🔨 Mysql 연동
mysql에 batch를 연동하기 위해서는 메타 데이터 테이블을 작성해야한다.
메타 데이터 데이터를 설명하는 데이터
엥? 그럼 내 DB에 batch가 사용하는 table을 내가 직접 만들어줘야된다고??라고 생각할 수 있는데 맞다 직접 만들어 줘야한다. 하지만 공식 문서를 보면 작성 sql을 모두 제공하고 batch 라이브러리에서도 제공하고 있기 때문에 크게 어렵진 않다!
batch meta data table 공식 문서에서 테이블 구조를 확인할 수 있으며 DDL 스크립트도 확인이 가능하다.
프로젝트 내부에서도 확인할 수 있는데
/{프로젝트 library 폴더}/{Spring Batch core 폴더}/Spring-batch-core-version.jar/org.springframework.batch.core/schema-mysql.sql 파일을 확인하면 된다. 혹시나 mysql이 아닌 다른 db를 사용한다면 다른 db들의 DDL 스크립트도 모두 정의 되어 있으니 해당 스크립트를 그대로 복사해서 사용하면 된다!
-- Autogenerated: do not edit this file
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME(6) NOT NULL,
START_TIME DATETIME(6) DEFAULT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME(6) DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME DATETIME(6) NOT NULL ,
END_TIME DATETIME(6) DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME(6),
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_STEP_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_SEQ);그것도 귀찮으신 분들은 이거 쓰면 된다. MySql용인것 잊지 말고 사용하자!
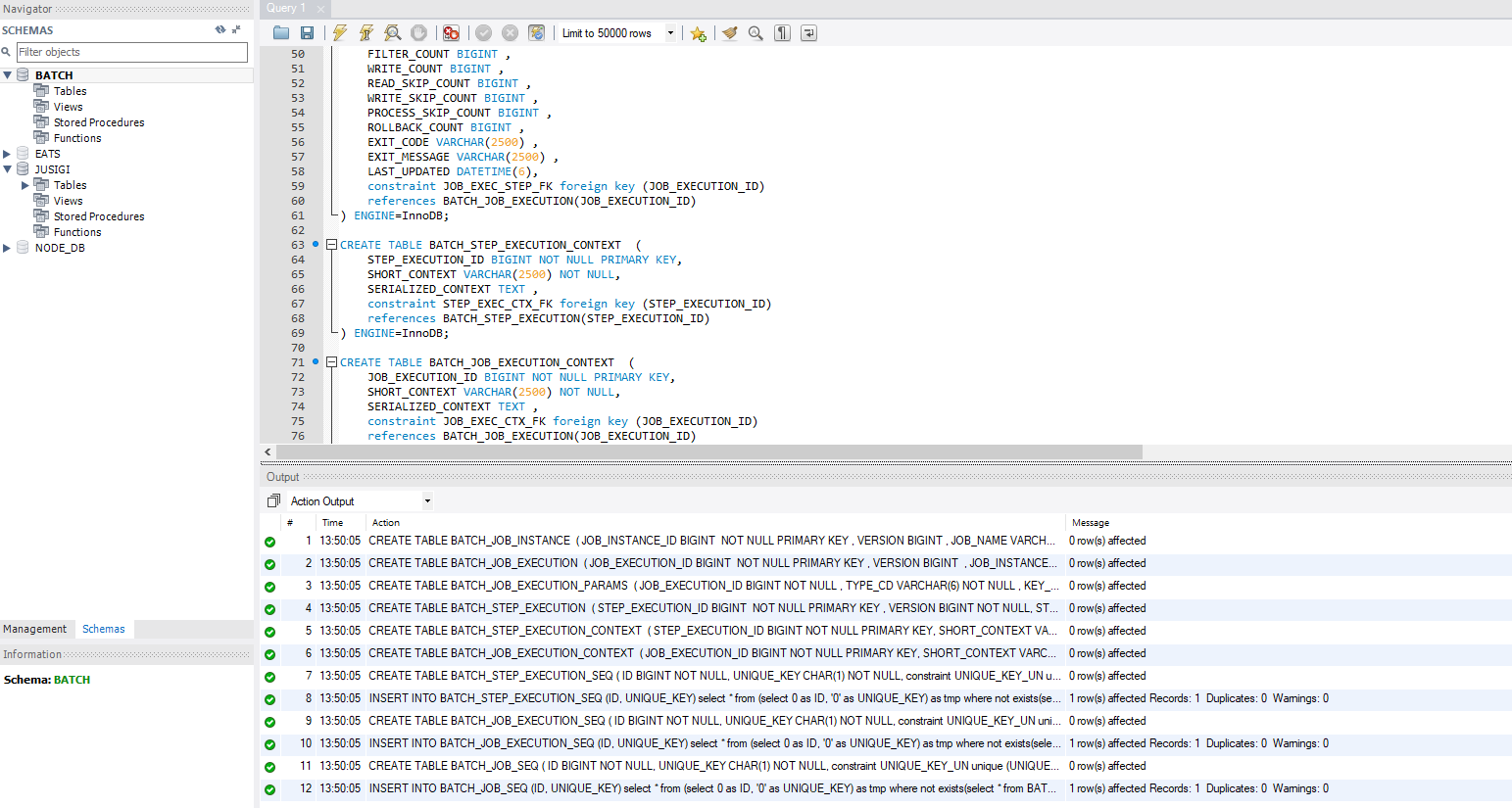
내가 사용하고 있는 MySql db에 다음과 같이 스크립트를 모두 적용시켜서 table을 생성했다.
spring:
profiles:
active: live
---
spring:
profiles: local
datasource:
hikari:
jdbc-url: jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE
username: sa
password:
driver-class-name: org.h2.Driver
---
spring:
profiles: live
datasource:
hikari:
jdbc-url: jdbc:mysql://localhost:3306/batch
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver그 후 yml파일에 다음과 같이 설정을 하면 되는데 위 코드는 개발환경과 실제 서버 환경을 구분하여 작동할 수 있도록 해놓았다. 테스트 환경은 나중에 작업해볼것이니까 우선은 위의 내용을 자신의 환경에 맞춰서 작성해주고 실행해보자! 아까와 같이 정상 실행이 된다면 정상적으로 작동하는 것이다.
📃 Batch Meta Table
우리가 지난 포스트에서 DDL 스크립트를 사용하여 batch의 테이블들을 정의했는데 각 테이블이 존재하는 이유가 있다. 그중 지금 당장 알아두면 batch의 구조를 이해하는데 도움이 되는 테이블 몇개를 알아보려고 한다.
BATCH_JOB_INSTANCE
위에서 MySql을 정상적으로 연동하고 정상 실행을 하였다면 DB에 정보가 하나 남아있을 것이다.
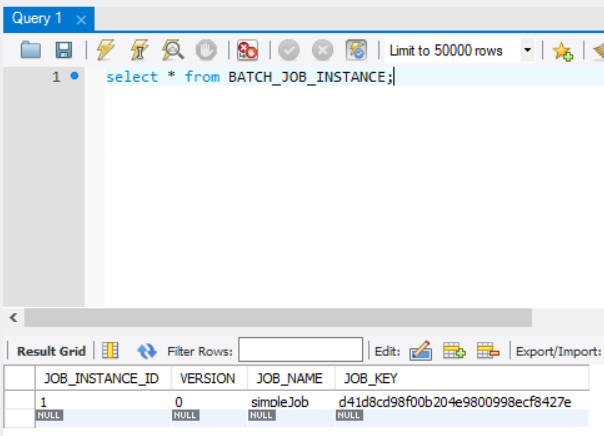
위 그림과 같이 방금 우리가 실행한 Job에 대한 기록이 남아 있다. 컬럼을 하나씩 보면
JOB_INSTANCE_ID Job 고유 idx pk
VERSION 해당 레코드에 update될때마다 1씩 증가
JOB_NAME 실행한 Job의 이름
JOB_KEY 동일한 Job의 이름으로 실행 시점에 부여된 JobParameter의 값을 통해 식별하는 값
다음과 같은 정보를 저장한다. 이제 우리는 Job을 실행할 때 JOB_KEY값이 각각 다르게 적용되어야 하는데 그럴려면 Job의 이름을 바꾸거나 JobParameter의 값을 변경해서 넣어줘야한다. Job의 이름을 바꾸기보다는 실행할 때 파라미터를 변경해서 넣는 것이 더 올바른 방법일 것이다.
실제로 우리가 실행했던 batch를 다시 실행해보면

Step이 이미 완료되었으며 재시작할 수 없다고 로그가 찍혀 나온다. 그럼 Job의 파라미터를 받을 수 있게 코드를 수정해보자.
@Slf4j
@RequiredArgsConstructor
@Configuration //Spring에 설정 파일이라는 선언
public class TestJob {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job simpleJob() {
return jobBuilderFactory.get("simpleJob") //simpleJob 이름으로 batch job을 생성
.start(simpleStep1(null)) //bean으로 등록된 Step을 실행
.build();
}
@Bean
@JobScope
public Step simpleStep1(@Value("#{jobParameters[requestDate]}") String requestDate) {
return stepBuilderFactory.get("simpleStep1") //simpleStep1 batch step을 생성
.tasklet((contribution, chunkContext) -> { //step 안에서 수행될 기능들을 명시, tasklet은 step 안에서 단일로 수행될 커스텀한 기능을 선언할 때 사용
log.info(">>>>> This is Step1");
log.info(">>>>> requestDate = {}",requestDate);
return RepeatStatus.FINISHED; //batch가 성공적으로 수행되고 종료됨을 반환
})
.build();
}
}코드를 다음과 같이 수정한다. 여기서 가장 중요한 것은 @JobScope 어노테이션과 @Value 어노테이션이다.
@JobScope Spring에 Job이라는 것을 알려주는 어노테이션
@Value lombok꺼 아님!
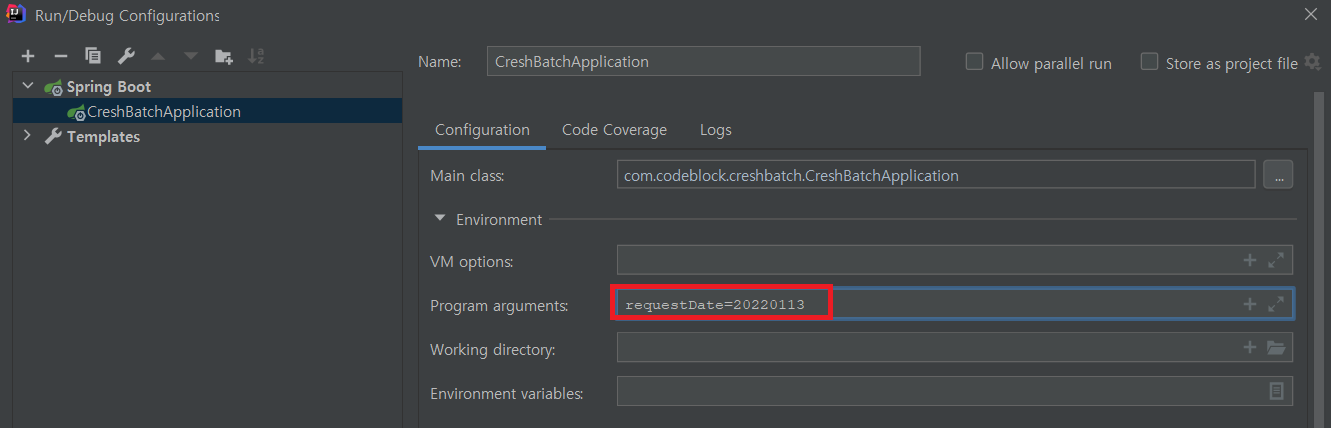
그 후 intellij에서는 다음과 같이 실행시 파라미터를 적용할 수 있는데 오늘 날짜를 적어주었다.
그리고 다시 실행을 해보자.
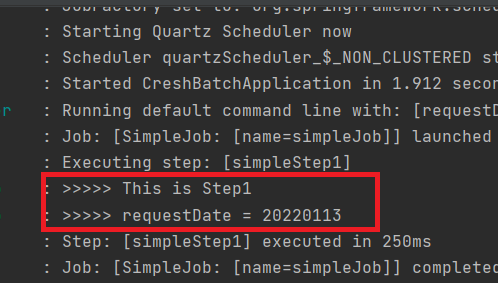
그러면 다시 정상적으로 batch가 실행된 것을 확인할 수 있다.
그리고 다시 테이블을 확인하면
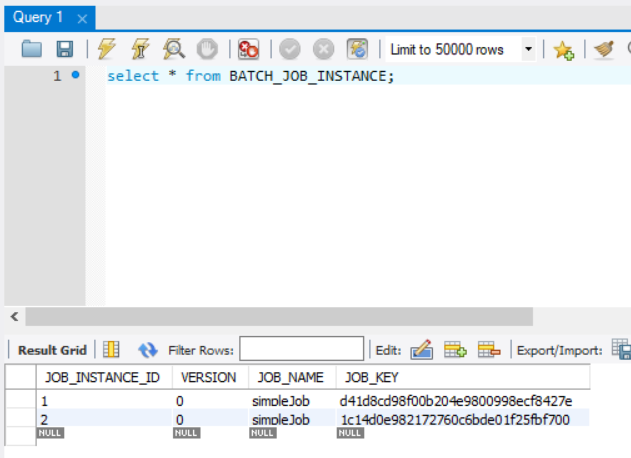
job이 추가된 것도 확인할 수 있다.
BATCH_JOB_EXECUTION
테이블을 먼저 select 해보자.
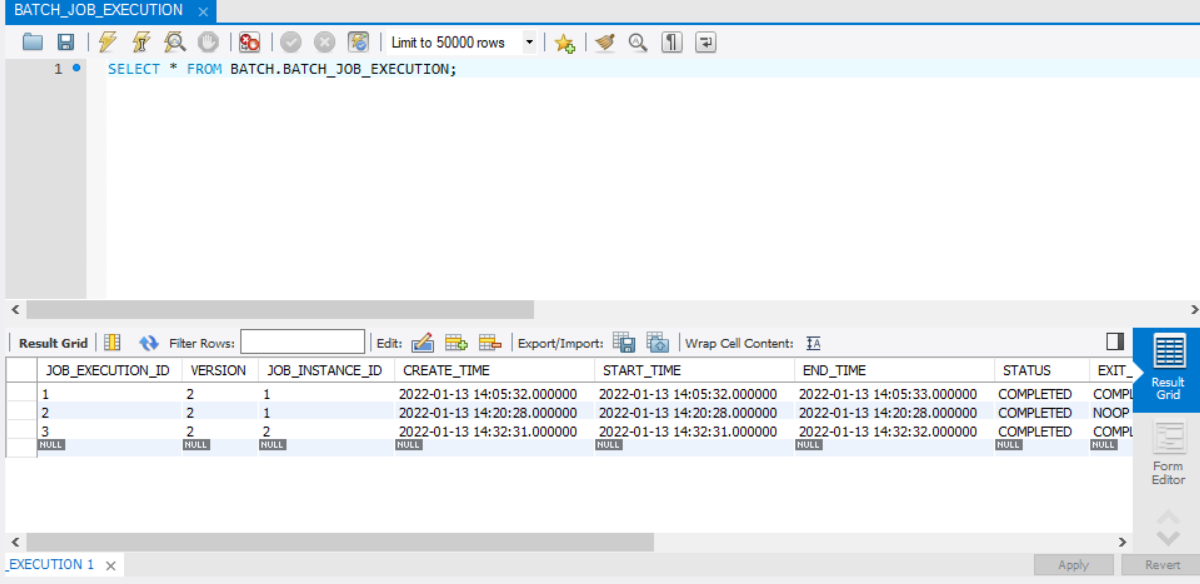
우리가 지금까지 실행한 3개의 job의 결과가 보인다.
BATCH_JOB_EXECUTION 테이블은 BATCH_JOB_INSTANCE 테이블과 부모-자식 관계인데 BATCH_JOB_INSTANCE가 실행했던 Job의 성공, 실패 내역을 BATCH_JOB_EXECUTION 테이블에 모두 가지고 있습니다.
그럼 Job에서 Exception을 발생시켜 실패해보겠습니다.
@Slf4j
@RequiredArgsConstructor
@Configuration //Spring에 설정 파일이라는 선언
public class TestJob {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job simpleJob() {
return jobBuilderFactory.get("simpleJob") //simpleJob 이름으로 batch job을 생성
.start(simpleStep1(null))//bean으로 등록된 Step을 실행
.next(simpleStep2(null)) //step1 종료 후 step2 실행
.build();
}
@Bean
@JobScope
public Step simpleStep1(@Value("#{jobParameters[requestDate]}") String requestDate) {
return stepBuilderFactory.get("simpleStep1") //simpleStep1 batch step을 생성
.tasklet((contribution, chunkContext) -> { //step 안에서 수행될 기능들을 명시, tasklet은 step 안에서 단일로 수행될 커스텀한 기능을 선언할 때 사용
throw new IllegalArgumentException("step1 예외 발생");
})
.build();
}
@Bean
@JobScope
public Step simpleStep2(@Value("#{jobParameters[requestDate]}") String requestDate) {
return stepBuilderFactory.get("simpleStep2") //simpleStep1 batch step을 생성
.tasklet((contribution, chunkContext) -> { //step 안에서 수행될 기능들을 명시, tasklet은 step 안에서 단일로 수행될 커스텀한 기능을 선언할 때 사용
log.info(">>>>> This is Step2");
log.info(">>>>> requestDate = {}",requestDate);
return RepeatStatus.FINISHED; //batch가 성공적으로 수행되고 종료됨을 반환
})
.build();
}
}job의 코드를 다음과 같이 Exception이 발생하도록 수정한 뒤 intellij에서 파라미터 값을 변경한 뒤 실행해보면

우리의 Job은 실행 도중 실패했다. 이제 table의 정보를 확인해보자.
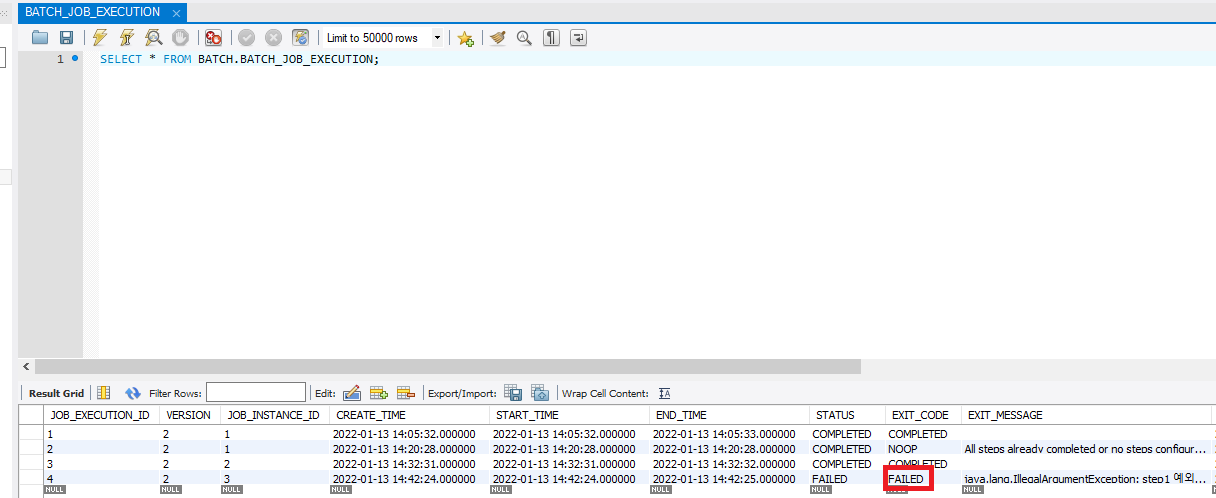
STATUS에서 실행 결과값을 볼수 있고 EXIT_MESSAGE를 통해 어떻게 실패했는지 정보를 알 수 있다.
그럼 이제 실패했던 Job을 다시 성공할 수 있도록 재실행해보자.
@Slf4j
@RequiredArgsConstructor
@Configuration //Spring에 설정 파일이라는 선언
public class TestJob {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean
public Job simpleJob() {
return jobBuilderFactory.get("simpleJob") //simpleJob 이름으로 batch job을 생성
.start(simpleStep1(null))//bean으로 등록된 Step을 실행
.next(simpleStep2(null)) //step1 종료 후 step2 실행
.build();
}
@Bean
@JobScope
public Step simpleStep1(@Value("#{jobParameters[requestDate]}") String requestDate) {
return stepBuilderFactory.get("simpleStep1") //simpleStep1 batch step을 생성
.tasklet((contribution, chunkContext) -> { //step 안에서 수행될 기능들을 명시, tasklet은 step 안에서 단일로 수행될 커스텀한 기능을 선언할 때 사용
log.info(">>>>> This is Step2");
log.info(">>>>> requestDate = {}",requestDate);
return RepeatStatus.FINISHED; //batch가 성공적으로 수행되고 종료됨을 반환
})
.build();
}
@Bean
@JobScope
public Step simpleStep2(@Value("#{jobParameters[requestDate]}") String requestDate) {
return stepBuilderFactory.get("simpleStep2") //simpleStep1 batch step을 생성
.tasklet((contribution, chunkContext) -> { //step 안에서 수행될 기능들을 명시, tasklet은 step 안에서 단일로 수행될 커스텀한 기능을 선언할 때 사용
log.info(">>>>> This is Step2");
log.info(">>>>> requestDate = {}",requestDate);
return RepeatStatus.FINISHED; //batch가 성공적으로 수행되고 종료됨을 반환
})
.build();
}
}코드를 먼저 성공할 수 있게 수정하고 파라미터는 변경하지 않은 상태로 다시 batch를 실행시킨다.
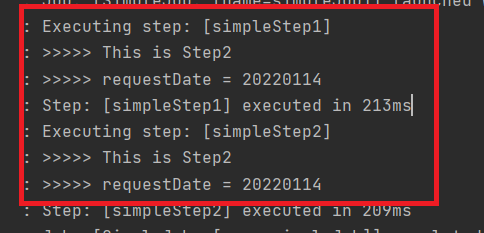
Job이 정상적으로 실행되고 완료된 것을 확인할 수 있다. log는 복붙하다가 그대로 적었으나 step의 이름이 다르니 이해바란다!
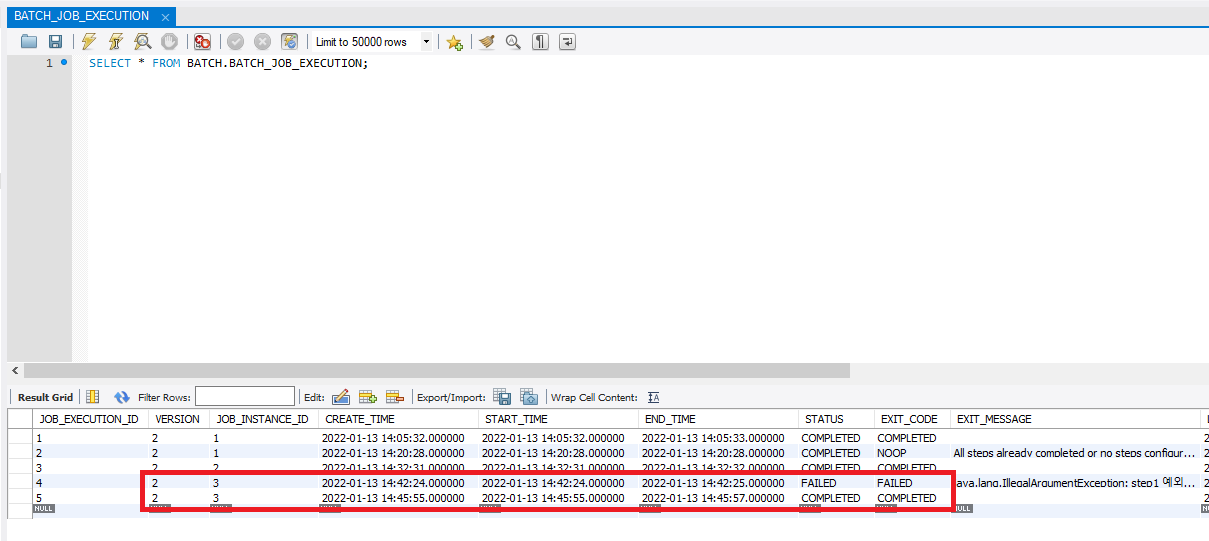
그 후 테이블에서 정보를 다시 확인하면 같은 인스턴스의 ID로 재실행이 되었고 상태값을 completed로 종료한 것을 확인할 수 있다.
여기서 확인할 수 있는 것은 batch는 실패한 실행에 대해서는 동일한 파라미터로 실행 요청이 들어와도 다시 실행시켜준다는 것이다.
BATCH_JOB_EXECUTION_PARAMS
테이블의 파라미터 값을 담고 있는 테이블이다.
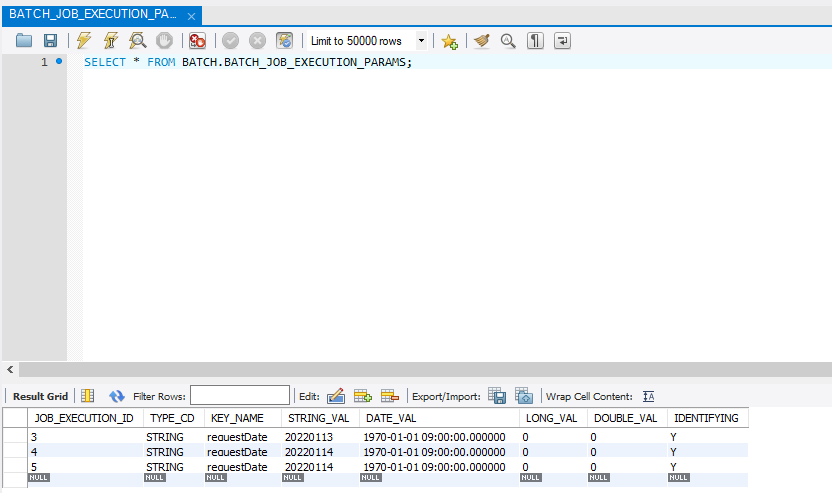
우리가 최초 실행한 2번의 파라미터 없는 요청을 제외하고 나머지 3번의 파라미터 요청에 대해서 모두 저장하고 있는 것을 확인할 수 있다.
그 외 테이블과 컬럼들의 구조를 알고 싶다면 batch 테이블과 컬럼들의 정의 글을 참고하면 좋을 것 같다.
