
❦ Thread
ෆ Create & Join & Detach
#include <iostream>
#include <thread>
#include <vector>
int *a, *b, *k, *c;
void mac(int tid, int num_threads)
{
for(int i-0;i<N/num_threads;i++)
{
int idx = tid*(N/num_threads) + i;
c[idx] = k[idx] * a[idx];
c[idx] += k[idx] * b[idx];
}
return;
}
int main(int argc, char* argv[])
{
...
std::vector<std::thread> threads;
for(int t=0;t<NT;t++) {
// create thread
threads.push_back(std::thread(mac, t, NT));
}
for(auto& thread: threads) {
// wait for finish
thread.join();
// don't want to wait for finish ..
//thread.detach();
}
return 0;
}ಌ Create
std::thread(mac, t, NT)
- 새로운 thread를 생성하는 데에 사용되는 코드
- 새로운 thread 객체 생성
- 해당 thread에서 실행될 작업 지정 가능
mac: 호출 가능한 객체 (callable)- callable : thread에서 실행될 작업을 정의하는 함수
- 별도의 thread에서 실행됨
t,NT:mac에 전달되는 인수
ಌ Join
thread.join();
- thread는 호출 가능한 객체가 반환될 때까지 기다린 뒤 반환
- 호출 가능한 객체가 실행을 완료하면 해당 thread가 종료
- 위의 코드는 호출한 thread가 대상 thread가 종료될 때까지 기다림
- 이 method를 호출한 thread는 대상 thread가 종료될 때까지 블록됨 → 여러 thread간에 작업의 실행 순서 조절, thread들의 실행 동기화
- 이 method를 호출한 thread는 대상 thread가 종료될 때까지 블록됨 → 여러 thread간에 작업의 실행 순서 조절, thread들의 실행 동기화
- thread가 이미 join되었는지 여부 확인 :
thread.joinable();
- 부울 값을 반환
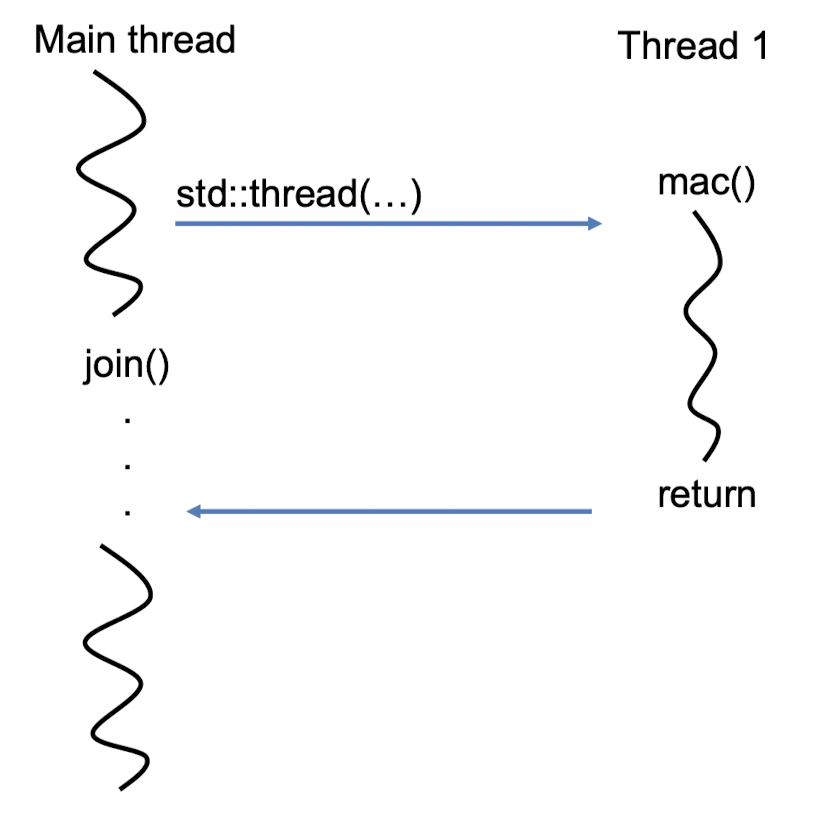
join();- 부모 thread가 생성한 자식 thread가 종료될 때까지 대기
- 부모 thread는 자식 thread의 종료를 기다림
- 자원을 정리하거나 결과를 처리할 수 있음
- 부모 thread가 생성한 자식 thread가 종료될 때까지 대기
ಌ Detach
thread.detach();
- 스레드가 호출 가능한 객체가 반환될 때까지 기다리지 않고, 스레드의 실행을 기다리지 않고 다른 작업을 수행하고 싶다면, 스레드의 실행을 조인하지 않으면 됨
- 스레드가 호출 가능한 객체가 반환될 때까지 기다리지 않고 실행을 계속하면, 스레드의 실행이 끝나지 않았더라도 호출 가능한 객체가 반환될 때까지 기다리지 않고도 다른 작업을 수행할 수 있음
- 호출 가능한 객체가 반환되기 전에 해당 스레드의 리소스가 정리되지 않을 수 있음
- 메모리 누수나 예기치 않은 동작이 발생할 수 있음
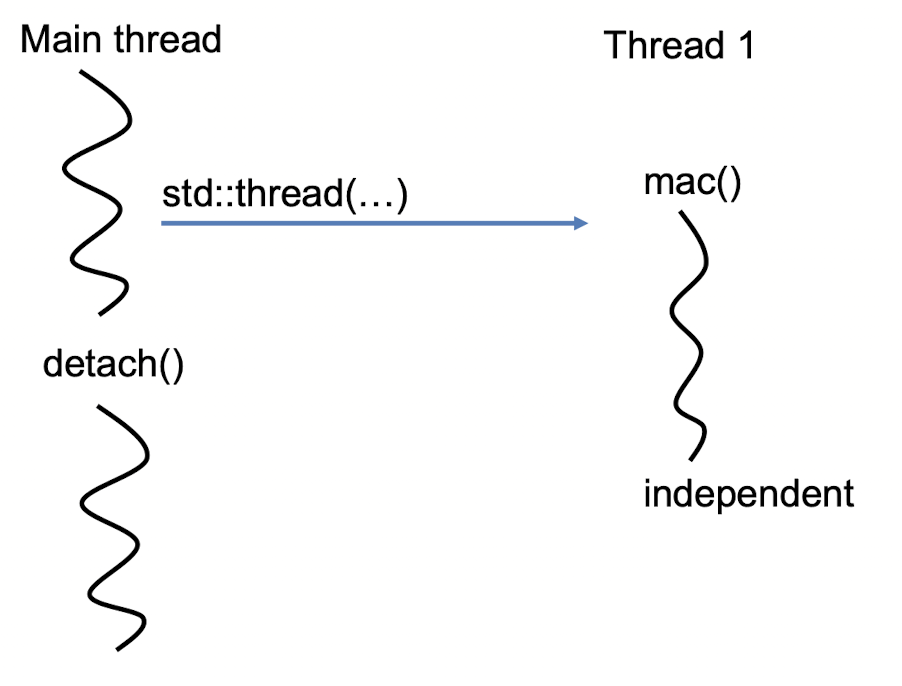
detach();- 부모 thread가 생성한 자식 thread가 독립적으로 실행
- 부모 thread는 자식 thread의 종료를 기다리지 않음
- 자원을 자식 thread에게 넘기고 별도의 작업 수행 가능
- 부모 thread가 생성한 자식 thread가 독립적으로 실행
- 만약 부모 thread가 자식 thread에게 할당한 자원을 정리하지 않고
detach()를 호출하지 않는다면?- 자식 스레드가 종료될 때까지 부모 스레드는 해당 자원을 계속해서 유지 → 메모리 누수와 같은 문제 발생
- 자식 스레드가 종료될 때까지 부모 스레드는 해당 자원을 계속해서 유지 → 메모리 누수와 같은 문제 발생
ಌ Callable
호출 가능한 객체 : 함수처럼 호출될 수 있는 객체
1. Function pointer
void mac(..params..)
{...}
...
std::thread(mac, ..params..)- 함수의 memory address를 가리키는 pointer
- 함수의 이름 또는 주소를 가리킴
2. Function object
class set_object
{
public;
void operator()(int* target)
{
*target = 1;
}
};
int main()
{
std::thread t(set_object(), &a);
}- 클래스 객체로서 operator() 멤버 함수를 구현함으로써 호출 가능한 객체를 만듦
- 함수처럼 호출될 수 있으며, 상태(state)를 유지할 수 있음
- 함수 pointer보다 유연하고 풍부한 기능 제공
3. Lambda expression
int b = 0;
std::thread t2([](int* target) {
*target = 1;
}, &b);
t2.join();- 익명 함수를 생성하는 간결한 방법
- 함수처럼 호출되며, 함수 객체를 만듦
- 주로 간단한 코드 조각 표현 시 사용
❦ Race Condition
동시에 여러 thread나 process가 shared resource에 접근할 때 발생
주로 Read-Modify-Write 연산이 동시에 수행될 때 발생
문제는 Read-Modify-Write 연산이 여러 thread에 의해 동시에 실행될 수 있고, 이들의 실행 순서가 보장되지 않는다는 것 ,,→ 하나의 thread가 Read 연산을 수행하는 동안, 다른 thread가 그 값을 Modify하거나 Write 연산을 수행할 수 있음
#include <iostream>
#include <thread>
#include <vector>
void worker(int* input, int start, int size, int* output)
{
for(int i=0;i<size;i++) {
if(input[start+i]==0 {
(*output)++;
}
}
}
int main(int argc, char* argv[])
{
const int N = atoi(argv[1]);
const int NT = atoi(argv[2]);
int *array = new int[N];
for(int i=0;i<N;i++) {
array[i] = 0;
}
int count=0;
std::vector<std::thread> threads;
for(int t=0;t<NT;t++) {
//assume N is a multiple of NT
int size=N/NT;
int start = t*size;
threads.push_back(std::thread(worker,array,start,size,&count));
}
for(auto& thread:threads) {
thread.join();
}
std::cout<<"there are "<<count<<"zeros"<<std::endl;
}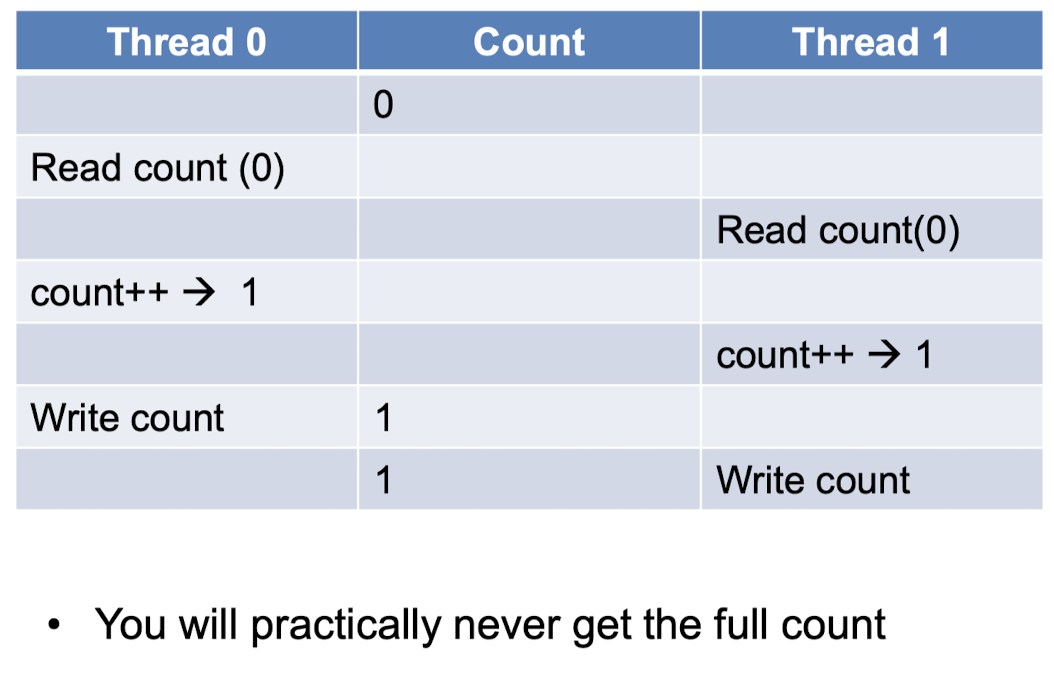
⇒ 결과는 thread들 간의 race condition에 따라 달라지게 됨
(thread가 자원에 접근하는 순서와 타이밍에 따라 결과가 달라질 수 있음)
race condition은 예측할 수 없는 결과를 초래하며, 디버그하기 어렵고 심각한 버그를 유발할 수 있음
→ 적절한 동기화 메커니즘을 사용 ~> 공유 자원에 대한 접근 제어, 경쟁 조건을 회피하거나 방지
ෆ Mutex
상호 배제(mutual exclusion)를 제공하는 동기화 기법 중 하나
여러 thread간에 공유된 resource에 대한 안전한 접근을 보장
-
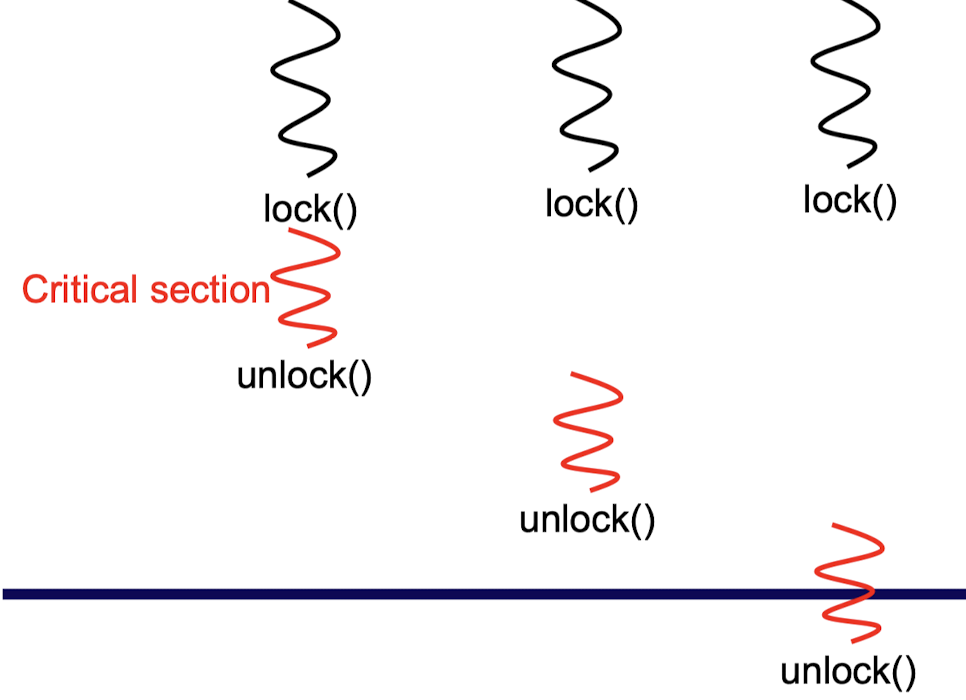
critical section (임계 영역)
: 상호 배제(mutaual exclusion)를 필요로 하는 코드 영역
→ 여러 thread가 동시에 접근하면 안 되는 공유 자원에 대한 접근을 제한하는 코드 부분
- 공유된 자원을 업데이트하거나 수정하는 코드 영역
- 여러 thread가 동시에 critical section에 접근하면, 경쟁상태가 발생할 수 있어 데이터의 일관성이 깨질 수 있음 → 한 번에 단 하나의 thread만이 critical section에 접근할 수 있도록 상호 배제 매커니즘 사용
-
locked 상태
mutex가 잠겨 있는 상태, 이 때 mutex를 소유한 thread만이 공유 자원에 접근 가능
- 오직 하나의 thread만이 lock을 획득할 수 있도록 보장
- 다른 thread가 mutex를 lock하려고 시도하면, 해당 thread는 mutex가 unlock될 때까지 대기해야 함
- → 여러 thread간에 공유된 자원에 대한 안전한 접근이 보장됨
-
unlocked 상태
mutex가 잠금 해제된 상태, 다른 thread가 mutex를 잠글 수 있게 됨
std::mutex global_mutex;
void inc(int* output)
{
global_mutex.lock;
(*output)++; //critical section
global_mutex.unlock(); //FORGOT TO UNLOCK?
}
void worker(int* input, int start,
int size, int* output)
{
for(int i=0;i<size;i++) {
if(input[start+i]==0) {
inc(output);
}
}
}unlock하는 것을 잊는 등, mutex를 부주의하게 사용하면 deadlock 상황이 발생할 수 있음
모든 thread가 mutex를 얻지 못해 무한정 기다리는 상황이 발생하여 더 이상 진행이 불가 ,,
std::mutex global_mutex;
void inc(int* output)
{
std::lock_guard<std::mutex> guard(global_mutex);
(*output)++;
}
void worker(int* input, int start,
int size, int* output)
{
for(int i=0;i<size;i++) {
if(input[start+i]==0) {
inc(output);
}
}
}-
lock_guard
RAII(Resource Acquistion Is Initialization) 기법을 활용하여 뮤텍스를 안전하게 관리
뮤텍스를 자동으로 잠그는 객체
- 객체가 생성될 때 뮤텍스를 잠금 상태로 만듦
- 객체가 소멸될 때 뮤텍스를 자동으로 해제
- lock_guard 객체의 생성자에서 뮤텍스를 잠그고, 소멸자에서 뮤텍스를 해제
-
RAII (Resource Acquistion Is Initialization)
- "자원 할당은 초기화(Initialization)의 책임을 갖는다”
- 객체의 생성자에서 자원을 할당하고, 소멸자에서 자원을 해제하여 자원 누수를 방지
- ex. Using RAII for thread join
class thread_guard
{
std::thread& t;
public:
thread_guard(std::thread& t_):t(t_)
{}
~thread_guard()
{
if(t.joinable())
{
t.join();
}
}
thread_guard(thread_guard const&) = delete; //del copy constructor
thread_guard& operator=(thread_guard const&) = delete; // del copy operator
};ෆ Deadlock 교착상태
thread 혹은 process가 자원을 얻지 못해 다음 처리를 하지 못하는 상태
시스템적으로 한정된 자원을 여러 곳에서 사용하려고 할 때 발생
- 다음 4가지 상황이 동시에 성립할 때 발생
-
상호 배제 (Mutual exclustion)
: 자원은 한 번에 하나만 사용가능
-
점유 대기 (Hold and wait)
: 최소한 하나의 자원을 점유하고 있으면서 다른 process에 할당되어 사용하고 있는 자원을 추가로 점유하기 위해 대기하는 process가 있어야 함
-
비선점 (No preemption)
: 다른 process에 할당된 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없음
-
순환 대기 (Circular wait)
: process의 집합 {P0, P1, P2, … ,Pn} 에서 P0은 P1이 점유한 자원을 점유하기 위해 대기하고 P1은 P2가 점유한 자원을 점유하기 위해 대기하고 … Pn-1은 Pn이 점유한 자원을 점유하기 위해 대기하며 Pn은 P0가 점유한 자원을 요구해야 함
-
class int_wrapper
{
public:
int_wrapper(int val):val(val){}
std::mutex m;
int val;
};
void swap(int_wrapper& v1,
int_wrapper& v2)
{
v1.m.lock();
v2.m.lock();
int tmp = v1.val;
v1.val = v2.val;
v2.val = tmp;
v1.m.unlock();
v2.m.unlock();
}
int main()
{
int_wrapper a(0);
int_wrapper x(1);
for(int i=0;i<10000;i++) {
std::cout<<"start iteration "<<i<<std::endl;
std::thread t1(swap, std::ref(x), std::ref(a)) ;
std::thread t2(swap, std::ref(a), std::ref(x)) ;
t1.join();
t2.join();
std::cout<<"done a: "<<a.val<<", x:
"<<x.val<<std::endl;
}
return 0;
}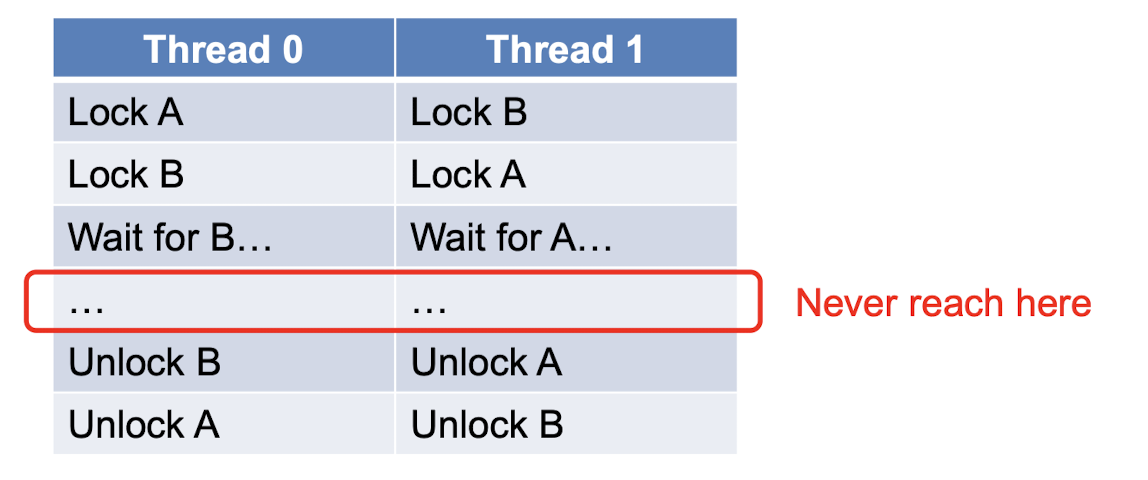
- 두 개의 mutex를 가지고 있음
- 각 mutex를 잠근 후 다른 mutex를 잠그는 swap 함수 정의
- swap함수를 두 thread에서 반복적으로 호출 → deadlock 발생
→ deadlock이 발생하는 이유 ?
- 각 thread가 서로 다른 순서로 mutex를 잠그기 때문,,
- 이러한 상황에서 두 thread는 서로가 가진 mutex를 얻지 못해 무한정 기다리게 되어 deadlock이 발생!
해결방법 ?
-
lock multiple mutexes
std::lock을 사용해 여러 개의 mutex를 한 번에 lock→ 모든 Mutex를 안전하게 lock 가능, deadlock의 위험을 피할 수 있음
void swap(int_wrapper& v1,
int_wrapper& v2)
{
std::lock(v1.m, v2.m);
int tmp = v1.val;
v1.val = v2.val;
v2.val = tmp;
v1.m.unlock();
v2.m.unlock();
}-
use lock_guard, adopt_lock
std::lock을 사용해 두 개의 mutex를 한 번에 잠그고, 이를lock_guard나unique_lock객체에adopt_lock옵션을 주어 넘겨줄 수 있음adopt_lock: 이미 잠겨 있는 mutex를 전달할 수 있게 해줌 → 두 mutex를 안전하게 잠그고 데드락을 피할 수 있음
class int_wrapper
{
public:
int_wrapper(int val):val(val){}
std::mutex m;
int val;
};
void swap(int_wrapper& v1, int_wrapper& v2)
{
std::lock(v1.m, v2.m);
std::lock_guard<std::mutex> lock_v1(v1.m, std::adopt_lock);
std::lock_guard<std::mutex> lock_v2(v2.m, std::adopt_lock);
int tmp = v1.val;
v1.val = v2.val;
v2.val = tmp;
}ෆ Wait
 producer-consumer 문제
producer-consumer 문제
: multi-thread 환경에서 공유 자원인 queue를 여러 producer thread가 data를 추가하고, 여러 consumer thread가 data를 소비하는 상황
→ producer thread가 data를 queue에 추가할 때 queue가 가득 차 있는 경우를 처리
→ consumer thread가 queue에서 data를 가져올 때 queue가 비어 있는 경우를 처리
1. busy wait
자원을 얻기 위해 기다리는 것이 아닌 권한을 얻기 위해 기다리는 것
#include <iostream>
#include <thread>
#include <queue>
#include <mutex>
std::mutex m;
std::queue<int> shared_queue;
const int N = 10000;
void produce()
{
for(int i=0;i<N;i++) {
m.lock();
std::cout<<"i produce"<<i<<std::endl;
shared_queue.push(i);
m.unlock();
//1sec artificial delay
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
}
}
void busy_consume()
{
for(int i=0;i<N;i++) {
while(shared_queue.empty()) {
m.unlock();
m.lock();
}
std::cout<<"i read "
<<shared_queue.front()<<std::endl;
shared_queue.pop();
}
}
int main()
{
std::thread t1(produce);
std::thread t2(busy_consume);
t1.join();
t2.join();
return 0;
}- consumer thread가 계속해서 queue가 비어있는지 확인
- 그러나 queue가 비어있는 경우에도 thread가 계속해서 CPU를 점유하며 queue가 채워질 때까지 대기함 → CPU 자원 낭비, 비효율적
2. busy wait + sleep
- Sleeping
권한을 얻기 위해 걸리는 시간을 wait
queue에 실행중인 Thread 정보를 담고 다른 Thread에게 CPU를 양보하는 것
#include <iostream>
#include <thread>
#include <queue>
#include <mutex>
std::mutex m;
std::queue<int> shared_queue;
const int N = 10000;
void produce()
{
for(int i=0;i<N;i++) {
m.lock();
std::cout<<"i produce"<<i<<std::endl;
shared_queue.push(i);
m.unlock();
//1sec artificial delay
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
}
}
void sleep_consume()
{
for(int i=0;i<N;i++) {
while(shared_queue.empty()) {
m.unlock();
std::this_thread::sleep_for(std::chrono::milliseconds(100));
m.lock();
}
std::cout<<"i read "
<<shared_queue.front()<<std::endl;
shared_queue.pop();
}
}
int main()
{
std::thread t1(produce);
std::thread t2(busy_consume);
t1.join();
t2.join();
return 0;
}- consumer thread가 queue가 비어 있는 경우 일정 시간동안 sleep
- 그 후에 다시 queue가 비어 있는지 확인 → consumer thread가 더 많은 CPU자원을 점유하지 않음 → queue가 채워질 때까지 기다리는데 도움이 됨 → but 여전히 일정 시간마다 불필요한 check가 필요 ,,
3. condition variables
#include <iostream>
#include <thread>
#include <condition_variable>
#include <queue>
#include <mutex>
std::mutex m;
std::queue<int> shared_queue;
const int N = 10000;
std::condition_variable cond;
void produce()
{
for(int i=0;i<N;i++) {
std::unique_lock<std::mutex> lock(m);
std::cout<<"i produce"<<i<<std::endl;
shared_queue.push(i);
cond.notify_one();
lock.unlock();
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
}
}
void consume()
{
for(int i=0;i<N;i++) {
std::unique_lock<std::mutex> lock(m);
cond.wait(lock,[]{return !shared_queue.empty();});
std::cout<<"i read"<<shared_queue.front()<<std::endl;
shared_queue.pop();
lock.unlock();
}
}
int main()
{
std::thread t1(produce);
std::thread t2(consume);
t1.join();
t2.join();
return 0;
}- queue가 비어 있는 경우 소비자 thread 대기
- condition variables
- thread가 특정 조건을 만족할 때까지 대기하도록 함
- 다른 Thread가 조건을 만족시키면 대기 중인 thread 깨움
- consumer thread : queue가 비어 있는 동안 조건 변수를 기다림
- producer thread : 데이터를 queue에 추가한 후 condition variable을 통해 consumer thread를 깨움
cond.wait(unique_lock, predicate function): condition variable을 기다리는 데에 사용unique_locklock_guard와 비슷한 용도- 사용자가 수동으로 잠금 및 잠금 해제 가능 (
lock(),unlock()) - 생성 시 뮤텍스를 잠그거나 해제 가능
predicate function- 조건이 만족되는지 확인하는 함수
- 조건 함수가 True : thread는 대기 중인 상태를 벗어나 다음 코드를 실행
- 조건 함수가 False : thread는 대기 상태에 남음, 나중에 조건이 충족될 때까지 기다림
notify_one()- 대기 중인 thread 중 하나를 깨우는 역할
- 조건 변수를 기다리는 thread 중 하나가 신호를 받아 실행 재개
notify_all()- 모든 대기 중인 thread 깨움
- 여러 thread가 동시에 조건 변수를 기다리고 있을 때 사용
ෆ Atomics
동시에 여러 thread에서 공유되는 변수의 안전한 업데이트를 가능하게 하는 기술
→ thread간 동기화가 필요할 때 사용
#include <iostream>
#include <thread>
#include <vector>
#include <atomic>
#include <assert.h>
std::atomic<int> output
void worker(int* input, int start, int size)
{
for(int i=0;i<size;i++) {
if(input[start+i]==0) {
output+=1;
}
}
}- All-Or-Nothing : 연산이 완전히 수행되거나, 전혀 수행되지 않아야 함
- 원자적 연산을 제공 → 여러 thread에서 동시에 접근해도 데이터의 일관성을 보장한다는 뜻
- 데이터의 일관성을 보장하기 위한 동기화 과정 때문에 일반적인 연산에 비해 비용이 더 들 수 있다..
- 또한 여러 연산이 함께 동작해야 하는 복잡한 동기화 작업에는 lock과 같은 더 고수준의 동기화 도구가 필요 ..
ෆ Barrier

-
전역 동기화(global synchronization)의 한 형태
-
모든 thread가 특정 지점에서 멈추고, 다른 모든 thread가 그 지점에 도달할 때까지 대기하는 동작
→ 여러 thread간의 작업을 동기화할 때 유용
#include <iostream>
#include <boost/thread/barrier.hpp>
#include <thread>
#include <vector>
void worker(int* input, int start, int size, int* output, boost::barrier& bar)
{
for(int i=0;i<size;i++) {
if(input[start+i]==0) {
(*output)++;
}
if(i%1000==0) {
bar.wait();
std::cout<<"thread starting at "<<start<<" passed bar at i="<<i<<std::endl;
}
}
}
int main(int argc, char* argv[])
{
const int N = atoi(argv[1]);
const int NT = atoi(argv[2]);
boost::barrier bar(NT);
for(int t=0;t<NT;t++) {
threads.push_back(std::thread(worker, array, start, size, &count, std::ref(bar)));
}
…
}❦ Thread-safety
여러 thread가 동시에 코드를 실행할 때 공유된 데이터를 안전하게 조작하는 능력
→ 여러 thread에서 동시에 실행되어도 예상대로 작동, 데이터 무결성을 보존
- 가장 쉽게 thread-safe한 코드를 만드는 법 → add a lock to it
ෆ Thread-safe queue
template<typename T>
class thread_safe_queue
{
std::queue<T> _queue;
std::mutex mtx;
public:
thread_safe_queue()
{}
void push(T value)
{
std::lock_guard<std::mutex> lock(mtx);
_queue.push(value);
}
T pop()
{
std::lock_guard<std::mutex> lock(mtx);
T res = _queue.front();
_queue.pop();
return res;
}
};→ safe, but inefficient
- queue에 대한 모든 조작(push,pop ..)이 하나의 mutex로 보호 → queue에 대한 동시 접근을 제어 → 데이터의 일관성 보장 → but, queue에 대한 조작이 가능한 thread 수를 제한
- 뮤텍스는 크리티컬 섹션(critical section)을 보호하기 위해 사용되며, 크리티컬 섹션을 보호하는 동안 다른 스레드는 대기 → 한 번에 하나의 thread만 queue에 접근 → 병목현상
ෆ Linked-list queue
template<typename T>
class linked_list_queue
{
class node
{
public:
node(T init_value):value(init_value)
{}
T value;
node* next;
};
node* head;
node* tail;
public:
linked_list_queue()
{
head = tail = new node(0); //dummy node
}
void push(T value)
{
node* tmp = new node(value);
tmp->value = value;
tmp->next = nullptr;
tail->next = tmp;
tail = tmp;
}
bool pop(T& value)
{
node* old_head = head;
node* new_head = old_head->next;
if(new_head == nullptr) {
return false;
}
value = new_head->value;
head = new_head;
delete old_head;
return true;
}
};→ 모든 조작에 대해 mutex를 사용할 필요가 없음
-
push()tail을 사용하여 새 node를 queue에 추가
→ tail을 변경하는 부분만 lock
-
pop()head를 사용하여 첫 번째 node를 queue에서 제거
→ head를 변경하는 부분만 lock
⇒ 각각 tail과 head만 잠그면 ok
서로 다른 thread가 동시에 queue에 접근 가능, 성능도 향상
ෆ Thread-safe Linked-list queue
template<typename T>
class safe_llq
{
class node
{
public:
node(T init_value):value(init_value)
{}
T value;
node* next;
};
node* head;
node* tail;
std::mutex head_mtx;
std::mutex tail_mtx;
public:
safe_llq()
{
head = tail = new node(0); //dummy node
}
void push(T value)
{
node* tmp = new node(value);
tmp->value = value;
tmp->next = nullptr;
std::lock_guard<std::mutex> tail_lock(tail_mtx);
tail->next = tmp;
tail = tmp;
}
bool pop(T& value)
{
std::lock_guard<std::mutex> head_lock(head_mtx);
node* old_head = head;
node* new_head = old_head->next;
if(new_head == nullptr) {
return false;
}
value = new_head->value;
head = new_head;
delete old_head;
return true;
}
};- 두 가지 mutex를 사용하여 두 가지 종류의 임계 영역 보호
-
tail_mtxpush()함수에서 새로운 값을 queue에 추가할 때 tail update→ tail을 잠그고 새로운 노드 추가
-
head_mtxpop()함수에서 첫 번째 값을 queue에서 제거할 때 head update→ head를 잠그고 첫 번째 노드 제거
push(),pop()함수가 동시에 발생 가능- 각각의 함수는 서로 다른 mutex를 사용하여 자신의 임계 영역 보호
⇒ fine-grained locking !
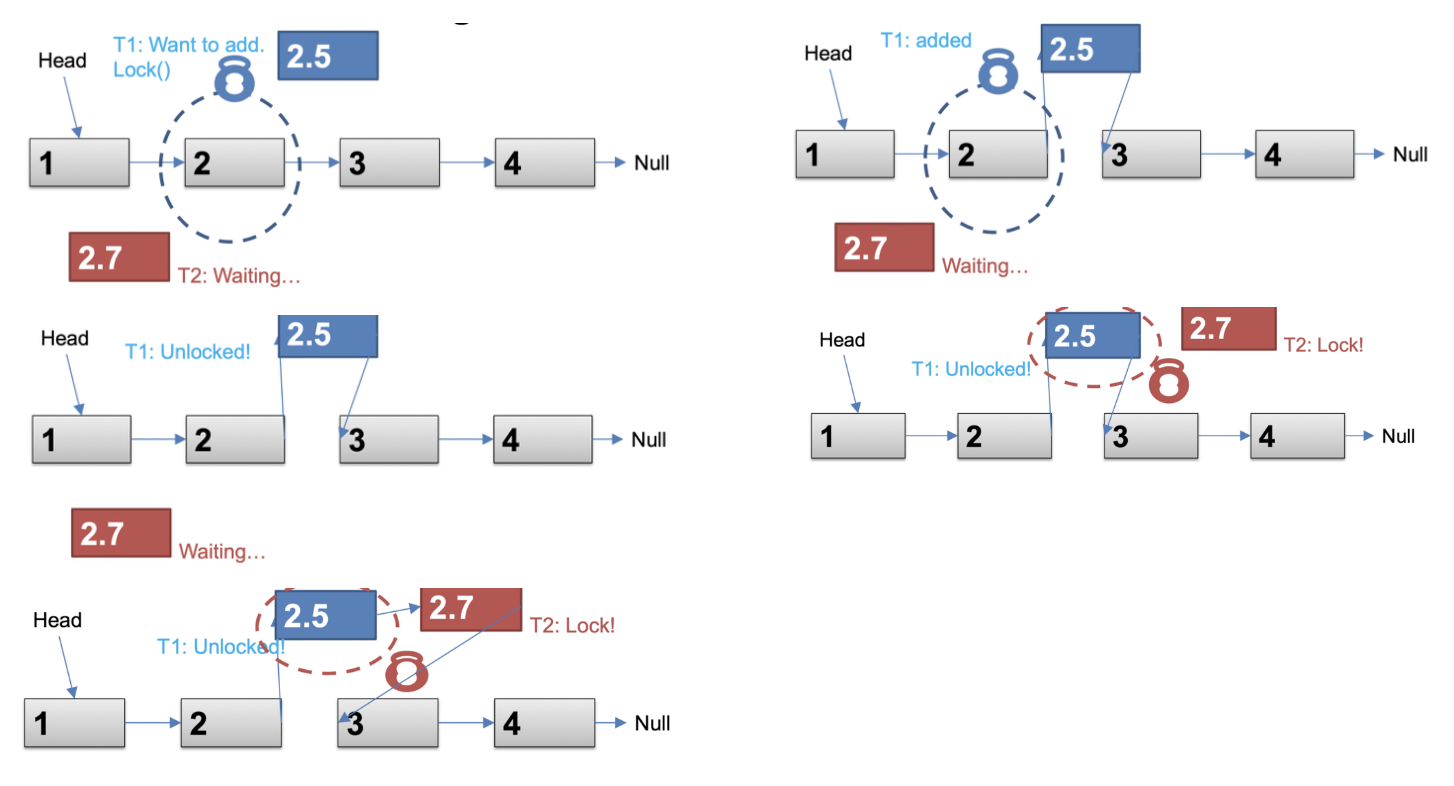
- Lock entire list
- queue의 모든 작업 (push / pop)이 하나의 mutex로 보호
- queue를 변경할 때마다 전체 list가 잠김
→ 간단하고 구현이 쉬우나, 동시성이 낮아지고 병목 현상이 발생
- Node-by-Node lock
- 각 node에 대해 개별적인 mutex를 사용하여 각 node를 개별적으로 보호
- 더 많은 동시성을 제공하지만, error 발생 가능
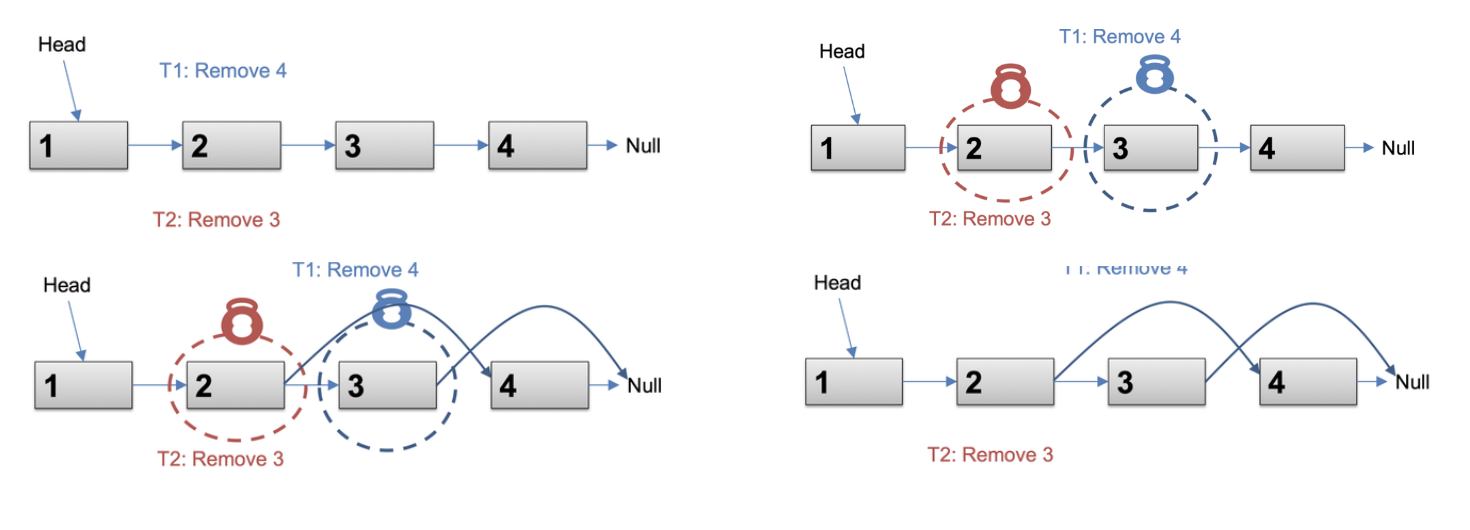
- Hand-over-Hand locking
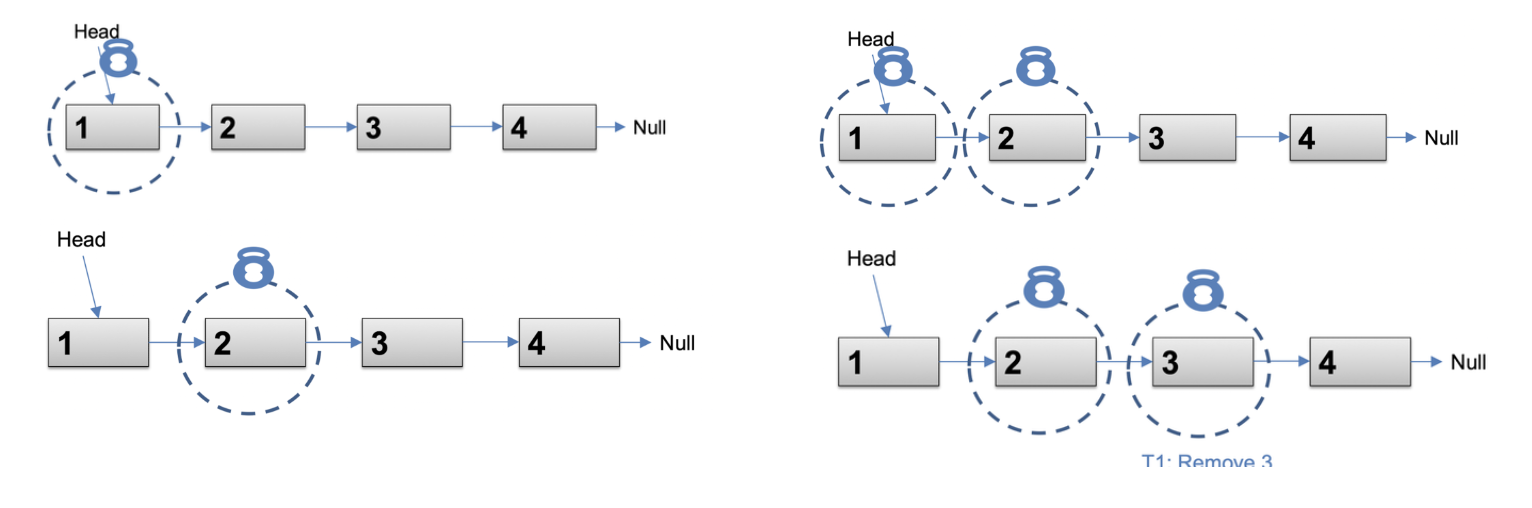
- 노드 사이에서 잠금을 전달
- 첫 번째 node를 잠근 다음, 두 번째 node를 잠금 …
- 구현이 복잡하고 잠금의 overhead 증가
ෆ Thread-safe Hash Table
- 아마도 가장 빠른 data structure ,,
- O(1) : write, read
- global lock
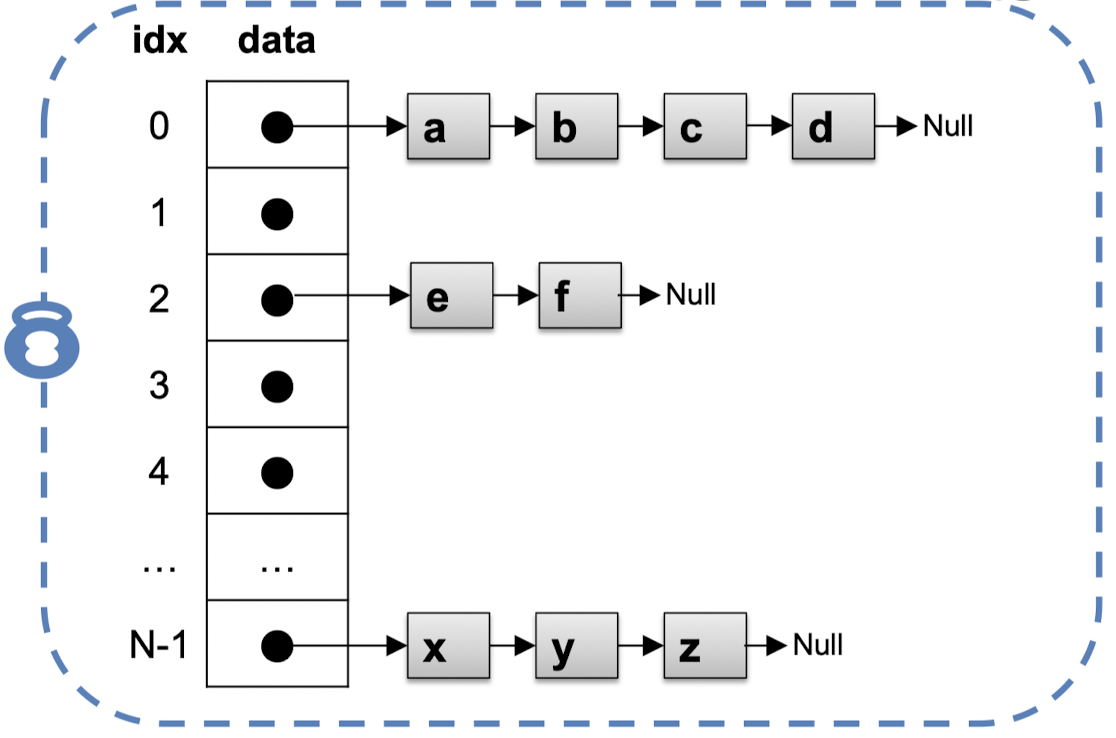
- hash table 전체에 대해 하나의 전역 락(mutex)를 사용
- 구현이 간단하고, 이해하기 쉽지만, 동시성이 낮고 병목 현상이 발생할 수 있음
-
fine-grained lock
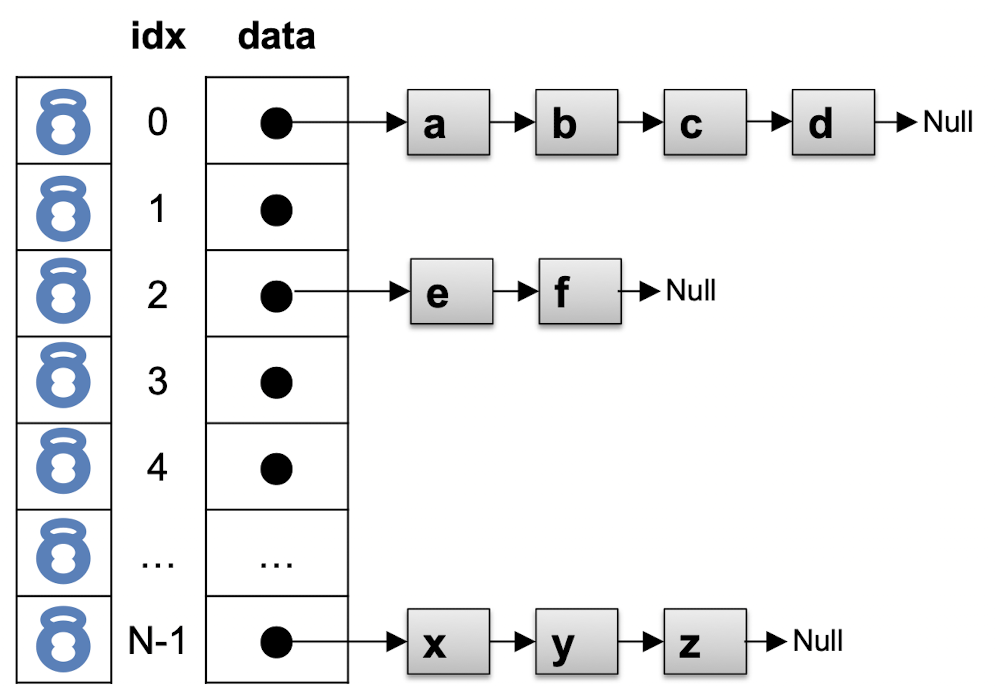
- hash table의 각 버킷에 대해 개별적인 락(mutex) 사용
- 각 버킷에 대한 작업은 해당 버킷에 대한 락을 획득
- 서로 다른 버킷에 대한 작업은 서로에게 영향을 주지 않아 더 많은 동시성 달성 가능
- 락 경합이 발생할 수 있음
- 두 thread가 동일한 버킷을 수정하려고 시도할 때 발생하는 경합 ,,
- 버킷의 개수가 많아지면 overhead 발생
- O(B) : B는 버킷의 수
-
lock striping
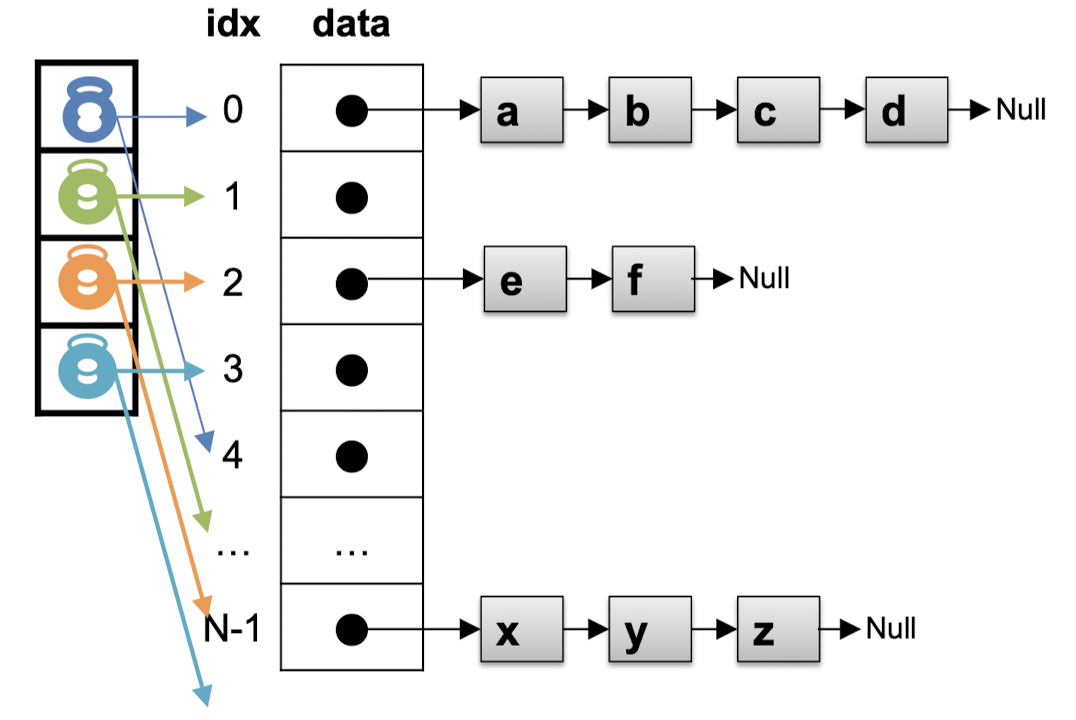
- hash table을 여러 개의 더 작은 섹션 또는 스트라이프로 분할
- 각 섹션에 대해 개별적인 락 사용
- 락 경합을 줄이고 동시성을 높일 수 있음
- but 스트라이핑을 어떻게 구현하느냐에 따라 락 경합이 발생 가능
ෆ Other features to look at
std::this_thread::get_id()- 현재 thread의 식별자를 나타내는
std::thread::id객체를 반환 - 디버깅이나 로깅과 같은 목적으로 사용, 실행 중에 개별 thread를 식별하는데 유용
- 현재 thread의 식별자를 나타내는
std::move()- lvalue를 rvalue로 변환
- 자원의 소유권을 전달하는 등의 상황에서 자주 사용
- 데이터 구조의 소유권을 한 thread에서 다른 thread로 전달 ,,
std::thread와 함께 사용되면 객체의 소유권을 thread에게 전달 가능
std::thread::hardware_concurrency()- 시스템이 지원하는 hardware thread의 수를 반환
- 동시에 실행 가능한 thread의 수에 대한 힌트를 제공
- 성능을 저하시키지 않고 동시성 thread를 실행할 수 있는 최적의 thread 수를 결정
- 최적의 thread 수를 결정하는데 자주 사용
std::async,std::promise,std::futurestd::async: 비동기 작업 실행을 위한 고수준 interface, 계산 결가를 나타내는std::future객체 반환std::promise: 값이나 예외를 비동기적으로 저장하기 위해 사용, 이후std::future객체를 통해 비동기적으로 사용 가능std::future: 아직 사용 가능하지 않은 값, 나중에 사용 가능하게 됨
- most vexing parse problem

-
괄호를 사용하여
nop_object의 인스턴스를 생성 -
이를
std::thread생성자에 전달하려고 시도- 하지만, 이 코드는 가장 먼저 "가장 광범위한 해석" 규칙(most vexing parse)에 의해 문제가 발생
- 컴파일러는 이것을 함수 선언으로 해석할 수 있으며, 결과적으로
t3를nop_object타입의 파라미터를 받고 반환 타입이std::thread인 함수 선언으로 오해
⇒ 해결 방법
 : use {} instead of ()
: use {} instead of ()
-
