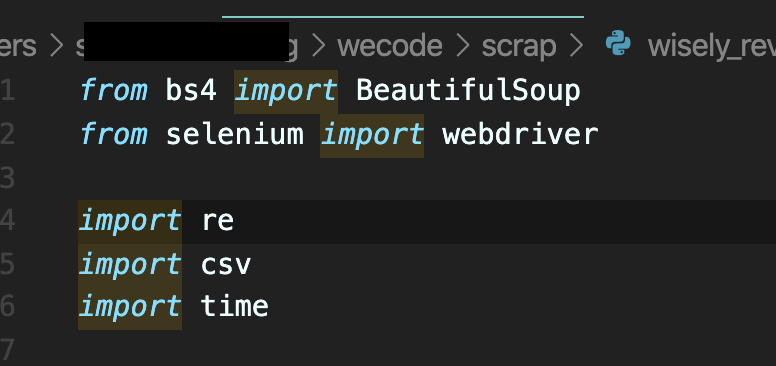
from selenium import webdriver # 웹 드라이버를 불러와야, 셀레니움을 이용하여 웹사이트를 띄울 수가 있다. import re # 파이썬에서 정규표현식을 컴파일하기 위해 필요한 모듈인 re를 임포트한다. import csv # 모든 자료를 크롤링한 후, csv(comma-separated values)형식으로 저장하기 위한 임포트. # 몇 가지 필드를 쉼표로 구분한 텍스트라고 이해하면 쉽다. import time # 셀레니움을 이용하여 웹페이지에 접근할 경우, 클릭 이벤트를 만들 수 있다. # 이 때, 클릭 후 렌더된 페이지의 정보를 모두 저장하기 위해 충분히 필요한 시간을 주어야 하는데, # 이 때, time 모듈이 필요하다.
2) 크롤링을 위한 초기 세팅: 셀레니움 웹 드라이버를 이용하여 웹에 접근하여 csv 형태의 파일로 저장할 것을 알려주기
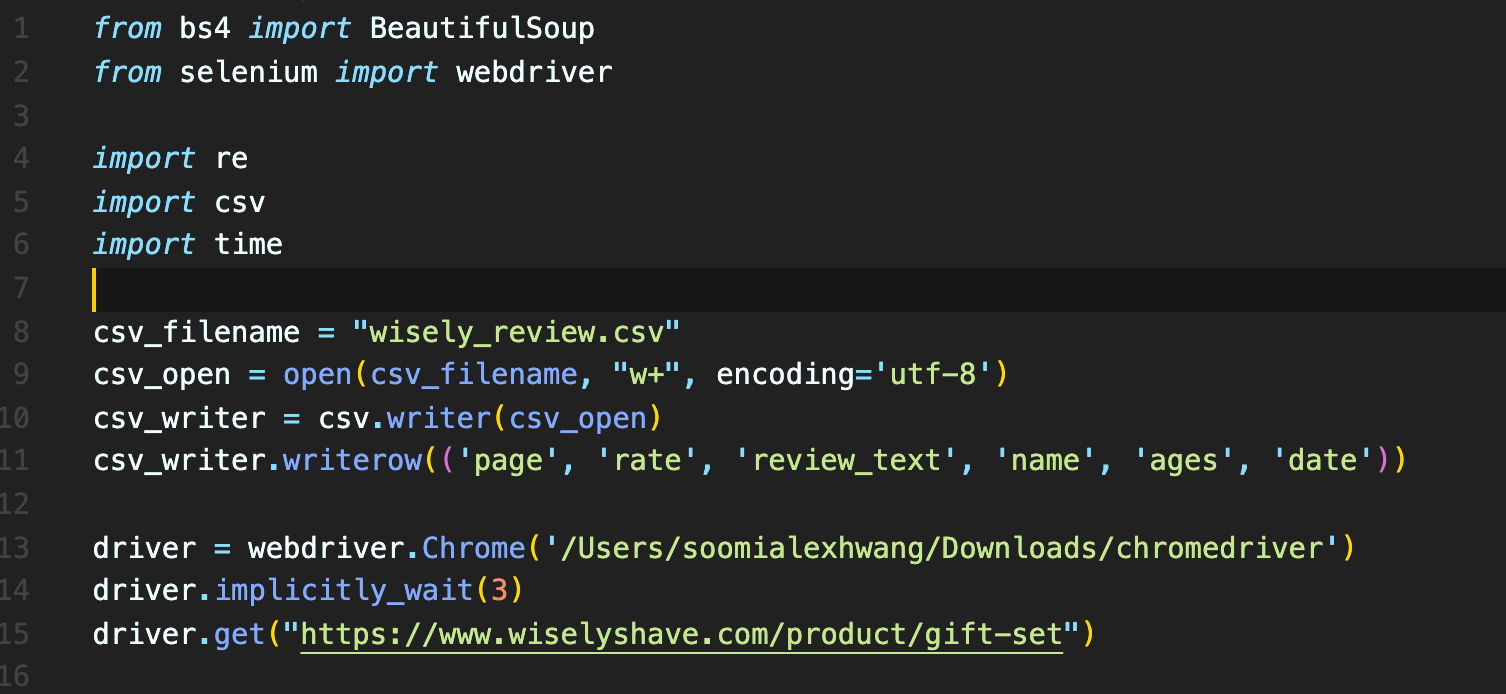
csv_filename = "실제 데이터를 저장할 csv 파일명" csv_open = open(csv_filename, "w+", encodeing='utf-8') # 바로 위에 변수로 선언한 csv 파일명을 가진 csv 파일을 열어 # write 모드 on하여, 'utf-8'형식으로 작성하겠다 csv_writer.writerow(('page', 'rate', 'review_text', 'name', 'ages', 'date')) # csv 파일에 row 이름을 지정해주었다. 총 6열. driver = webdriver.Chrome('로컬 환경에서 크롬 드라이버가 저장되어있는 위치') # 크롬 드라이버를 이용하여 작업을 할 것이며, driver.implicitly_wait(3) # 🍎 이 부분이 과연 time.sleep(n)과 무엇이 다른 것인지 궁금했었다. # sleep은 프로세스 자체를 지정한 시간동안 기다려주는 것으로 무조건 지연되나 # implicitly_wait은 뜻 그대로 # 브라우저에서 사용되는 엔진 자체에서 파싱되는 시간을 기다려주는 메소드이다. (셀레니움에서만 사용하는 특수 메소드) # 그렇다면 여기서는 드라이버 열고 '3초의 파싱 시간을 주자'의 의미. driver.get("파싱을 시작할 웹 페이지 url") # 내 경우 와이즐리 상품보기 페이지였다.
3) 다섯 페이지 매크로 걸어 크롤링 해보기
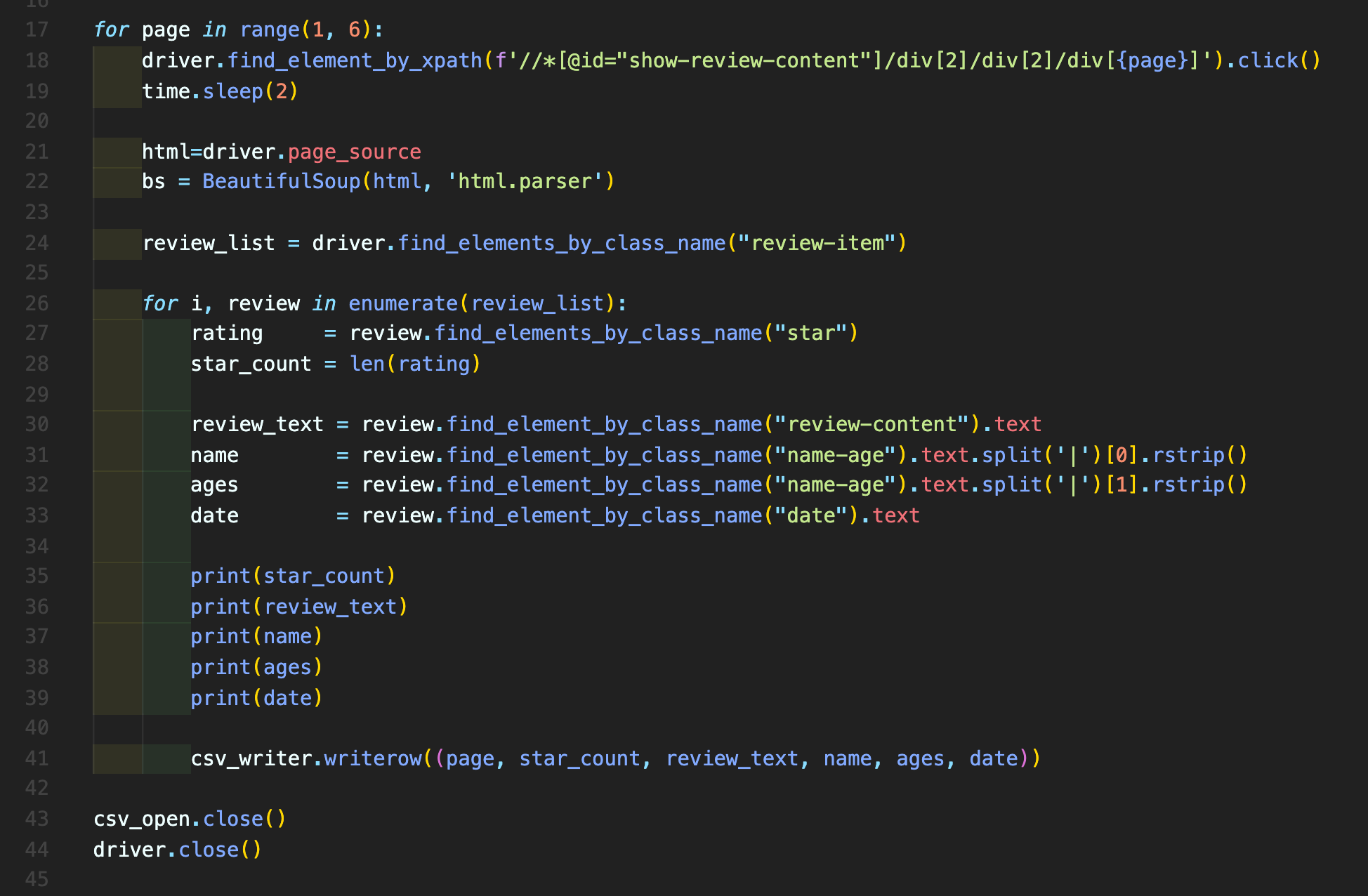
for page in range(1, 6): # 페이지네이션에서 1부터 5페이지까지 볼 것이므로 range(1, 6)으로 전체 포문 설정 driver.find_element_by_xpath(f'//*[@id="show-review-content"]/div[2]/div[2]/div[{page}]').click() # 🍎 find_element_by_xpath를 개발자도구로 살펴본 결과, div[2]/div[2]/div[n] 임의 규칙을 발견하였다. # 그래서 이 곳에 {page} 값이 들어가서 포문을 돌 수 있도록 설정하였다. # 페이지네이션 부분이라 이곳을 클릭하는 것도 필요하여 .click() 까지 설정 time.sleep(2) # 그리고 한 페이지 들어가서 충분히 정보를 긁는 시간을 2초 주었다. (리뷰 자체가 많지 않아서 5초 이상이 필요하지 않을 것 같았다.) html=driver.page_source # 셀레니움 드라이버의 page_source를 이용하여, 현재 열려있는 페이지의 모든 소스 정보를 html 변수에 담아 놓은 후, bs = BeautifulSoup(html, 'html.parser') # time.sleep으로 주어진 2초동안 해당 페이지 내의 모든 소스인 html에서 # 필요한 특정 정보를 긁을 때 뷰티풀숩의 'html.parser'를 사용하기 위해 해당 기능을 변수 bs에 담는다. # 🍎 그런데 코드를 계속해서 고치는 과정에서 bs 변수는 사용하지 않게 되었다. # 지금 이 블로깅을 하면서 알았는데, # ⭐️ 뷰티풀숩의 기능을 이용하지 않고 오로지 셀레니움의 기능만으로 크롤링을 했더라. # 즉 이 코드는 사실 필요하지 않은 코드. review_list = driver.find_elements_by_class_name("review-item") # 🍎🍎 우선 내가 긁어야하는 정보(별점, 리뷰 내용, 유저 이름, 유저 연령대, 리뷰 적은 날짜)가 # 가장 상단에서 꼽자면(크게 봐서) 어디에 속해있는지 개발자 도구를 통해서 확인해본다. class명의 시작이 review-item인 태그에 내가 수집해야할 모든 내용들이 걸려있는 것을 확인했고, # 그래서 이 식을 제일 위에 적었다. # (모든 정보가 이 변수 속에서 나올 예정)
for i, review in enumerate(review_list): rating = review.find_elements_by_class_name("star") star_count = len(rating) # 이미 앞서 최상단의 태그를 지정해주었기 때문에 (review-item) # 이 아래부터 포문을 돌리며 된다(🍎 Indent 주의!) # 다만, 별점의 경우 별 이미지로 표현되어 있어, 해당 별의 개수를 len함수로 세어 star_count에 넣어 # 이 star_count를 별점으로 활용했다. review_text = review.find_element_by_class_name("review-content").text name = review.find_element_by_class_name("name-age").text.split('|')[0].rstrip() ages = review.find_element_by_class_name("name-age").text.split('|')[1].rstrip() date = review.find_element_by_class_name("date").text # 그리고 내가 원하는 정보에 적힌 클래스명을 적어주었다. # 적을 때, 이미 위에서 최상단에 정의한 review_list 태그 속에서 포문을 돌려 찾는 것이므로, 모든 값은 review.으로 시작한다 # 🍎 여기서 잠깐: enumerate(review_list)로 포문을 돌 때에는 꼭 i, review를 모두 써주도록 한다. # i는 뭔가 필요가 없어보여서 지웠더니 [AttributeError: 'tuple' object has no attribute 'find_elements_by_class_name'] 에러 발생 #print(star_count) #print(review_text) #print(name) #print(ages) #print(date) # 요 위 다섯개 프린트는 출력값을 확인하기 위한 장치 csv_writer.writerow((page, star_count, review_text, name, ages, date)) # 처음에 11번째 줄에 선언했던 6개의 로우인 'page' 'rate', 'review_text', 'name', 'ages', 'date'에 # 크롤링한 변수 여섯 개를 넣어(적어)준다. # 이 과정에서 변수의 이름은 비슷할 수도 있고, 같을 수도 있고, 다를 수도 있으나 # 나는 star_count를 제외하고 거의 같게 사용하였다. csv_open.close() # 주의할 점은 csv_close()가 아니라는 점 driver.close()
references:
https://www.inflearn.com/questions/5597 (implicitly_wait)
