- updated Oct.02.21: 구현
Prologue
MobileNet과 EfficientNet의 network를 구성하고 있는 layer다. 모바일 환경이 점차 늘어나면서 '어떻게 하면 network의 크기와 연산량을 줄일 수 있을까?' 하는 고민으로부터 나온 결과물이다.
Standard convolution
기존의 conv layer는 두 tensor를 frobenius dot product로 연산해서 scalar를 내놓는다. 이 연산은 두 가지 과정으로 이루어져있다.
- Hadamard product
- Sum
특히 2번 연산을 거치면서 마치 채널방향으로 나뉘어 있던 신호가 뒤섞이게 된다.
Depthwise Separable Convolution
CNN이 발전하면서 bottleneck layer나 GAP(Global Average Pooling)로 연산량을 효과적으로 줄일 수 있었지만 모바일 기기에 얹을 수 있는 모델을 만들기에는 한계가 있었다. 연산량을 보다 더 줄이기 위해 Depthwise Separable Convolution은 기존의 Convolution연산을 2가지로 쪼개놨다.
- Depthwise convolution
- Pointwise convolution
Depthwise convolution
이름이 직관적이다. standard convolution은 입력 tensor의 채널 수와 kernel의 채널 수가 일치하는 데에 비해 Depthwise convolution은 kernel의 채널이 1로 만들어진다. 그래서 입력 tensor의 채널 수만큼 kernel이 만들어지고 각 채널 별로 convolution연산을 수행하므로 출력 tensor의 채널은 입력 tensor의 채널과 일치하게 된다.
Pointwise convolution
이 연구에서 pointwise convolution이라고 표현했지만 1x1 conv layer와 같은 연산이다.
Why is this effective?
과연 효과적인지 계산해보자. 먼저 기본적으로 conv layer의 연산량은 kernel의 모양과 출력 tensor의 모양이 결정하는데 로 계산한다. 문제를 단순하게 보기위해 여기에서는 임의의 kernel과 출력 tensor는 각각 높이와 너비가 같다고 하고 bias는 빼기로 한다.
- Kernel shape:
- Output shape:
Cost calculation
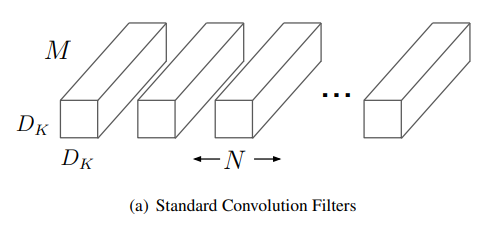
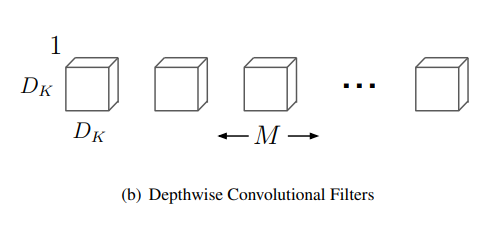
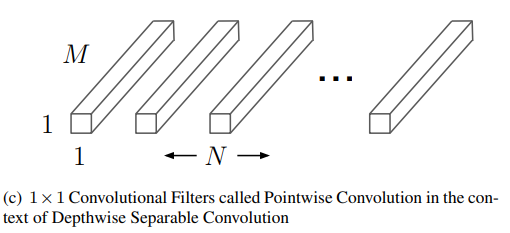
지금까지 계산한 연산량을 바탕으로 Standard convolution과 의 비율은 다음과 같다.
즉 depthwise separable convolution은 standard convolution에 비해 만큼 효율적인 연산이라고 할 수 있다. 논문에서는 3x3 depthwise separable convolution이 같은 크기의 standard convolution에 비해 8-9배정도 효율적이라고 적고 있다.
Building block

depthwise conv layer와 pointwise conv layer를 붙여쓰는 줄 알았더니 엄밀하게는 따로 연산한다. 붙여서 쓸 수도 있지만 conv layer 2개를 붙여서 쓰는 것보다는 activation function을 하나 거치면 표현력이 더 좋아져서 이런 구조를 선택한 것처럼 보인다.
Epilogue
-
일반적으로 연산량이 줄면 자연스레 성능저하도 같이 일어난다. 신기한 점은 연산량이 감소하는 만큼 성능저하가 그렇게 크지 않다.
-
구글에서 하는 연구들을 읽다보면 기업이라 그런지 상용화에 관심이 많아보인다.
