퍼셉트론은 Nand, And, Or등의 게이트를 통해 컴퓨터가 수행하는 복잡한 처리도 표현할 수 있지만, weight를 결정하는 작업은 사람이 수동으로 작성해야한다.
신경망은 이 문제를 해결하는데, 신경망은 가중치의 적절한 값을 데이터로부터 자동으로 학습하는 성질을 갖고 있다.
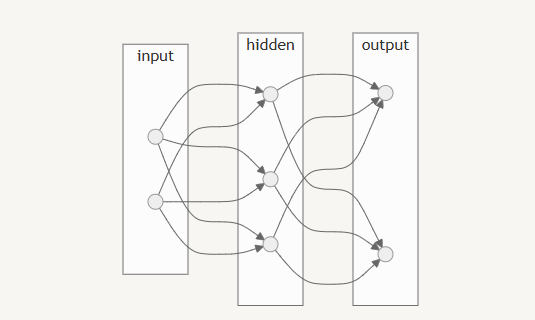
퍼셉트론에서 신경망으로
신경망의 가장 왼쪽 줄을 입력층 맨 오른쪽 층을 출력층, 나머지 중간층을 은닉층이라고 한다.
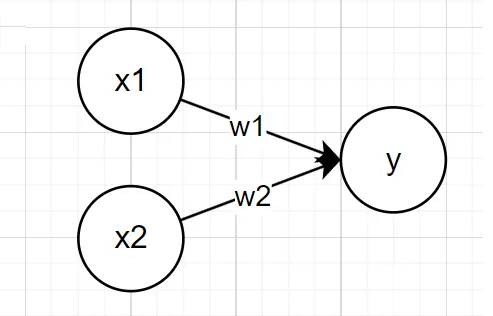
이전 파트에서 퍼셉트론을 다음과 같이 다이어그램으로 나타내었고
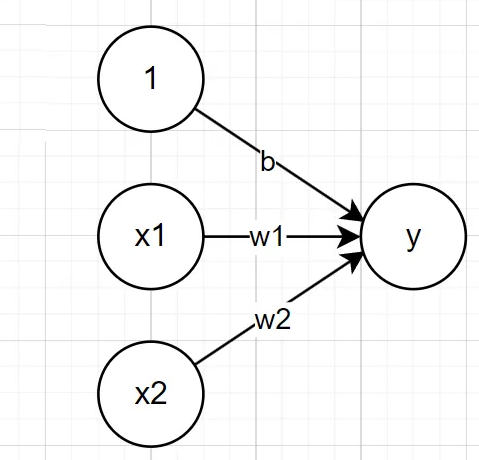
수식으로는 다음과 같다.
그런데 위 다이어그램과 수식을 비교했을때, 다이어그램에는 편향이 나타나있지 않기때문에 다음과 같이 명시적으로 추가해 줄 수 있다.
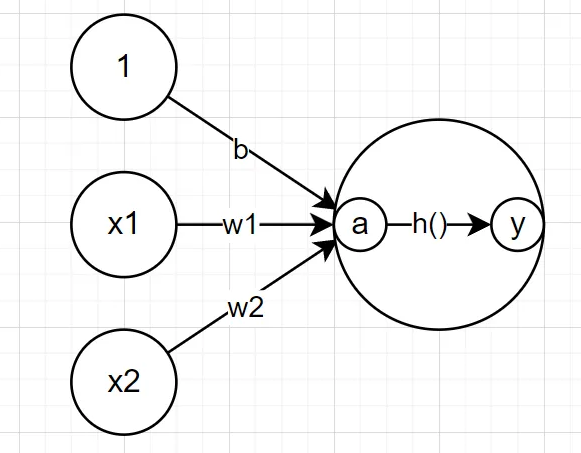
또한 위의 수식 또한 간결한 형태로 정리할 수 있다.
여기서 사용된 h(x)를 활성화 함수(activation function)이라고 한다.
이제 여기서 식을 조금 더 정리하게 되면
정리할 수 있고 이를 다시 다이어그램으로 다음과 같이 나타낼 수 있다.
활성화 함수
임계값을 경계로 출력이 바뀌는 활성화 함수는 계단 함수라고 한다.
위에서 정리한 퍼셉트론은 활성화 함수로 계단함수를 이용하고 있다.
그런데 여기서 계단함수가 아닌 다른함수를 사용하므로써 신경망을 구성할 수 있게된다.
시그모이드 함수
시그모이드 함수는 다음과 같은 수식으로 작성된다.

신경망에서는 활성화 함수로 시그모이드 함수를 이용하여 신호를 변환하고, 그 변환된 신호를 다음 뉴런에 전달한다.
계단함수 구현
퍼셉트론에 사용된 계단함수를 파이썬으로 작성하면 다음과 같다
from functools import singledispatch
import numpy as np
@singledispatch
def step_function(x):
raise NotImplementedError("Unsupported type")
@step_function.register(float)
def _(x):
return 1 if x > 0 else 0
@step_function.register(np.ndarray)
def _(x):
return np.array(x > 0, dtype=np.int)파이썬에선 오버로딩을 지원하지 않기때문에 데코레이터를 사용해서 오버로딩을 구현했다.
오버로딩으로 실수 입력 뿐만 아니라 numpy 배열로의 확장을 구현하였다.
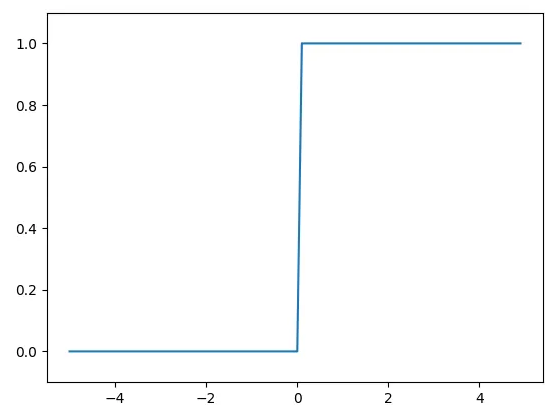
이를 그래프로 나타내면 다음과 같다
import matplotlib
matplotlib.use('TkAgg')
import numpy as np
import matplotlib.pyplot as plt
from step_function_perceptron import step_function
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()마치 계단처럼 생겼기 때문에 계단함수라고 한다.
시그모이드 함수 구현
def sigmoid(x):
return 1 / (1 + np.exp(-x))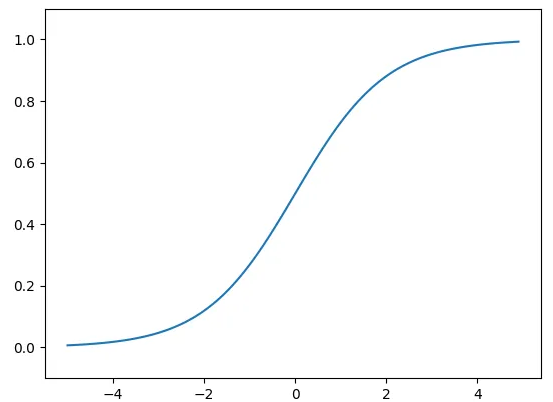
import matplotlib
matplotlib.use('TkAgg')
import numpy as np
import matplotlib.pyplot as plt
from sigmoid import sigmoid
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.show()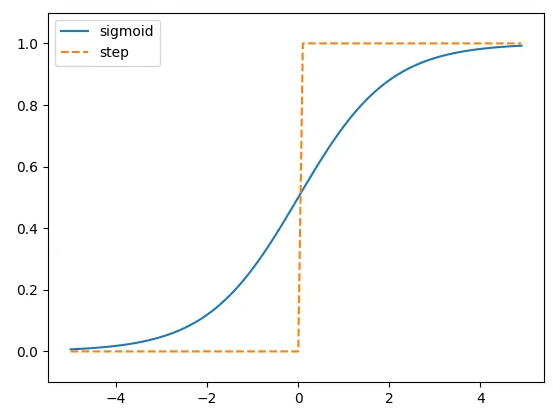
시그모이드 함수와 계단함수를 겹쳐놓고 그래프를 그려보았다.
시그모이드 함수는 곡선으로 되어 있으며, 입력에 따라 출력이 부드럽게 변화한다.
한편으로 계단함수는 임계값 0을 기준으로 출력이 갑자기 바뀐다.
또한 0, 1만 출력하는 계단 함수와는 다르게 시그모이드 함수는 실수로 출력을 돌려준다.
비선형 함수
계단 함수와 시그모이드 함수는 모두 비선형 함수이다. 신경망에서는 다음과 같은 점들 때문에 선형함수를 활성화 함수로 사용하지 못한다.
-
선형 함수는 신경망의 깊이 효과가 사라진다.
두 층의 신경망을 수식으로 다음과 같이 나타낼수 있다.
그런데 만약 활성화 함수가 선형이라면 이를 단순하게
로 나타낼 수 있고 이 식은 곧,
와 같은 형태이기 때문에 한 층의 신경망과 같은 효과를 낸다.
-
비선형 관계를 학습할 수 없다.
선형 함수는 선형적인 데이터만 처리할 수 있기 때문에, 비선형적인 데이터나, 복잡한 패턴이 필요한 문제에 대해서 성능이 크게 떨어진다.
ReLU(Rectified Linear Unit) 함수
신경망에서 가장 많이 사용되는 비선형 활성화 함수중 하나이다. 간단하지마 매우 효과적인 비선형성을 신경망에 도입해 주는 함수로 수식으로는 다음과 같이 나타낸다.
ReLU함수는 입력값이 0보다 크면 그대로 통과시키고, 0 이하이면 0으로 바꾸는 함수이다.
다른 함수들에 비해 계산비용이 적어서 부담이 적기때문에 많이 사용되고 있다.
import numpy as np
def ReLU(x):
return np.maximum(0, x)행렬곱으로 표현된 신경망
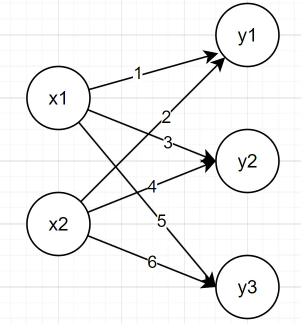
위의 그림과 같이 표현되는 신경망은 다음과 같은 수식으로 작성될 수 있다.
위 표현을 파이썬으로 작성하면 다음과 같다.
import numpy as np
X = np.array([1, 2])
W = np.array([[1, 3, 5], [2, 4, 6]])
Y = X@W
print(f"X.shape: {X.shape}")
print(f"W.shape: {W.shape}")
print(f"Y.shape: {Y.shape}")
print(f"Y: {Y}")
# result
# X.shape: (2,)
# W.shape: (2, 3)
# Y.shape: (3,)
# Y: [ 5 11 17]다층 신경망 구현
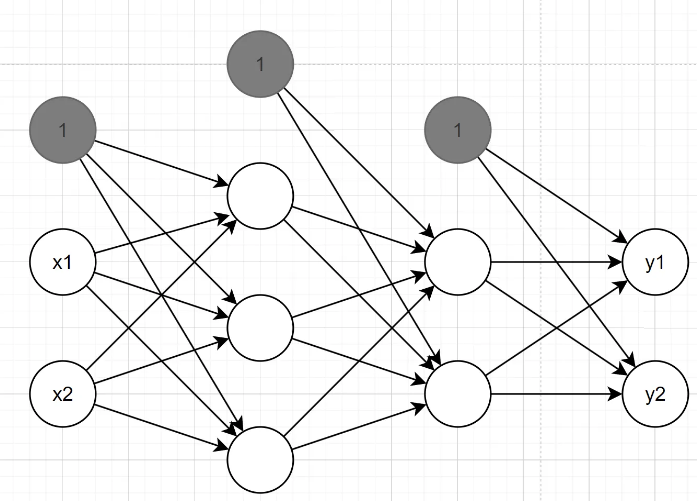
이번에는 편향 B까지 포함하여 다층 신경망을 구현해보자.
먼저 0층에서 1층까지의 계산은
으로 표현할 수 있으며, 여기서 활성화로 시그모이드 함수를 사용하여 신호를 변환하면
으로 나타낼 수 있다.
각각 2층, 3층까지의 결과는
로 나타낼 수 있다.
로 표현된 출력층의 활성화 함수는 항등함수로 일단 설정한다.
풀고자 하는 문제에 따라 출력층의 활성화 함수를 변경할 수 있다.
위에서 나타낸 다층 신경망을 파이썬으로 구현하면 다음과 같다
import numpy as np
from sigmoid import sigmoid
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
b1 = np.array([0.1, 0.2, 0.3])
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
b2 = np.array([0.1, 0.2])
W3 = np.array([[0.1, 0.3], [0.2, 0.4]])
b3 = np.array([0.1, 0.2])
x = np.array([1.0, 0.5])
a1 = x@W1 + b1
z1 = sigmoid(a1)
a2 = z1@W2 + b2
z2 = sigmoid(a2)
a3 = z2@W3 + b3
y = a3
print(f"y: {y}")
# y: [0.31682708 0.69627909]활성화 함수 두개
1. 항등함수 identity function
위에서 사용된 출력층의 활성화 함수인 항등함수는 입력과 출력이 같은 의 함수를 말한다.
2. 소프트맥스 함수 softmax function
소프트맥스 함수는 입력신호의 지수함수, 분모는 모든 입력신호의 지수 함수의 합으로 나타난다.
파이썬에서는 다음과 같이 작성된다.
import numpy as np
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return ya의 최댓값 c를 빼준값의 지수를 취하는 이유는 오버플로우를 피하기 위해서이다.
위와 같이 계산을 많이 해야하는 소프트맥스 함수를 사용하는 이유는 출력이 0에서 1사이로 나타난다는 것과, 출력의 총합이 1로 나타난다는 점이다.
출력의 총합이 1이라는 말은 곧 확률로 볼수 있다는 말이다.
요약
- 퍼셉트론의 한계: 가중치를 수동으로 결정해야 하는 문제점이 있다.
- 신경망의 도입: 가중치의 적절한 값을 데이터로부터 자동으로 학습할 수 있다.
- 활성화 함수: 비선형 함수(시그모이드, 계단 함수)의 중요성과 특징을 설명한다.
- ReLU 함수: 신경망에서 많이 사용되는 비선형 활성화 함수로, 계산 비용이 적다.
- 행렬곱으로 표현된 신경망: 신경망의 계산을 효율적으로 수행할 수 있다.
- 다층 신경망 구현: 여러 층으로 구성된 신경망의 구조와 계산 과정을 설명한다.
- 출력층의 활성화 함수: 항등함수와 소프트맥스 함수의 특징과 사용 목적을 설명한다.
- 소프트맥스 함수: 출력을 확률로 해석할 수 있게 해주며, 다중 클래스 분류에 유용하다.
