- updated Mar.24.22: 구현
Prologue
모델을 generalize하는데 많은 시간이 들어간다. 좀 다른 말로 overfitting을 막는 일이다. 특히 optimizer로 overfitting을 막는 방법에는 L regularization, weight decay가 있다고 알려져 있지만 실제로 잘 쓰는 일은 쉽지 않다.
What did the authors try to accomplish?
이런 이유로 여전히 많은 연구에서 SGD momentum을 사용하고 있어서 연구자들은 SGD momentum을 어떻게 하면 효율적으로, 또 안정적으로 쓸 수 있을지 고민했다.
CLR
물론 효율적으로 쓸 수 있는 방법이 아주 없던 것은 아니다. 이 연구와 접근방법이 가장 비슷한 것이 Cyclical Learning Rate이다.

learning rate(lr)를 주기적으로 진동하게 해서 기존의 lr decay보다 빠른 학습속도를 보여줬다.
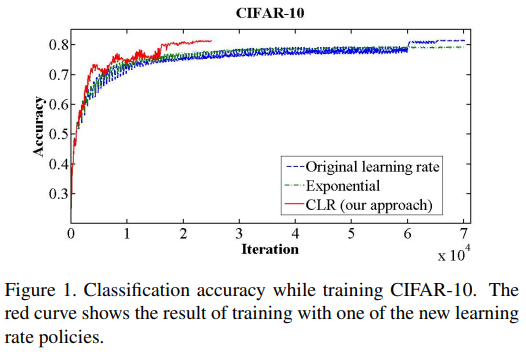
그래프에서 전체적인 trend는 학습속도가 빠르다고 읽을 수 있다. 그렇지만 자글자글하게 진동하는 게 보이는데 mini batch마다 lr, data가 다르기 때문이다. SGDR에서는 이 점을 단점으로 봤다.
What were key elements of the approach?
연구자들은 안정적인 학습을 위해 restart 위에 몇 가지 장치들을 얹어놨다.
Cosine annealing
점화식이 말해주듯이 learning rate 는 함수에 의해 를 주기로 최댓값 와 최솟값 사이를 진동한다. 예를 들어 일 때 는 아래와 같이 변한다.

CLR과 cosine annealing두 가지 방법 일정한 주기로 를 초기값으로 돌려놓는 모습을 볼 수 있다. 이것을 restart라고 부른다.
Cycle update
다만 update rule을 좀 바꿨다. 를 만족할 때마다 만큼 늘어나도록 하고 를 다시 1부터 시작하게 했다. 그러면 그래프는 CLR과는 약간 다른 양상을 보인다.
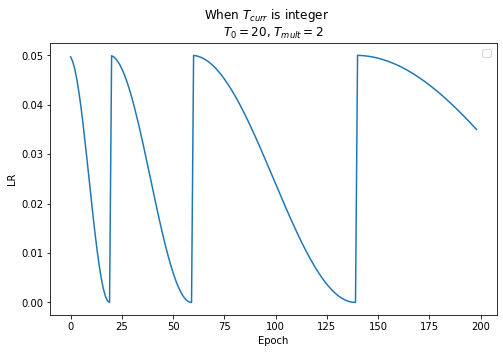
Pro tip
최적의 model을 저장해야 할 때 주의해야 할 점이 있다고 언급했다. 연구자들은 이 방법이 가끔씩 loss가 튈 때도 있어서 웬만하면 가 최소값이 될 때 저장하도록 했다. 실제 학습에서 써보니까 연구자들의 조언대로 가 최소값이 될 때마다 이전 epoch의 기록을 갈아치우는 모습을 보여줬다.
Experiments
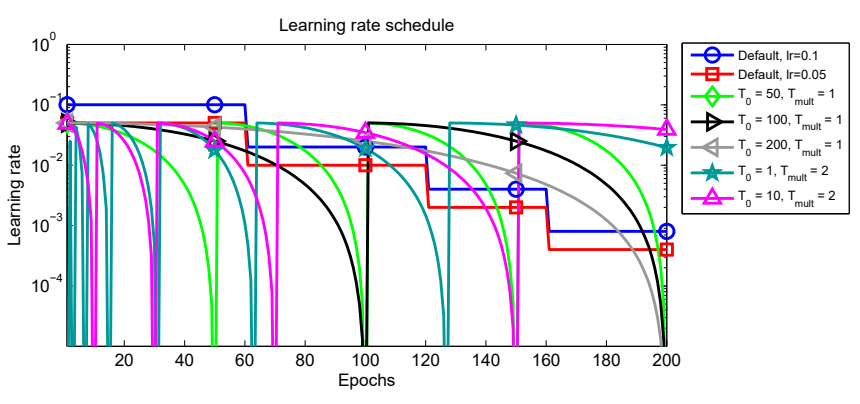
연구에서는 SGD momentum을 optimizer로 해서 lr을 업데이트하는 규칙을 lr decay와 restart로 나눠서 실험했다. 뒤에 나올 그래프가 좀 어지럽지만 전부 같은 그래프다.

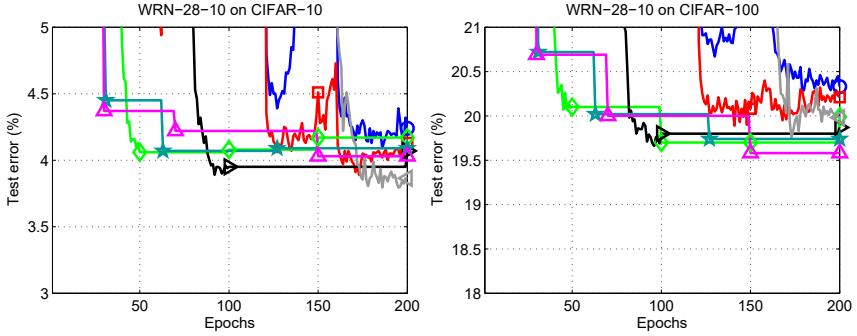
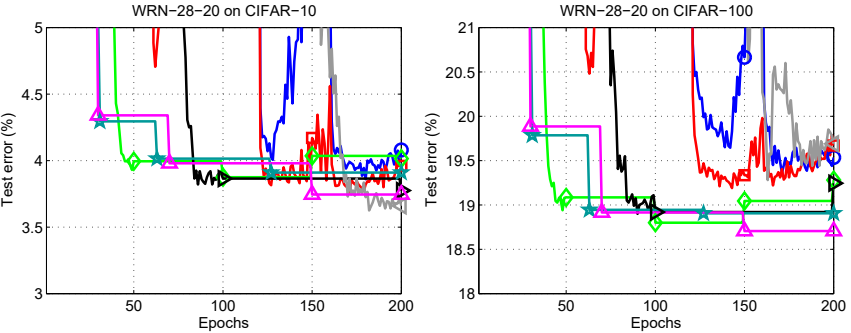
첫번째 줄은 전체 trend, 두번째 줄은 잘 되는 구간을 확대 했고 세번째 줄은 restart기법 사이의 세부사항을 확인할 수 있도록 확대해놨다. 실험을 통해 확인할 수 있는 것은 크게 3가지로 압축할 수 있다.
- lr decay보다 restart가 잘 된다.
- 일 때 lr decay보다 성능이 좋지만 연구자들이 추구했던 안정적인 학습과는 거리가 멀다.
- 일 때 일 때 보다 학습이 잘 될뿐만 아니라 그래프가 자글자글하게 튀지 않는다.
을 업데이트하면 의 변화율은 점점 낮아지는데 이전 주기보다 weight update를 좀 덜하게 한다. 이 점이 regularizer역할을 하는 게 아닌가 싶다.
Epilogue
연구자들의 코드를 돌려보면 lr는 이렇게 변한다.
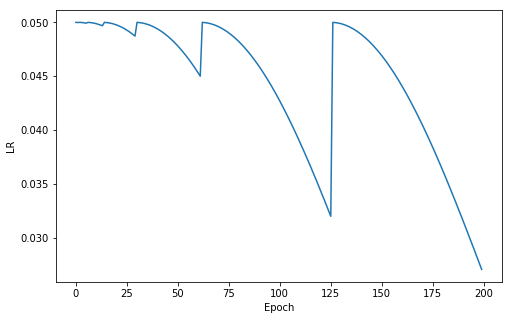
- cosine annealing 점화식에서 restart할 때마다 을 초기화 하는 게 아니었다. 오히려 함수의 성질을 이용해서 가 를 왔다갔다 하게 만들었다.
- 연구자들은 와 를 낮게 해야 한다고 권유하는데 그렇게 해야 가 점점 낮아지게 해서 안정적인 학습이 가능하다고 봤다.
