- updated Jul.15.21: 모델 구현 추가
Prologue
CNN의 뿌리라고 할 수 있다. 그만큼 인용수도 엄청나다. ILSVRC 2012에서 처음으로 딥러닝 모델로 다른 모델을 압도하면서 우승했다. parameter가 6000만개여서 연구자들이 특히 신경썼던 것은 최대한 overfitting을 막으면서 학습속도를 높이려고 애쓴 게 논문을 통해 보인다.
Archetecture
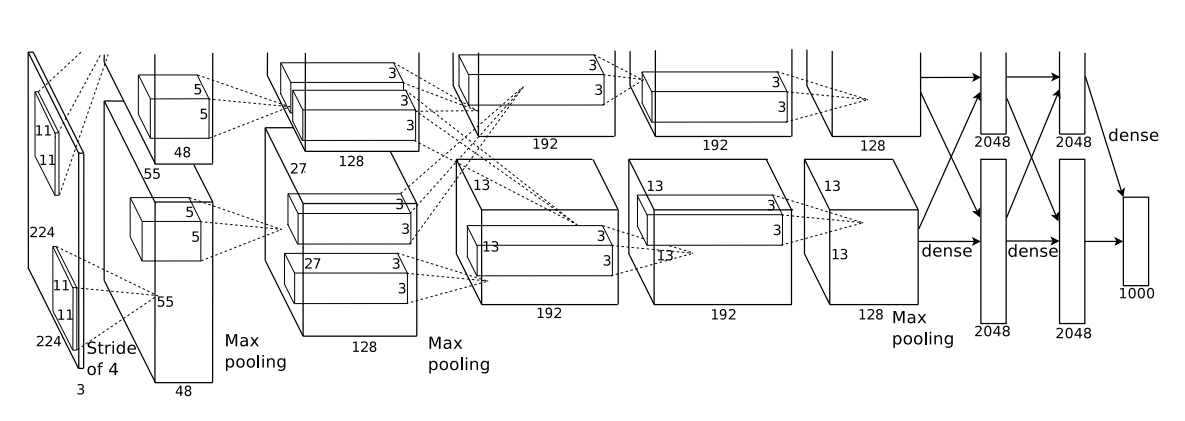
Conv layer 5개, FC layer3개 이렇게 총 8개의 레이어로 이루어져있다. 이 당시에는 요즘 나오는 GPU에 비해 성능이 떨어지는 편이어서 입력이미지를 독립적인 GPU에 집어넣어서 각각 다른 feature map을 만들어내는 방식으로 병렬학습처럼 이용했다. 3번째, 6번째 레이어에서 서로 feature map정보를 주고받는다
특이한 점은 1번 GPU의 kernel은 none color feature를, 2번 GPU의 kernel은 color feature에 특화된다는 점을 관찰했는데 매번의 학습(논문에서 run으로 나와서 이게 epoch인지 batch인지, 아니면 조건을 다르게 한 다른 학습에서였는지 잘 모르겠다.)에서 나타났고 임의로 weight initialize해도 같은 현상이 나타났다. 왜 그런지는 모르는 것같다.
이전과는 다른 방법으로 과제를 해결했기 때문에 AlexNet이 가지는 특징이 몇가지 있다.
- ReLU
- Local response normalization
- Overlapping pooling
- Dropout
- Data augmentation
1. ReLU
요즘이야 activation function으로 relu를 쓰는 게 보편적이지만 이 때는 tanh 혹은 그 응용형을 주로 썼다. 특히 가 학습이 효율적이지만 ImageNet에 있어서는 overfitting이 심하다는 점이 relu를 사용하기로 하는 직접적인 근거가 됐다.
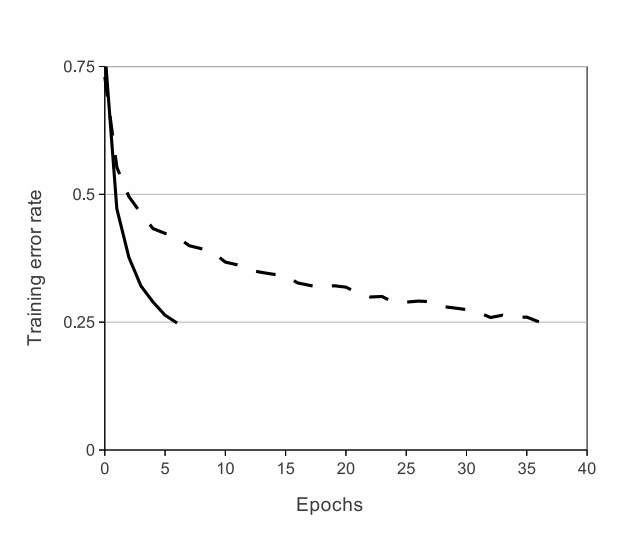
CIFAR-10을 4 layer CNN으로 tanh(점선), relu(실선)로 각각 학습한 결과를 그린 그래프다. 이 실험에서 relu를 사용한 모델이 학습속도가 6배 빠르다고 관찰했다.
2. Local response normalization
특이한 점은 Local response normalization(LRN) layer를 사용했다. lateral inhibition이라는 신경생리학에서 가져온 개념인데 자극을 더 잘 잡하내기 위한 메커니즘으로 어떤 수용장에 자극이 들어오면 수용장 근처에 있는 뉴런들은 활성화를 억제한다.
AlexNet에서는 relu layer 다음에 배치해서 데이터를 정규화한다. 요즘은 batch norm이 자리를 대신하고 있다. 가장 큰 차이는 BN은 학습할 수 있지만 LRN은 학습할 수 없다.
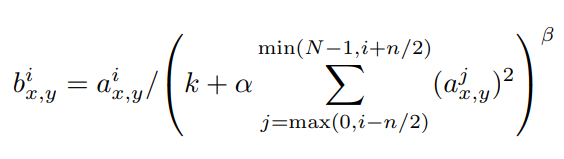
LRN은 위 점화식을 따른다. 는 LRN의 결과값, 는 relu의 결과값이다. 여기에서 번째 kernel에서 나온 feature map상의 행 열의 픽셀을 각각 로 표현하고, 은 kernel의 수다. 는 사용자가 정하게 돼있는데 특히 을 통해 feature map에서 몇 개의 channel에 걸쳐서 정규화할지 정한다.
3. Overlapping pooling
AlexNet은 따로 pooling layer를 따로 두지 않고 있지만 kernel을 겹치게 stride를 설계하는 방법으로 pooling을 하고 있다. 모델 구조에서 보면 뒷단으로 갈수록 feature map의 크기가 쪼그라든다고 알 수 있다. 이렇게 해서 결과적으로 0.4%정도 error rate를 낮추면서 overfitting을 방지하는 대신 연산량이 좀더 든다.
4. Dropout
머신러닝에서 여러 모델을 학습해서 평균내는 게 성능이 가장 좋다. 딥러닝 모델을 하나 학습하려면 며칠씩 걸리기도 해서 아무래도 꺼리는 학습기법이기도 하다. 그런데 이것을 각 유닛들을 일정 확률로 끄는 방법으로 혁신적으로 짧은 시간에 해주면서 overfitting까지 방지해준다.
이 연구에서는 FC layer에만 적용했고 dropout이 없는 모델은 overfitting이 굉장히 심했다고 서술하고 있다.
5. Data augmentation
데이터 차원에서 overfitting을 줄이는 방법이다. (256, 256)크기의 이미지를 각 모서리와 중앙 이렇게 5군데를 (224, 224)크기의 패치로 잘라낸 다음에 수평으로 뒤집어서 10개로 뻥튀기 했다.
그리고 나서 RGB를 기반으로 PCA를 진행하면서 top-1 오류를 1%낮추는 효과를 얻었다.
Training
학습은 120만개의 데이터를 128개의 batch size로 나눠서 90 epochs로 진행했다. Optimizer로 SGD momentum을 이용해서 momentum 계수는 0.9로, 학습률은 1e-2부터 시작해서 validation error가 개선하지 않으면 10으로 나눠줬다. weight decay는 0.0005로 했다.
weight는 평균이 0, 분산이 0.01인 정규분포로 초기화 했다. 2, 4, 5, FC layer의 bias는 1, 나머지 layer의 bias는 0으로 초기화했다.
Epilogue
- 요즘은 overfitting을 막아주는 기법이 많아져서 그런가 논문을 읽는 내내 연구자들이 overfitting에 집착하고 있다고 느껴졌다.
- 논문에서 (224, 224)크기의 이미지를 입력단에 넣으면 (55, 55)크기의 feature map을 출력한다고 하는데 계산해보면 (227, 227)크기의 이미지를 입력해야 (55, 55)가 된다. 연구자들이 padding을 까먹었든, 입력이미지 크기를 착각했든 둘 중에 한 가지겠지.
