
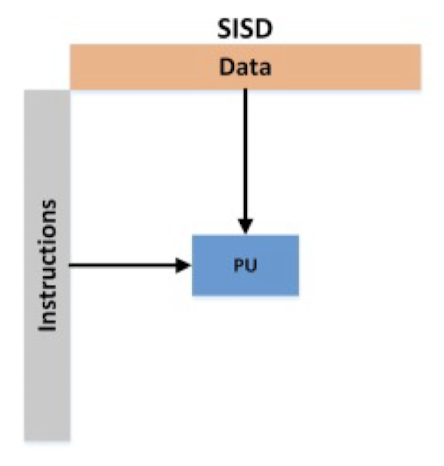
❦ Superscalar processors (SISD, Single Instruction Single Data)
ෆ ILP
보통 instruction은 sequential 하게 나열 → 순서대로 하나씩 실행 시 overhead ↑
→ 두 개 이상의 instruction을 ‘동시에’ 실행하려면 ?
- 서로 independent한 instruction들을 찾아서 parallel(병렬)하게 실행시킬 수 있다면 overhead ↓ 가능
- Superscalar
- 1 cycle 동안에 서로 다른 independent한 2개의 instruction을 동시에 수행
- Superscalar
- 완전히 중첩시키지는 않더라도 pipeline과 같이 stage를 약간씩 중첩시켜서 실행 가능
- Superpipeline
- 한 클럭을 2개로 나누고, 나누어진 클럭에서 각각 서로 다른 연산을 수행
- Superpipeline
- 동시에 수행
⇒ ILP 방식
: 서로 독립적인 명령어들을 최대한 찾고, 이들을 오버랩해서 실행
ෆ ILP 예시

- processor : a machine that executes the assembly instructions in sequence
→ 컴퓨터 운영을 위해 기본적인 명령어들을 처리하고 반응하기 위한 논리회로 - PC (Program Counter) : references the instruction to be executed
→ 해당 예시에서 모든 instruction을 실행하려면 5 cycle이 걸림
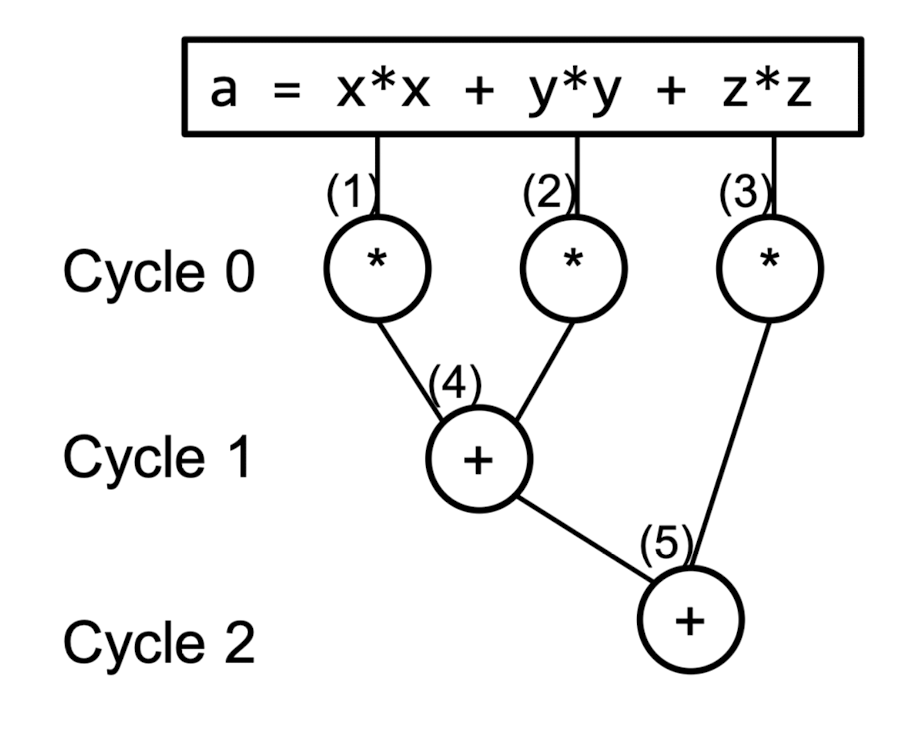
- 하지만 위와 같이 여러 개의 execution unit이 있다면 여러 개의 instruction을 한 cycle에 수행 가능
- 그럼에도 1 cycle에 모든 instruction을 수행할 수는 없음
- (4) instruction의 경우, (1)과 (2)의 수행결과가 있어야 수행할 수 있으므로 ..
- ⇒ Data Dependency
: 한 작업이나 명령이 다른 작업의 결과에 의존할 때 발생하는 상황
- 3 cycle에 모든 instruction 수행 완료
- Q: execution unit은 몇 개가 필요한가 ..
- 기본적으로 3개 : (1), (2), (3) 의 연산을 한 번에 수행
- 2개도 가능 : (3), (4) 의 연산은 독립적이기 때문에 한 번에 수행해도 ok !
- Q: execution unit은 몇 개가 필요한가 ..
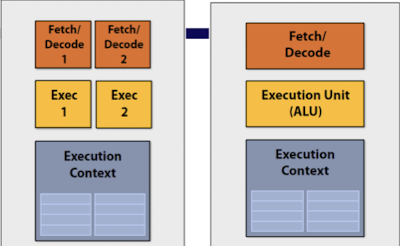
ෆ Scalar processor VS Superscalar processor
-
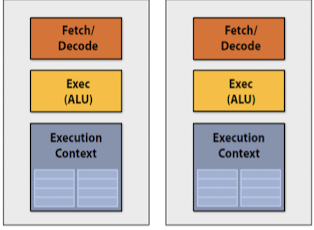
Scalar processor : 한 번에 하나의 데이터를 처리하는 CPU (1ALU)
- 한 번에 하나의 instruction만 처리 가능
- 각 instruction는 순차적으로 처리 (다음 instruction은 현재의 instruction의 처리가 완료된 후 실행)
- 단순하고 예측하기 쉬운 성능 제공
- 처리 능력이 제한적

-
Superscalar processor
- 한 번에 여러 개의 instruction 처리 가능
- 여러 ALU를 통해 동시에 다양한 instruction 실행
- instruction을 parallel(병렬적)으로 처리
⇒ 주요 차이점
- 처리 능력 : Superscalar processor는 Scalar processor보다 더 많은 instruction을 동시에 처리 가능 → 처리 능력 ↑
- 구조 복잡성 : Superscalar processor는 여러 ALU를 동시에 관리하고 조율해야 하므로 Scalar processor보다 더 복잡한 구조
- 성능 측면에서의 효율성 : Superscalar processor는 parallel 처리를 통해 더 빠른 성능을 제공
but, 이로 인해 설계와 구현이 더 어려워짐, 비용도 ↑
ෆ Superscalar processor
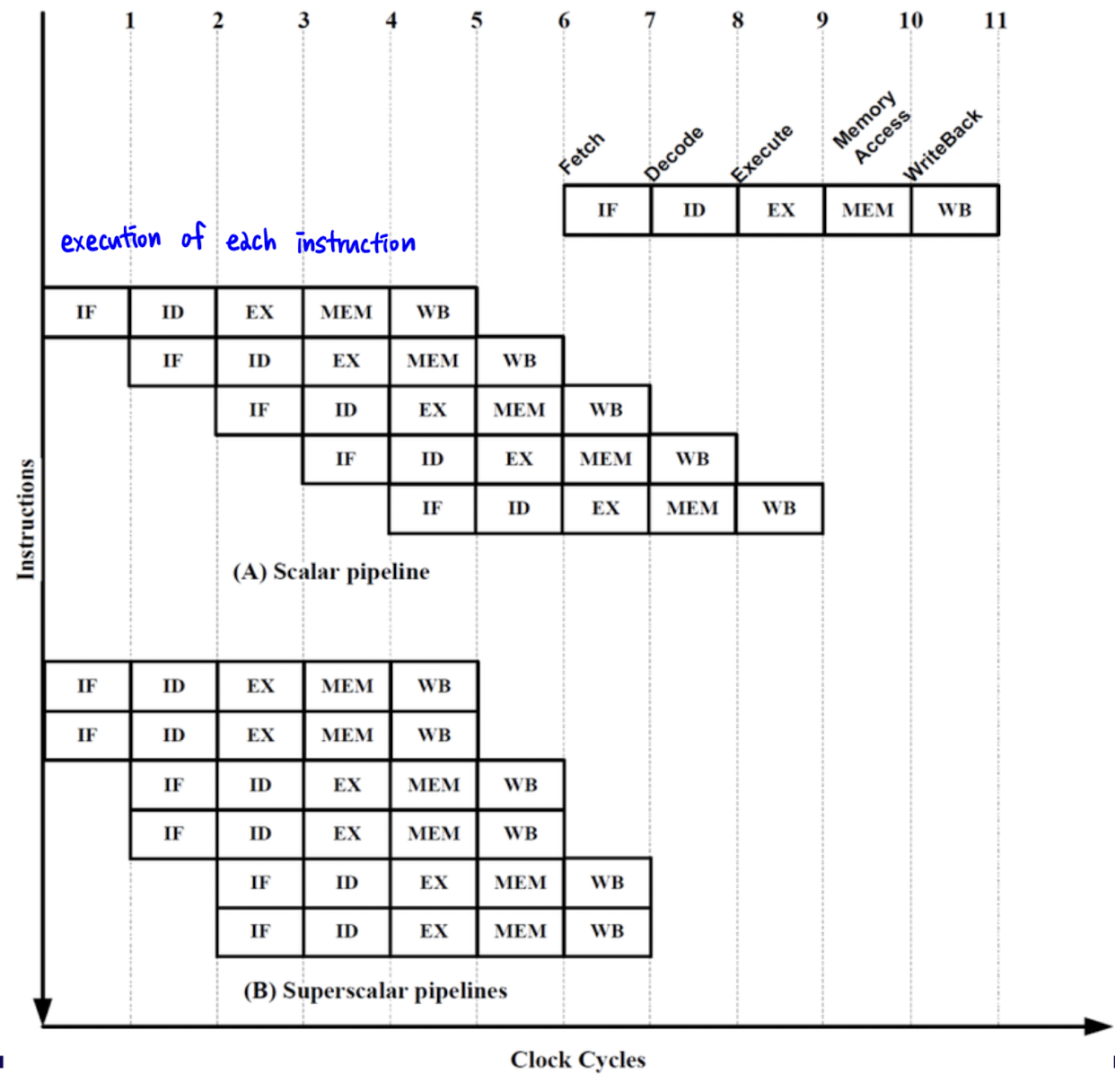
컴퓨터 성능 → CPU의 기본 처리 속도 = cycle 당 instruction을 한 번 처리하는 것 (IPC = 1)
⇒ 한 cycle에 instruction이 하나 이상 처리되면 CPU는 그만큼 한 번에 여러 개의 연산 처리가 가능 ~ 체감 속도 ↑
ex. “ “
해당 연산 결과를 뽑으라는 instruction을 줬다고 가정했을 때
- IPC = 1인 환경 → 1 cycle이 지나면 곱셈의 결과를 얻을 수 있음
- 하지만 해당 식은 덧셈의 결과를 바탕으로 곱셈의 결과를 얻어야 함 → 1 cycle 이상 걸림
- 덧셈의 instruction을 수행하는 데에 1 cycle이 소비되기 때문
- 컴퓨터 성능 향상 불가 ..
⇒ instruction 간의 dependence 때문
이를 극복하기 위한 방법 → Superscalar processor
instruction이 처리되는 path를 여러 개 만들고 각각의 instruction을 해당 path를 통해서 처리하게 하면 됨
- 지금까지 생각한 MIPS 구조의 pipeline을 그대로 따라가면서 그것과 비슷한 line을 하나 더 생성
-
하나는 data만 처리할 수 있게
-
하나는 instruction만 처리할 수 있게
⇒ instruction을 읽어오면서 data pipeline을 통해서 결과를 뽑을 수 있게끔
-
- 이 모든 작업을 parallel하게 처리
- IPC = 1인 형태를 넘어서서 성능향상 구현 가능
independent한 instruction을 어떻게 찾냐 → dynamic scheduling을 통해서 ..
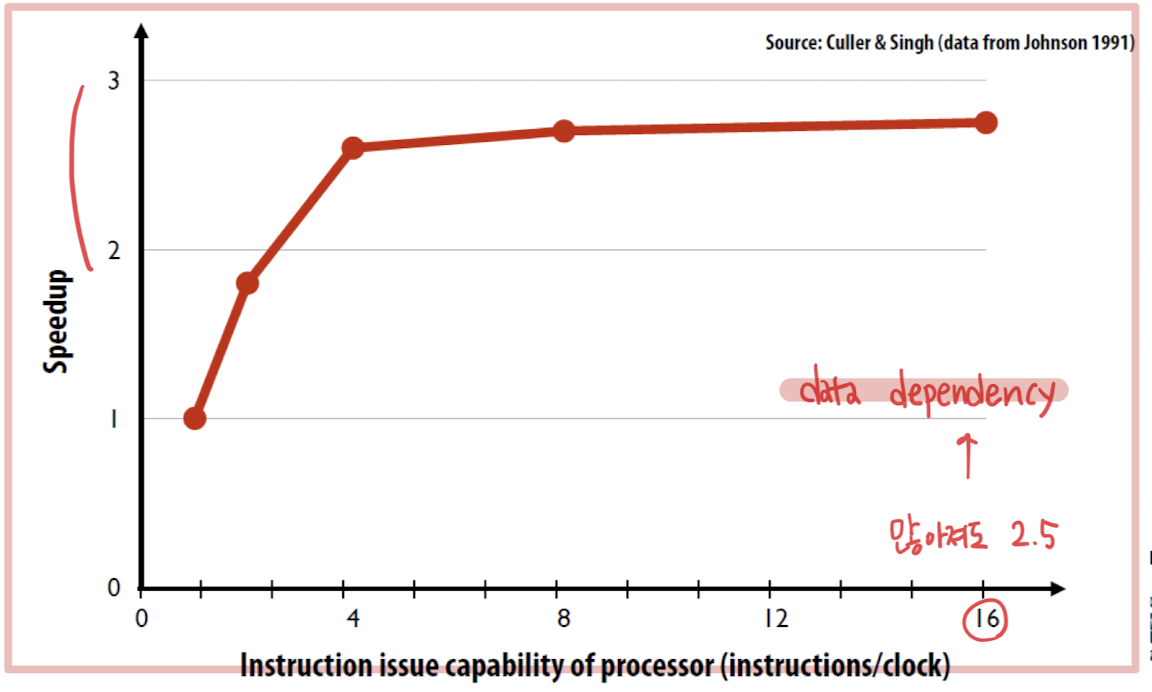
ෆ Superscalar processor가 그럼 limit 없이 성능이 향상되는가
-
Superscalar processor의 장점
-
프로그램 호환성
: 기존의 프로그램 코드를 변경하지 않고도 성능 향상 가능
processor가 자동으로 instruction 간의 independency 판별, parellel로 실행 가능한 instruction 선정
-
효율성
: 복수의 ALU를 통해 instruction을 동시에 처리 → 처리 속도가 ↑
(특히 복잡한 계산이나 대량의 data 처리가 필요한 application에서 유용)
⇒ 한계 ?
-
자원의 한계
: 동시에 실행할 수 있는 instruction의 수는 결국 processor 내의 ALU의 수와 관련 자원에 의해 제한됨
-
instruction dependency
: 일부 instruction은 다른 instruction의 result에 의존 → 성능의 병목 현상
-
메모리 대역폭
: processor가 더 많은 processor를 동시에 처리하려면, memory로부터 data를 더 빠르게 가져와야 함
-
-
ෆ Processor scaling trend
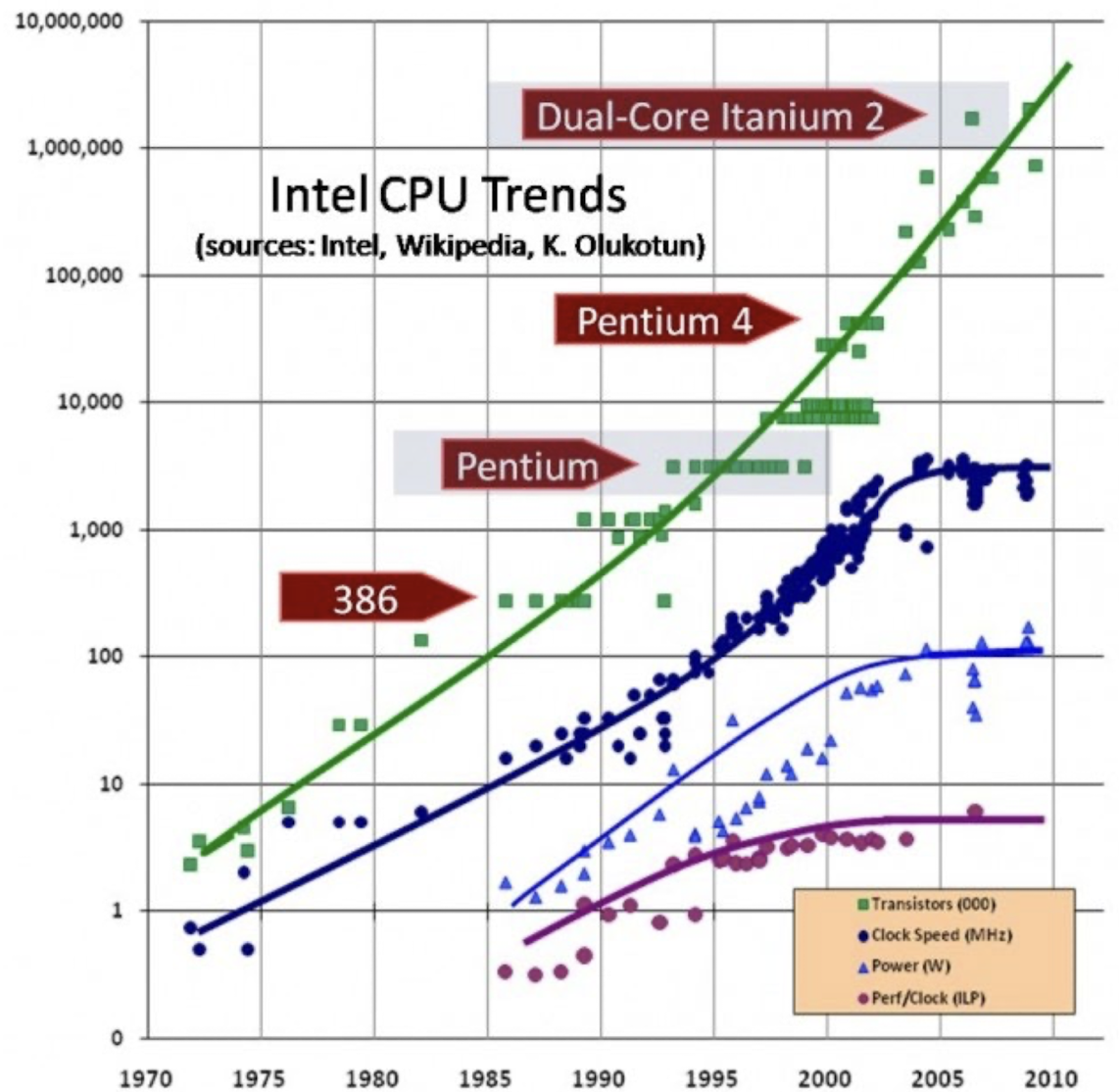
- 무어의 법칙 : 집적회로 내의 transistor 수가 약 18개월에서 24개월마다 2배로 증가한다는 관찰을 기반으로 함
→ 초기 몇십년 동안 processor 성능 향상의 주요 동력이었으나, 물리적 한계와 제조 비용의 증가로 인해 지속 가능한지 … - clock speed : processor가 초 당 수행할 수 있는 cycle 수
이 clock speed를 늘리는 것에 집중했으나, 높은 clock speed는 열 문제와 전력 소비 증가를 초래 - power : 효율적인 에너지 설계가 중요 .. (배터리 수명 .. 등) → 전력 소비를 줄이면서도 성능을 최적화 하는 방향으로 ..
⇒ multi-core , multi-threading
: clock speed 향상의 한계에 직면 (발열 문제)
→ 여러 개의 처리 core를 하나의 칩에 집적하는 multi-core processor !
- 단일 processor 내에서 parellel 처리가 가능해져 성능이 향상
- hyper-threading 같은 기술을 통해 core 당 여러 thread를 동시에 처리할 수 있음
❦ Multi-core processors (MIMD, Multiple Instruction Multiple Data)
ෆ Multi-core processor
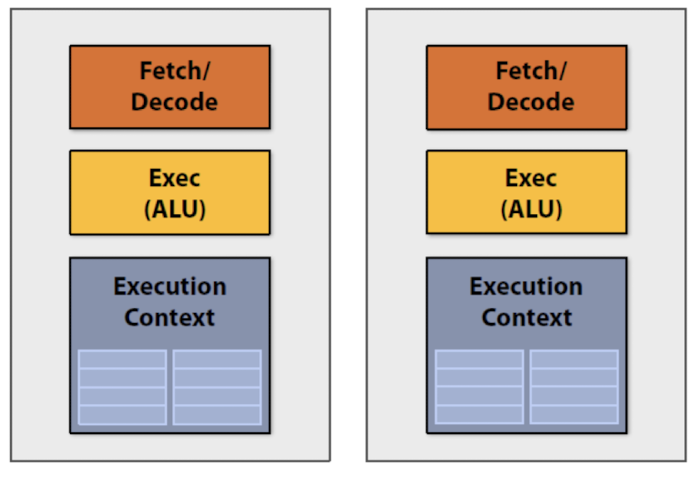
-
여러 개의 작업을 보다 효율적으로 처리하기 위해 2개 이상의 느린 processor가 붙어있는 ‘집적회로’
-
power가 증가되고 열 손실이 감소한 2개의 processing 엔진 > processing core가 하나일 자원이 부족한 칩
e.g. 80% clock frequency → 2 cores :

다시 돌아와서 .. multi-core processor에서 다음 코드를 돌린다고 가정하면,
오히려 드는 시간이 늘어나게 됨 ..
→ multi-thread와 같은 기법을 사용하지 않으면, core 한개가 노는 상태 ..
~ 결국 위 코드의 실행 시간은
⇒ thread를 이용해야 ..!
ෆ Thread
: process 내에서 process의 자원을 이용하여 실행되는 여러 흐름의 단위
: process 내에서 실제로 작업을 수행하는 주체
→ 운영체제의 스케줄러에 의해 독립적으로 관리될 수 있는 프로그래밍된 명령어의 가장 작은 시퀀스
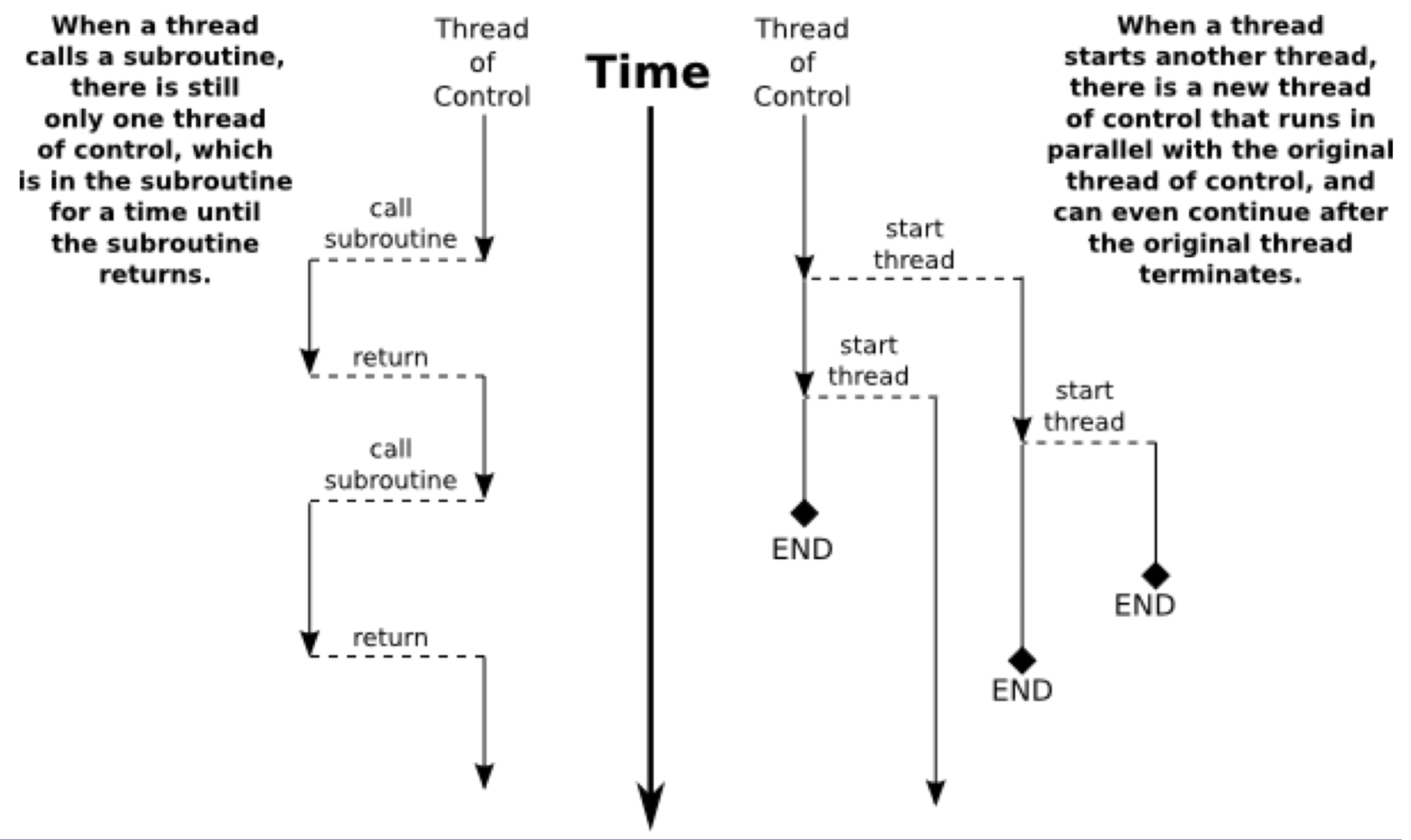
1. subroutine을 호출하는 경우
- subroutine : 프로그램 내에서 다른 부분에서 실행되는 코드 블록
- 현재 실행 중인 작업을 중단하고 해당 서브루틴으로 제어를 이동
- 서브루틴을 실행한 후 다시 호출한 지점으로 돌아와 작업을 계속할 수 있음
- 일반적인 함수 호출 방식과 유사한 방식
- 새로운 thread를 시작하는 경우
- 새로운 스레드가 현재 스레드와 병렬로 실행
→ 여러 작업을 동시에 처리 가능 - 새로운 스레드를 시작하는 작업은 일반적으로 다른 함수나 메소드 내에서 수행
→ 새로운 스레드의 실행을 시작하고, 해당 스레드가 실행될 함수 또는 코드 블록을 지정
ෆ Process VS Thread
-
process
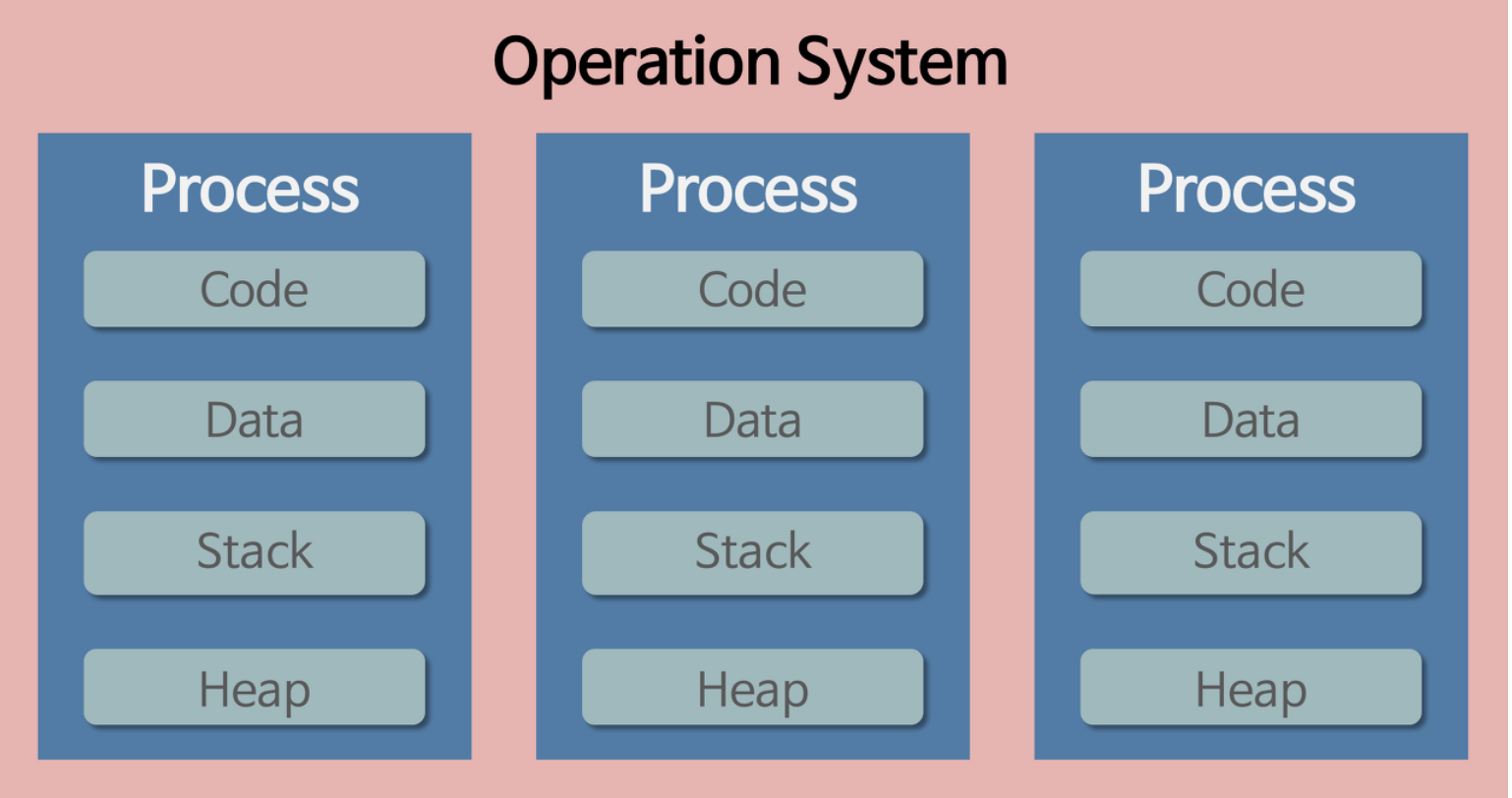
작업 중인 프로그램
-
process가 memory에 올라갈 때 OS로부터 시스템 자원을 할당받음
- process마다 각각 독립된 memory 영역
- 기본적으로 process끼리 다른 process의 memory에 직접 접근 불가
- Code/Data/Stack/Heap의 형식→ 한 프로세스를 실행하다가 오류가 발생해서 프로세스가 강제로 종료된다면, 다른 프로세스에게 어떤 영향이 있을까?
: 공유하고 있는 파일을 손상시키는 경우가 아니라면 아무런 영향을 주지 않는다.
-
-
thread
프로세스의 코드에 정의된 절차에 따라 실행되는 특정한 수행 경로
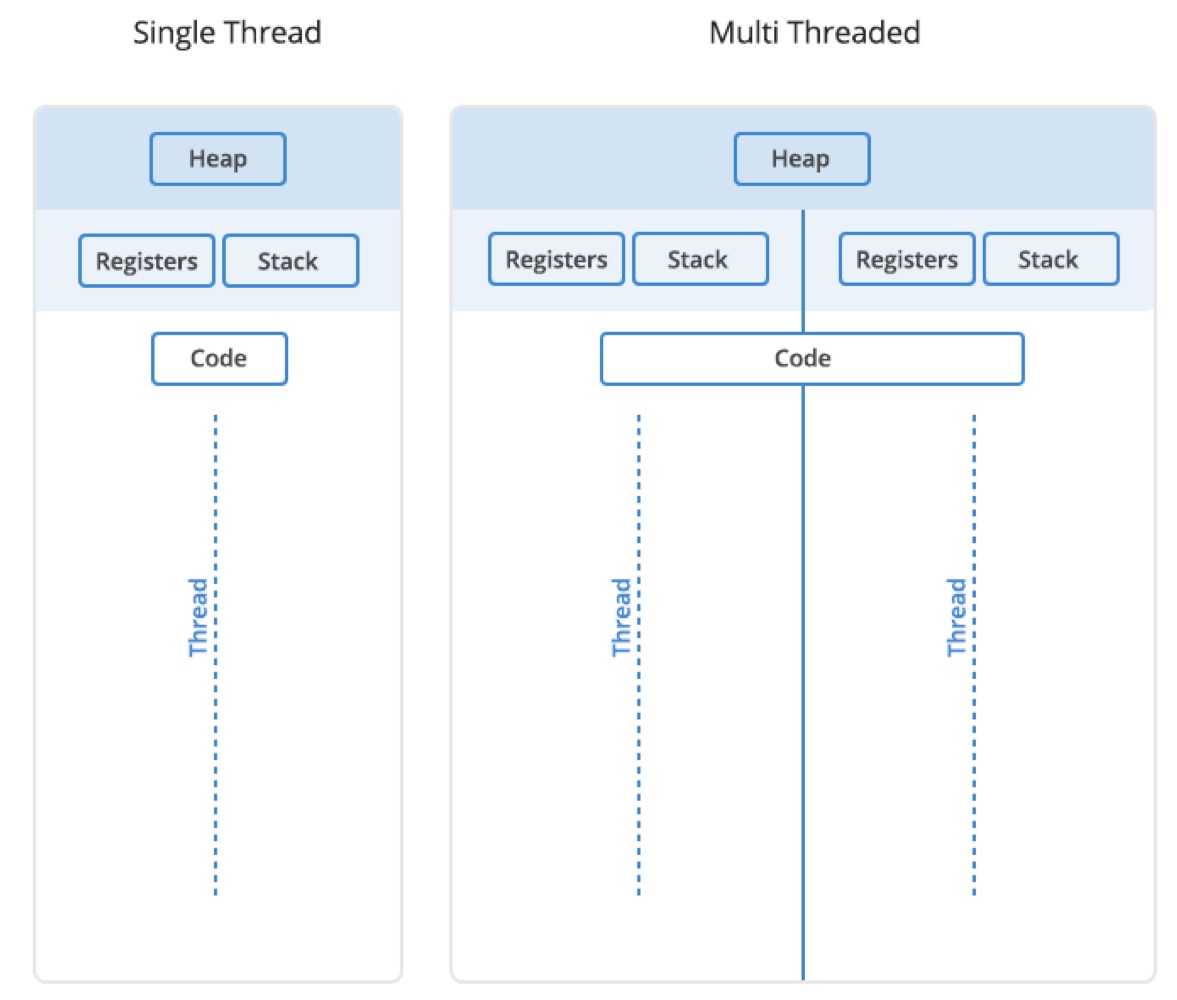
-
메모리를 서로 공유할 수 있음
- Code/Data/Heap 형식으로 할당된 메모리 영역을 공유
-
heap 메모리는 공유하기 때문에 서로 다른 스레드에서 가져와 읽고 쓸 수 있음
→ 어떤 스레드 하나에서 오류가 발생한다면 같은 프로세스 내의 다른 스레드 모두가 강제로 종료
-
- address space
- …
- Code/Data/Heap 형식으로 할당된 메모리 영역을 공유
-
공유되지 않는 resource
- Stack 형식으로 할당된 메모리 영역은 따로 할당
- stack: 함수 호출 시 전달되는 인자, 되돌아갈 주소값, 함수 내에서 선언하는 변수 등을 저장하는 메모리 공간
- 독립적인 스택을 가졌다 → 독립적인 함수 호출이 가능하다 → 독립적인 실행 흐름이 추가된다
- 독립적인 stack을 가짐으로써 thread는 독립적인 실행 흐름을 가질 수 있게 됨
- PC
- 각 스레드는 자체 프로그램 카운터를 가지고 다음에 실행할 명령어의 위치를 추적
- instruction이 같다면 PC 공유도 가능 .. 하긴 함
- register
- 각 스레드는 자체 레지스터를 가지고 데이터 및 연산을 처리
- instruction이 같아도 register는 공유 불가 → thread마다 다른 data를 다루기 때문 ,,
- Stack 형식으로 할당된 메모리 영역은 따로 할당
-
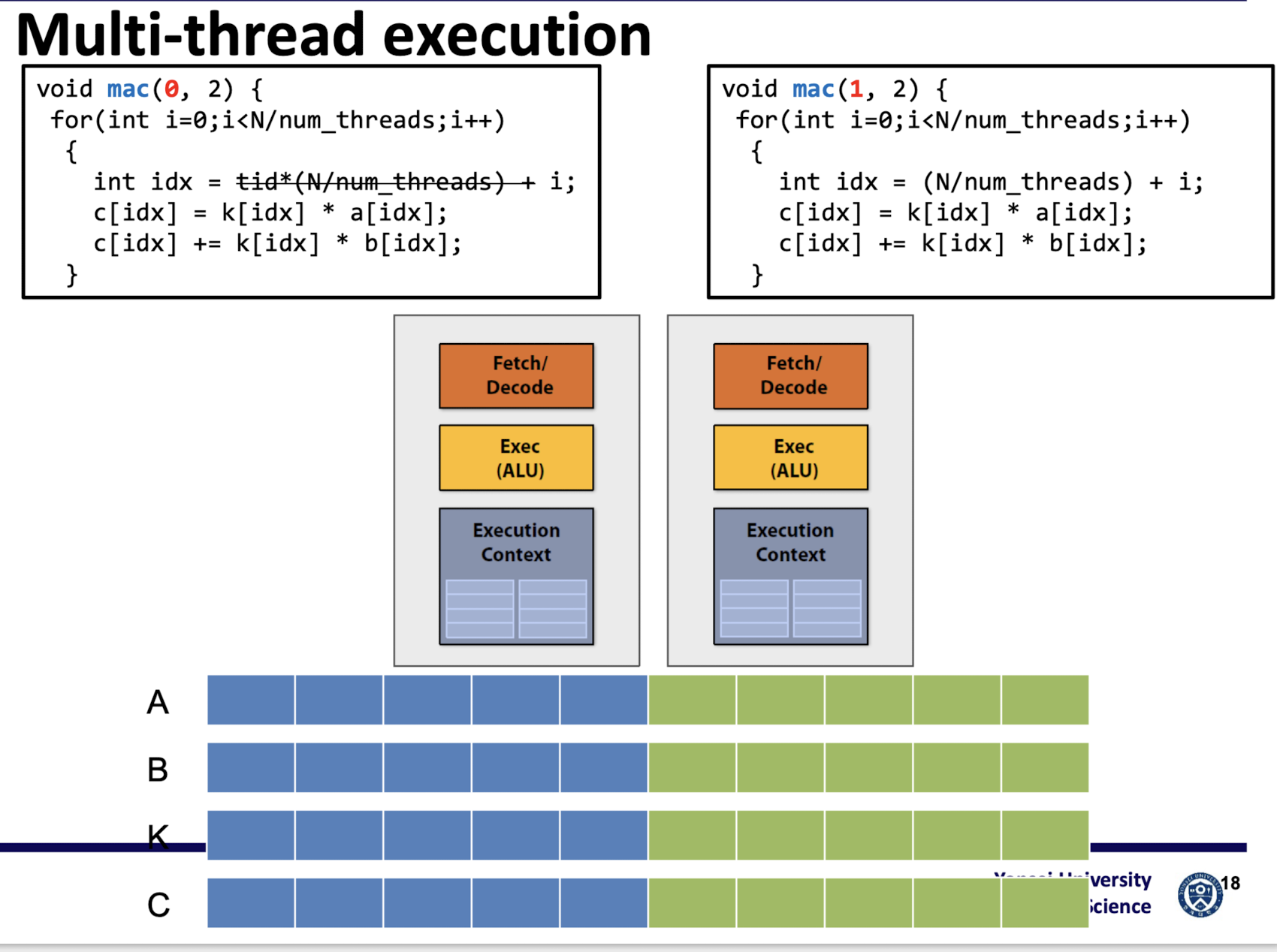
ෆ Example code
#include <iostream>
const int N = 100;
int main()
{
int a[N], b[N], k[N], c[N];
for(int i=0;i<N;i++) {
a[i] = i;
b[i] = 1000*i;
k[i] = 10;
c[i] = 0;
}
for(int i=0;i<N;i++) {
c[i] = k[i]*a[i];
c[i] += k[i]*b[i];
}
return 0;
}multi-thread program
#include <iostream>
#include <thread>
#include <vector>
// 정수 포인터를 선언하여 동적으로 할당된 배열을 가리키는 역할
int *a, *b, *k, *c;
// 벡터 연산을 수행하는 함수
// mac : multiply-accumulate, 주어진 두 배열을 곱하고 결과를 누적하는 역할
// tid : thread의 index, num_threads : 전체 thread의 수
void mac(int tid, int num_threads)
{
// 전체 vector의 크기를 전체 thread 수로 나누어 각 thread가 처리할 부분을 결정
for(int i=0;i<N/num_threads;i++)
{
// idx : 현재 thread가 처리할 index
int idx = tid*(N/num_threads) + i;
c[idx] = k[idx] * a[idx];
c[idx] += k[idx] * b[idx];
}
return;
}
int main(int argc, char* argv[])
{
...
// thread를 저장할 vector를 선언
std::vector<std::thread> threads;
// 전체 thread 수만큼 반복하면서 thread를 생성
for(int t=0;t<NT;t++) {
// 새로운 스레드를 생성하고 벡터 threads에 추가
// 각 스레드는 mac 함수를 호출하며, 스레드의 인덱스(t)와 전체 스레드 수(NT)를 전달
threads.push_back(std::thread(mac, t, NT));
}
// 모든 스레드가 종료될 때까지 대기
for(auto& thread: threads) {
thread.join();
}
return 0;
}
Data-Parallel expressions
병렬화를 위한 loop나 반복문을 쉽게 target으로 지정할 수 있는 개념
→ 프로그래머가 루프의 반복이 독립적이라고 선언하고, 해당 루프를 병렬로 실행할 수 있도록 지시
#include <iostream>
//const int N = 1000000;
#defiine N 1000000000LL
int main()
{
...
#pragma omp parallel for
for(long long int i=0;i<N;i++) {
c[i] = k[i]*a[i];
c[i] += k[i]*b[i];
}
return 0;
}- 각 반복이 다른 반복과 독립적으로 실행될 수 있는 경우
: 독립성을 활용하여 병렬 처리를 수행 - 이러한 독립적인 반복을 탐지하고, 해당 반복을 여러 스레드로 병렬화하여 동시에 실행할 수 있는 코드를 생성
- OpenMP : data-parallel expression을 사용하여 loop를 병렬화
-
프로그래머는 OpenMP의 지시문을 사용하여 루프가 독립적임을 선언
-
OpenMP는 해당 지시문을 해석하여 루프를 병렬로 실행하는 코드를 생성
→ 프로그래머는 직접 thread를 관리하지 않고도 병렬 처리를 수행할 수 있음
-
❦ Vector processing (SIMD, Single Instruction Multiple Data)
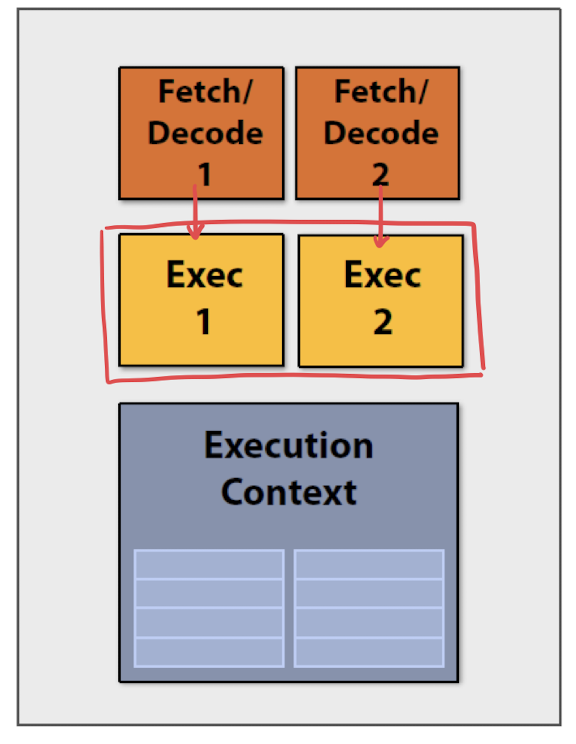
ෆ Multicore processor의 Fetch/Decode 부분이 여러 개여야 하는가 ,,
이전의 예시에서
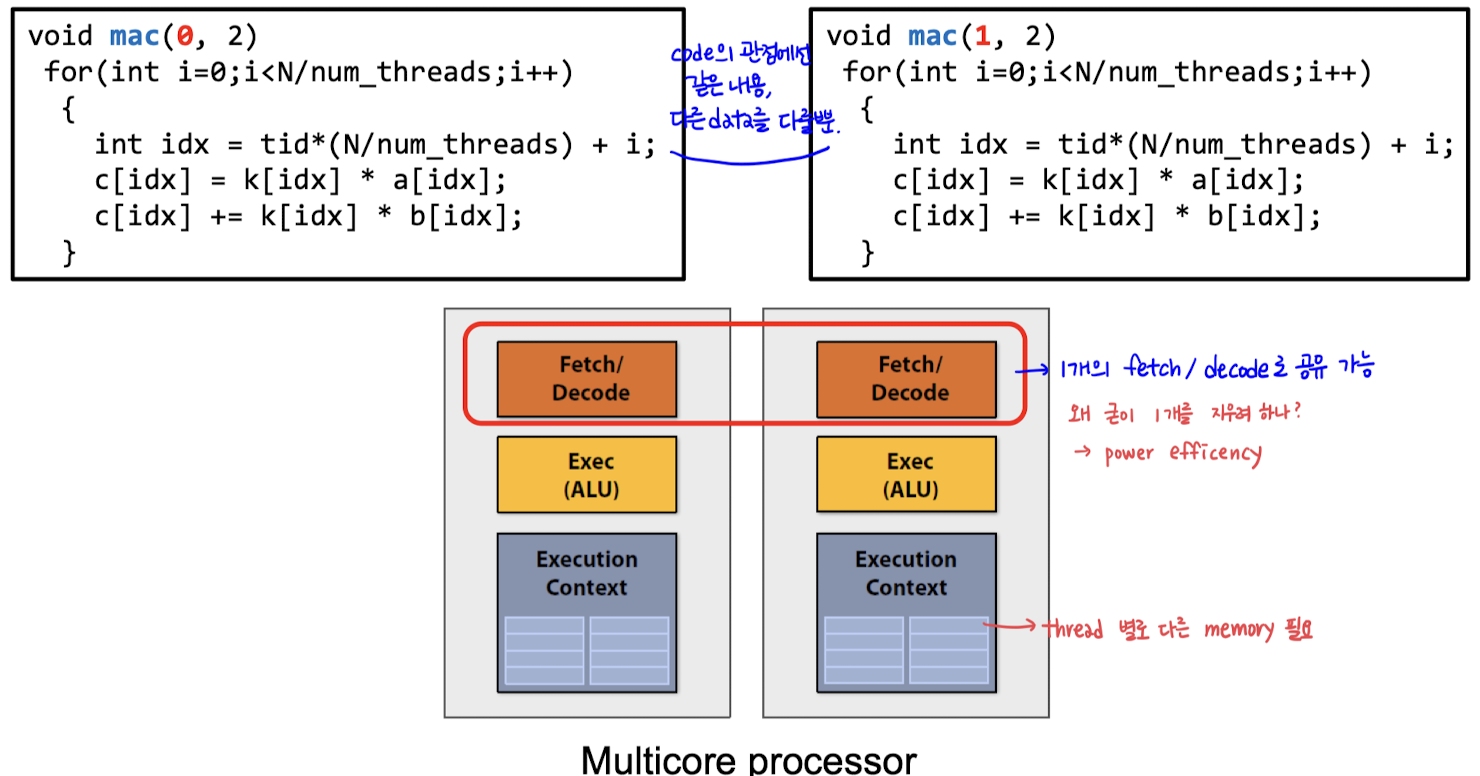
- 위의 코드가 정확히 같은 code, data만 다른 data를 다루는 것
→ fetch/decode가 꼭 2개의 unit일 필요가 없음 : Vector processing !
- execution context는 2개의 unit 이어야 함
- thread별로 각각 다른 memory가 필요하기 때문 ..
ෆ Vector processing
- 하나의 instruction을 통해 여러 개의 data 요소를 동시에 처리하는 기술
하나의 명령어가 여러 개의 데이터 요소에 대해 동시에 작업을 수행할 수 있도록
→ 하나의 명령어가 다수의 연산장치(ALU)에서 동시에 실행되도록 : 병렬성 ↑, 연산량 효율적으로 처리
#include <immintrin.h>
#pragma omp parallel for
for(long long int i=0;i<N;i+=8) {
// __m256i : 256비트(32바이트)크기의 정수형 벡터를 나타내는 데이터 타입
// _mm256_load_si256 : AVX register에 data load
__m256i A = _mm256_load_si256((__m256i*)(&a[i]));
__m256i B = _mm256_load_si256((__m256i*)(&b[i]));
__m256i K = _mm256_load_si256((__m256i*)(&k[i]));
// _mm256_mullo_epi32 : 두 개의 256비트 정수형 벡터의 각 요소를 곱한 결과를 반환
__m256i C1 = _mm256_mullo_epi32(A,K);
__m256i C2 = _mm256_mullo_epi32(B,K);
// _mm256_add_epi32 : 두 개의 256비트 정수형 벡터의 각 요소를 더한 결과를 반환
__m256i C = _mm256_add_epi32(C1,C2);
// _mm256_store_si256 : AVX register의 데이터를 메모리에 저장
_mm256_store_si256((__m256i*)(&c[i]), C);
}
return 0;
}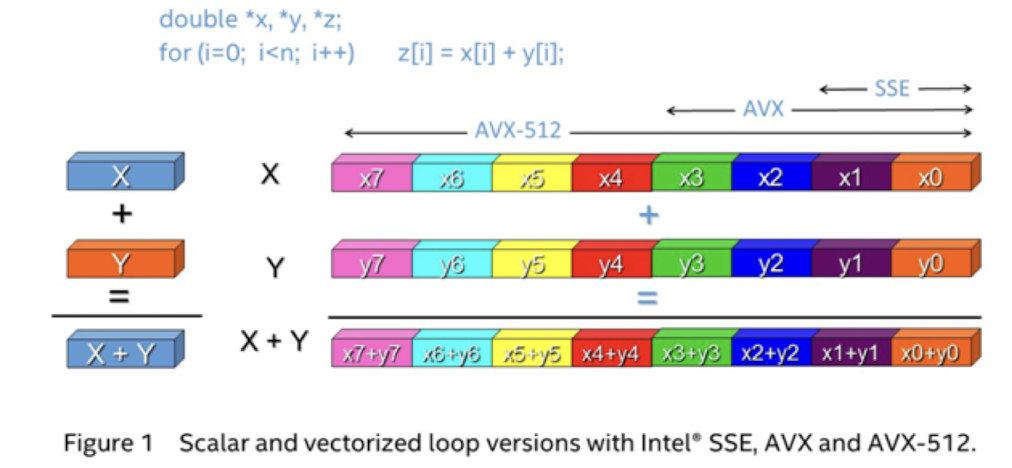
- SSE(Streaming SIMD Extensions)
- 128비트 SIMD 명령어 세트 : 432비트, 264비트
- 이전의 기본 x86 명령어 세트를 확장하여 추가된 기능
- AVX2(Advanced Vector Extentions 2)
- 256비트 SIMD 명령어 세트 : 832비트, 464비트
- SSE의 확장으로, 더 많은 데이터를 한 번에 처리할 수 있도록 하여 성능을 향상
- AVX-512
- 512비트 SIMD 명령어 세트 : 1632, 864
- AVX2의 확장으로, 더 많은 데이터를 한 번에 처리할 수 있어서 더 높은 성능을 제공
- 컴파일러는 코드를 분석하여 병렬성을 추론하고 필요한 경우에는 자동으로 SIMD 명령어를 생성
- 프로그래머가 직접 SIMD 명령어를 사용하고 싶은 경우→ ntrinsics(인트린식)라는 특별한 함수를 사용 (위의 코드 예시 참고) → 성능을 더욱 향상시킬 수 있음
Conditional execution ?
벡터 처리에서 조건부 실행을 구현하는 방법
⇒ Predication : Masking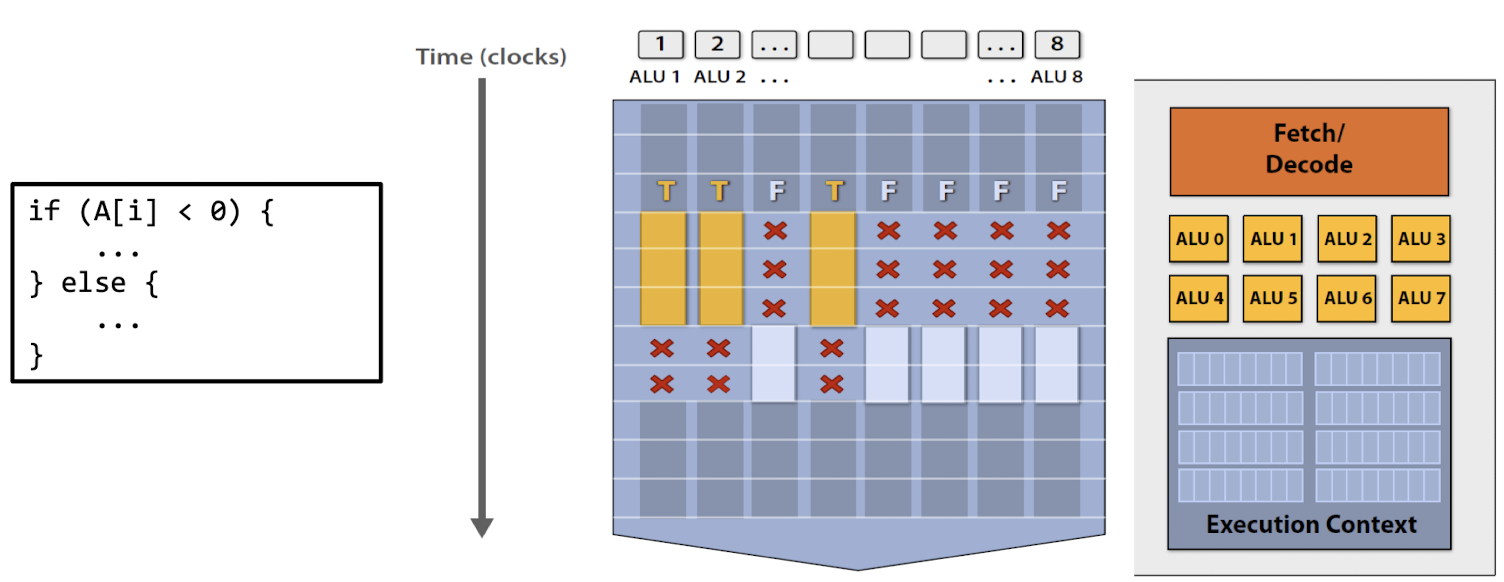
- SIMD instruction을 사용하여 조건을 확인
- 해당 조건이 참(True)일때만 연산을 수행
- 해당 연산에 대한 마스크 설정 → 해당 연산이 실행되도록 ,,
- 해당 조건이 거짓인 경우 연산을 건너뜀
- 해당 연산에 대해 마스크를 설정하지 않음 → 해당 연산이 무시되도록 ,,
- 전체적인 연산량에 대한 이점을 제공
but! 일부 연산은 실제로는 실행되지 않으므로 이로 인해 하드웨어의 이용률이 낮아질 수 있음
⇒ 마스킹을 사용하면 일부 ALU(산술 논리 장치)가 실제로는 유휴 상태일 수 있다 ,,
- GPU(Graphic Processing Unit)에서도 마스킹 기술이 널리 사용됨
❦ 정리
ෆ SISD : Single Instruction, Single Data
- Scalar processor
- Superscalar processor
ෆ MIMD : Multiple Instruction, Multiple Data
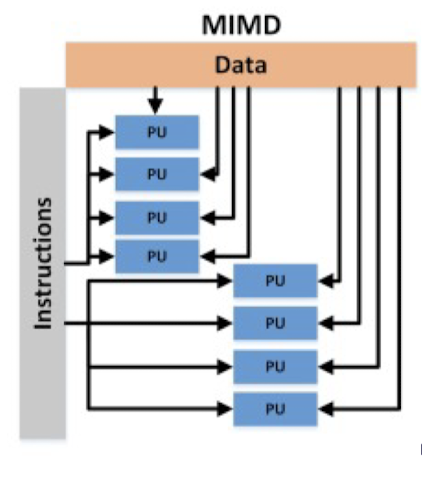
- Multi-core processor
ෆ SIMD : Single Instruction, Multiple Data
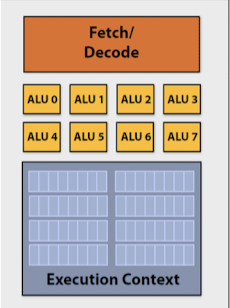
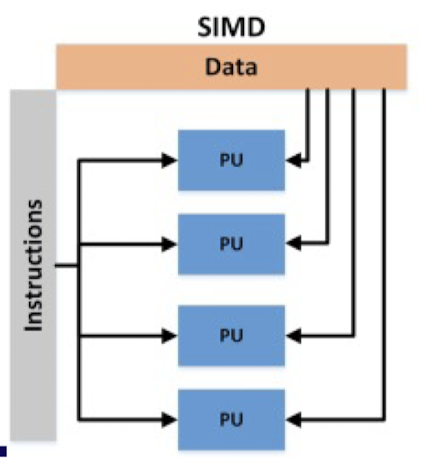
- Vector processor
ෆ MISD : Multiple Instruction, Single Data
일반적으로 병렬성을 향상시키는 데 사용되지 않음
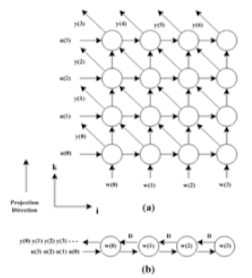
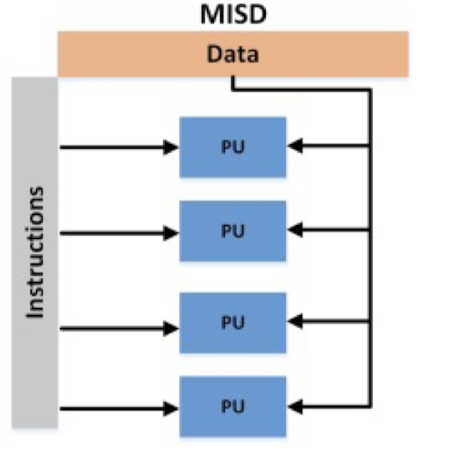
→ 특정 유형의 작업에 최적화된 특수 목적 프로세서에서 사용
- Systolic Array
- 여러 개의 프로세서 코어가 특정한 데이터 스트림을 따라 일련의 연산을 수행하는 구조
- 주로 행렬 곱셈과 같은 수치 연산에서 사용
- Google TPU
- 대규모 딥러닝 모델의 추론 및 학습을 가속화하기 위해 설계
- 그리고 많은 다른 NPU(Neural Processing Unit)
- NPU : 인공 신경망을 실행하고 가속화하기 위해 설계된 전용 하드웨어 장치

잘 보고 갑니다~