💭 왜 DB 다중화?
Batch 프로젝트를 진행하면서 Batch 메타 테이블이 꼭 실제 서비스 중인 프로젝트 DB에 붙어야할까? 라는 생각을 하게 되었다. 또한 Batch의 테스트 코드 작성이 실제 DB에 직접적으로 붙는다는게 개인적으로 좋게 보이지 않았다.
그래서 각 서비스 로직 별로 적용되는 DB를 나눌수 있지 않을까? 라는 생각을 하게 되었고 DI 부분에서 bean을 명시하여 등록해주는 방법이 있다는 것을 알았다.
🔨 우리가 진행할 작업
- yml or properties 파일에 db에 대한 정보를 분할
- @Value를 통해 yml 정보 불러오기
- data source를 여러 bean으로 등록
- batch에서 사용될 bean은 @Primary 적용
- 실제 사용될 dataSource를 @Qualifier를 통해 명시적으로 주입
- test code를 통해 bean 목록 조회와 명시적으로 DI가 되었는지 확인
이 순서로 작업을 진행해보자!
✍ yml 파일 수정
spring:
profiles: live
datasource:
hikari:
jdbc-url: jdbc:mysql://ip:port/schema
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver기존에 다음과 같이 설정되어있던 yml 파일의 내용을
spring:
profiles: live
db:
batch:
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://ip:port/schema1
username: root
password: root
service:
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://ip:port/schema2
username: root
password: root다음과 같이 db에 대한 설정을 2개로 batch와 service로 나누었다. 이 부분은 내가 작성한 방법대로 해도 되고 다르게 설정해도 된다. yml 작성 방법을 검색 후 편한대로 작성하면 될거 같다.
✍ DataSourceConfig.java
파일의 이름이나 패키지는 어디든 어떤 이름이든 상관없다. 하지만 나는 기존에 config 디렉터리를 생성해 둬서 그 안에 DataSourceConfig라는 이름으로 파일을 생성했다.
@Configuration
public class DataSourceConfig {
//===============================
//(1) batch db 설정 (=기본 primary 설정)
@Value("${db.batch.driver-class-name}")
private String defaultDriverClassName;
@Value("${db.batch.jdbc-url}")
private String defaultJdbcUrl;
@Value("${db.batch.username}")
private String defaultJdbcUserName;
@Value("${db.batch.password}")
private String defaultJdbcPassword;
//batch db 설정 종료
//(2) service db 설정
@Value("${db.service.driver-class-name}")
private String serviceDriverClassName;
@Value("${db.service.jdbc-url}")
private String serviceJdbcUrl;
@Value("${db.service.username}")
private String serviceJdbcUserName;
@Value("${db.service.password}")
private String serviceJdbcPassword;
//service db 설정 종료
//===============================
@Primary
@Bean(name = "defaultDb")
public DataSource defaultDataSource(){
return getDataSource(defaultDriverClassName, defaultJdbcUrl, defaultJdbcUserName, defaultJdbcPassword);
}
@Bean(name = "serviceDb")
public DataSource serviceDataSource(){
return getDataSource(serviceDriverClassName, serviceJdbcUrl, serviceJdbcUserName, serviceJdbcPassword);
}
//(3) DataSource 정보 세팅 method
private DataSource getDataSource(String driverClassName, String jdbcUrl, String jdbcUserName, String jdbcPassword) {
HikariConfig hikariConfig = new HikariConfig(); //(4) Spring Boot 기본적으로 HikariCP를 사용
hikariConfig.setJdbcUrl(jdbcUrl);
hikariConfig.setDriverClassName(driverClassName);
hikariConfig.setUsername(jdbcUserName);
hikariConfig.setPassword(jdbcPassword);
return new HikariDataSource(hikariConfig); //(5) 세팅된 정보를 DataSource 만들어서 반환
}
}그 후에 다음과 같이 코드를 작성했는데, 하나씩 살펴보자
- batch db에 대한 설정이다. yml에서 batch db로 정의한 내용을 그대로 불러와서 사용한다. 해당 db에는 메타 테이블이 정의되어 있다.
- service db에 대한 설정이다. 해당 db에는 실제로 서비스에서 사용되는 테이블들이 정의되어 있다.
- DataSource의 정보를 세팅하는 method이다. 반복적으로 사용되므로 method로 빼서 사용한다.
- Spring Boot는 기본적으로 HikariCP를 사용하고 있고 다른 CP를 사용한다면 검색 후 그대로 사용하면 될거 같다.
- 파라미터로 받은 값들을 세팅하여 DataSource 객체로 반환하여 사용한다.
이렇게 기본적인 코드 작성에 대한 설명은 끝났고 어떻게 이 로직이 실행되는지 알아보자.
- @Configuration 어노테이션을 통해 해당 class는 application 시작시 Spring이 관리하는 Container에 등록됨
- @Value를 통해 yml의 정의된 내용을 변수의 값으로 넣어줌
- @Bean의 name 옵션을 통해 등록되는 bean의 이름을 명시해줌
- @Primary를 통해 명시적으로 주입되지 않는 부분에 대해서는 자동으로 주입될 bean을 명시해둠
그러면 실제로 bean으로 등록이 잘 되었는지 먼저 확인해보자.
@SpringBootTest
public class BatchTest {
@Autowired
private ApplicationContext applicationContext;
@Test
void bean_이름_조회(){
String[] beans = applicationContext.getBeanDefinitionNames();
for (String bean : beans) {
System.out.println("bean = " + bean);
}
}
}test code로 다음과 같이 작성 후 실행해보면
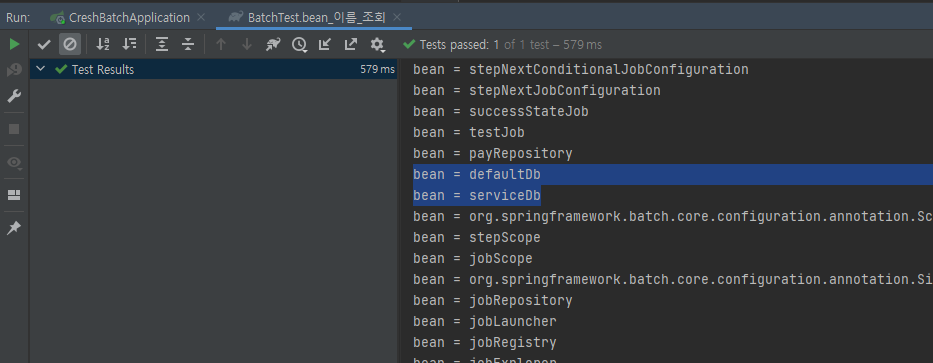
내가 방금 등록한 bean의 이름을 목록에서 확인할 수 있다.
그러면 등록한 이름을 통해 bean에 대한 주입을 정말로 명시적으로 실행할 수 있는지 확인해보자.
@SpringBootTest
public class BatchTest {
@Autowired
@Qualifier("serviceDb")
DataSource dataSource;
@Test
void dataSource_출력(){
System.out.println("dataSource = "+dataSource.toString());
}
}다음과 같이 dataSource에 @Autowired와 @Qualifier를 사용하여 명시적으로 주입해준뒤 출력해보자.
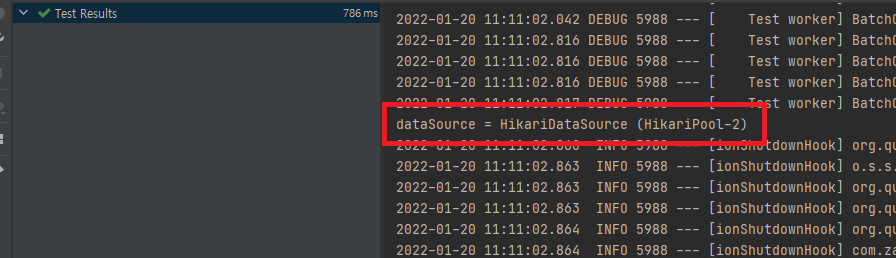
정상적으로 DataSource를 주입 받은 것을 확인할 수 있다.
여기서 Test를 진행할 때 DI Container를 사용해야 하므로 @SpringBootTest 어노테이션을 붙여서 진행해야한다.
그럼 이제 내가 설정한 대로 DB의 정보를 바꿔서 적용할 수 있다는 것을 알 수 있었다. 그럼 실제 코드에 적용해서 확인해보자.
🔨 Job에 DataSource 적용
@Slf4j
@RequiredArgsConstructor
@Configuration
public class SuccessStateJob {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Autowired
@Qualifier("serviceDb")
private DataSource dataSource; //db
private static final int chunkSize = 10;
@Bean
public Job SuccessStateJob() throws Exception{
return jobBuilderFactory.get("successStateJob")
.start(successStateStep())
.build();
}
@Bean
public Step successStateStep() throws Exception{
return stepBuilderFactory.get("successStateStep")
.<Pay, Pay>chunk(chunkSize)
.reader(successStateReader())
.processor(successStateProcessor()) //필요할 경우 데이터 처리
.writer(successStateWriter())
.build();
}
@Bean
public ItemReader<? extends Pay> successStateReader() throws Exception {
Map<String, Object> param = new HashMap<>();
param.put("success_state","false");
return new JdbcPagingItemReaderBuilder<Pay>()
.pageSize(chunkSize)
.fetchSize(chunkSize)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Pay.class))
.queryProvider(createProvider())
.parameterValues(param)
.name("jdbcPagingItemReader")
.build();
}
@Bean
public PagingQueryProvider createProvider() throws Exception{
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setDataSource(dataSource);
provider.setSelectClause("id, amount, tx_name, tx_date_time, success_state");
provider.setFromClause("from pay");
provider.setWhereClause("where success_state = :success_state");
Map<String, Order> sortKey = new HashMap<>(1);
sortKey.put("id", Order.ASCENDING);
provider.setSortKeys(sortKey);
return provider.getObject();
}
@Bean
@StepScope
public ItemProcessor<? super Pay, ? extends Pay> successStateProcessor() { //success_state를 true 처리
return item -> {
item.setSuccessState("true");
return item;
};
}
@Bean
public JdbcBatchItemWriter<? super Pay> successStateWriter() {
return new JdbcBatchItemWriterBuilder<Pay>()
.dataSource(dataSource)
.sql("update pay set success_state = :successState where id = :id")
.beanMapped()
.build();
}
}DataSource를 불러오는 부분만 명시적으로 주입하기 위해 사용했다.
그럼 실제로 Job을 실행시키고 결과를 확인해보자!
👊 Test
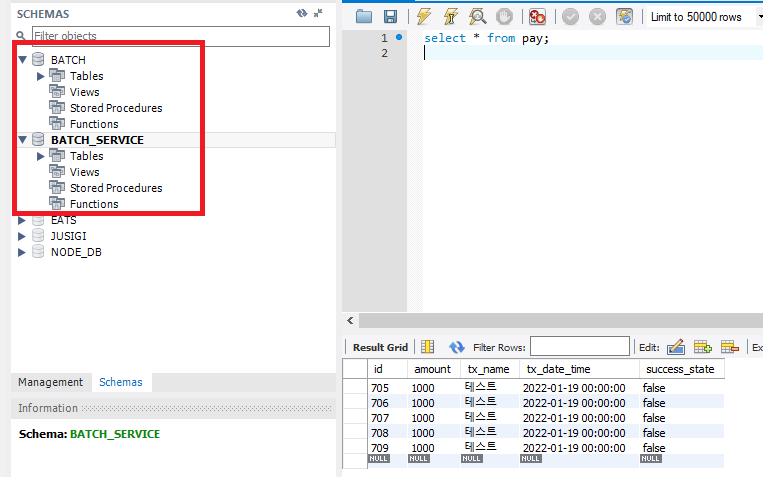
위 사진처럼 나는 현재 Schema를 2개로 나누어서 Batch와 Service로 나누어놨다. 그리고 pay table의 현재 success_state 값은 모두 false로 되어 있는데 우리가 작성한 Job은 false -> true로 변경해주는 Job이였다.
내가 예상하는 결과
- Batch_Service의 pay table의 상태값이 모두 true로 변경
- Batch의 BATCH_JOB_EXECUTION 결과를 기록
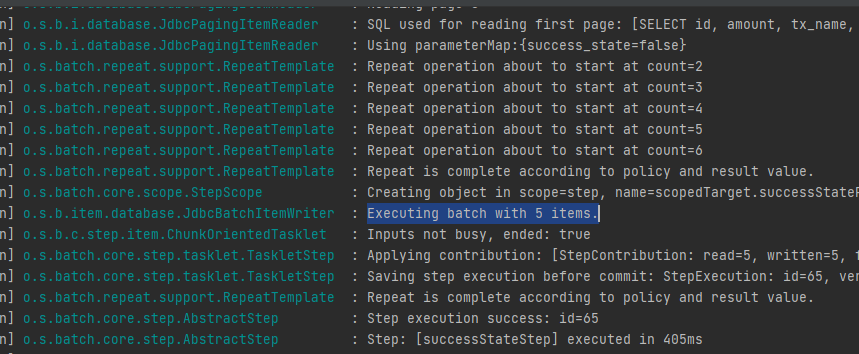
batch에서는 어떤 error가 없이 잘 실행되었고
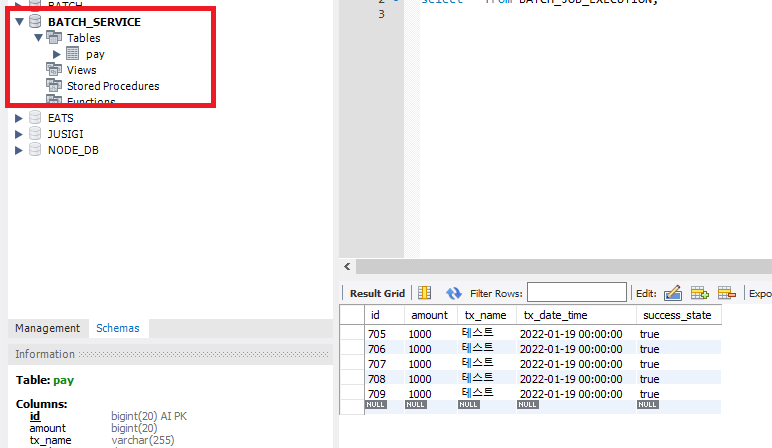
pay 테이블에도 true로 모두 변경이 되었다.
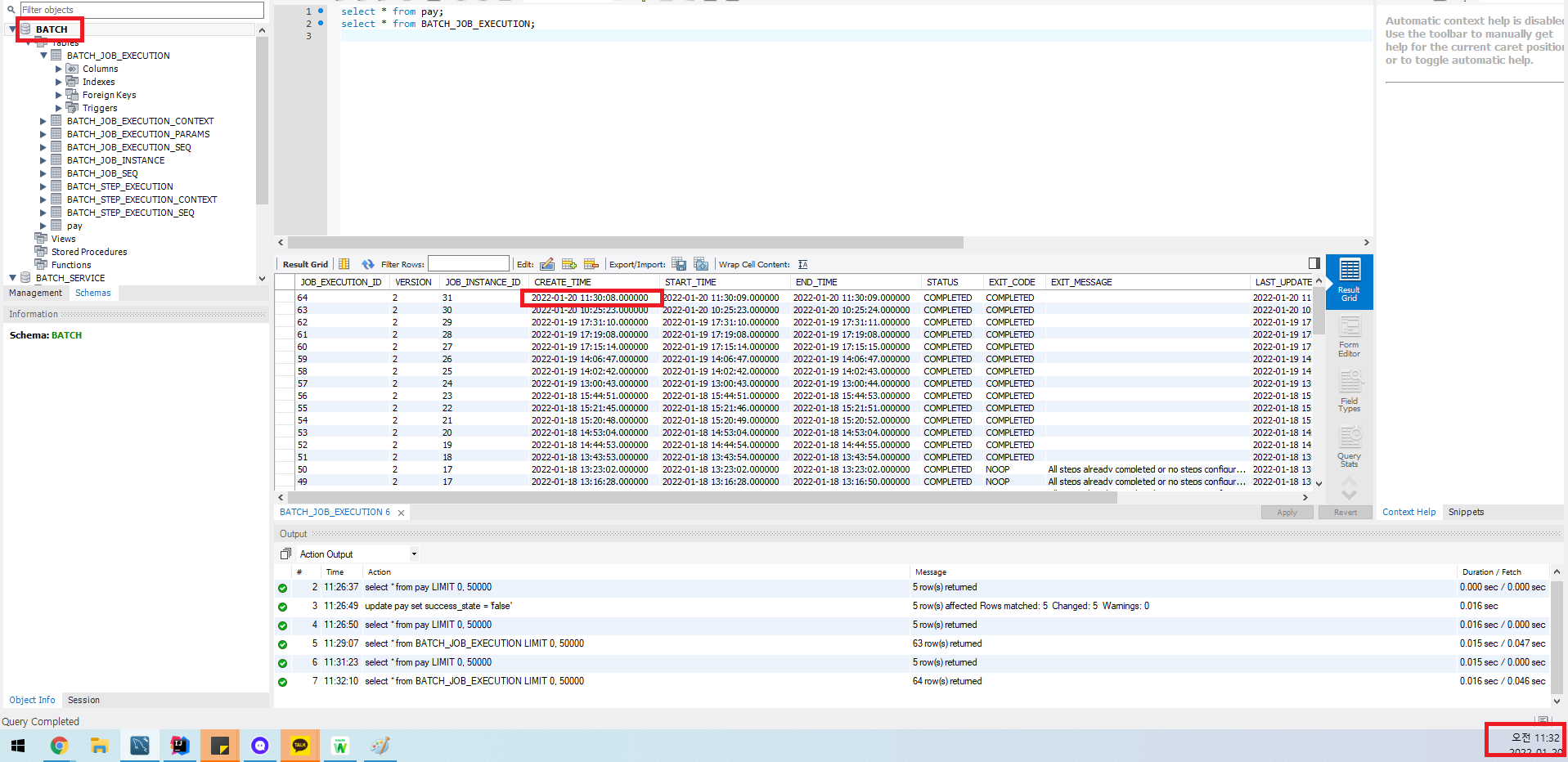
BATCH_JOB_EXECUTION 테이블에도 현재 시간으로 Job이 정상적으로 실행되었고 완료되었다는 정보가 남게된다.
🧪 JDBC, DataSource, DBCP
JDBC
JDBC는 DB와 연결하는 Driver Class를 통해 데이터베이스와 연결되어 데이터를 주고 받을 수 있게 해주는 API이다.
API란 Application Programing Interface 컴퓨터나 컴퓨터 프로그램 사이에 연결역할
Driver
사용하고자 하는 DB에 맞는 드라이버
Connection
DB와 연결정보를 가지는 Interface
DriverManager로부터 Connection 객체를 가져옴
Statement
SQL query문을 DB에 전송하는 방법을 정의한 Interface
ResultSet
Select를 통해 조회할 방법을 정의한 Interface
public class JdbcCustomerRepository {
private static final Logger logger = LoggerFactory.getLogger(JdbcCustomerRepository.class);
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
// connection 획득
connection = DriverManager.getConnection("jdbc:mysql://localhost/order_mgmt", "root", "1234");
// statement 객체 생성
statement = connection.createStatement();
// RDB와 통신
resultSet = statement.executeQuery("SELECT * FROM customers");
while (resultSet.next()) {
var customerId = UUID.nameUUIDFromBytes(resultSet.getBytes("customer_id"));
var name = resultSet.getString("name");
logger.info("customer id -> {} name -> {}", customerId, name);
}
} catch (SQLException throwables) {
logger.error("Got error while closing connection", throwables);
} finally {
// 사용한 객체들 반납
try {
if (connection != null) connection.close();
if (statement != null) statement.close();
if (resultSet != null) resultSet.close();
} catch (SQLException e) {
logger.error("Got error while closing connection", e);
}
}
}
}이전에 DB에서 JDBC를 통해 데이터를 조회하는 코드를 보면 훨씬 쉽게 이해할 수 있다.
DataSource
DBCP를 관리하는 목적으로 사용되는 객체
DBCP
위에서 JDBC를 통해 매번 결과를 DB에서 호출할때마다 Connection 객체를 생성하고 객체를 반납하는 동작을 반복해야한다. 이 행동은 성능에 있어서 매우 불리한 동작이다.
그래서 Data Base Connection Pool을 통해 일정한 Connection들을 미리 만들어서 대기하고 DB에 연결이 이뤄질때 Pool에 미리 만들어 놓은 Connection을 빌려 쓰며 사용후에는 Pool에 다시 반납한다.
👍 DB 이중화를 하며 느낀점
- DB 이중화를 하며 DI의 개념에 대해 더 간접적으로 느끼며 직접 세팅해볼 수 있었다.
- 실제로 Bean이 ApplicationContext에 등록되어 있는 것을 Test Code로 실행해보며 로직을 이해하는데 도움이 되었다.
- DB에서 사용되는 DataSource와 JDBC, DBCP 등의 개념을 더 숙지할 수 있었다.
- 매번 생성자 or @Autowired를 통해 개념 없이 의존성을 주입하다가 명시적으로 주입해볼 수 있던 기회가 되었다.
