
- LLM의 Transformer 아키텍처는 Masked multi-head self-attention 메커니즘을 사용한다.
Masking
마스킹의 목적
- 언어 모델이 다음 단어를 예측하는 작업을 수행할 때, 현재 위치의 토큰이 미래의 정보를 참조하지 못하도록 제한합니다.
- 이는 인간이 문장을 생성할 때, 앞서 말한 단어들을 기반으로 다음 단어를 선택하는 과정과 유사합니다.
- 마스킹을 통해 모델이 올바른 순서로 문장을 생성할 수 있도록 합니다.
마스킹의 중요성
- 미래의 정보를 참조할 수 있다면, 모델이 다음에 나올 단어에 대한 답을 미리 알게 되어 예측이 아닌 암기를 하게 됩니다.
- 마스킹을 통해 모델이 올바른 예측을 수행하고, 학습 과정에서 실제로 필요한 패턴을 학습하게 됩니다.
Decoder-only 구조와 자기 회귀적 생성
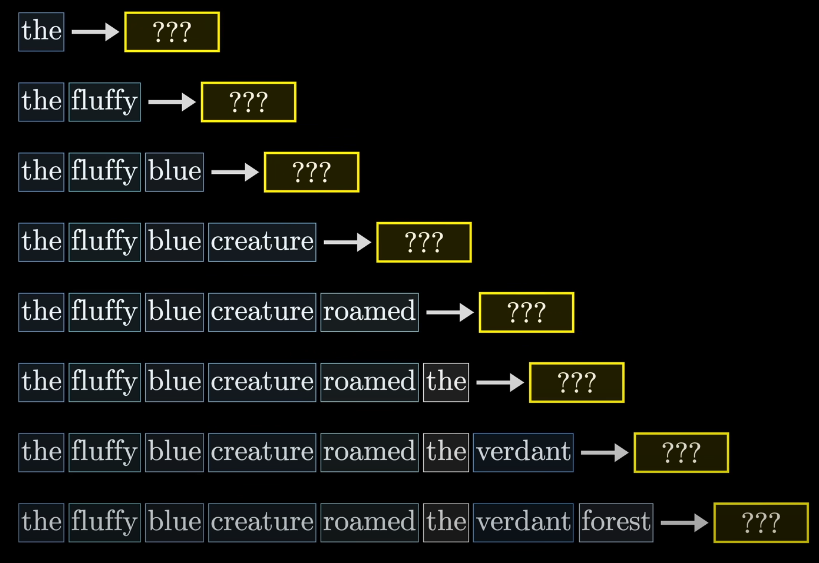
- 언어 모델은 decoder-only 구조를 사용하며, decoder는 새로운 텍스트를 예측, 생성하는 역할을 수행합니다.
- 자기 회귀적 생성:
- 모델은 한 번에 하나의 토큰을 생성합니다.
- 생성된 토큰을 다시 입력으로 사용하여 다음 토큰을 예측합니다.
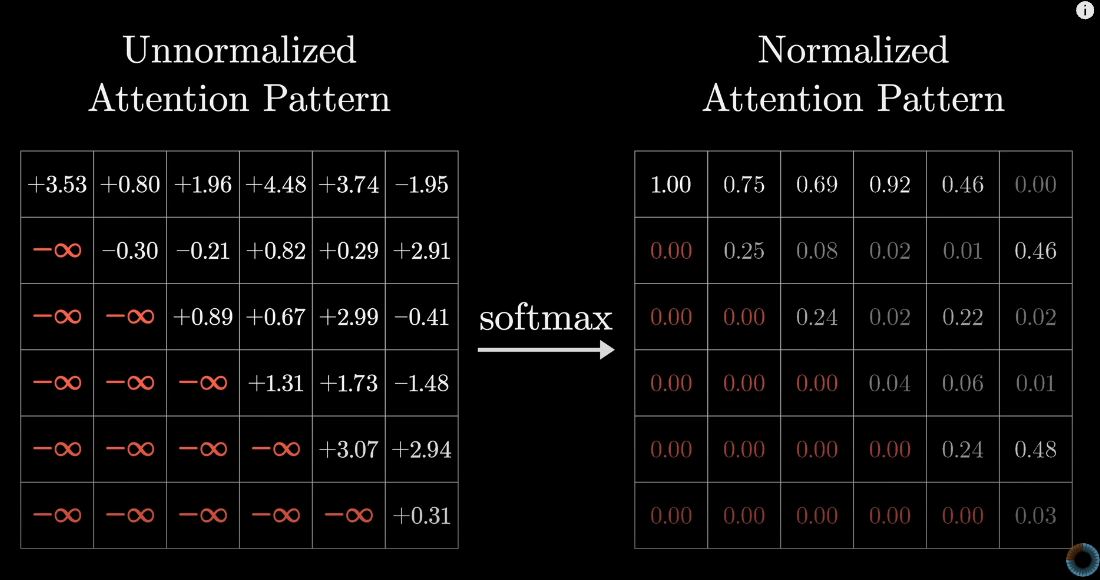
마스킹의 동작 방식
- 마스킹은 어텐션 스코어 행렬에 적용되어, 각 토큰이 자신과 이전 토큰만 참조할 수 있도록 합니다.
- 구체적인 과정:
1. 다음 토큰에 해당하는 위치의 스코어를 음의 무한대로 설정합니다.
2. 소프트맥스(Softmax) 함수 적용 시, 해당 위치의 가중치가 0이 되어 실제로 참조되지 않도록 합니다.
Multi-head Attention
목적과 기본 개념
- 모델이 다양한 관점에서 문맥을 이해할 수 있도록 돕습니다.
- 여러 개의 서로 다른 가중치 행렬 , , 를 사용하여 여러 개의 self-attention 연산을 병렬로 h번 수행합니다.
- = d_model
동작 방식
- 각각의 head에서 self-attention 연산을 수행합니다.
- 각 head에서 나온 출력을 이어붙입니다(concat).
- 이어붙인 결과에 다시 선형 변환을 적용하여 최종 출력을 만듭니다.
Multi-head Attention의 이점
- 다양한 시각에서 입력 데이터를 분석할 수 있습니다.
- 결합된 출력은 정확하고 신뢰성 있는 예측을 가능하게 합니다.
- 여러 어텐션 헤드를 병렬로 처리함으로써 계산 효율성을 높입니다.
- 일반화 능력(새로운 데이터에 대한 적용 능력)을 향상시킵니다.

일잘러가 되어야지