Lecture 4
Computational Graphs
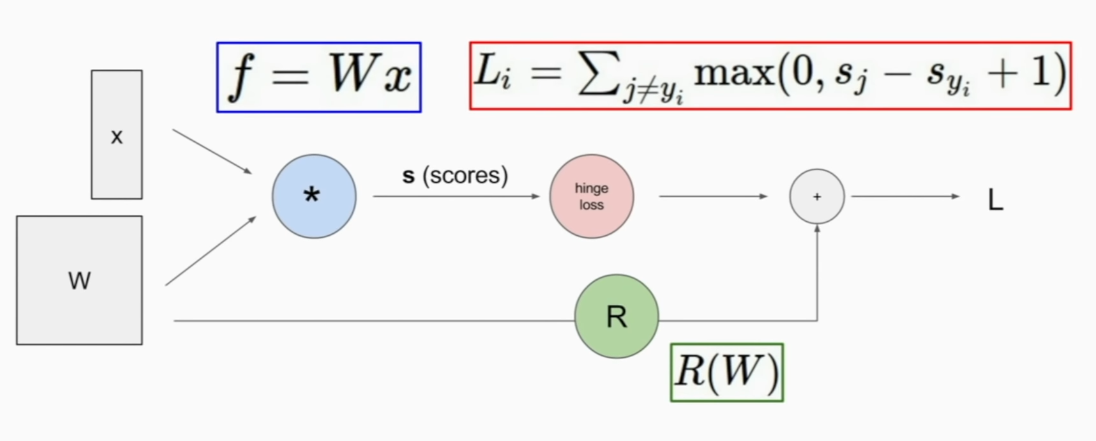
Backpropagation
Backpropagation => using chain rule
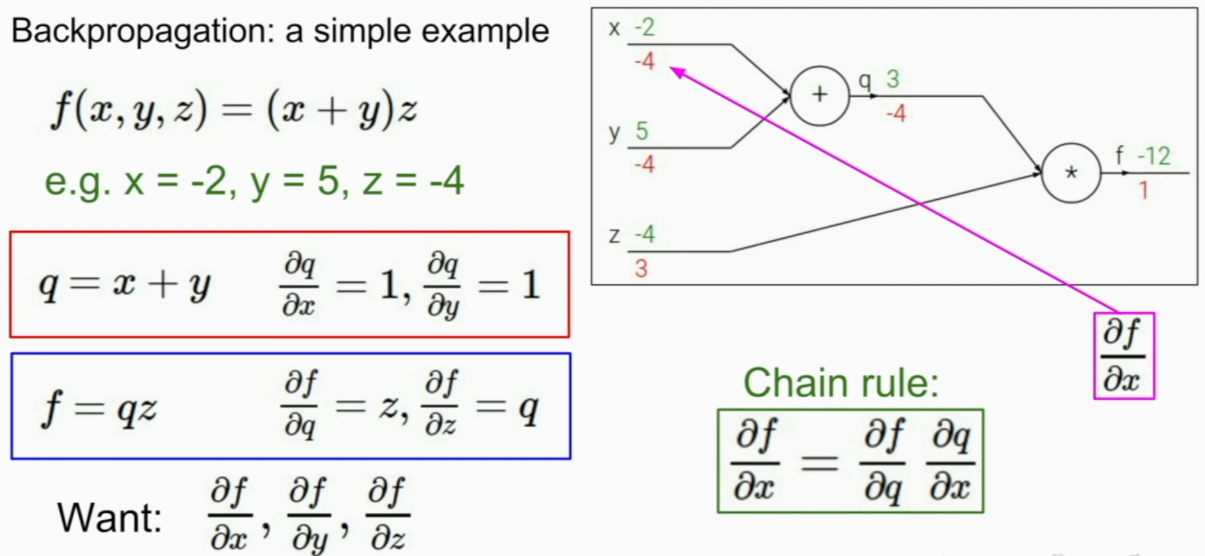
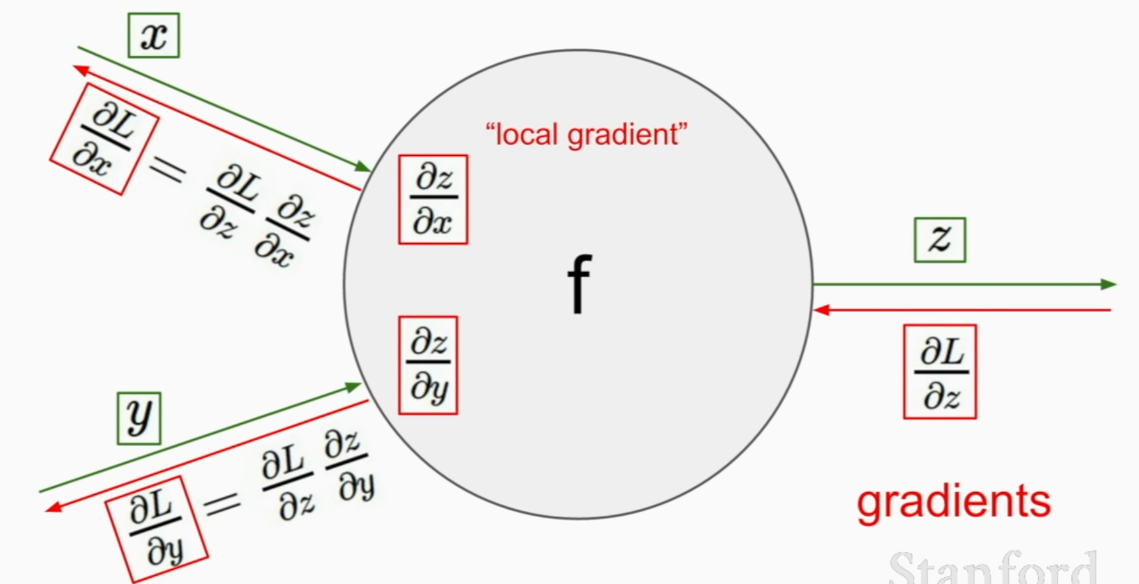
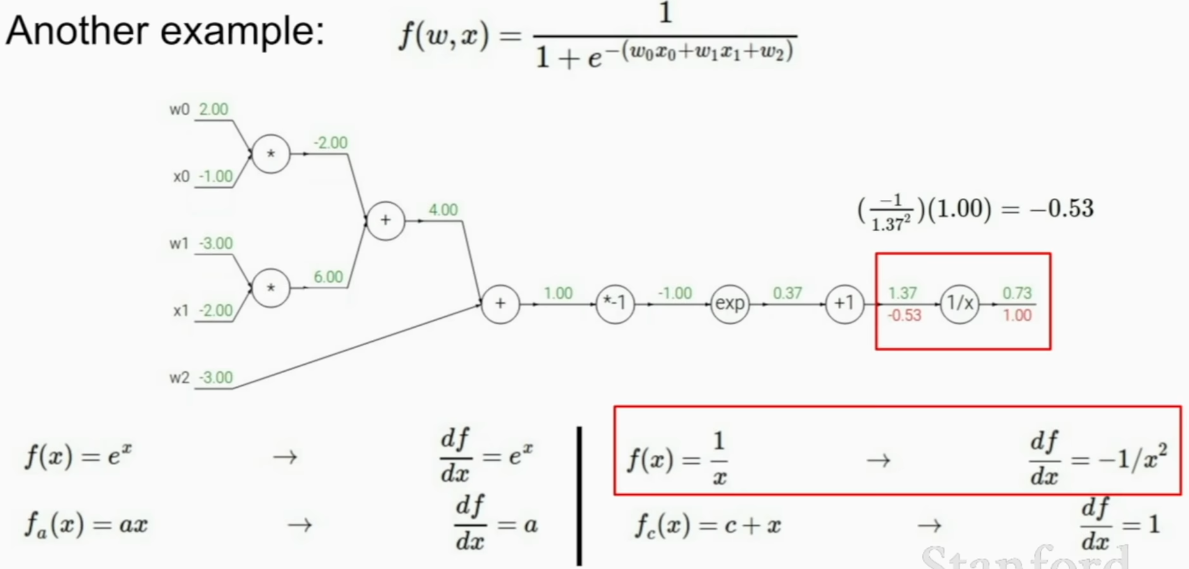
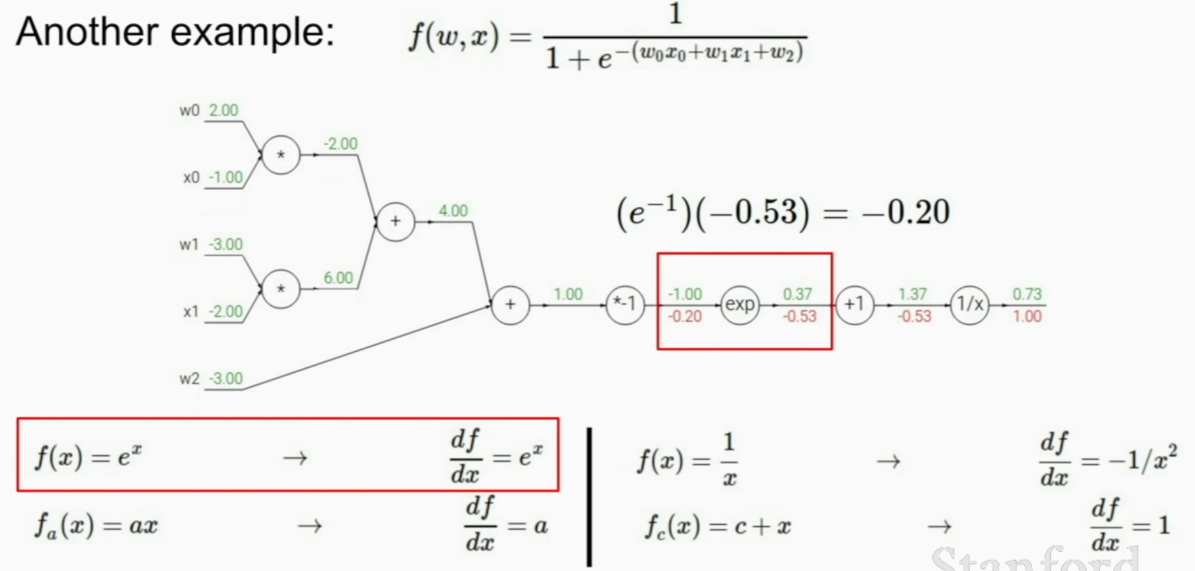
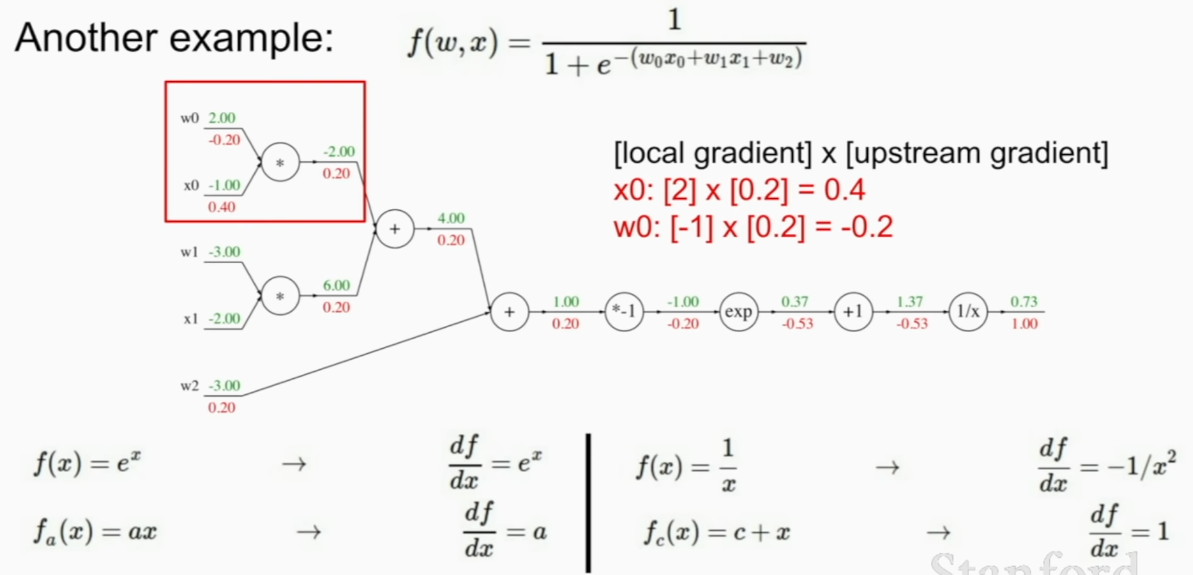
we can do it like this
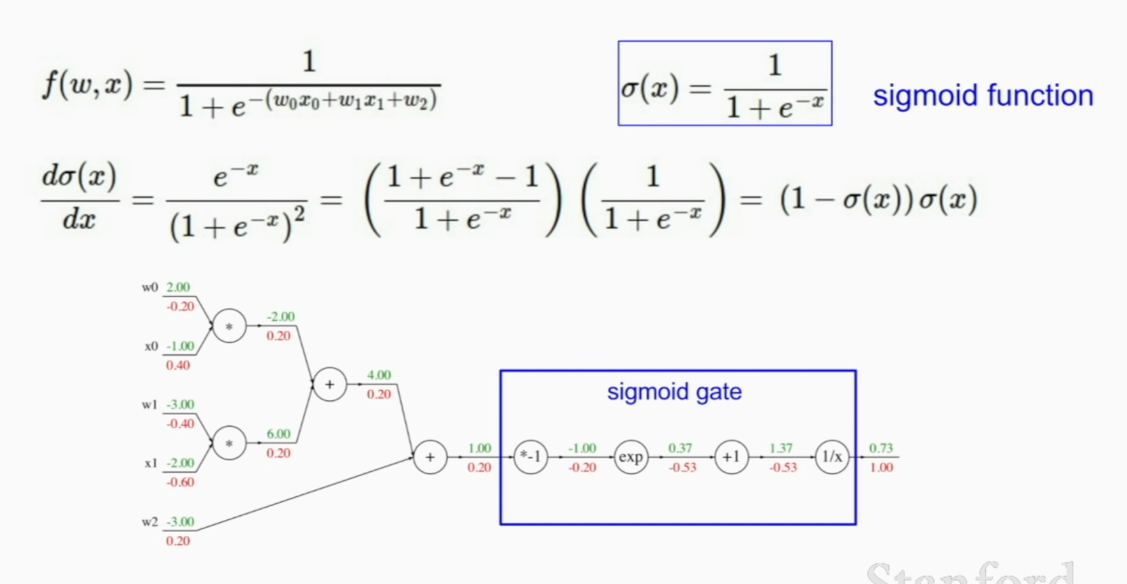
simpler to little be more complex group if you can derive local gradient.
max gate
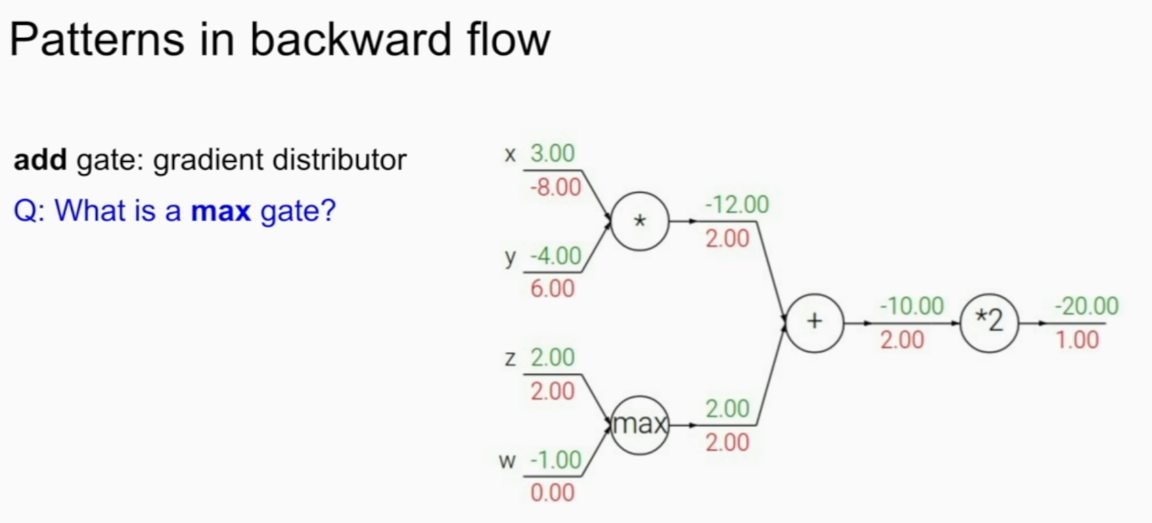
one will have full gradient of before while other will get gradient of 0.
because in forward path, also max value was used!
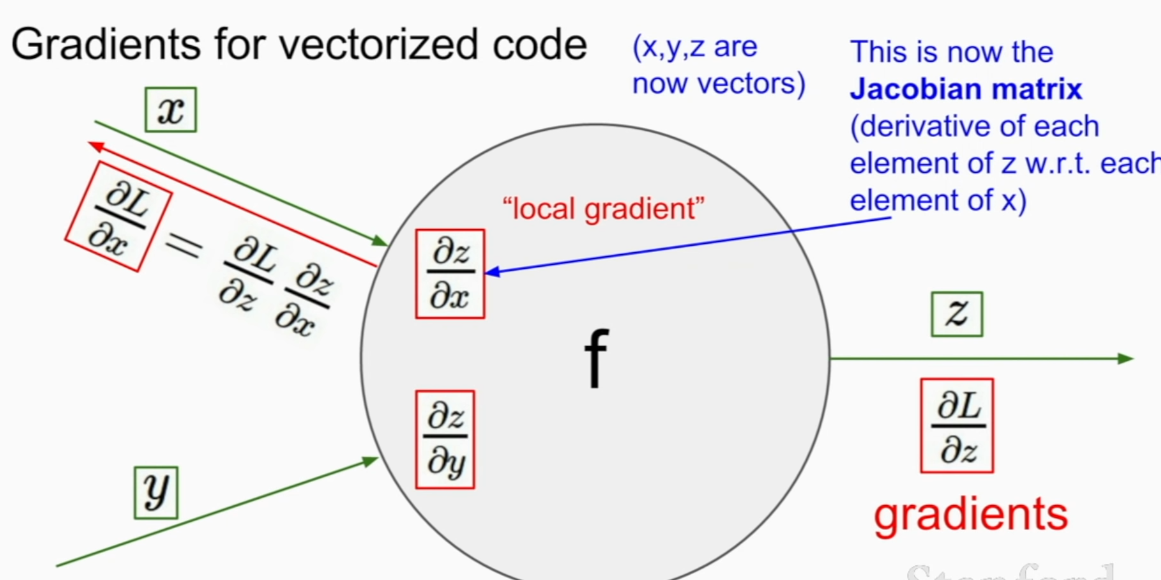

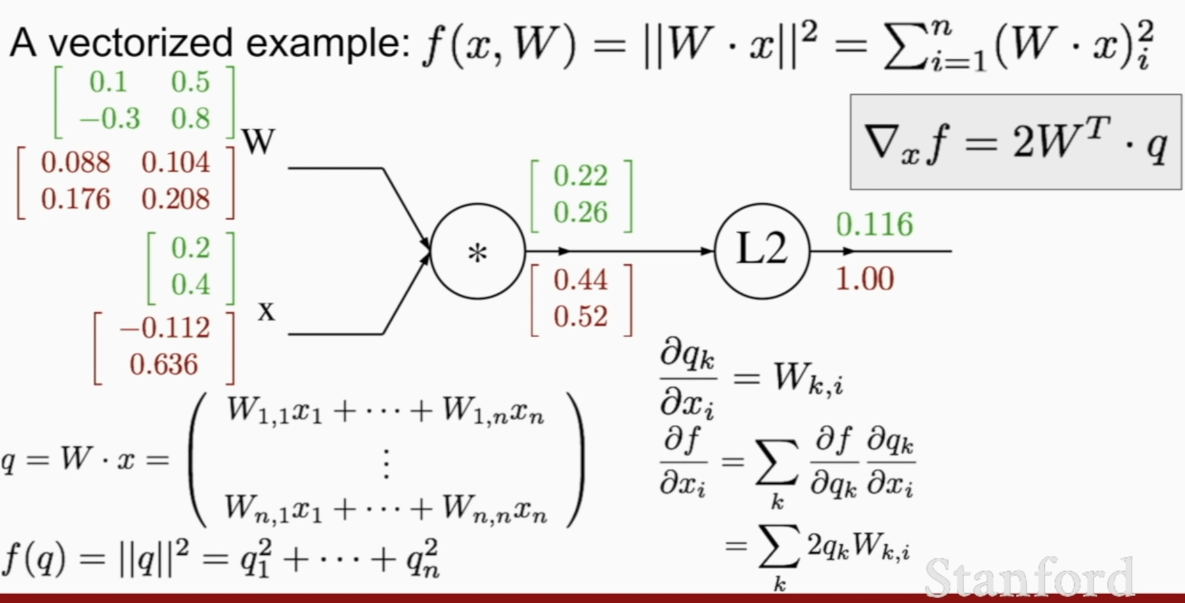
Jacobian Matrix will be just a diagonal matrix

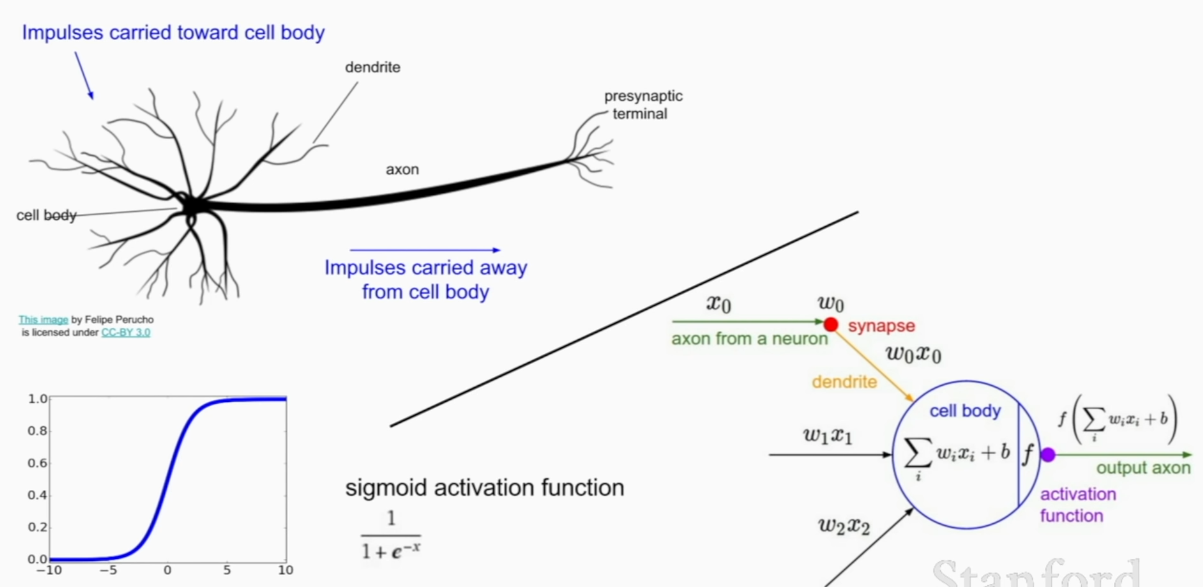
calculating how much does the number affect the final output
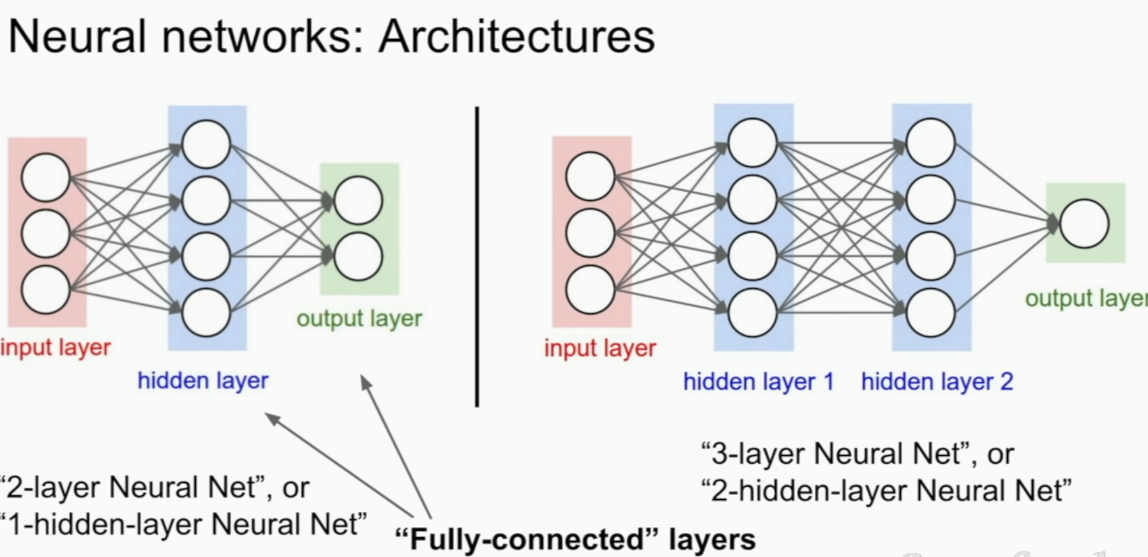
Neural Networks

non linearity is important!
multiple layers
h is value of scores of each of templates on W1
W2 weights all of them
h is right after the non linearity