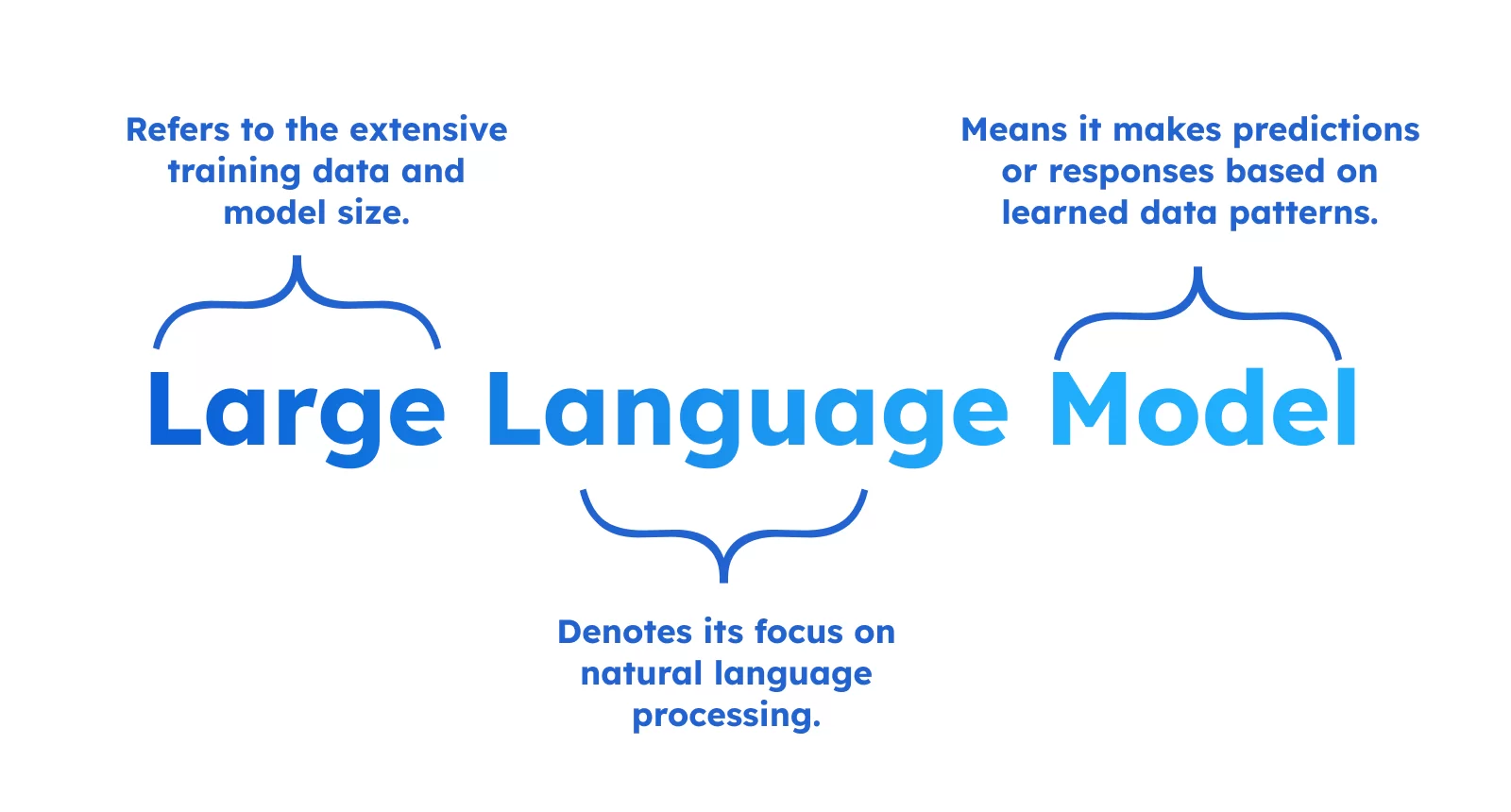
1. 언어 모델의 발전
인공지능의 핵심 기술 중 하나인 언어 모델(Language Model, LM) 은 “텍스트 시퀀스에서 다음에 올 토큰을 예측”하는 확률 모델입니다. 언어 모델은 n-그램 통계 기반에서 출발해 지금은 GPT-4 같은 거대한 모델로 발전했습니다. 그리고 오늘날 SLM → NLM(RNN/LSTM 같은 신경망 기반) → PLM(대규모 사전 학습 모델) → LLM(대형 언어 모델) 까지 진화해왔습니다.
1. LM이란 무엇인가?
언어 모델(Language Model, LM)은 텍스트 시퀀스의 확률을 계산하고, 그 확률을 기반으로 자연스럽게 이어질 다음 토큰(단어 또는 서브워드 조각)을 예측합니다.
수학적으로는 다음과 같이 표현할 수 있습니다.

즉, “관찰한 문맥에서 다음에 나올 단어의 조건부 확률을 맞추는 것”이 언어 모델의 핵심입니다.
예를 들어, “나는 오늘 아침에 커피를 ___” 이라는 문장에서 LM은 “마셨다”라는 단어의 확률을 높게, “갔다”라는 단어의 확률을 낮게 부여합니다.
그런데 문제는, 컴퓨터는 문자나 단어 자체를 이해할 수 없다는 점입니다. “커피”라는 단어를 그대로 주면, 모델은 이를 처리할 수 없습니다. 따라서 언어 모델이 제대로 작동하려면 텍스트를 먼저 숫자(벡터)로 변환해야 합니다. 이 과정을 크게 두 단계로 나눌 수 있는데, 바로 토큰화(Tokenization)와 임베딩(Embedding)입니다.
2. 텍스트를 숫자로 바꾸는 과정: 토큰화와 임베딩
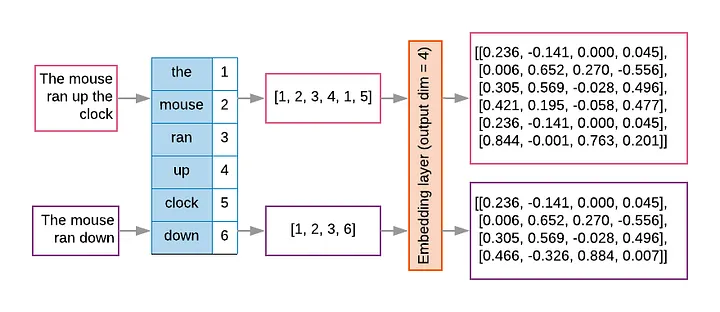
1. 토큰화(Tokenization)
텍스트는 먼저 토큰(token) 단위로 잘려야 모델이 처리할 수 있습니다.
-
단어 기반 토큰화: 직관적이지만, 희귀 단어·오타 처리에 취약합니다.
-
서브워드 기반 토큰화 (BPE, WordPiece, Unigram 등): 단어를 더 작은 단위로 분해하여, 희귀 단어도 조합 가능. 대부분의 최신 LLM에서 사용됩니다.
-
예:
- 단어 기반: "unbelievable" → ["unbelievable"]
- 서브워드 기반: "unbelievable" → ["un", "believ", "able"]
2. 임베딩(Embedding)
토큰은 곧바로 처리할 수 없으므로, 각 토큰을 고차원 벡터 공간으로 변환합니다.
- 예: “coffee” → [0.12, -0.45, …, 0.78] (768차원 벡터)
- 학습 과정에서 의미가 유사한 단어는 벡터 공간에서도 가깝게 위치합니다.
즉, 토큰화는 “잘게 쪼개는 과정”, 임베딩은 “숫자로 바꾸는 과정”이라고 볼 수 있습니다.
3. 언어 모델 학습 방식
1. 순방향(인과적) 예측: Causal LM
- 목표: 이전 단어들을 기반으로 다음 단어를 예측
- 대표 모델: GPT 시리즈 (GPT-2, GPT-3, GPT-4, LLaMA 등)
- 장점: 자연스럽고 긴 문장을 생성하는 데 강력
- 활용: 대화형 AI, 글쓰기, 코드 생성
2. 양방향 예측: Masked LM
- 목표: 문장에서 마스킹된 토큰을 예측
- 대표 모델: BERT, RoBERTa 등
- 장점: 문맥 이해와 표현 학습에 최적 → 분류, 감정 분석, 정보 추출 등에 활용
- 예시
- 입력: “나는 오늘 아침에 [MASK]를 마셨다”
- 출력: “커피”
3. 변형 학습: Permutation / Span 예측
- XLNet: 토큰 순서를 무작위로 섞어 예측 (순열 기반) → 더 유연한 문맥 반영
- T5: 문장에서 특정 구간(span)을 마스킹 후 복원 → 번역, 요약에 강함
4. 인코더–디코더 구조: Seq2Seq
- 구조: 입력(Encoder) → 출력(Decoder)
- 대표 모델: T5, BART, mT5
- 장점: 입력과 출력이 다른 텍스트일 때 강력 (번역, 요약 등)
- 예시: 영어 → 한국어 번역, 문서 요약
4. 정리
- LM의 본질: “문맥을 기반으로 확률 분포를 학습해, 가장 자연스러운 토큰을 예측하는 모델”
- 텍스트 처리: 토큰화 → 임베딩 → 확률 계산
- 학습 목표별 구분
- Causal LM → 생성 최적화
- Masked LM → 이해 최적화
- Seq2Seq → 입력–출력 변환 최적화
5. 언어 모델(Language Model, LM) 발전 과정 정리
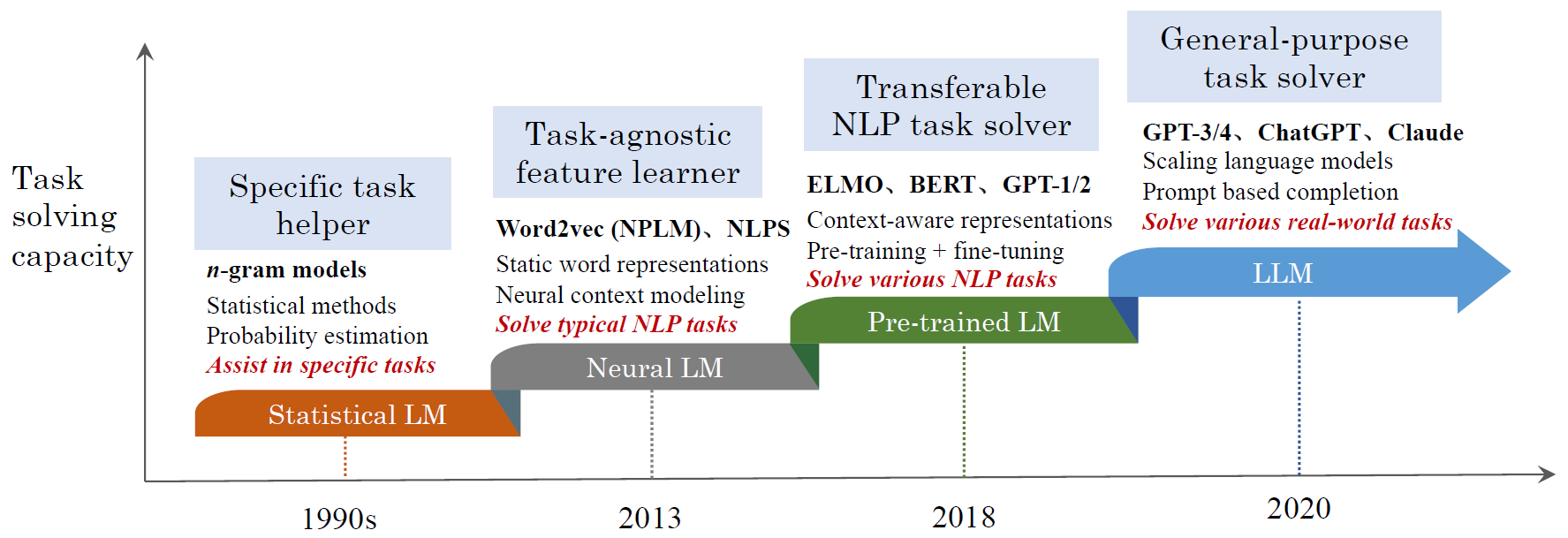
앞서 LM의 기본 개념과 구조를 살펴봤다면, 이번에는 언어 모델이 어떻게 발전해왔는지 시대별로 정리해 보겠습니다. LM은 단순한 확률 모델에서 시작해, 오늘날의 거대하고 지능적인 LLM으로 진화하기까지 여러 단계를 거쳤습니다.
1. 통계적 언어 모델 (SLM, Statistical Language Model)
초기 언어 모델은 N-그램(N-gram)이라는 통계적 접근법에 의존했습니다. N-그램은 다음에 올 단어를 예측하기 위해 직전의 N-1개 단어만 참고하는 방식입니다.
- 기술: n-gram, 마르코프 체인 기반 확률 계산
- 특징
- 문장에서 단어가 등장할 확률을 단순히 통계적으로 계산.
- n-그램 모델: 최근 n개의 단어를 기준으로 다음 단어의 확률을 추정.
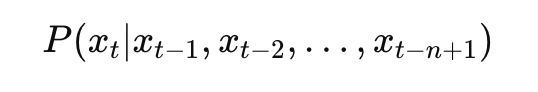
예를 들어, Tri-gram(3-그램)은 “오늘" "아침에” 다음에 “커피”가 나올 확률을 말뭉치에서 계산합니다.
- 활용: 입력기 자동완성, 맞춤법 교정
입력: "나는 오늘 아침에"
출력: "밥"- 장단점
- 장점: 단순하고 빠르며 계산량이 적음.
- 한계: 긴 문맥 반영 불가, 희귀 조합(OOV 문제)에 취약, 데이터가 커질수록 맥락이나 몇 문단 전의 중요한 정보를 기억하지 못함.
2. 신경 언어 모델 (NLM, Neural Language Model)
다음으로는 신경망 기반 언어 모델이 등장했습니다. 단순히 단어 빈도를 세는 것이 아니라, 단어를 벡터로 표현하고 문맥을 이해합니다.
- 기술: Word2Vec, RNN, LSTM
- 특징
- SLM의 한계를 극복하기 위해 인공 신경망 도입.
- 단어를 벡터(임베딩)로 변환 후, RNN/LSTM/GRU 같은 순환 구조로 문맥을 반영.
- 단어 의미를 벡터로 표현, 문맥 이해 가능
- 활용: 기계 번역, 감정 분석, 텍스트 분류
입력: "I love you"
출력: "나는 너를 사랑해"- 장단점
- 장점: 문맥 이해력 향상, 다양한 NLP 작업(기계 번역, 감정 분석 등)에 활용.
- 한계: 장기 의존성 문제(gradient vanishing/exploding), 병렬 학습 어려움, 대규모 학습의 한계.
3. 사전 학습된 언어 모델 (PLM, Pre-trained Language Model)
PLM은 대규모 데이터로 사전학습(Pretraining) 하고, 특정 작업에 맞게 미세조정(Finetuning) 하는 모델입니다.
- 기술: Transformer 구조, Pretraining → Fine-tuning (전이학습)
- 특징: 대규모 텍스트 데이터로 사전 학습, 다양한 NLP 작업에 쉽게 적용 (QA, 요약, 분류 등), 적은 라벨 데이터로도 높은 성능
- 활용: 검색 엔진 질의응답, 뉴스 요약 서비스, 챗봇 시스템
문단: "파리는 프랑스의 수도이다."
질문: "프랑스의 수도는?"
출력: "파리"-
장단점
- 장점: 소량의 라벨 데이터만 있어도 좋은 성능, 다양한 NLP 작업에 범용 적용 가능.
- 한계: 모델 크기와 학습 비용 증가, 특정 태스크 적용 시 추가 파인튜닝 필요.
- 단순 단어 매칭이 아니라 문단 전체 의미를 이해해 정답을 뽑아냅니다.
4. LLM (Large Language Model)
PLM을 초대형으로 확장한 것이 LLM입니다. GPT-3, GPT-4, PaLM, LLaMA 같은 모델이 여기에 해당합니다.
- 기술: 초거대 Transformer (수십억~수천억 파라미터), Zero-shot / Few-shot Learning
- 특징: 복잡한 추론과 창의적 문제 해결 가능, 다양한 작업을 하나의 모델로 처리 가능 (범용 AI 성격), 대화형 인터페이스로 직관적 사용
- 활용: ChatGPT 같은 대화형 AI, 코드 자동 생성, 멀티모달 AI (텍스트+이미지+음성 이해)
프롬프트: "이 문장을 일본어로 번역하고, 영어로 요약해줘: '나는 오늘 아침에 지하철을 타고 회사에 갔다.'"
출력 (일본어): "私は今朝地下鉄に乗って会社に行きました。"
출력 (영어 요약): "Went to work by subway this morning."별도의 학습 없이, 번역 + 요약이라는 복합 작업을 동시에 수행합니다. GPT-3, GPT-4 같은 모델이 바로 여기에 해당합니다.
-
장단점
- 장점: 뛰어난 생성 능력, 대화형 AI, 요약, 번역, 코드 작성, 창작 활동 등 다양한 분야 활용.
- 한계:
- 환각(Hallucination) 문제 (사실과 다른 내용을 자신있게 말함).
- 높은 학습·추론 비용.
- 최신 지식 반영 한계 → RAG(검색 증강 생성), 파인튜닝 필요.
5. 발전 과정 요약
| 세대 | 핵심 기술 | 대표 모델 | 장점 | 한계 |
|---|---|---|---|---|
| SLM | n-그램 | n-gram | 단순, 빠름 | 긴 문맥 불가, OOV |
| NLM | RNN/LSTM | Elman RNN, LSTM | 문맥 이해 가능 | 장기 의존성, 병렬화 한계 |
| PLM | 사전 학습 + 파인튜닝 | BERT, GPT | 범용 적용, 전이학습 | 학습 비용 증가 |
| LLM | 초대규모 트랜스포머 | GPT-4, Claude | 복잡한 작업 처리, 범용성 ↑ | 환각, 비용, 최신성 문제 |
2. 대규모 언어 모델(LLM) 이란?
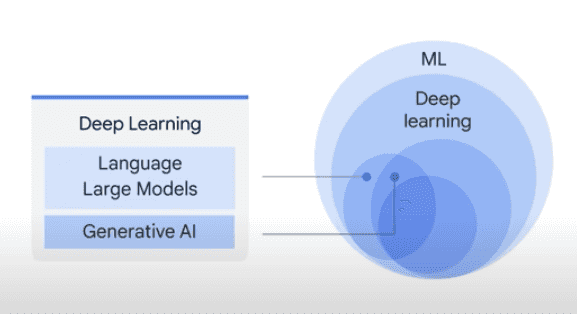
대규모 언어 모델(LLM)은 딥러닝의 하위 집합으로, 사전에 훈련된 후 특정 목적을 위해서 정교하게 튜닝될 수 있는 범용언어모델(general-purpose Language model) 입니다. 이 모델은 텍스트 분류, 질문 답변, 번역, 요약, 생성 등 다양한 자연어 처리(NLP) 작업을 수행할 수 있습니다.
가장 중요한 특징은 트랜스포머(Transformer) 아키텍처를 사용한다는 점입니다. 트랜스포머는 데이터 시퀀스 내 서로 다른 단어들 간의 관계를 거리와 상관없이 파악할 수 있도록 설계된 구조입니다. 덕분에 문맥을 깊이 이해하고, 앞뒤 맥락을 고려한 자연스러운 텍스트 생성을 가능하게 합니다.
또한, LLM은 수십억~수천억 개의 매개변수(parameter)를 가지고 있는데, 이를 일종의 지식 저장소로 볼 수 있습니다. 모델은 훈련 과정을 통해 이 매개변수를 조정하면서 언어 패턴과 의미를 학습합니다.
1. 트랜스포머 아키텍처 기반
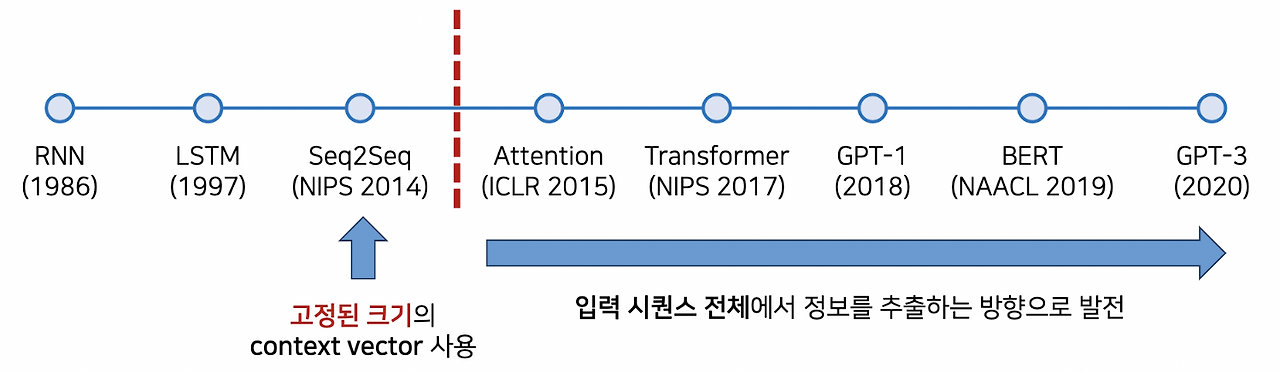
2015년 이전 기계번역에서는 Seq2Seq(LSTM 기반) 모델이 주로 쓰였으나, 고정된 크기의 context vector 한계로 성능 제약이 있었습니다. 이를 개선하기 위해 Attention 메커니즘이 도입되어 번역 성능이 크게 향상되었지만, 여전히 RNN의 장기 의존성 문제가 존재했습니다. 이후 2017년 구글의 Transformer 논문에서 RNN 없이 Attention만 사용하는 방식이 제안되며 획기적인 성능 개선이 이루어졌습니다.
- 핵심 흐름: Seq2Seq → Attention → Transformer
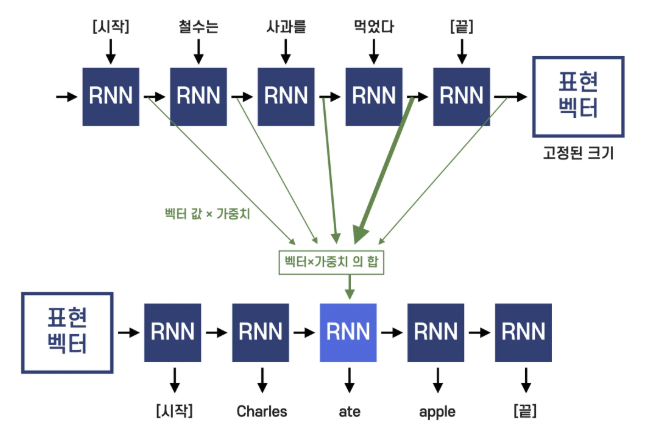
1. Seq2Seq (2014, Sutskever et al.)
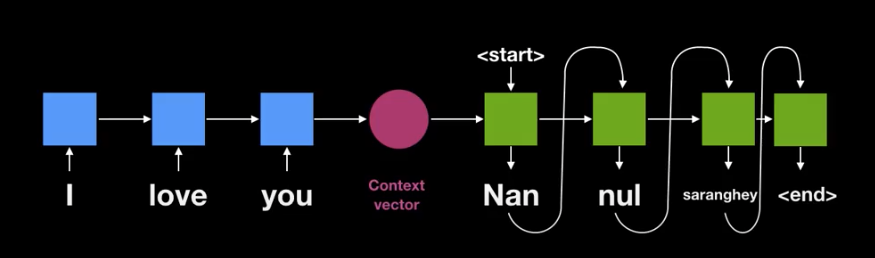
1. 구조
-
인코더(Encoder): RNN(LSTM/GRU)을 사용하여 입력 문장을 단어 단위로 읽고, 마지막 은닉 상태를 컨텍스트 벡터(context vector) 로 요약.
-
디코더(Decoder): 인코더가 만든 벡터를 초기 상태로 하여 번역 문장을 한 단어씩 생성. 학습 시에는 Teacher Forcing 기법으로 정답 단어를 입력해 빠르게 학습.
2. 한계
-
긴 문장을 하나의 고정 크기 컨텍스트 벡터에 압축해야 하므로 정보 손실 발생.
-
RNN은 순차적 구조로 인해 멀리 떨어진 단어 간의 관계를 학습하기 어려움(그래디언트 소실/폭주).
-
순차 계산 특성 때문에 병렬화가 어렵고 학습이 느림.
2. Attention 메커니즘 (2015)
Seq2Seq 한계를 해결하기 위해 나온 것이 바로 Attention입니다. 2015년 Bahdanau et al.이 제안한 이 아이디어는 간단하지만 강력합니다.
1. 구조
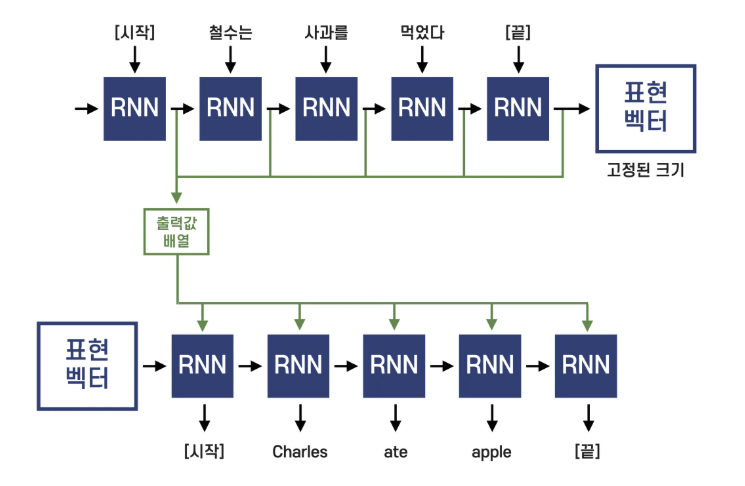
- 디코더가 단어를 생성할 때 전체 입력 문장을 다시 “참조”할 수 있도록 합니다.
- 고정된 하나의 벡터가 아니라, 인코더의 각 시점(hidden state)을 가중합으로 활용합니다.
- 즉, “현재 번역해야 하는 단어와 관련된 부분에 집중(attend)”할 수 있게 된 것입니다.
2. 예시
“I love you” → “나는 너를 사랑해” 번역 시,
- “나는”을 생성할 때는 “I”에 더 높은 가중치를,
- “너를”을 생성할 때는 “you”에 더 높은 가중치를 두는 방식입니다.
이 접근은 사람의 번역 방식과도 유사했습니다. 사람 역시 문장을 통째로 외우는 것이 아니라, 필요할 때마다 원문을 참고하기 때문입니다.
3. 효과
- 기계번역 성능이 눈에 띄게 향상되었습니다.
- RNN/LSTM의 장기 의존성 문제를 완전히 없애지는 못했지만, 정보 손실 문제는 크게 완화되었습니다.
3. Transformer 아키텍처 (2017)
“RNN이나 LSTM을 아예 없애고, Attention만으로 번역할 수 있지 않을까?” 2017년, 구글은 논문 “Attention is All You Need”를 통해 이를 현실로 만들었습니다. 바로 Transformer 모델입니다.
1. 구조
-
순차적 처리 제거
- RNN은 입력을 한 단어씩 순차적으로 처리해야 하지만, Transformer는 병렬 처리가 가능합니다.
- 이는 학습 속도와 효율성에서 엄청난 도약을 의미했습니다.
-
Self-Attention 메커니즘
- 입력 문장 내 단어들이 서로 어떤 관계를 맺고 있는지 직접 학습합니다.
- 예를 들어, “bank”라는 단어가 “river bank”인지 “financial bank”인지 문맥에 따라 달라지는데, Self-Attention은 이런 문맥적 의존성을 효과적으로 포착합니다.
-
스케일 확장성
- 모델 크기를 키우는 것만으로도 성능이 계속 올라갔습니다.
- 이는 이후 GPT, BERT, T5 같은 대규모 언어모델로 이어졌습니다.
2. 결과
-
기계번역뿐만 아니라, 텍스트 분류, 요약, 질의응답 등 거의 모든 NLP 과제에서 Transformer가 표준이 되었습니다.
-
오늘날 ChatGPT 같은 대규모 언어모델 역시 Transformer 구조 위에 세워져 있습니다.
2. Transformer 아키텍처의 3가지 유형
2017년 구글의 “Attention is All You Need”가 Transformer를 제시하며 NLP에 혁명을 일으켰고, 오늘날 ChatGPT 같은 서비스의 기반이 되었습니다. Transformer 계열 모델은 인코더·디코더 조합 방식에 따라 세 가지 유형으로 나뉘며, 조합에 따라 특성과 용도가 달라집니다. 아래 내용에서 이 3가지 유형의 모델들을 간단히 살펴보겠습니다.
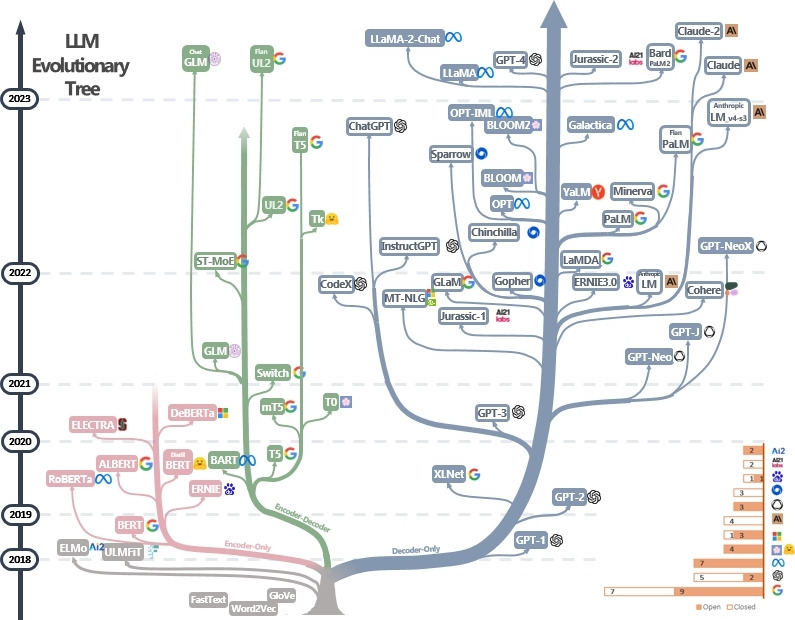
그림에서 분홍색 가지는 Encoder 구조만 사용한 모델들이고, 초록색은 Encoder - Decoder 구조를, 파란색은 Decoder 구조만 사용한 모델들입니다. 3가지 유형의 모델들은 간략하게 알아 보겠습니다.
1. 인코더-디코더 모델 (Encoder-Decoder, Seq2Seq)
1. 작동 원리와 특징
인코더-디코더 모델은 원래 Transformer 논문에서 제안된 완전한 형태의 구조입니다. 이름 그대로 인코더와 디코더, 두 개의 큰 블록으로 구성되어 있습니다.
인코더: 입력 문장을 받아 그 의미를 압축된 벡터 표현으로 변환합니다
Context Vector: 인코더의 출력이 문장의 전체 맥락을 담은 중간 표현이 됩니다
디코더: 이 압축된 정보를 바탕으로 목표 출력을 순차적으로 생성합니다
마치 통역사가 한국어를 듣고 머릿속에서 의미를 이해한 다음, 영어로 다시 말하는 과정과 비슷합니다.
2. 대표적인 모델들
-
T5 (Text-to-Text Transfer Transformer)
- Google이 2019년에 발표한 모델로, 모든 NLP 작업을 "텍스트 입력 → 텍스트 출력" 형태로 통일했습니다
- "translate English to German: Hello" → "Hallo" 같은 방식으로 작동합니다
- 11B 파라미터 버전까지 공개되어 있으며, 다양한 작업에서 균형 잡힌 성능을 보입니다
-
BART (Bidirectional and Auto-Regressive Transformers)
- Facebook AI Research가 개발한 모델로, BERT의 양방향 인코딩과 GPT의 자기회귀 디코딩을 결합했습니다
- 특히 텍스트 요약과 생성 작업에서 뛰어난 성능을 보입니다
- 노이즈 제거(denoising) 방식으로 사전 학습되어 손상된 텍스트 복원에도 강점이 있습니다
-
mT5 (multilingual T5)
- T5의 다국어 버전으로, 101개 언어를 지원합니다
- 한국어를 포함한 비영어권 언어 처리에 효과적입니다
3. 주요 활용 분야
인코더-디코더 모델은 입력과 출력의 형태가 다른 변환 작업에 특히 적합합니다.
- 기계 번역: 한 언어를 다른 언어로 변환
- 텍스트 요약: 긴 문서를 핵심만 담은 짧은 텍스트로 압축
- 질의응답: 지문을 읽고 질문에 대한 답변 생성
- 대화 시스템: 대화 맥락을 이해하고 적절한 응답 생성
4. 현재 위치와 전망
GPT 같은 디코더 전용 모델의 부상으로 상대적으로 주목도가 떨어졌지만, 특정 작업에서는 여전히 최고의 선택입니다. 특히 입력과 출력의 길이가 크게 다르거나, 구조적 변환이 필요한 작업에서는 디코더 전용 모델보다 효율적일 수 있습니다.
2. 인코더 전용 모델 (Encoder-Only)
인코더 전용 모델은 텍스트를 생성하는 것이 아니라 깊이 있게 이해하는 것이 목표입니다. 양방향(bidirectional) 어텐션을 사용해 문장의 모든 단어가 서로를 참조할 수 있어, 문맥을 완벽하게 파악할 수 있습니다.
1. 핵심 특징
- 양방향 어텐션: 각 단어가 문장 내 모든 다른 단어와 상호작용
- Masked Language Modeling (MLM): 일부 단어를 가리고 예측하는 방식으로 학습
- 문맥 표현: 같은 단어라도 문맥에 따라 다른 벡터로 표현됨
예를 들어 "배가 고프다"와 "배를 타다"에서 '배'는 전혀 다른 의미인데, 인코더 모델은 이를 정확히 구분할 수 있습니다.
2. 대표적인 모델들
-
BERT (Bidirectional Encoder Representations from Transformers)
- 2018년 Google이 발표한 혁명적인 모델
- 11개 NLP 작업에서 당시 최고 성능을 달성
- Base(110M) 버전과 Large(340M) 버전 존재
- 한국어 버전인 KoBERT, KoELECTRA 등도 활발히 개발됨
-
RoBERTa (Robustly Optimized BERT Pretraining Approach)
- Facebook AI가 BERT를 개선한 모델
- 더 많은 데이터와 긴 학습으로 성능 향상
- 동적 마스킹, NSP(Next Sentence Prediction) 제거 등 최적화 적용
-
ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
- Google이 개발한 효율적인 학습 방법
- GAN과 유사한 방식으로 'generator'와 'discriminator' 사용
- 같은 컴퓨팅 자원으로 BERT보다 뛰어난 성능 달성
-
ALBERT (A Lite BERT)
- 파라미터 공유 기법으로 모델 크기를 크게 줄임
- 팩토라이제이션, 크로스 레이어 파라미터 공유 등 혁신적 기법 도입
3. 주요 활용 분야
인코더 모델은 텍스트 분류와 이해 작업에 최적화되어 있습니다:
- 감성 분석: 리뷰나 댓글의 긍정/부정 판단
- 개체명 인식(NER): 텍스트에서 인명, 지명, 기관명 등 추출
- 문서 분류: 뉴스 기사 카테고리 분류, 스팸 메일 필터링
- 의미적 유사도: 두 문장의 의미가 얼마나 비슷한지 측정
- 자연어 추론: 두 문장 간의 논리적 관계 파악
4. 현재 위치와 전망
BERT의 등장은 2018-2020년 NLP 연구의 황금기를 열었습니다. 하지만 ChatGPT의 등장 이후 생성형 AI가 주목받으면서 상대적으로 연구가 줄어들었죠.그러나 인코더 모델은 여전히 중요합니다.
- 효율성: 생성 모델보다 훨씬 작은 크기로 분류 작업 수행
- 정확성: 특정 이해 작업에서는 GPT보다 우수한 성능
- 실용성: 기업 환경에서 빠르고 정확한 텍스트 분석에 필수적
3. 디코더 전용 모델 (Decoder-Only, Autoregressive)
주어진 입력에 기반하여 다음 단어를 예측하는 방식으로 텍스트 생성에 최적화되어 있습니다.
주로 챗봇, 문서 생성, 코딩 지원 등 다양한 생성형 AI 작업에 활용됩니다.
대표 모델은 GPT 계열, LaMDA, PaLM, LLaMA, Claude 등이 있습니다.
2020년대 이후 가장 주목받고 있는 구조로, GPT-3의 등장(2020) 이후 디코더 전용 모델이 NLP 연구의 중심이 되었습니다.
3. 매개변수(Parameters): 모델이 가진 “조정 가능한 기억”
1. 매개변수란?
-
정의: 신경망의 가중치(weight)와 편향(bias). 학습을 통해 값이 바뀌는, 모델이 세상으로부터 배운 모든 것을 담는 그릇.
-
역할: 언어의 패턴(문법, 의미, 상식, 추론 습관)을 수치 형태로 압축해 저장.
-
규모: “수십억~수천억”이 일반적. 파라미터 수가 크면 표현력(capacity)이 커지지만, 데이터/연산/메모리 비용도 비례해 증가.
2. 파라미터가 성능에 주는 영향
-
용량 vs. 일반화: 큰 모델은 복잡한 패턴을 더 잘 포착하지만, 데이터나 최적화가 부족하면 일반화 성능이 나빠질 수 있음.
-
스케일링 직관: 파라미터 수, 학습 토큰 수, 연산량이 균형을 이룰 때 가장 효율적. (데이터가 부족한데 모델만 키우면 학습이 “헛돌” 수 있어요.)
3. 파라미터와 하이퍼파라미터의 차이
-
파라미터: 학습으로 바뀌는 값(가중치/편향).
-
하이퍼파라미터: 사람이 미리 정하는 설정(학습률, 배치 크기, 층 수, 드롭아웃 등). 학습으로 자동 업데이트되지 않음.
4. 실무에서 자주 듣는 파라미터 관련 용어
-
임베딩(Embedding): 토큰/단어를 고정 길이 벡터로 매핑하는 초입층 파라미터.
-
어텐션 가중치: 트랜스포머가 문맥 내 상호작용을 계산할 때 쓰는 핵심 파라미터.
-
헤드/레이어 수: 모델 깊이·폭을 결정하는 구조적 하이퍼파라미터이지만, 그 결과로 실제 파라미터 수가 달라짐.
4. 사전 학습(Pre-training): “언어의 일반 법칙”을 체득하는 단계
1. 무엇을 학습하나?
-
목표(objective): 대부분 다음 토큰 예측(autoregressive). 입력 시퀀스가 주어졌을 때 바로 다음 토큰을 맞히는 문제를 무한 반복하며 언어의 통계적 구조를 흡수.
-
대안/변형: 마스크드 언어모델(MLM), 양방향 컨텍스트 등도 존재. 하지만 최신 LLM은 생성 능력을 위해 대부분 다음 토큰 예측을 채택.
2. 왜 “사전 학습”이 중요한가?
-
범용성: 뉴스, 서적, 코드, 포럼 등 광범위 데이터로 훈련하여, 특정 태스크를 넘는 일반적 언어 감각을 획득.
-
지식 축적: 세계 상식, 서술 패턴, 추론 단서 등을 파라미터에 압축 저장. 이후 다운스트림 작업의 기반이 됨.
3. 데이터·최적화·안정성 포인트
-
데이터 구성: 도메인 다양성, 품질 필터링, 디덕플리케이션(중복 제거), 안전/라이선스 준수.
-
토크나이제이션: BPE/Unigram 등. 토큰 효율은 비용과 성능에 직접 영향.
-
최적화: AdamW 계열 옵티마이저, 러닝레이트 워밍업→코사인/폴리 디케이 스케줄, 정규화(가중치 감쇠, 드롭아웃).
-
모니터링: 학습 손실/퍼플렉서티(PPL) 추적. 과적합 조짐(검증 PPL 악화) 관찰.
“아무런 지시가 없어도 언어의 일반적 규칙을 잘 따르도록 만드는 기초 체력 훈련”
5. 미세 조정(Fine-tuning): “특정 목적에 맞춘 기량 다듬기”
3. reference
https://wikidocs.net/222912
https://wikidocs.net/21687
https://www.dgmunit1.com/blog/genAi/02_Introduction-to-large-language-models
http://inwedo.com/blog/business-potential-of-ai-solutions/
https://data-newbie.tistory.com/953
https://medium.com/mti-technology/n-gram-language-model-b7c2fc322799
https://login-data.tistory.com/13
https://wikidocs.net/237619
https://geoffrey-geofe.medium.com/tokenization-vs-embedding-understanding-the-differences-and-their-importance-in-nlp-b62718b5964a
https://seungseop.tistory.com/21
https://hyunsooworld.tistory.com/entry/%EC%B5%9C%EB%8C%80%ED%95%9C-%EC%89%BD%EA%B2%8C-%EC%84%A4%EB%AA%85%ED%95%9C-%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-Attention-Is-All-You-NeedTransformer-%EB%85%BC%EB%AC%B8
https://ctkim.tistory.com/entry/RNN-seq2seq%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80
https://heeya-stupidbutstudying.tistory.com/entry/DL-Seq2Seq%EA%B3%BC-Attention
https://wikidocs.net/24996
https://www.youtube.com/watch?v=WsQLdu2JMgI&list=PLVNY1HnUlO26qqZznHVWAqjS1fWw0zqnT&index=12
https://deepdaiv.oopy.io/55b8a52b-4904-4455-ae32-e5985e9914d9
https://csshark.tistory.com/134
