- Q. 랜덤 포레스트 알고리즘에 대해 설명해보세요.
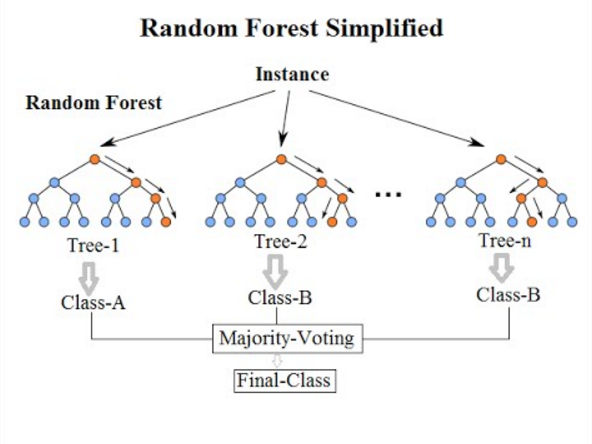
A. 랜덤 포레스트는 수많은 의사결정나무 decision tree 들을 만들어 ensemble, 다수결에 의해 최종 답을 내는 알고리즘입니다.
- Q. 랜덤 포레스트의 장점과 단점을 아는대로 말해보세요.
A. 랜덤 포레스트는 장점으로는 과적합, 이상치 및 결측치에 강하다는 점. 그리고 정규화 과정이 필요없고 비선형적인 데이터에도 좋은 성능을 보입니다. 단점으로는 수많은 의사결정나무를 만들어야하기 때문에 학습 시간과 연산이 많이 든다는 것입니다.
머신러닝 하다보면 거의 무조건 마주치는 랜덤 포레스트 알고리즘에 대해 정리하려고 한다.
랜덤 포레스트 Random Forest
랜덤 포레스트는 의사결정나무들의 집합이다. 이때 의사결정나무란 Decision Tree 로 나무의 가지에 따라 파라미터를 학습해 데이터들을 분류하는 방식이다. 이 의사결정나무는 초반의 데이터에 따라 크게 좌지우지되는 단점이 있으며 이게 곧 overfitting 과적합으로 이어질 수 있다, (학습 데이터에 과하게 맞춰진 나무, 새로운 테스트 데이터에 대해서는 정확도가 낮은). 이때 의사결정나무 만들때 가지치기 파라미터를 이용해 과적합을 막을 수 있지만 추천되는 방법은 아니다.
이러한 의사결정나무의 단점을 보완해주기 위해 수많은 트리를 만드는 것, 그게 바로 랜덤 포레스트이다. Random Forest Algorithm 은 Ensemble 중에서도 Bagging 에 해당된다. 수많은 의사결정나무를 만들어 그들의 다수결에 따라 최종 답을 결정한다.
이러한 랜덤 포레스트는 ensemble 특성상 좋은 성능을 보장하기 때문에 (큰 수의 법칙?) 머신러닝 알고리즘에 자주 언급된다. 개인적으로 랜덤 포레스트사용하면서 제일 편했던 점은 정규화, scaling 이 필요없다는 것이었다. 사실 랜덤 포레스트의 대부분의 장점들이 의사결정나무와 ensemble, 이 두 특징에서 기인한다.
- 장점
- 과적합이 잘 일어나지 않는다. ensemble 이기 때문에.
- 결측치나 이상치에 강하다. ensemble 이기 때문에.
- 회귀 알고리즘이 아닌 의사결정나무 알고리즘에 기반한 기법이기 때문에 scaling, 정규화 과정이 아예 필요 없다.
- 비선형적 데이터에 강하다. 이 역시 회귀 알고리즘이 아니라 의사결정나무이기 때문이다.
- 새로운 데이터가 들어와도 크게 영향을 받지 않는다. ensemble 이기 때문에.
- 단점
- 학습 시간과 계산 연산량이 높다. 수많은 트리를 계산하기 때문이다.
나무가 많으면 많을수록 과적합이 일어날 확률은 적어진다. 하지만 이 역시 time accuracy trade off 가 존재하며 산업에 이용하기 위해서는 잘 조절해야한다. Python sklearn library 는 기본적으로 100개의 트리 가지고 한다. 예전 프로젝트에서는 2000개 가지고 했는데 좀 과했나 싶네 ㅎㅎ
정리.
랜덤 포레스트는 ensemble, decision tree 이다.
장점으로는 과적합, 결측치 및 이상치에 강하며, 정규화 과정이 필요없으며 비선형적인 데이터도 좋은 정확도를 보여준다.
단점으로는 학습 시간 및 연산이 오래 걸린다.
함께 보기 좋은 것
의사결정나무 Decision Tree
앙상블 Ensemble
과적합 Overfitting
