Prologue
모델이 발전할수록 모델이 요구하는 메모리와 용량이 커진다. 그래서 클라우드 혹은 서버에 모델을 실어서 서비스하기도 한다. 실시간으로 응답해야 하거나 개인정보처럼 민감한 정보를 처리하는 경우라면 반드시 온디바이스에서 처리해야 한다.
What did the authors try to accomplish?
문제는 온디바이스의 메모리와 용량은 서버가 가진 것만큼 크지 않다. 이 문제를 해결하는 간단한 방법으로 작은 모델을 만들면 응답시간을 줄일 수 있지만 성능은 포기해야한다. 이 연구는 Model Compression에서 큰 ensemble 모델이 학습한 정보를 단일 모델로 옮길 수 있다고 밝힌 점을 다시 정리했다.
What were the key elements of the approach?
Teacher student paradigm
혼자 학습하는 것보다 누가 지식을 전수하면 학습속도가 빨라진다. 이 사회에 교육기관이 있는 게 그런 이유다. 여기에서 착안해서 연구자들은 이렇게 생각했다.
"큰 모델이 가진 답지를 작은 모델이 학습하면 좋지 않을까?"
Soft target
모델이 내놓는 값은 data가 가진 logit이다. 여기에서 할 수 있는 선택은 2가지다.
- logit을 그대로 쓰기
- logit을 one-hot으로 바꿔서 쓰기
1을 soft target이라고 하고 2를 hard target이라고 한다. 왜 이렇게 부르는지 처음에는 납득하기가 쉽지 않았다. 그래프를 보면 soft target은 hard target에 비해 중간지대를 허용하고 있는 것을 볼 수 있다.
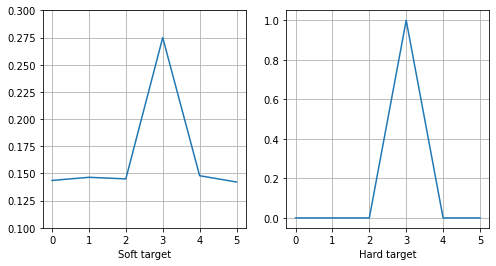
이렇게 soft target을 쓰면 teacher 모델이 내는 오류들도 학습하는 샘인데 연구에서는 이런 오류들도 의미가 있다고 봤다. 예를 들어 바퀴를 보고 이게 자동차인지 비행기인지 판단하는 근거가 오류에도 어느정도 녹아있다고 보는 거다.
soft target과 hard target을 비교하는 실험에서 teacher 모델을 하나 학습해서 student 모델 2가지를 각각 knowledge distillation으로 학습했다.
- 학습데이터의 3%를 hard target으로 학습
- 학습데이터의 3%를 soft target으로 학습
1번 모델은 overfitting 때문에 학습을 일찍 멈췄고 심지어 test accuracy가 44%까지 떨어졌다. 반면에 2번 모델은 overfitting없이 학습을 마쳤고 test accuracy도 teacher 모델 수준으로 오른 것을 관찰할 수 있다.

Temperature
연구에서는 soft target을 만드는 방법으로temperature라는 개념을 도입했다. 점화식을 보면 softmax의 입력값을 로 나눠줬다.
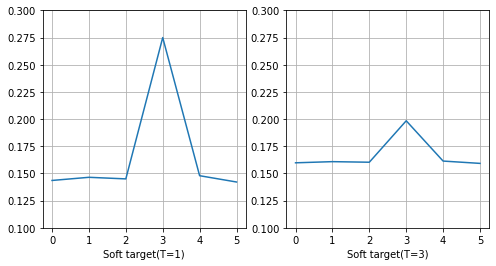
softmax도 label과 비교하면 soft target에 든다고 할 수 있지만 를 높여서 softness를 더 높일 수도 있다.
Distiller
Distiller의 전체적인 목적은 teacher 모델이 내는 logit과 student 모델이 내는 logti을 최대한 같게 하는 것이다.
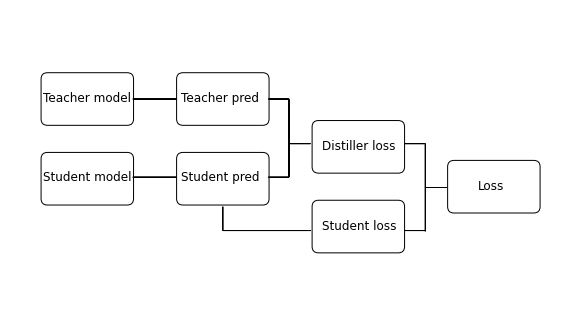
distiller는 3가지 loss function이 필요하다.
- Distiller loss
- Student loss
- Loss
Distiller loss
입력값 에 대해 teacher 모델과 student 모델의 예측값을 1보다 큰 를 사용해서 soft target으로 만들어서 두 예측값의 거리를 측정하는 loss function이다. 그래서 KL divergence를 쓴다.
Student loss
입력값 에 대한 student 모델의 예측값과 hard target(label)의 거리를 측정한다. 기존의 classification과제에서 사용하는 Cross entropy를 사용한다.
Loss
두 loss function을 활용해서 최종적인 loss를 내는데 를 활용해서 distiller loss와 student loss의 비율을 조절한다. 전체 loss에서 student loss의 영향력을 줄이는 쪽이 성능이 좋다고 연구에서 언급하고 있다.
Epilogue
-
이 연구에서는 teacher와 student의 logit의 분포를 최대한 같게 했지만 후속연구에서는 teacher와 student의 weight를 최대한 같게 하는 연구를 진행했다.
