< 썸네일 출처 >
https://eunchankim-dev.tistory.com/55?category=445591
평소에 train validation test dataset 의 차이 정도는 알고 있었지만 이 공부를 통해 더 확실하게, 그리그 그 쓰임새까지 알 수 있게 되었다. 그리고 K-Fold Validation 을 처음에는 잘 이해 못했는데, 이제는 잘 알 것 같다.
-
Q. Train dataset 과 Validation dataset 에 대해 말해보세요.
A. Train data 은 모델을 학습시킬때 직접 사용되는 데이터입니다. Valid data은 학습된 모델의 예측성능을 확인하기 위한 데이터입니다. 이때 과적합이 안 일어났는지 유심히 살펴봐야합니다. -
Q. Valid dataset 과 Test dataset 의 차이에 대해 말해보세요.
A. Valid dataset 은 과적합의 유뮤와 파라미터 튜닝에 사용되는 데이터입니다. 즉, 모델이 valid dataset 의 영향을 받습니다. 하지만 test dataset 은 오로지 예측성능이 어떤지를 확인하기 위한 데이터로 이 지표 가지고 튜닝을 하면 안 됩니다. -
Q. K-fold validation 에 대해 설명해보세요.
A. 한번의 train valid 과정이 부족하다고 생각되어 만들어진 기법으로, k 만큼 나누어 돌려가면서 train valid 시키는 방법입니다. 모델의 안정성을 보장하기 때문에 실제로 자주 사용됩니다. -
Q. K-fold validation 의 장단점에 대해 말해보세요.
A. 장점으로는 모든 데이터가 valid 으로 사용되기 때문에 안정적인 예측성능을 가졌다고 말할 수 있게 해줍니다. 단점으로는 똑같은 데이터에 여러번 학습하기 때문에 시간이 오래 걸립니다.
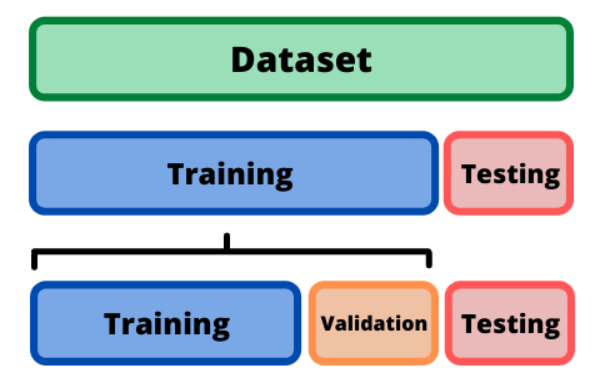
Train Validation Test Datasets
머신러닝 모델 학습할때 데이터셋은 당연히 필요하고 이 데이터셋을 어떻게 활용해야하는지도 알아야한다.
머신러닝 정의 : 머신러닝은 인공지능의 하위 분야로, 데이터와 알고리즘을 이용해 사람이 학습하는 과정을 흉내내 기계도 학습하게 하는 것을 말합니다.
머신러닝 학습을 할때 dataset 은 크게 3가지로 나눠서 사용한다. 그게 각각 Train set, Validation set, Test set 이다.
Train Set
Train set 은 모델을 학습시킬때 사용하는 데이터이다.
Validation Set
Validation set 은 train set 을 통해 학습된 모델이 예측을 얼마나 잘 하는지 확인하기 위한 데이터셋이다. 예측성능을 확인하고, 알맞게 parameter tuning 을 하는 것이 validation dataset 의 사용 목적이다.
한 가지 중요한 것은 train set 에 비해 성능이 너무 떨어지면 과적합(high variance, low bias) 이 된 것임을 알 수 있다. 따라서 train set 의 error 값과 validation set 의 error 값을 대응하면서 튜닝을 진행해야 한다.
Test Set
Test set 은 최종 모델의 성능 평가에 사용되는 데이터이다. 원칙적으로는 이 데이터에서의 성능 평가가 모델의 최종 성능이 되는 것이고 이 이후에는 모델 튜닝을 하면 안 된다. (하지만 다들 그 이후에도 튜닝을 진행한다)
Validation set 과 test set 을 구분하는 이유에 대해 잘 이해 못하는 사람들도 있다. 간단하게 말해 test set 은 '순수' 예측성능을 알아보기 위함이다. Validation set 도 예측성능을 확인해 파라미터 튜닝을 하는데 사용된다. 바꿔 말하면, 모델은 validation set 의 영향도 받는 것이다. 또 다시 말하면, 모델이 train set 과 validation set 에 과하게 맞춰진, 과적합 될 위험이 있다. Test set 은 이러한 상황을 막기 위해 있다.
Test set 은 순수 예측성능을 알아보기 위해 사용되는 것이다.
K-Fold Validation
머신러닝에 이용되는 데이터셋은 (시계열을 제외하고) 보통 랜덤하게 섞여서 들어간다. 따라서, 우연히 아주 잘 맞는 train set 과 그 예측성능을 좋게 나타내는 validation set이 걸릴 수 있고 우리는 이 한번의 실험을 통해 좋은 모델을 만들었다고 착각할 수 있다. 당연히 test set 또는 real data 에서의 예측성능은 떨어진다. 이러한 상황을 막기 위해 k-fold validation 기법이 많이 사용된다.
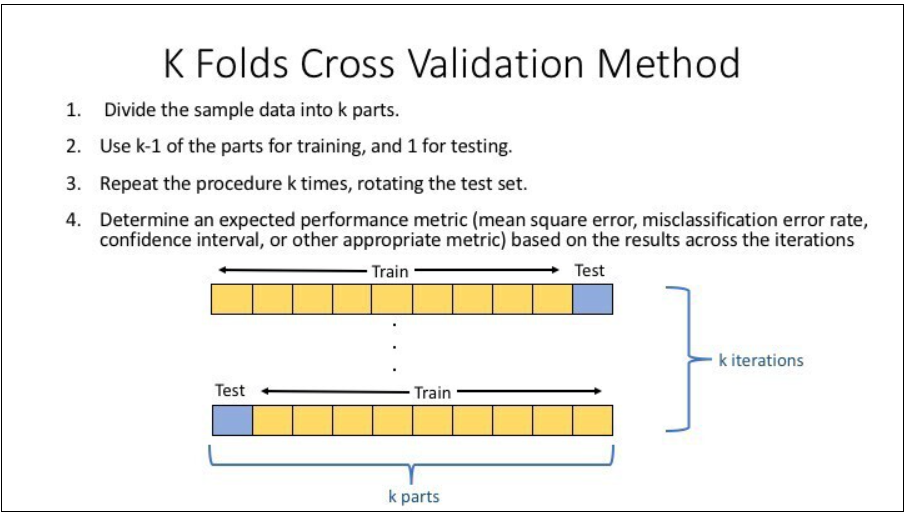
K fold validation 의 목적은 ‘여러 shuffle을 통해 모든 데이터가 최소 한번은 validation 에 이용된다‘ 이다. 5 fold validation 을 하면 데이터셋을 학습 80, validation 20 으로 나누어 5번에 걸쳐 학습한다. 그리고 이 5번의 에러값들의 평균을 모델의 최종 성능으로 낸다.
Bagging 의 장점을 가져온 것으로, 실제 머신러닝 모델 평가할 때 자주 쓰는 기법이다. 하지만 단점으로는 똑 같은 실험을 여러 번 하기 때문에 시간소요가 크다는 점이다.
