컴퓨터와 데이터
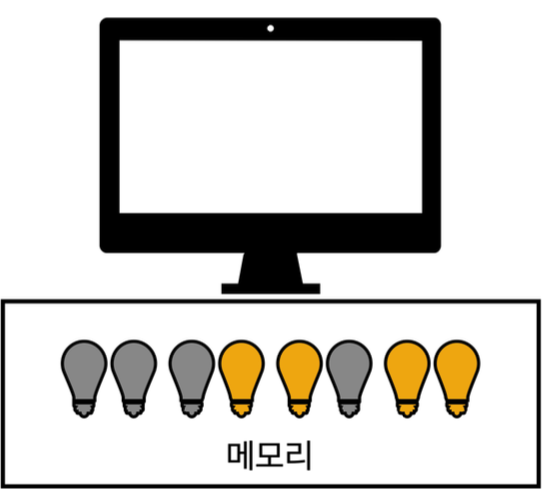
컴퓨터 메모리는 반도체로 구성, 트렌지스터들이 모여 하나의 반도체를 구성하고, 전기가 흐르고 안흐르고를 0과 1로 표기 = 이진수라 표현 (RAM)
2진수
전구를 켜고 끈다는 것은 0과 1만 나타낼수 있는 2진수로 표현
컴퓨터는 사람과 같이 10진수를 이해하고 숫자를 메모리에 저장, 불러오는 것이 아닌, 단지 상태만 변경 확인
8 bit = 1 byte
+) 음수표현
음수를 표현한다면 기호로 1bit를 사용한다
컴퓨터와 문자 인코딩 1
문자 인코딩 : 문자 집합을 통해 문자를 -> 숫자
문자 디코딩 : 문자 집합을 통해 숫자를 -> 문자
ASCII 문자 집합
서로 다른 컴퓨터간 문자가 올바르게 표시되지 않는 문제 발생, -> ASCII 표준 문자 집합 개발
아스키코드 표 표가 궁금하다면 들어가서 확인하자 !
컴퓨터와 문자 인코딩 2
UC-KR이나 MS949 같은 한글 문자표를 PC에 설치하지 않으면 다른 나라 사람들은 한글로 작성된 문서를 열
어볼 수 없는 상황. -> 유니코드 등장
유니코드
세계의 모든 문자들을 단일 문자 세트로 표한할 수 있는 유니코드
UTF-8
8bit(1byte) 기반, 가변 인코딩
1byte ~ 4byte를 사용해서 문자를 인코딩
- 1byte: ASCII, 영문, 기본 라틴 문자
- 2byte: 그리스어, 히브리어 라틴 확장 문자
- 3byte: 한글, 한자, 일본어
- 4byte: 이모지, 고대문자등
저장공간 절약과 네트워크 효율성 : UTF-8은 ASCII 문자를 포함한 많은 서양 언어의 문자에 대하 1byte를 사용. ASCII 문자로 이뤄진 영문 text에서는 UTF-8이 더 효율적
문자 집합 조회
package chap51.charset;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.Set;
import java.util.SortedMap;
public class AvailableCharsetMain {
public static void main(String[] args) {
//이용 가능한 Charset
SortedMap<String, Charset> charsets = Charset.availableCharsets();
for (String charsetName : charsets.keySet()) {
System.out.println("charsetName = " + charsetName);
}
System.out.println("==========");
//문자로 조회 -> MS949, ms949, x-windows-949
//Charset.forName 특정 집합을 찾을때
Charset charset1 = Charset.forName("MS949");
System.out.println("charset1 = " + charset1);
//별칭 조회
Set<String> aliases = charset1.aliases();
for (String alias : aliases) {
System.out.println("alias = " + alias);
}
//UTF-8 문자로 조회
Charset charset2 = Charset.forName("UTF-8");
System.out.println("charset2 = " + charset2);
//UTF-8 상수로 조회
Charset charset3 = StandardCharsets.UTF_8;
System.out.println("charset3 = " + charset3);
//시스템 기본의 Charset 조회
Charset defaultCharset = Charset.defaultCharset();
System.out.println("defaultCharset = " + defaultCharset);
}
}
Charset.availableCharsets()
모든 문자 집합을 조회 가능
Charset.forName()
특정 문자 집합을 지정해서 찾을때 사용. 인자로 문자 집합의 이름아나 별칭 사용 -> 대소문자 구분 X
별칭은 aliases 메서드 사용하면 구별 가능
Charset.defaultCharset()
현재 시스템에서 사용하는 기본 문자 집합 반환
문자 인코딩 예제 1
package chap51.charset;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
import static java.nio.charset.StandardCharsets.*;
public class EncodingEngine {
private static final Charset EUC_KR = Charset.forName("EUC-KR");
private static final Charset MS_949 = Charset.forName("MS949");
public static void main(String[] args) {
System.out.println("==ASCII 영문 처리==");
encoding("A", US_ASCII);
encoding("A", ISO_8859_1);
encoding("A", EUC_KR);
encoding("A", MS_949);
encoding("A", UTF_8);
encoding("A", UTF_16BE); // 2byte 단위로 하기 때문에 지원 X
System.out.println("==한글 지원==");
encoding("가", EUC_KR);
encoding("가", MS_949);
encoding("가", UTF_8); //한글에 대해서는 호한이 안됨
encoding("가", UTF_16BE);
}
//모든 문자를 byte로 변경할 때는 인코딩 표가 있어야 함
private static void encoding(String text, Charset charset) {
byte[] bytes = text.getBytes(charset);
System.out.printf("%s -> [%s] 안코딩 -> %s %sbyte\n", text, charset, Arrays.toString(bytes), bytes.length);
}
}
문자를 컴퓨터가 이해할 수 있는 숫자로 변경하는 것을 문자 인코딩
text.getBytes(charset); = String.getBytes(charset); 메서드 활용시, String -> byte로 변경
byte로 변경하려면 문자 집합 필요
문자 인코딩 예제 2
package chap51.charset;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
import static java.nio.charset.StandardCharsets.*;
public class EncodingEngineV2 {
private static final Charset EUC_KR = Charset.forName("EUC-KR");
private static final Charset MS_949 = Charset.forName("MS949");
public static void main(String[] args) {
System.out.println("==ASCII 영문 처리==");
test("A", US_ASCII, US_ASCII);
test("A", US_ASCII, ISO_8859_1);
test("A", EUC_KR, US_ASCII);
test("A", US_ASCII, MS_949);
test("A", US_ASCII, UTF_8);
test("A", US_ASCII, UTF_16BE); // 2byte 단위로 하기 때문에 지원 X
System.out.println("==한글 지원 기본==");
test("가", US_ASCII, US_ASCII);
test("가", ISO_8859_1, ISO_8859_1);
test("가", EUC_KR, EUC_KR); //한글에 대해서는 호한이 안됨
test("가", MS_949, MS_949);
test("가", UTF_8, UTF_8);
test("가", UTF_16BE, UTF_16BE);
System.out.println("==한글 인코딩 복잡한 문자 ==");
test("뷁", EUC_KR, EUC_KR);
test("뷁", MS_949, MS_949);
test("뷁", UTF_8, UTF_8);
test("뷁", UTF_16BE, UTF_16BE);
System.out.println("== 한글 인코딩, 디코딩이 다른 경우");
test("가", EUC_KR, MS_949);
test("뷁", MS_949, EUC_KR);
test("가", EUC_KR, UTF_8);
test("가", MS_949, UTF_8);
test("가", UTF_8, MS_949);
System.out.println("== 영문 인코딩 - 디코딩이 다른 경우 ==");
test("A", EUC_KR, UTF_8);
test("A", MS_949, UTF_8);
test("A", UTF_8, MS_949);
test("A", UTF_8, UTF_16BE);
}
//모든 문자를 byte로 변경할 때는 인코딩 표가 있어야 함
private static void test(String text, Charset encoding, Charset decoding) {
byte[] encoded = text.getBytes(encoding);
String decoded = new String(encoded, encoding);
System.out.printf("%s -> [%s] 인코딩 -> %s %sbyte -> [%s] 디코딩 -> %s\n",
text, encoding, Arrays.toString(encoded),
encoded.length,
decoding, decoded);
}
}
개발하는데 그렇게 필요한 내용은 아니지만 혹시 개발도중 한글이 깨지거나, 문자가 깨지는 일이 있다면 본인이 사용하고 있는 언어 default 값을 확인해보는 것도 하나의 방법일 듯 하다.
