- updated Jul.16.21: 모델구현 추가
Prologue
논문 제목(Very Deep Convolutional Networks For Large-Scale Image Recognition)에서부터 "많이 쌓을 거다"가 느껴진다. 2012년 이후로 ILSVRC에서는 AlexNet을 다듬어서 성능을 높이려는 시도를 하고 있었다. VGGNet은 19 layer까지 쌓아서 성능을 끌어올렸다.
What did the authors try to acomplish?
'Conv layer를 쌓으면 성능을 높일 수 있나?'하는 호기심에 시작한 연구처럼 보인다. 모델을 깊게 만들면 필연적으로 parameter가 늘어날텐데 overfitting을 막으면서 성능은 어떻게 높일 수 있었을까?
What were the key elements of the approach?
3x3 kernel
이전 연구에서는 kernel을 11x11이나 7x7같이 상대적으로 큰 kernel을 썼지만 이 연구에서는 모델에 있는 모든 kernel을 3x3으로, stride를 1로 고정했다. 이렇게 해서 얻을 수 있는 이점은 2가지다.
1. Parameters
(32, 32, 3)크기의 이미지를 7x7 kernel과 3x3 kernel 각각 10개를 사용할 때 parameter는 각각 1470, 270으로 parameter를 약 5.4배정도 줄일 수 있다.
2. More activation function
중간에 pooling layer가 없다는 조건으로 7x7 kernel로 만들어낸 feature map의 크기는 3x3 kernel에서 나온 feature map보다 작다. 3x3 kernel로 7x7 kernel을 쓴 것 같은 효과를 보려면 kernel 3개를 써야 한다. 한 방에 팍! 줄이는 것보다 점진적으로 feature map을 줄이는 횟수만큼 activation function도 더 쓸 수 있어서 모델 성능을 높여준다. 위에서 본 것처럼 3x3 kernel을 3개 쓴다고 하더라도 여전히 parameter는 7x7 kernel 하나보다 훨씬 낮다.
Archetecture
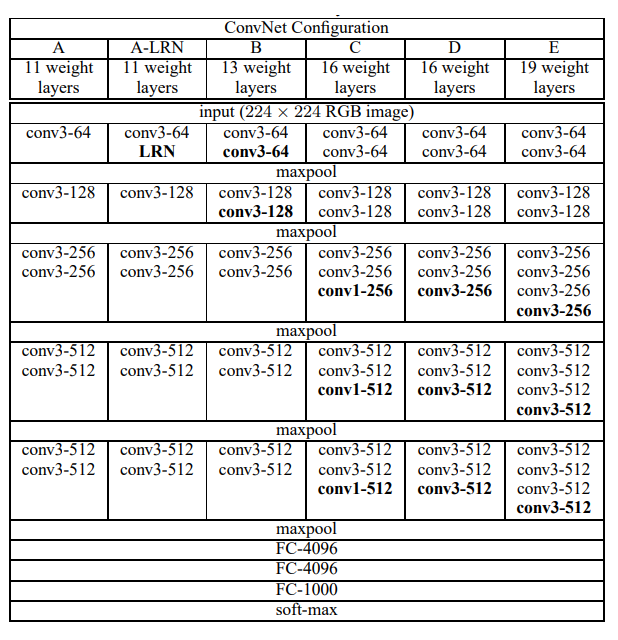
A에서 E로 갈수록 깊이가 깊어지고 성능도 E가 가장 좋았다. 6개 모델 전부 5개의 maxpool layer를 사용하고 있는데 2x2 크기의 filter를 stride 2로 설계해서 maxpool layer를 지날 때마다 feature map이 반으로 줄어든다.
Train
기본적인 학습방법은 AlexNet과 같다. 전체 데이터를 256개의 batch size로 나눠서 74 epochs로 진행했다. Optimizer로 SGD momentum을 이용해서 momentum 계수는 0.9로, 학습률은 0.01부터 시작해서 validation accuracy가 개선하지 않으면 10으로 나눠줬다. weight decay는 0.0005로 했다.
이 연구에서 parameter를 초기화하는 방법이 흥미로웠다. A 모델의 parameter를 임의로 초기화한 다음에 CIFAR-10을 데이터셋으로 학습한 후 처음 4개 conv layer와 FC layer 3개의 weight를 나머지 모델에 그대로 썻다. 나머지 layer는 평균이 0, 분산이 0.01인 정규분포로 초기화하고 모든 layer의 bias는 0으로 초기화했다.
Epilogue

VGGNet은 AlexNet보다 conv layer를 5배 더 깊이 설계하면서 parameter는 2.3배 증가하는 것으로 그쳤다. layer를 잘 쌓으면 모델성능도 끌어올릴 수 있다는 것을 증명하면서 후속연구에서 layer 쌓기 경쟁을 시작하게 했다.
