
❦ Programming model
Parallel programming에서 programming model은 프로그래머에게 communication abstraction을 제공
→ 프로그래머가 컴퓨터 시스템의 병렬성을 이해하고 활용할 수 있게 도와줌
- Shared Memory Model
- 모든 process/thread가 동일한 주소 공간을 공유
- 데이터를 공유하는 것이 가능
- process/thread간의 communication은 주로 공유된 변수 또는 데이터 구조를 통해 이루어짐
- 대부분의 multi processor system/ multi-core processor에서 사용
- ex. OpenMP : Shared Memory Model을 기반으로 구현되어 있음
- 프로세스 또는 스레드 간의 데이터 공유를 편리하게 처리
- 데이터의 일관성과 동기화에 대한 관리가 필요
- 모든 process/thread가 동일한 주소 공간을 공유
- Message Passing Model
- process간 communication을 위해 명시적으로 message를 주고 받는 방식
- 각 process는 자체적으로 독립적인 주소 공간을 가짐
- 분산 시스템에서 주로 사용
- 대규모 cluster 또는 분산 컴퓨팅 환경에서 process간 통신이 필요한 경우 유용
- ex. MPI (메시지 패싱 라이브러리)
- 명시적인 통신을 통해 분산 환경에서의 효과적인 상호 작용
- 통신 비용과 병목 현상에 대한 관리가 필요
- process간 communication을 위해 명시적으로 message를 주고 받는 방식
ෆ Shared memory model
ಌ Memory
address를 통해서 접근(읽기 및 쓰기)할 수 있는 byte의 집합
데이터와 명령어를 저장하고 접근하는 장치
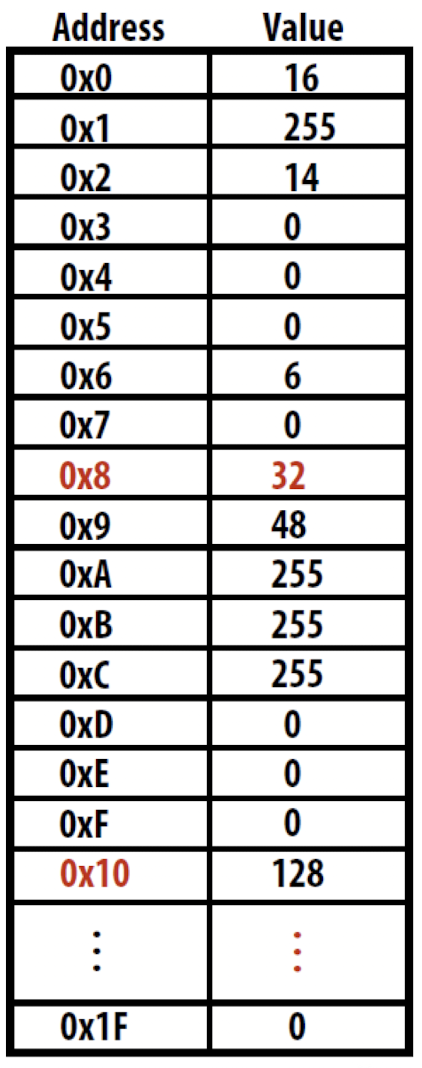
- 0x8 에 32가 저장되어 있음
- 0x10에 128이 저장되어 있음
- 주로 byte 단위로 주소 지정이 이루어짐
⇒ CPU와 Memory의 구조는?
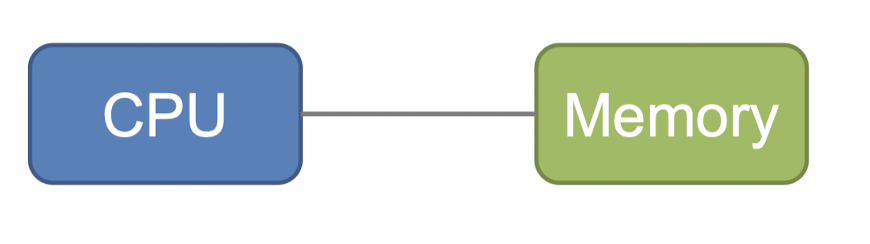
- Von Neumann 아키텍쳐
-
Single data bus
CPU와 memory간에 단일 데이터 버스가 존재
→ 이 bus를 통해 CPU는 memory로부터 명령어와 데이터를 읽거나 쓸 수 있음
-
Single Storage
프로그램의 명령어와 데이터는 동일한 메모리에 저장
프로그램의 구조를 단순화하고 프로그램의 유연성을 높임
-
Instruction and Data Separation
프로그램 명령어와 데이터는 동일한 메모리에 저장되나, CPU는 명령어와 데이터를 구분하여 처리
CPU는 PC를 사용하여 메모리에서 다음에 실행할 명령어의 위치를 추적
-
Sequential Instruction Execution
프로그램은 순차적으로 실행
CPU는 메모리에서 한 번에 하나의 명령어를 가져와 실행
→ 프로그래밍의 단순성을 유지하고 복잡성을 줄임
-
- 그럼 multi-core CPU는 ??

⇒ 하지만 실제로는 ,, : Memory hierarchy
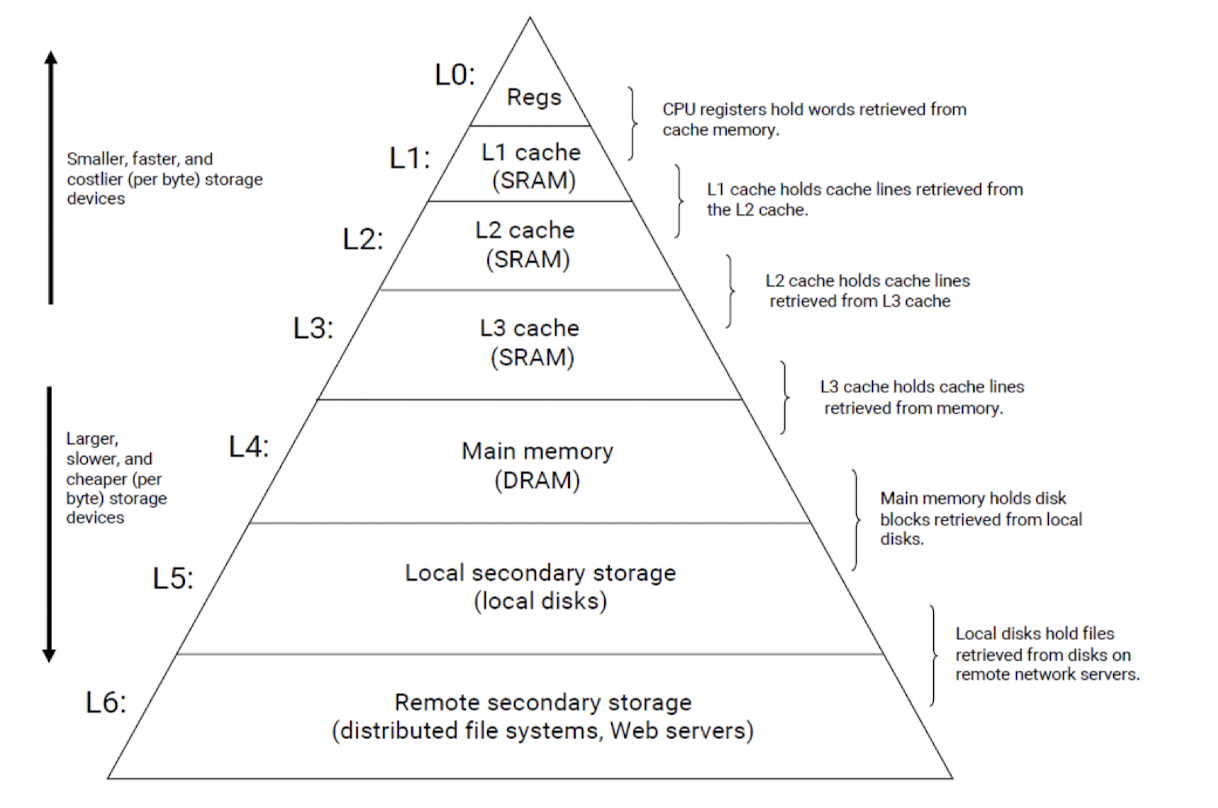
상위 계층 : 일반적으로 빠른 접근 속도 제공
하위 계층 : 더 큰 용량을 제공
- Register
: cache memory에서 검색된 단어를 저장 - Cache
- L1 : L2 cache에서 검색된 cache line을 저장
- L2 : L3 cache에서 검색된 cache line을 저장
- L3 : memory에서 검색된 cache line을 저장
- Main memory
: local disk에서 검색된 disk block을 저장 - Secondary Storage
: 원격 network server의 disk에서 검색된 file을 저장
ಌ Shared address space
- 각 thread는 동일한 process 내에서 실행
- memory에 접근 시 동일한 address space를 공유 → 여러 thread가 동일한 address space를 공유하면 하나의 thread가 해당 address에 쓴 내용을 다른 thread가 볼 수 있음
- 한 thread가 address space에 값을 쓰면, 이 값이 다른 모든 thread에게도 즉시 반영
- mutual exclusion (상호 배제)를 필요로 함
- 여러 thread가 동시에 memory에 access 하는 것을 방지 → data의 일관성과 무결성 보장
- 여러 thread가 동시에 memory에 access 하는 것을 방지 → data의 일관성과 무결성 보장
- Hardware적 지원이 필요
- core간의 interconnect
- 시스템이 확장되면서 발생 가능한 확장성 문제
- 캐시 일관성
- …
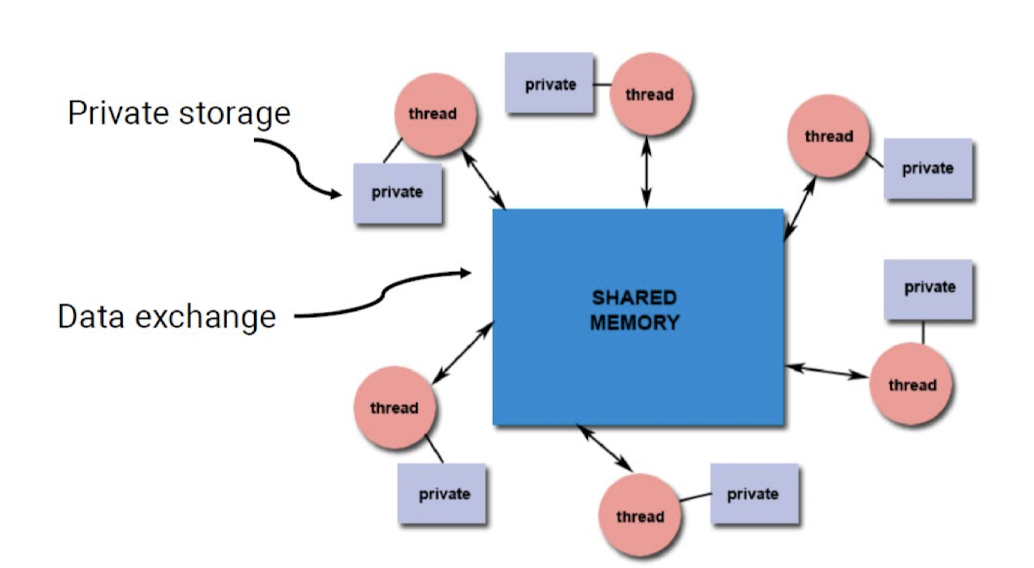
- “Dance-hall” organization
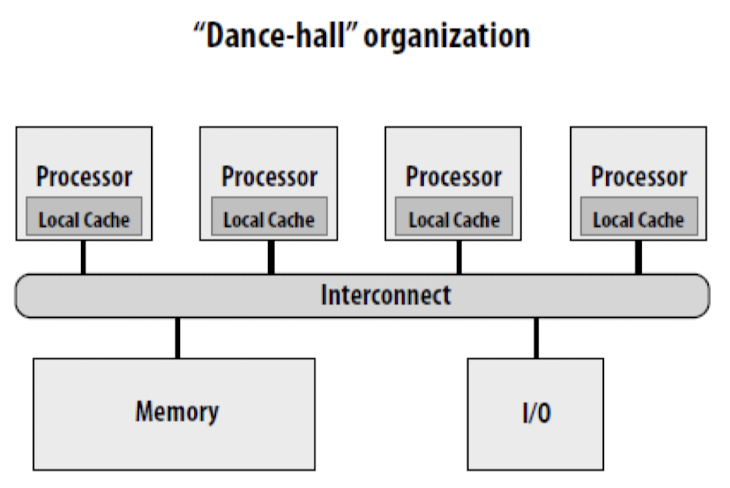
여러 스레드가 자유롭게 데이터를 교환하고 공유
- 메모리 주소 공간의 각 부분이 다수의 스레드에 의해 공유
- 스레드 간의 데이터 공유와 통신이 쉽게 이루어질 수 있도록 설계
- Interconnect examples
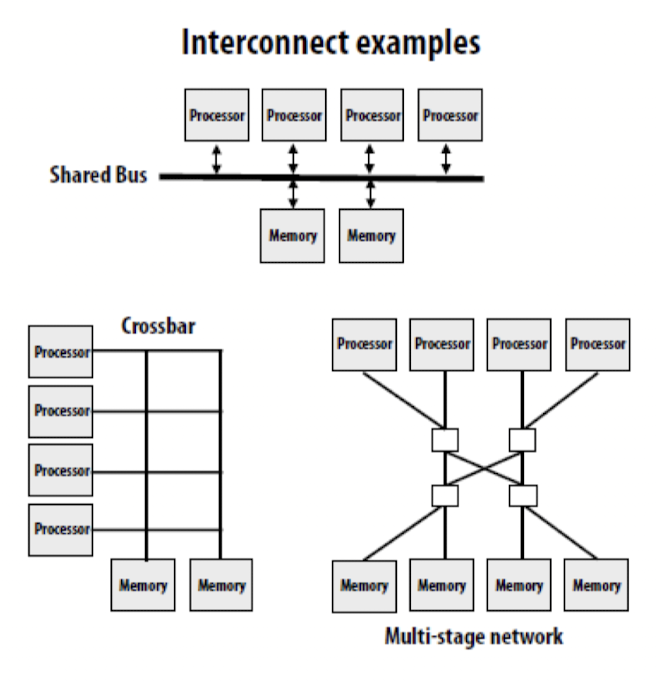
- 스레드 간 통신을 위한 인터커넥트(Interconnect) 구조
- 인터커넥트는 다수의 프로세서 또는 코어 간의 통신을 지원하기 위한 통신 경로 및 프로토콜을 제공
- 인터커넥트는 스레드 간의 데이터 전송과 동기화를 지원하며, 고성능 및 효율적인 데이터 교환을 가능
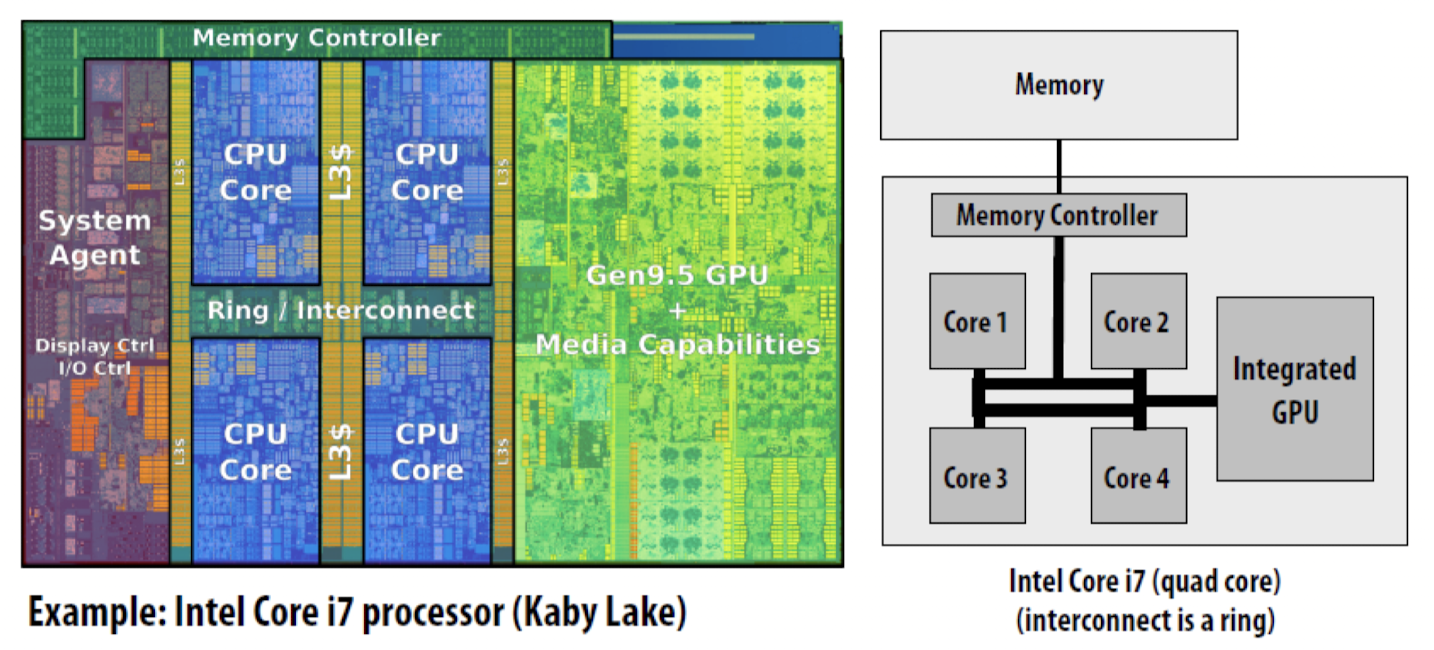
- ex 1 : intel core i7 (Kaby Lake)
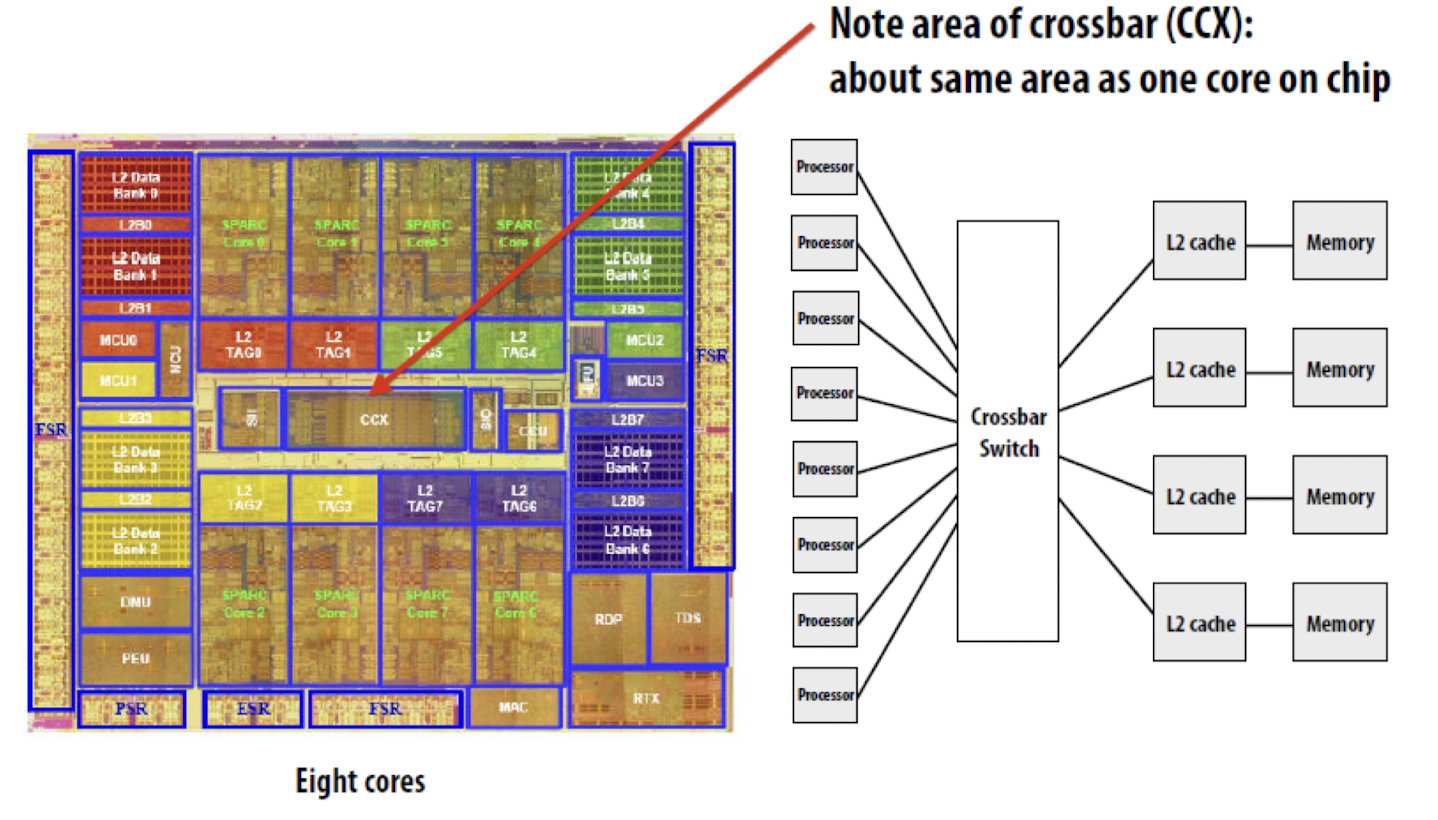
- ex 2 : sun Niagara 2
ಌ Shared memory UMA (Uniform Memory Access)
- 균일 기억 장치 접근
- 모든 processor들이 상호간에 연결되어 하나의 메모리를 공유하는 기술
- processor들은 memory의 어느 영역 이던지 접근이 가능하며, 모든 processor가 걸리는 시간이 동일
- 구조가 간단하고, 프로그래밍 하기는 쉬우나, 메모리에 한번에 하나씩의 연결만 가능하여, 커지면 커질수록 효율성이 떨어짐
ಌ Shared memory NUMA (Non-Uniform Memory Access)
-
메모리에 접근하는 시간이 processor와 memory의 상대적인 위치에 따라 달라짐
- local memory access (로컬 메모리에 접근) vs remote memory access (원격 메모리 접근) → 서로 다른 지연 시간을 가짐
- local memory access : 각각의 CPU마다 memory를 가지고 있는 구조에서 memory에 접근하는 경우
- remote memory access : CPU와 memory를 합쳐 node를 구성 → 자신의 memory가 아닌 다른 node의 memory 접근하는 경우
- local memory access : 각각의 CPU마다 memory를 가지고 있는 구조에서 memory에 접근하는 경우
- local memory access (로컬 메모리에 접근) vs remote memory access (원격 메모리 접근) → 서로 다른 지연 시간을 가짐
-
물리적인 interconnects로 인해 발생하는 지연(latency)및 대역폭(bandwidth) 불균형
-
성능 저하의 원인
-
동일한 주소 공간 내에서 발생
⇒ first touch 정책
-
memory가 처음으로 access 될 때 해당 memory를 local memory에 할당하는 정책
-
각 processor가 가능한 한 local memory에 access하여 지연 시간과 대역폭 불균형을 최소화
⇒ 메모리 할당을 수동으로 제어 : munactl 유틸리티
-
-membind: 메모리를 할당할 노드를 정의합니다.
-
-cpunodebind: 사용할 NUMA 노드를 지정합니다.
-
-physcpubind: 사용할 CPU를 선언합니다.
-
-interleave: 메모리 할당에 대한 interleaving 정책을 사용합니다.
-
→ 메모리 및 CPU 할당을 세밀하게 제어하여 성능을 최적화
-
-
ex. modern dual socket machine
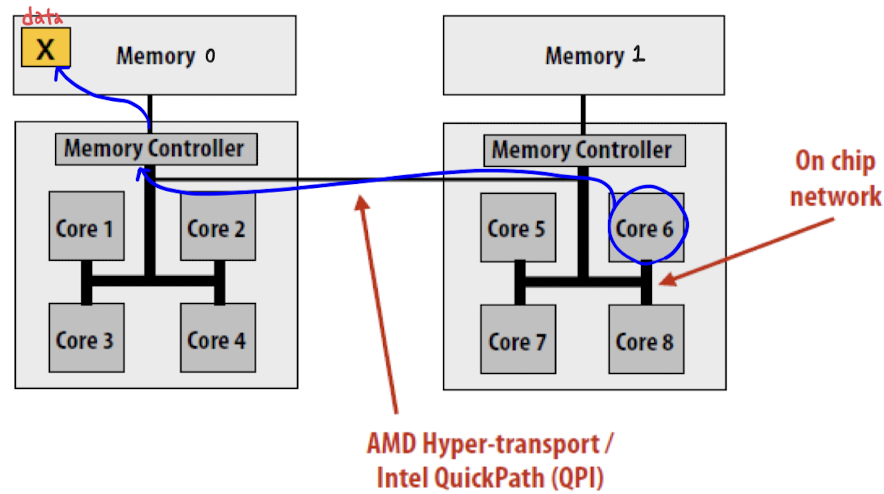 core 6에서 data x에 접근해야 한다면 ,,
core 6에서 data x에 접근해야 한다면 ,,
sol 1 : data x를 Memory 1에 위치하게 함
sol 2 : core 6에서 하는 일을 core 1이 하게끔 함 -
thread migration
: processor가 thread를 중지하고 현재 상태 저장 → 다른 core에서 thread를 다시 시작 → 이전 상태 복원
