update Aug.20.22: 오류수정
Prologue
요즘 회사에서 YOLO v3를 구현하는 김에 세미나를 해달라는 부탁을 받았다. 그래서 하는 정리.
What did the authers try to accomplish?
테크리뷰라는 것을 핑계로 구어체로 쓴 특이한 연구. 성능향상을 위한 아이디어는 딱히 들어있지 않고 이미 다른 연구에서 사용한 방법을 가져와서 YOLO v2보다 성능향상을 꾀했다.
YOLO
RCNN계열에서 제시했던 복잡한 pipeline을 전부 걷어내고 그냥 regression과제로 생각해서 object detection과제를 푸는 알고리즘이다.
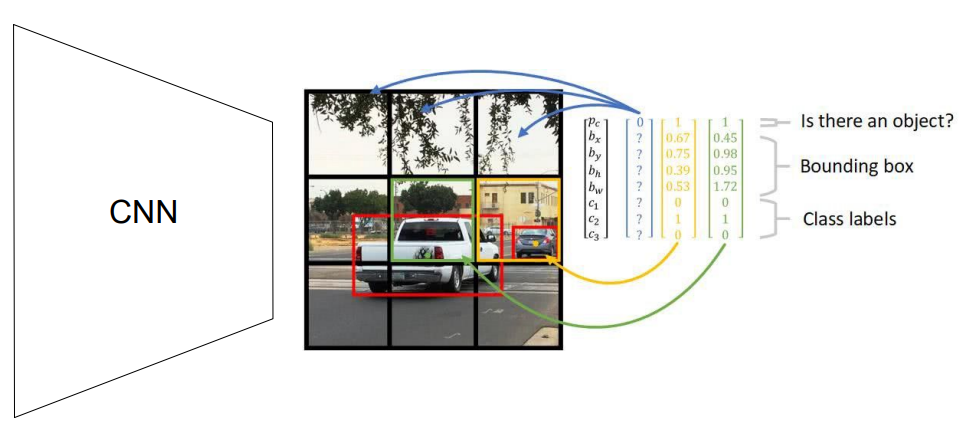
간단히 말하면 입력이미지를 개의 cell로 나눠서 물체가 있는 cell을 예측하고 크기와 클래스를 예측한다.
What were the key elements of the approach
Darknet 53
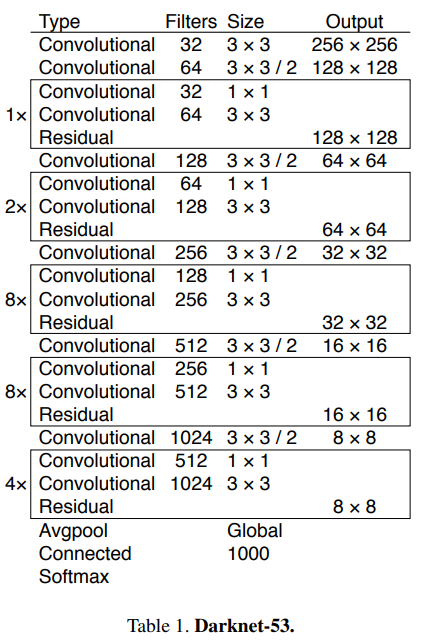
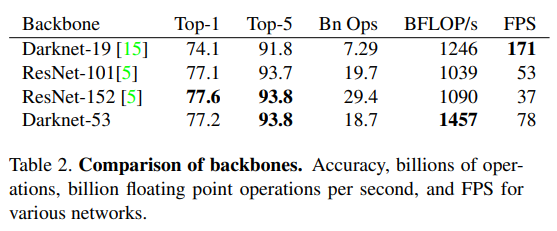
v2보다 큰 모델을 사용해서 ResNet 152와 비슷한 성능을 확보했다. 그렇지만 전체 연산량은 ResNet 152보다 낮고 초당 1.5배 많은 양을 처리한다. 그렇지만 Darknet 19보다 FPS가 떨어지기 때문에 Better, not Faster, Stronger라는 별명이 붙어있다.
YOLO v3
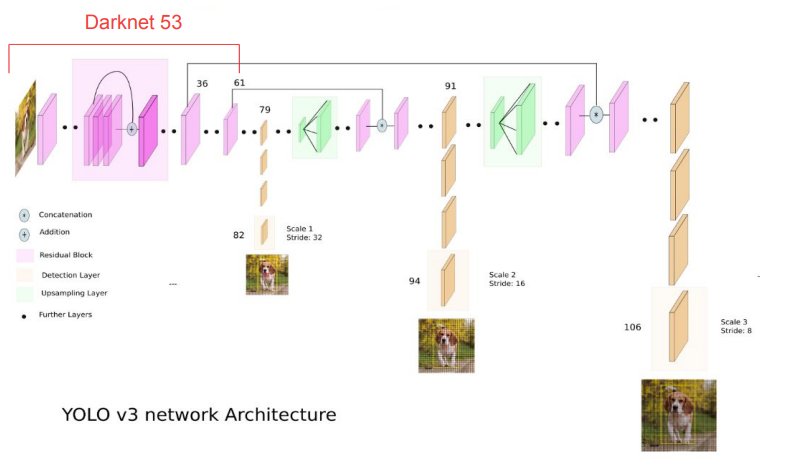
표시한데까지가 backbone이다. backbone이후에 FPN을 활용해서 3가지 scale에 대해 에측한다.
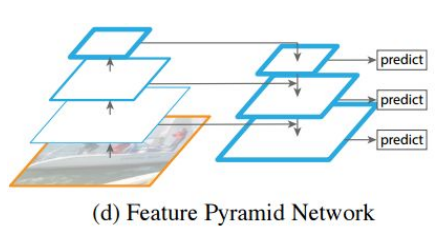
일반적으로 CNN은 해상도를 줄여서 feature를 추출한다. 가장 마지막의 feature map에는 feature정보가 많이 남아있어서 clasification에는 유리하지만 해상도가 떨어지므로 물체가 구체적으로 어디에 있는지 예측하기 어렵다. 특히 작은 물체라면 난이도는 더욱 올라간다. FPN에서 이 문제를 해결한 방법은 네트워크의 앞단에 있는 높은 해상도의 feature map을 활용했는데 이렇게 해서 localization 성능을 높이면서 작은 물체를 더 잘 잡아낸다.
Anchor
bbox를 예측할 때 사용하는 방법은 v2와 같다. 이번에 리뷰하면서 다시 생각해보니까 k-means clustering을 사용하는 방법이 좋은 접근이라는 생각이 들었다. 기존에는 연구자의 경험에 의해서 결정하는 방법보다 데이터의 대푯값을 이용하면 더 쉽게 bbox를 예측할 수 있기 때문이다. 예를 들어 보행자를 잡아내는 과제에서 위아래로 길쭉한 bbox가 대부분일텐데 마찬가지로 위아래로 길쭉한 anchor를 사용하면 bbox를 잘 잡아낼 것이다. v3에서는 총 9개 anchor를 추출했고 작은 것부터 3개씩 작은 물체, 중간크기, 큰 물체를 탐지하는데 사용한다.
Loss function
Anchor
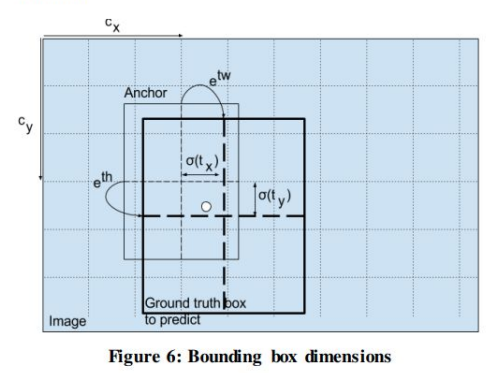
이미지처럼 anchor를 통해서 gt box를 예측할 때 중심좌표 가 주어진다. 이 때 에 를 적용해서 예측값이 에 있게 한다.
즉 이 gt box의 중심좌표가 속한 cell을 벗어날 수 없게 하는데 이렇게 해서 중심좌표를 안정적으로 예측한다. 나머지 너비와 높이를 예측하는 것은 거의 대부분의 detector와 동일하다.
Objectness score
이걸 결정하는 방법은 Faster R-CNN처럼 가장 높은 iou를 가지는 anchor 에는 을 메기고, 그렇지 않은 것들은 threshold를 넘겼어도 을 메긴다. 이렇게 하면 YOLO는 물체 하나에 bbox 하나를 가진다. object score는 아래처럼 계산한다.
No objectness score
object score가 0으로 메긴 cell은 target cell과 비교해서 BCE를 계산한다.
Class score
이것도 특이하다 생각했는데 bbox가 여러개 class를 가질 가능성도 열어놨다. 예를 들어 dataset을 봤을 때 골든리트리버, 화이트리드리버처럼 여기에도 속하고 저기에도 속할 수 있으면 각 class마다 BCE를 계산해서 여러 class를 가질 수 있게 했다. 만약에 dataset이 그렇지 않으면 그냥 softmax crossentropy를 쓰면 된다.
생각해보면 이게 superclass - subclass관계가 아니다. 원본 이미지를 로 줄여나가면 하나의 cell에 object들이 있는 경우가 있다. 아니 많을 거다. 그럴 때 anchor는 동시에 몇 가지 class를 가지게 해야 하는데 softmax crossentropy로는 그럴 수 없다.
Output tensor
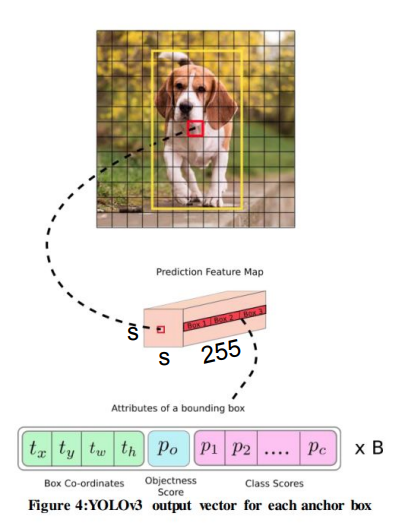
이걸 다 모으면 output tensor는 COCO dataset의 경우 가 된다. 이 말은
- annotation을 적당히 가공해서 같은 모양의 tensor를 만들어야 하고
- loss function을 계산할 때 anchor, objectness, class socre가 있는 자리를 잘 찾아야 한다는 말과 같다.
Epilogue
YOLOv3를 이해하는데는 여기까지 알면 된다. 구현하는데는 이것들 말고도 여러 모듈이 필요하고 또 서버환경에서 분산학습을 위한 코드를 짜야 한다. 언제나 그렇듯 할 일은 많고 시간은 촉박하다. 야근을 좀 해야겠다.
