L2 regularization과 weight decay가 같다고 할 때 αλθt=λ′θt가 성립한다. λ,λ′,α는 모두 scaler이므로 λ=αλ′일 때 SGD는 L2 regularization과 weight decay가 완전히 같은 모양이 된다. SGD에 한정해서는 참인 명제다. 이런 이유로 pytorch에서는 weight decay를 L2 regularization으로, tensorflow에서는 weight decay만 구현하고 있다.
사족을 달자면 L2 regularization의 λ는 α의 영향에서 자유로울 수 없다는 점을 주목해야 한다. 이 말은 L2 regularization을 사용하는 SGD에 LR scheduler를 함께 쓴다면 최적의 λ를 찾았다고 해도 α가 바뀌면서 λ는 힘을 잃는다는 말과 같다. adaptive gradient method에 L2 regularization과 weight decay를 적용해보면서 연구자의 주장한 3가지의 근거를 알아볼 수 있다.
Adaptive gradient method
Adam을 대표로 하는 adaptive gradient method는 점화식이 복잡해서 α를 줄여주는 부분은 Mt로 단순하게 해서 볼 거다.
마찬가지로 L2 regularization과 weight decay가 같을 때 Mt,θt는 matrix, λ,λ′,α는 모두 scaler이므로 모든 θt에 대해 λ′θt=αMtλθt가 성립해야 한다. 그러면 반드시 Mt=kI이어야 한다. 그렇지만 optimizer의 정의에 의해 λ′θt=αMtλθt는 성립할 수 없다. αMtλ는 t가 변할때마다 바뀌는 반면 λ′는 고정값이기 때문이다. 이제 연구자들의 주장에 대한 근거가 드러났다.
L2 regularization과 weight decay는 같지 않다.
위와 같은 이유로 대부분의 경우 adaptive gradient method에서는 L2 regularization과 weight decay가 반드시 달라야 하므로 Mt=kI가 성립하고 L2 regularization과 weight decay가 같다는 주장은 거짓이다.
L2 regularization은 Adam에서 제대로 작동하지 않는다.
adaptive gradient method는 L2 regularization에서 SGD보다 Mt만큼 가중치를 준다는 점을 알 수 있는데 이것은 L2 regularization를 쓰면서 기대하는 행동이 아니다.
Weight decay는 SGD, Adam에서 모두 효과적이다.
두 가지 optimizer에서 weight decay λ′은 α와 Mt 두 가지로부터 자유롭다.
그럼에도 불구하고 L2 regurlarization과 weight decay가 같은 특수한 경우를 생각해보자. 그러면 L2 regularization은 θ를 s로 scale하고 Mt=s1I로 고정해야 한다.
Adaptive gradient method with scaled adjusted L2 Regularization
이렇게 해야 그나마 SGD처럼 λ=αλ′가 성립한다. 그렇지만 adaptive gradient method라는 이름에 어울리는 optimizer가 되려면 t를 업데이트 할 때마다 s도 함께 바꿔줘야 한다. 여기에서는 θ에 s를 곱하고 있는데 이것은 L2 regularization를 사용한 Adam보다 강하게 regularize하는 효과가 있다. 그렇지만 이렇게 해도 SGD가 가진 문제가 여전히 남아 있다.
Decoupling
지금까지의 증명으로 기존의 optimizer에서 구분없이 사용하고 있던 L2 regularizaer와 weight decay를 따로 떼놔야 한다고 주장하고 있다.
좀 복잡하니까 weight update부분만 따로 떼서 보면 SGDW에서 L2 regularization 대신 weight decay를 사용해서 α의 영향에서 벗어나서 좀더 안정적으로 generalization할 수 있게 했다.
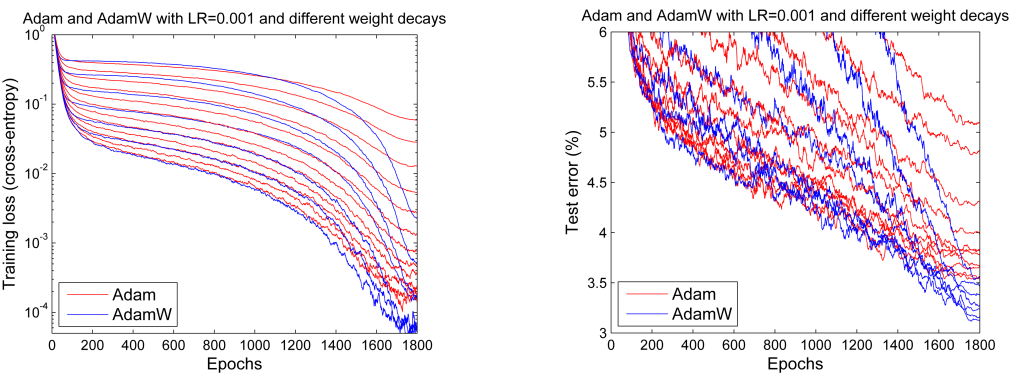
CIFAR-10을 각각의 optimzier로 학습한 해서 test error를 측정한 결과물을 봐도 decouple한 optimzier의 gerneralization성능이 뛰어나다고 알 수 있다.
Experiment 2
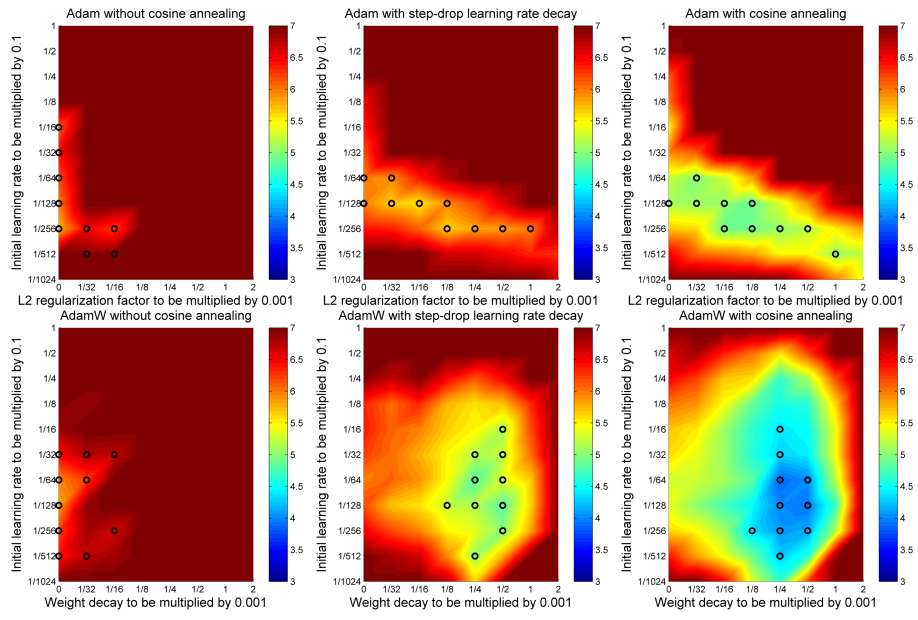
첫번째 줄은 L2 Regularized Adam, 두번째 줄은 AdamW로 CIFAR-10을 학습한 모델이다. 여기에 첫 행부터 fixed, step, cosine annealing을 LR policy로 했다. 처음에 Adam을 접했을 때 optimizer가 자체적으로 LR을 decay해줘서 LR policy가 오히려 학습을 방해할거라고 생각했다. 연구에서는 오히려 LR policy를 사용하면 넓은 search space와 성능도 함께 가져갈 수 있다는 점이 장점으로 작용한다고 밝혔다.
Epilogue
나는 tensorflow를 주로 써서 이걸 읽는 내내 weight decay가 optimizer에서 잘 분리돼있는데 왜 자꾸 따로 떼어놓자는 건지 와닿지 않았다. pytorch에서는 weight decay라고 적고 L2 regularization으로 구현하고 있어서 이렇게 주장할 수도 있겠다 싶었다.